

Amazon’s AI Self Sufficiency | Trainium2 Architecture & Networking
Trn2, Trn2-Ultra, Performance, Software, NeuronLinkv3, EFAv3, TCO, 3D Torus, Networking Costs, Supply Chain
Amazon is currently conducting one of the largest build-out of AI clusters globally, deploying a considerable number of Hopper and Blackwell GPUs. In addition to a massive Capex invested into Nvidia based clusters, AWS is also investing many billions’ dollars worth of capex into Trainium2 AI clusters. AWS is currently deploying a cluster with 400k Trainium2 chips for Anthropic called “Project Rainier”. Our industry leading Accelerator model has had the unit volumes, cost, specs, and many other details related to the gargantuan Amazon ramp with Marvell and others for close to a year now.
So far, Amazon’s Trainium1 and Inferentia2 based instances have not been competitive for GenAI frontier model training or inference due to weak hardware specs and poor software integration. With the release of Trainium2, Amazon has made a significant course correction and is on a path to eventually providing a competitive custom silicon in training and inference on the chip, system, and the software compiler/frameworks level.
To be clear, Amazon is still in crisis mode due to their internal models such as Titan and Olympus having failed. Furthermore, while they have firmly planted the flag as a distant second in the race for custom AI silicon, after Google, they are still heavily reliant on Nvidia capacity. Amazon’s Trainium2 is not a proven “training” chip, and most of the volumes will be in LLM inference. Amazon’s new $4 billion investment in Anthropic is effectively going to find its way back into the Project Rainier 400k Trainium2 cluster, and there are no other major customers yet.
AWS Trainium1 / Inferentia2 GenAI Weakness
In 2022, AWS released its Trainium1 and Inferentia2 chips. The Trainium1 chip and Inferentia2 chips are nearly the same, except that the Inferentia2 chip only has two Neuronlink-v2 interconnect ports vs the Trainium1’s four ports.
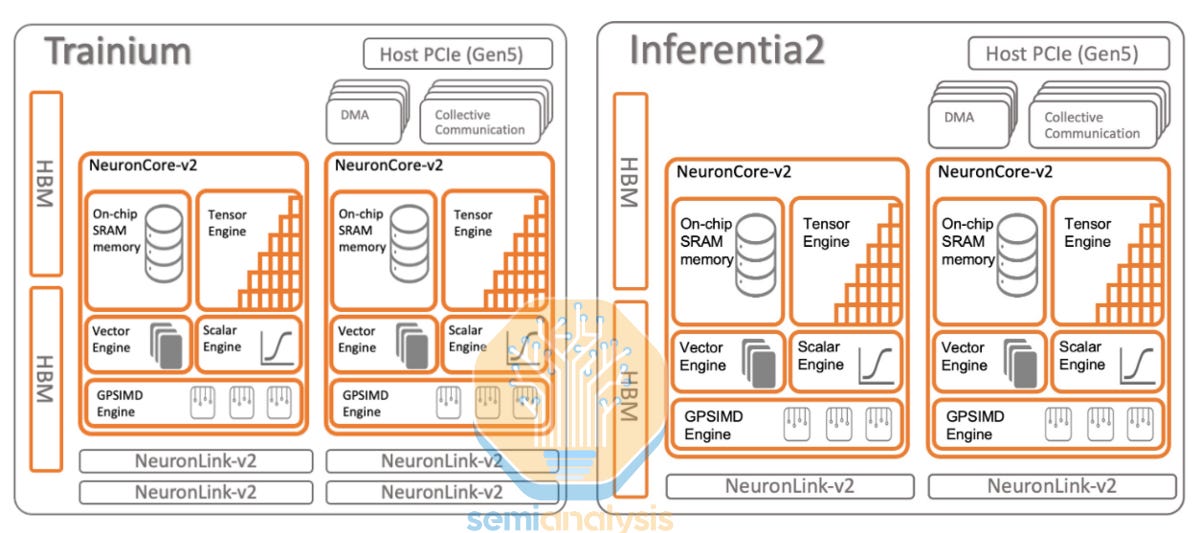
Trainium1/Inferentia2 has been underwhelming for GenAI training due to uncompetitive scale-up and scale-out networking, with many software bugs also detracting from customers’ workloads. As such, Trainium1/Inferentia2 has instead been used for training non-complex non-GenAI internal Amazon workloads such as credit card fraud detection AI models as well as for inferencing for Anthropic and Amazon internal workloads.
