

Amazon’s AI Resurgence: AWS & Anthropic's Multi-Gigawatt Trainium Expansion
Anthropic multi-gigawatt clusters, Trainium ramp, best TCO per memory bandwidth, system-level roadmap, Bedrock and internal models
Two-and-a-half years ago, we flagged a looming “cloud crisis” at AWS. Today, the evidence has mounted. AWS is the crown jewel of the Amazon empire, generating ~60% of group profits, and dominating the lucrative Cloud Computing market. But it struggles to translate this strength into the new GPU/XPU Cloud era.
Microsoft Azure now leads the market on quarterly new cloud revenue, and the gap between Google Cloud and AWS has materially narrowed especially with Google's big moves on the TPU that we've been posting about for over a month. Markets have noticed. Year-to-date, Amazon is the clear laggard among the four tech-and-AI titans as investors mark down the company most for losing momentum in AI.
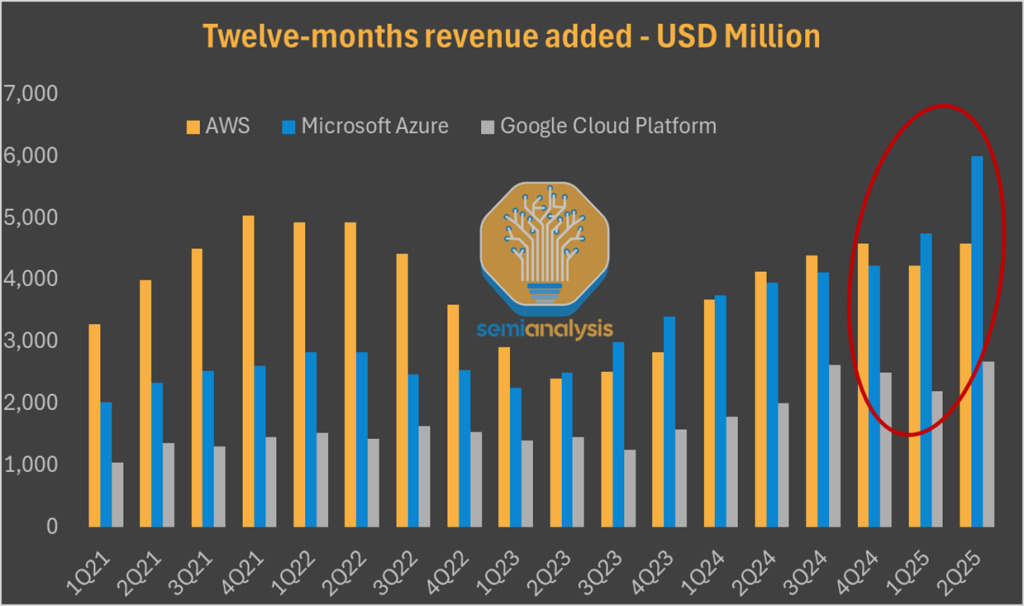
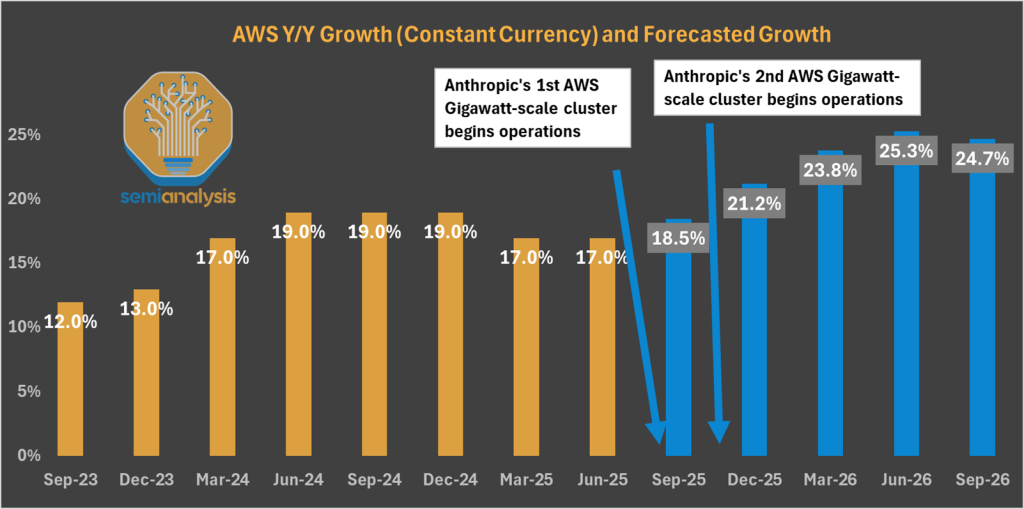
Today, SemiAnalysis is back with another out-of-consensus call. While the market overplays the Cloud Crisis theme, we call for an AWS AI Resurgence. We laid out our thesis a month ago to our Core Research subscribers, forecasting an upcoming acceleration beyond 20% year-over-year growth by the end of 2025.