Ironically, Trainium1 is better for GenAI inferencing than training. Internally, Amazon has also been using Inferentia2 for inferencing such as on Prime Day 2024 with over 80k Inferentia2/Trainium1 chips being used to power an ML based assistant for Amazon helping Amazon.com prime members.
AWS Trainium2 Specifications Overview
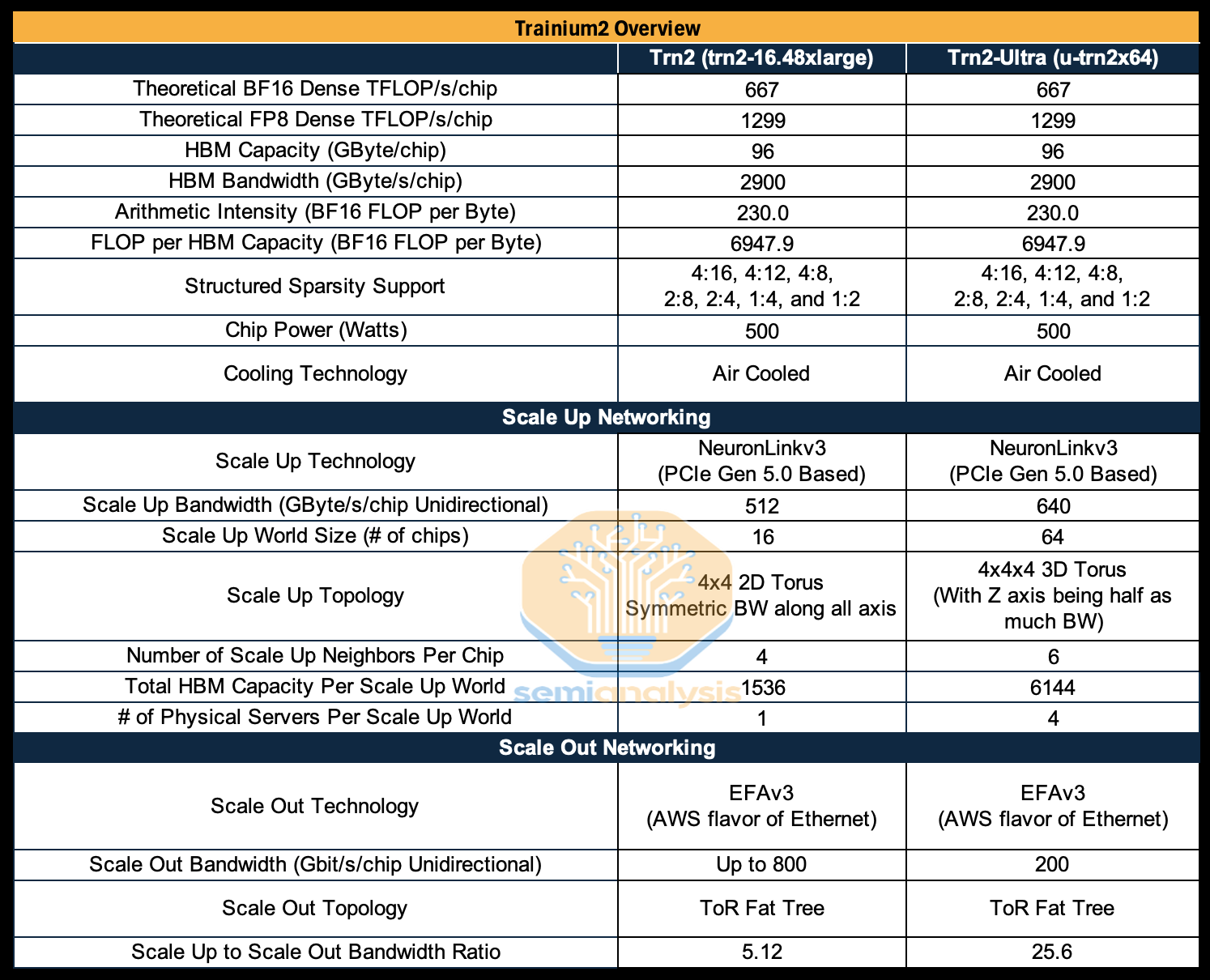
This all stands to change with Trainium2, as AWS is now firmly targeting complex GenAI LLM inferencing and training workloads with a ~500W chip that has 667 TFLOP/s per chip of a dense BF16 performance with 96GByte of HBM3e memory capacity.
Trn2 will use both HBM3 & HBM3e but all current SKUs have been set with to HBM3 speeds of 2.9TByte/s through firmware. In the future, AWS may make a custom SKU where chips with HBM3e will be 3.2TByte/s.
The other key advancement is in Trainium2’s scale-up network. Nvidia’s scale-up network is called NVLink and for the H100 it runs at 450Gbyte/s per GPU vs 50Gbyte/s for the InfiniBand scale-out network, Google TPU’s scale-up network is called ICI while AWS’s scale up network is called NeuronLink. All deployments of AI clusters that feature a scale-up network still use a back-end scale-out network. The high-bandwidth domain provided by the scale-up network used to implement parallelism schemes that require high bandwidth and low latency such as Tensor Parallelism, while the low-bandwidth domain of the scale-out network is used for other forms of parallelism such as data parallelism that are relatively less latency sensitive. Nvidia’s shift from 8-GPU NVLink domains to 72-GPU NVLink domains with its GB200 NVL72 is one of the most important drivers lowering the cost of inference for large models by ~14x because it enables a huge diversity of parallelism schemes that were not possible with a smaller scale-up network domain.
There are two SKUs of Trainium2, the first one which connects 16 Trainium2 chips together per server unit into a single scale up world size in a 4x4 2D torus while the second connects 64 Trainium2 chips per server unit (across two racks) together into a single scale up world size in a 4x4x4 3D torus called Trainium2-ultra. The Trainium2-ultra now provides an additional dimension of connectivity vs the Trainium1, which only featured a 4x4 2D torus. This extra dimension allows for tensor parallelism and activation sharding across the whole scale up domain.
Trainium2-ultra will be the primary SKU for GenAI frontier model training and inference for internal Amazon workloads and for Anthropic’s workloads. We will deep dive into the NeuronLink scale up network later in the article.
Comparison of Trainium2 to TPUv6e/GB200/H100
Trainium2’s scale-up topology is a 2D/3D torus for the 16-chip SKU/64-chip SKU meaning the Trainium2’s scale-up network is closer to a TPU-like topology (except that Trainium2 has a much smaller world size) than it is to an Nvidia NVLink topology. The key difference is that Trainium and TPU have point to point connections where as NVLink has Switches and enable all to all connectivity.
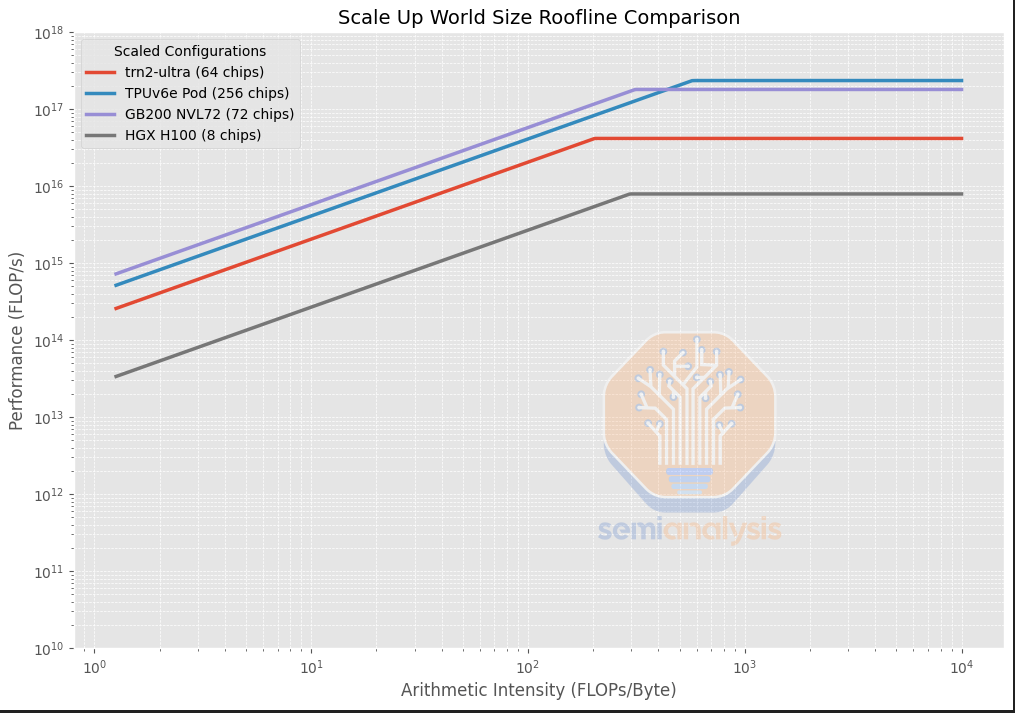
The main difference between the Trainium2 and the other accelerators is in its much lower Arithmetic Intensity at 225.9 BF16 FLOP per byte compared to TPUv6e/GB200/H100 which is targeting 300 to 560 BF16 FLOP per byte. Arithmetic Intensity