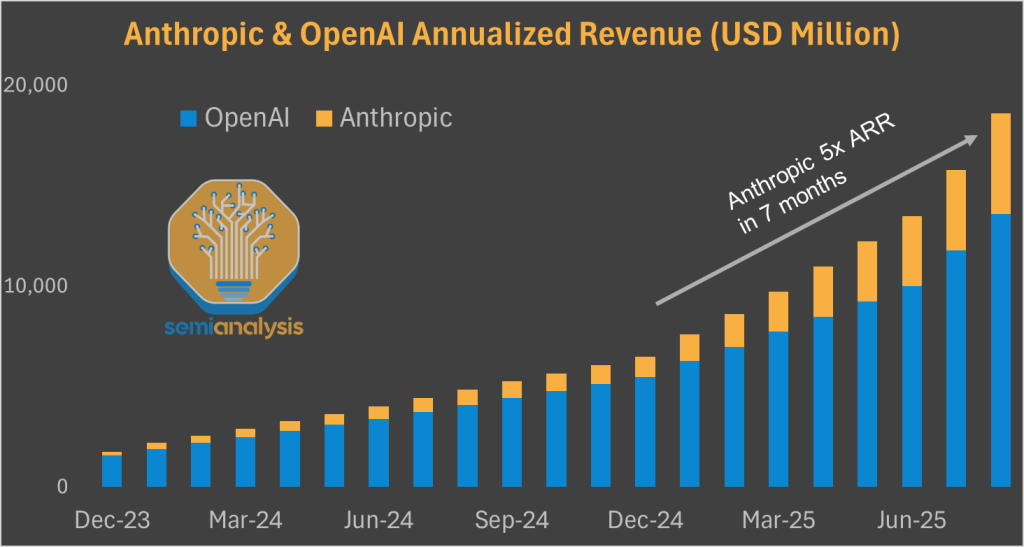
Amazon’s savior has a name: Anthropic. The startup has been the clear outperformer in the GenAI market in 2025, multiplying revenue fivefold year-to-date to reach $5B annualized.
To keep that trajectory, Anthropic is betting hard on Scaling Laws. While Dario’s startup draws fewer headlines than OpenAI, xAI and Meta Superintelligence, it isn’t shy about investment. AWS has well over a gigawatt of datacenter capacity in final stages of construction for its anchor customer. AWS is building datacenters faster than it ever has in its entire history. And there’s much more on the horizon.

To understand and forecast GPU/XPU power capacity by AI Lab broken down by Cloud Provider, we rely on our proprietary Datacenter Industry Model powered by real-time satellite imagery. Trusted by all hyperscalers, AI labs, and the world’s largest investors, it provides a quarterly building-by-building datacenter forecast for OpenAI, Anthropic, xAI, Meta Superintelligence, Google DeepMind, and more. Contact us for more information.
Trainium vs GPUs
While Amazon’s AI Datacenters are impressive in scale and speed, the design of individual building is unremarkable. Hyper-optimized for air-cooling, this blueprint is identical to 5-year-old traditional AWS Cloud datacenters.
What makes these facilities unique is their inside: they’ll host the world’s largest cluster of non-Nvidia AI chips, with just under a million Trainium2 in the largest campus. To understand everything about the Trainium2 system, read our December 2024 technical deep dive.
Trainium2 lags Nvidia’s systems in many ways, but it was pivotal to the multi-gigawatt AWS/Anthropic deal. Its memory bandwidth per TCO advantage perfectly fits into Anthropic’s aggressive Reinforcement Learning roadmap. Dario Amodei’s startup was heavily involved in the design process, and its influence on the Trainium roadmap only grows from here.
Put plainly: Trainium2 is converging toward an Anthropic custom-silicon program. This will enable Anthropic to be, alongside Google DeepMind, the only AI labs benefiting from tight hardware–software co-design in the near horizon.