is calculated by dividing the FLOP/s by the HBM Bandwidth in Byte/s and it indicates the ratio of compute throughput vs memory bandwidth. It is important to analyze as many applications such as inference are often bottlenecked by memory bandwidth, leaving compute FLOPS under utilized, so a different Arithmetic Intensity can indicate an accelerator is better suited to a particular task or technique – more on this later.
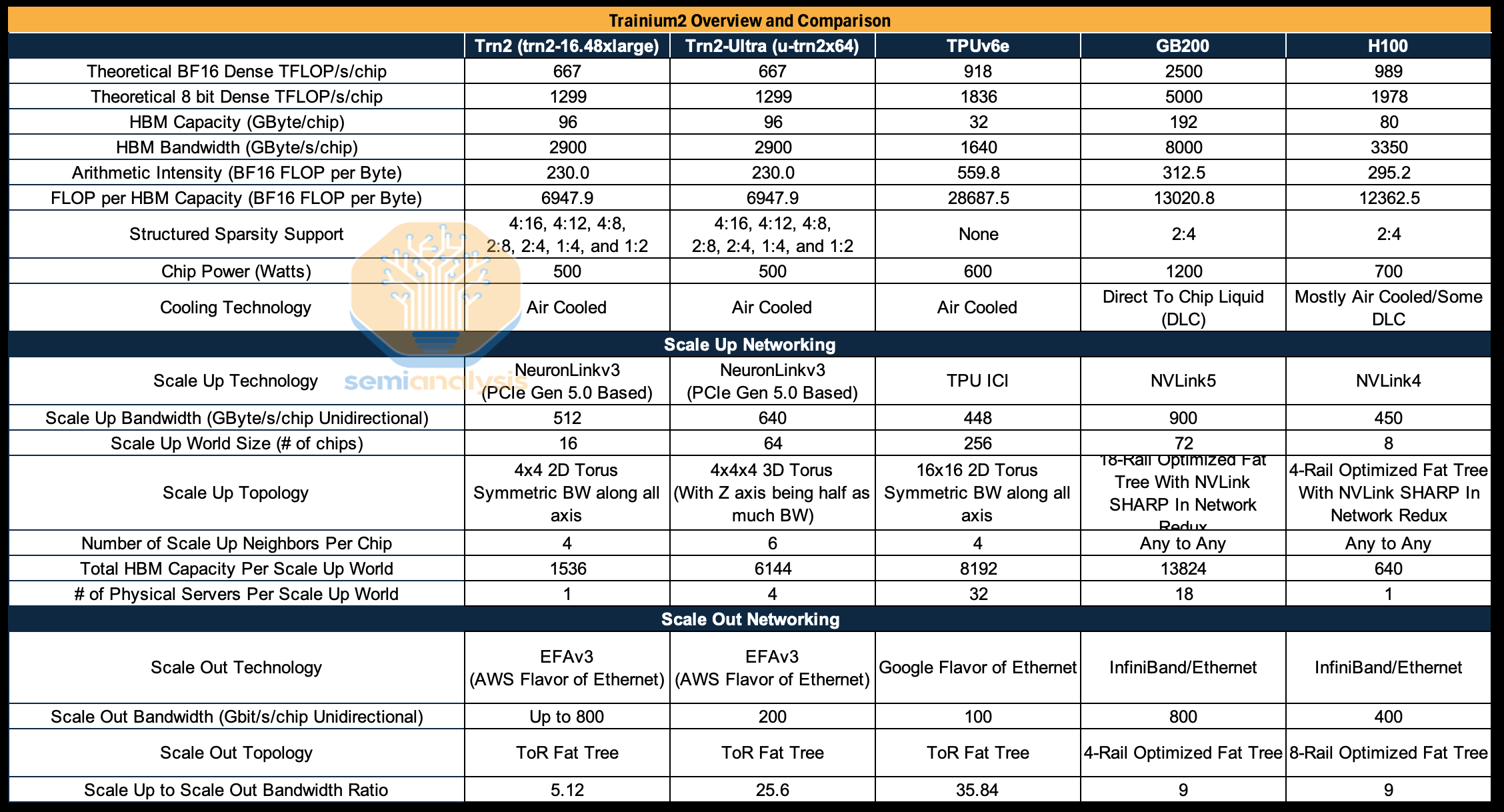
Designing the Trainium2 with a lower Arithmetic Intensity may be the right choice because models have had a slower growth of arithmetic intensity due to advances in ML research. Prominent examples include the quite popular Mixture of Experts (MoE), which uses Grouped GEMMs. In Grouped GEMMs, each token only gets routed to at most a couple of experts, thus the amount of memory needed to load the weights is much greater compared to dense feedforward networks (FFN) where each token “seen” does computation with each of the weights.
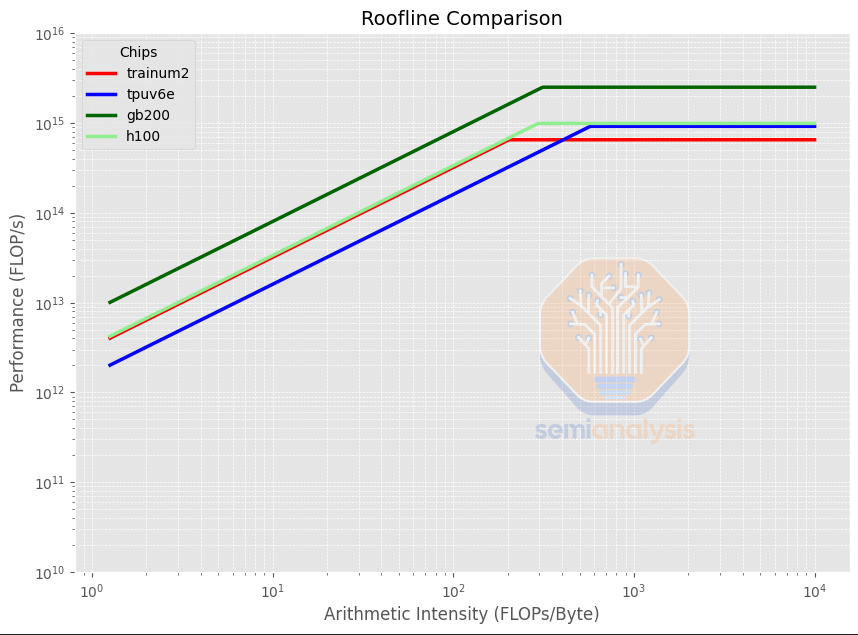
After normalizing by the number of chips in the scale-up domain, we can see that Trainium2 still has lower arithmetic intensity, but each scale-up world size (of 64 chips in the case of Trainium2-Ultra) has much lower aggregate peak FLOP/s due Trainium2’s smaller world size compared to the TPUv6e at a world size of 256 chips.