This report will dig into all aspects of Amazon’s AI resurgence: the Anthropic partnership, datacenters, and Trainium. At the end of the report, we provide a longer-term outlook on Anthropic, AWS Bedrock and internal models, and explain why everything isn’t rosy.
First, a step back on why AWS has underperformed rival AI Clouds to date.
AWS GenAI underperformance
To understand the causes of Amazon’s underperformance in the GenAI era, we can analyze drivers of success in the GPU/XPU cloud market. In the most simplistic way, we see two primary customer groups for GPU/XPU capacity:
Wholesale bare metal users: large-scale customers like OpenAI, Anthropic, ByteDance, and other hyperscalers.
Managed SLURM/Kubernetes: Smaller customers such as startups, research institutes, and enterprise pilot projects.
Cloud Crisis and ClusterMAX underperformance
In the second category, our ClusterMax AI cloud rating is the best way to compare relative strengths and weaknesses. Platinum and gold-rated AI Clouds have seen more traction than others and boast higher-than-average pricing power. As such, the likes of CoreWeave, Oracle, Nebius, Crusoe and Azure have outperformed the market for multitenant GPU clusters – which require high performance and advanced software layers.

As predicted two years ago, key to Amazon’s underperformance is the use of custom networking fabric EFA. AWS's success with ENA on the frontend network has not yet translated to EFA on the backend. EFA still lags behind other networking options on performance: NVIDIA's InfiniBand and Spectrum-X, as well as RoCEv2 options from Cisco, Arista, and Juniper. Raw performance isnt the only metric, the user experience of EFA isn't as good as InfiniBand & RoCEv2 either. That being said, with Amazon's newest EFAv4 performance at real world msg sizes is improving, albeit still behind the competiton.
Amazon's custom networking also reduces their time-to-market due to customization requirements of Nvidia systems. Other items like advanced passive and active automated weekly scheduled health check strategies aren’t as solid as gold & platinum-rated clouds.
Our upcoming ClusterMAXv2 rating will provide an update on all major cloud providers based on our proprietary testing. Stay tuned!
Searching for an anchor customer
More important to AWS’ XPU business growth is the ability to secure anchor customers – the market-makers in this first wave of GenAI demand. Scale, time-to-market, deep partnerships, and pricing are key to winning these accounts, more so than advanced software layers.
No firm better illustrates this than Microsoft. Azure’s AI outperformance over peers is entirely driven by its OpenAI partnership. As of Q2 2025 (June 2025), all of OpenAI’s >$10B cloud spending is booked by Azure.
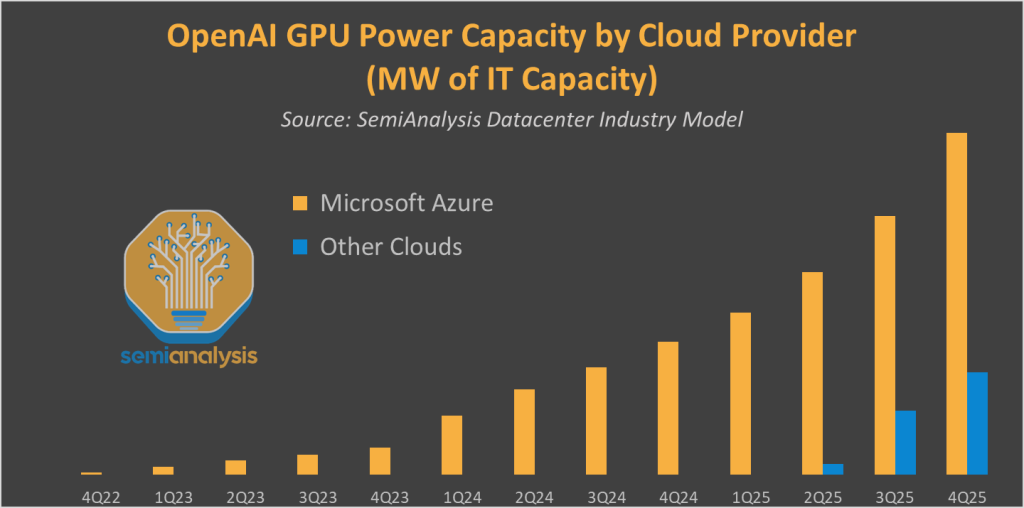
Amazon understood early on the need for an anchor customer and invested $1.25B, expandable to $4B in Anthropic in September 2023. The partnership expanded in March 2024 with Anthropic committing to use Tranium and Inferentia chips. In November 2024, Amazon invested an additional $4B into Anthropic, with the latter naming AWS as its primary LLM training partner.
Anthropic’s outperformance, AWS underperformance?
Amazon’s bet has been the right one. Anthropic is the clear outperformer in 2025 in the GenAI market, with revenue surging from $1B to $5B annualized. In this context, AWS’ underperformance understandably frustrates investors, but they’re misunderstanding the composition of Anthropic’s spending on training and inference.
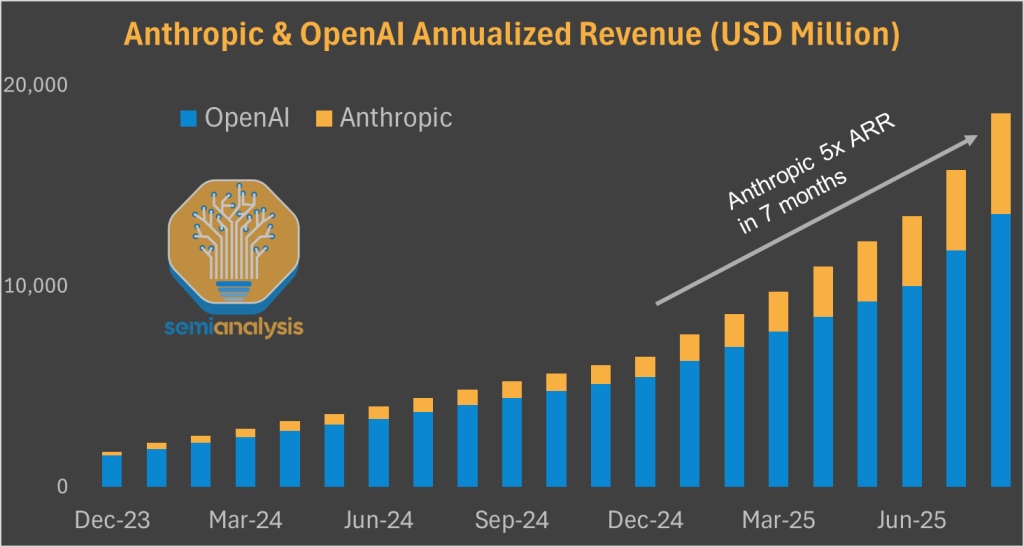
There are two clear reasons explaining why Amazon isn’t yet truly benefiting from its relationship with Anthropic:
As of Q2 2025, Anthropic’s cloud spending is over 2x smaller than that of OpenAI.
A large share of Anthropic’s spending is going to Google Cloud – one of Anthropic’s first major investors ($300M round late-2022) and preferred cloud partner in 2023 and 2024, before the expanded AWS deal.
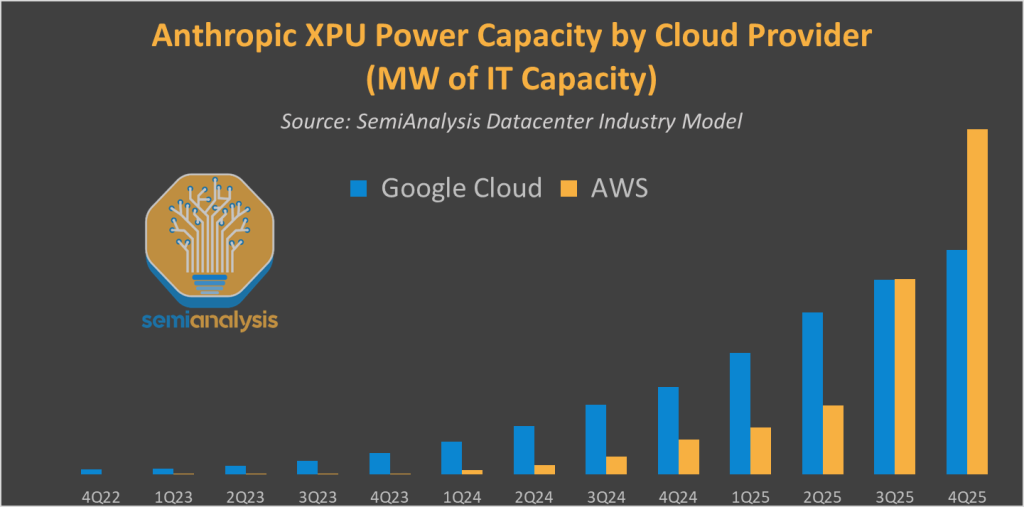
Anthropic & AWS multi-gigawatt AI Training infrastructure
In particular, we believe that most of Anthropic’s skyrocketing inference needs are served by Google Cloud. Having the world’s best inference system (TPU) is a key competitive advantage.
The AWS infrastructure buildout is aimed at taking a chunk of this for its key customer will also focusing on training. While Anthropic makes less headlines than peers like OpenAI, xAI and Meta, is it all-in on the AGI race and isn’t planning to be shy on training spending. Anthropic leadership truly believes in Scaling for RL.
Their belief will materialize as early as this year. We show below three AWS campuses in final stages of construction, boasting over 1.3GW of IT capacity for the sole purpose of serving Anthropic’s training needs. The speed of construction is remarkable.

While these datacenters look built from the skies, we don’t think they are generating any meaningful revenue yet. Trainium has faced some yield issues on the assembly phase – fairly standard for a new system. We think the three large AWS campuses will meaningfully contribute to AWS’ top line by the end of 2025 and jack up growth above the 20% YoY threshold.
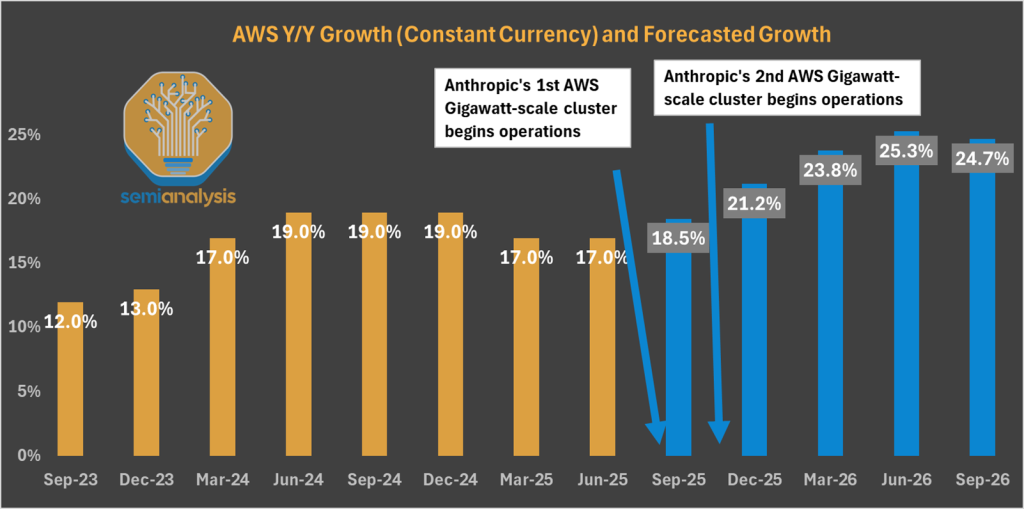
Anthropic isn’t stopping there. Its ~$13B funding round at a $183B valuation will provide capital to sign additional deals with AWS, Google, and others. AWS isn’t waiting standing still – they're already breaking ground on upcoming GW-scale datacenters to capture this growth.

As explained earlier, these datacenters will primarily be filled with AWS’ custom chip Trainium. Given the sheer scale, we can’t understate how bold Anthropic’s bet is. Not only are they committing to spending tens of billions of dollars, they're doing it on a largely unproven chip!
Let’s try to make some sense of their bet by digging into Trainium’s TCO and roadmap.
Trainium2 TCO analysis – how Anthropic’s big bet could pay off
Trainium2 supply chain signals are currently extremely strong. Our industry-leading AI Accelerator Model track both the package shipments and the system/rack shipments and they’ve surged since the beginning of the year. It provides quarterly volume forecasts for the 10+ SKUs comprising the Trainium2 and Trainium3 product family and calls out suppliers set to disproportionately benefit from specific SKUs. Contact us for more information.
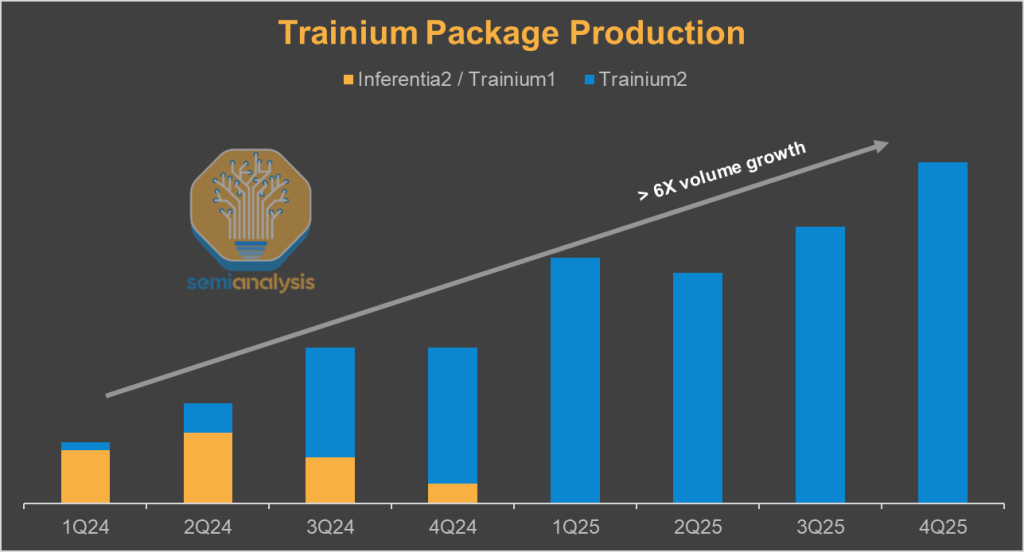
Note this is chip production, rack production is lagged, but we also track it.
Competing with Nvidia and Google’s TPU is, of course, no small feat. While Google is rolling out its seventh generation TPU, Ironwood, Trainim2 is only Amazon’s third-generation AI Accelerator.
Chip specifications: Trainium2 inferior on all fronts, but…
A simple look at chip specifications shows Trainium as a clear laggard relative to Nvidia:
Nvidia’s GB200 has a 3.85x FP16 FLOPs advantage, at 2500 TFLOP/s/chip vs Trainium2’s 667 TFLOP/s/chip. Note that spec sheet numbers are inflated compared to actual achievable FLOPs.
In terms of Memory bandwidth, the gap narrows to 2.75x, at 8000GB/s/GPU vs 2900GB/s/Trn2
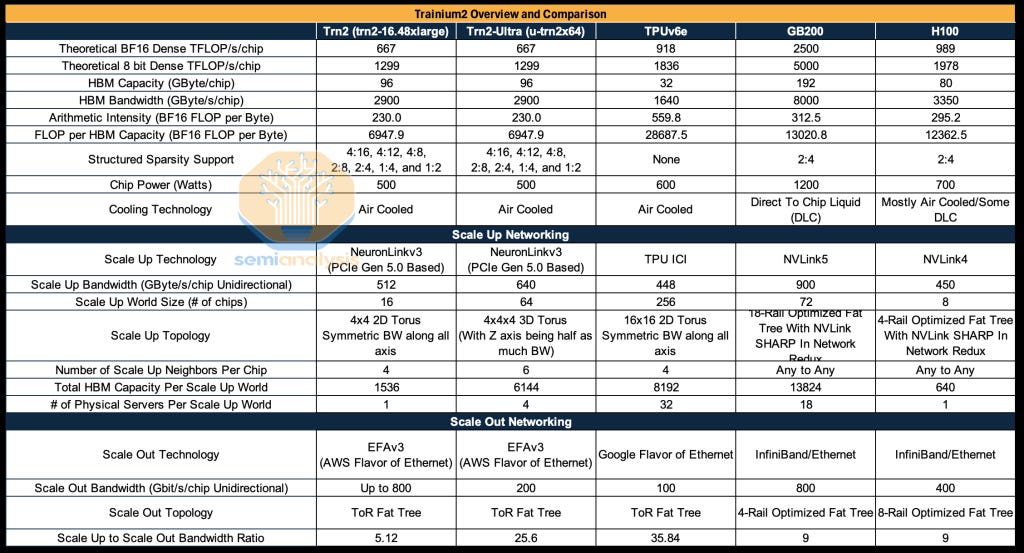
Evaluating scale-up network bandwidth is another key item. We’ve explained several times the importance of scale-up networks for reasoning model inference. Our deep-dive on Reinforcement Learning highlighted the similarities of RL with inference workloads, making memory bandwidth a crucial item to scale post-training.
Nvidia’s GB200 NVL72 boasts an aggregate 576TB/s memory bandwidth across World Size.
This is a 3.1x advantage relative to Trainium2’s (Teton2-PD-Ultra-3L SKU) 186 TB/s – with the caveat that it varies across SKUs.
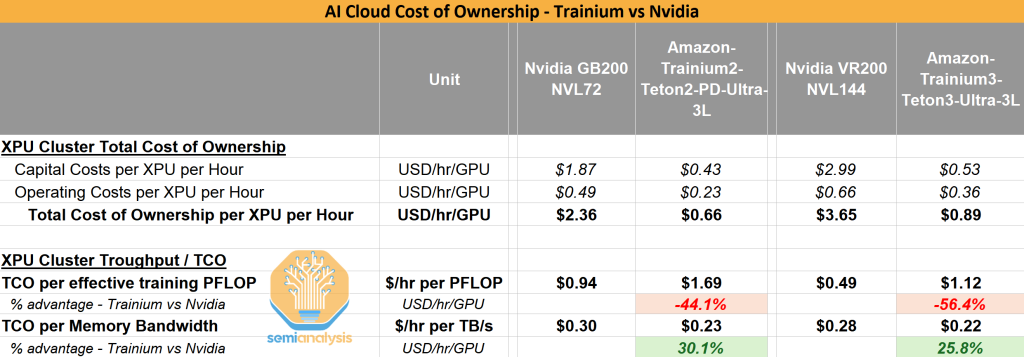
While Trainium appears materially behind, the picture changes once we factor-in Total Cost of Ownership.
Trainium’s memory bandwidth per TCO advantage
In the table below, we incorporate TCO into our comparison. While Nvidia has a material head on a TCO per effective training PFLOP, Trainium2 is highly competitive on a TCO per million Tokens and TCO per TB/s of memory bandwidth.
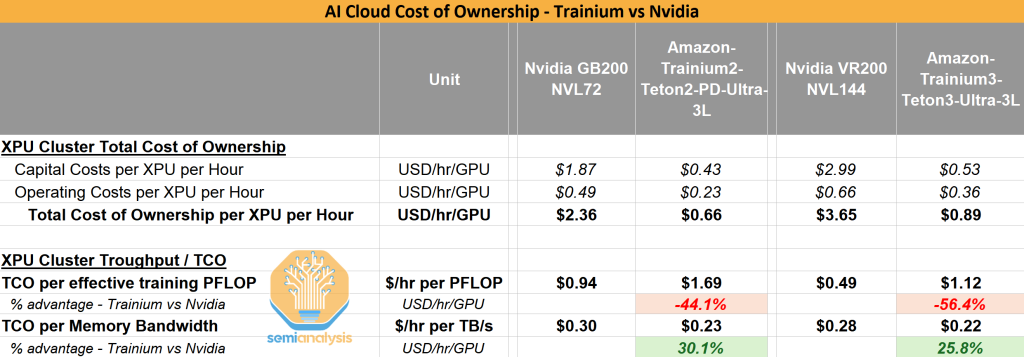
And we don’t see Nvidia’s upcoming VR200 NVL144 change the picture relative to AWS’ Trainium3. To be clear, TCO has many other moving parts. AWS has other system-level architecture deployments that better fit some use cases. Later down the road, Nvidia’s Kyber rack will boast the world’s most advanced scale-up network architecture.
For a full understanding of the TCO of 50+ Nvidia SKU and a detailed TCO comparison with all AMD, Trainium and TPU SKUs, check out our AI Cloud TCO Model. The largest hyperscalers, Neoclouds and their financial sponsors rely on our model to time their investment decisions.
Anthropic is betting on hardware-software codesign
Trainium2’s memory bandwidth per TCO advantage is key to understanding Anthropic’s choice. While Nvidia’s chips and systems are better on most fronts, Trainium2 fits perfectly into Anthropic’s roadmap. They’re the most aggressive AI Lab on scaling post-training techniques like Reinforcement Learning. Their roadmap is more memory-bandwidth-bound than FLOPs bound. Our recent HBM report explains in-depth which AI workloads tend to be memory-bound.
Anthropic’s ramp will make it not only the only large external end-user of Trainium2, it’ll also be materially larger than Amazon’s internal needs (e.g. Bedrock, Alexa, etc). They’re now heavily involved in all Trainium design decisions and, essentially, use Amazon’s Annapurna Labs as a custom silicon partner! This makes Anthropic the only AI lab, alongside Google DeepMind, benefiting from tight hardware-software codesign.
Trainium’s roadmap: doubling down on systems
Amazon is rolling out a new system-level architecture for its anchor customer. Currently, the two systems deployed by AWS are Teton PD and Teton PD Ultra. Next year, the new Teton PDS and Teton Max are set to ship in large volumes. Our AI Accelerator Model provides the exact volumes and SKU-by-SKU breakdown on a quarterly basis.
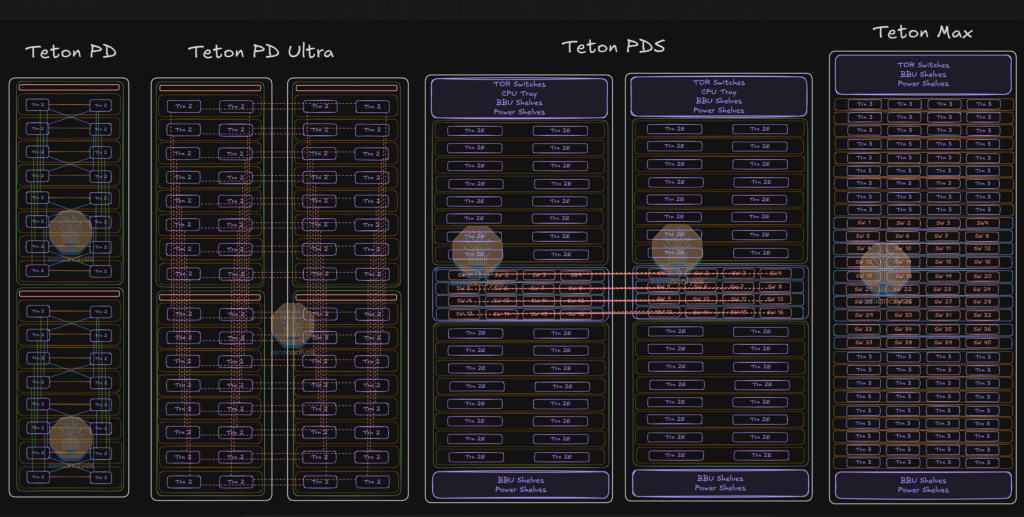
The key difference is the introduction of an all-to-all scale-up network dubbed NeuronLinkv3. Trainium’s architecture is thus converging towards Nvidia’s NVL72 NVLink.
Four NeuronLinkv3 switch trays will be placed in the middle of the rack with 16 compute trays above and below split evenly. Certain supply chain vendors are set to benefit disproportionately, as highlighted two months ago on Core Research – our institutional research service trusted by the world’s largest hedge funds. That vendor is up 73% since our post. We see the introduction of PDS as an intermediate step in Trainium’s path to catch up with Nvidia. We also believe that Anthropic was heavily involved in the launch of this new system-level architecture.
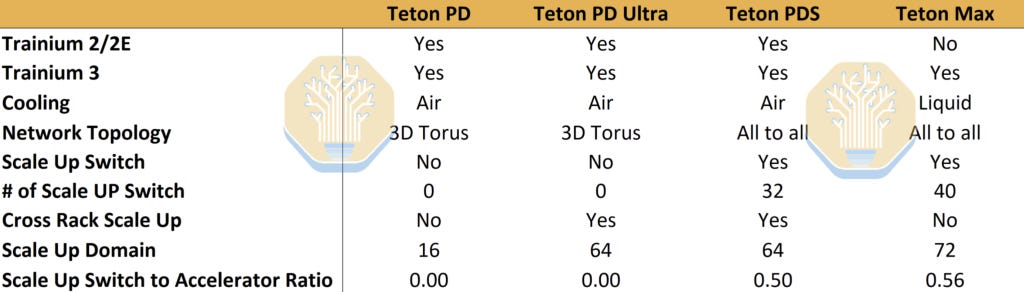
Anthropic’s increased involvement in design decisions bodes well for future volumes. But they’re not giving up on TPUs and Nvidia GPUs either. Our Accelerator Model forecasts Amazon and Google Cloud’s chip purchases broken down by precise SKU, and our Datacenter model to understand which datacenter and cloud partners support Anthropic’s ramp. The TPU ramp for Anthropic in 2026 is huge, and their are unique aspects to their deal as we have been posting about for over a month.
Let’s now take a longer-term view and evaluate what the future of AWS might look like. Behind paywall, we discuss the following items:
The outlook for Amazon’s key customer: Anthropic.
Amazon’s GenAI business beyond Anthropic: Bedrock and internal LLM efforts.
The Trainium ramp in 2026 & 2027, potential new external customers, and how it might impact Amazon’s financial profile in future years.
 |
|