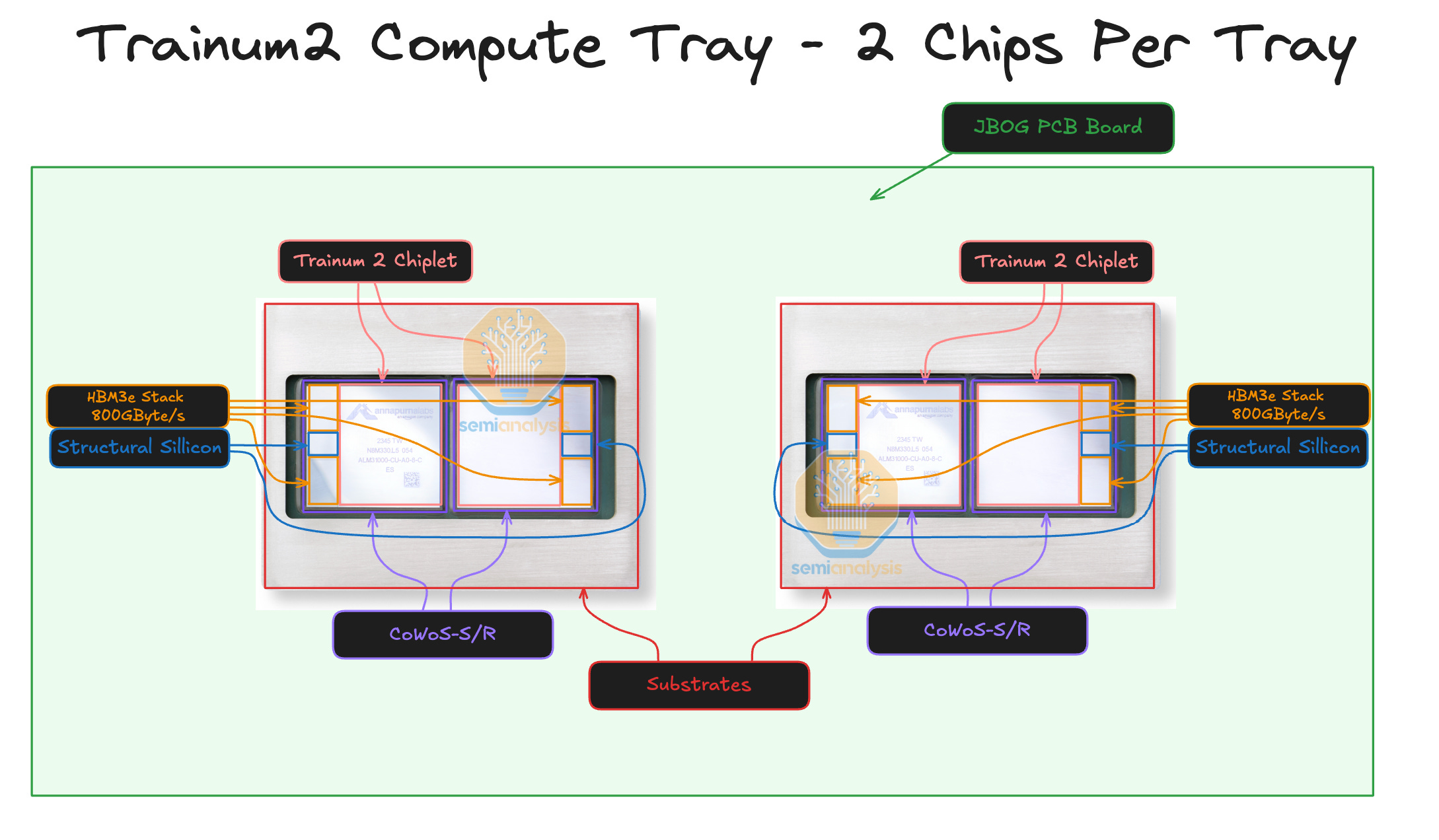
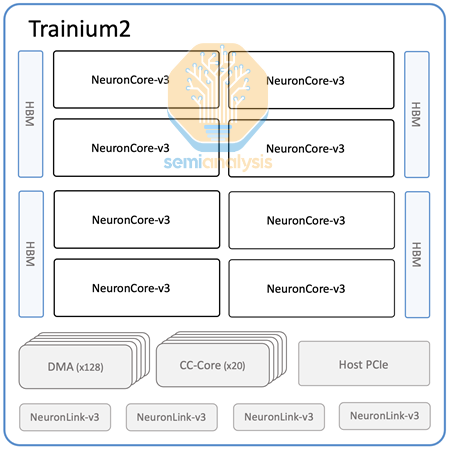
AWS Trainium2 Packaging
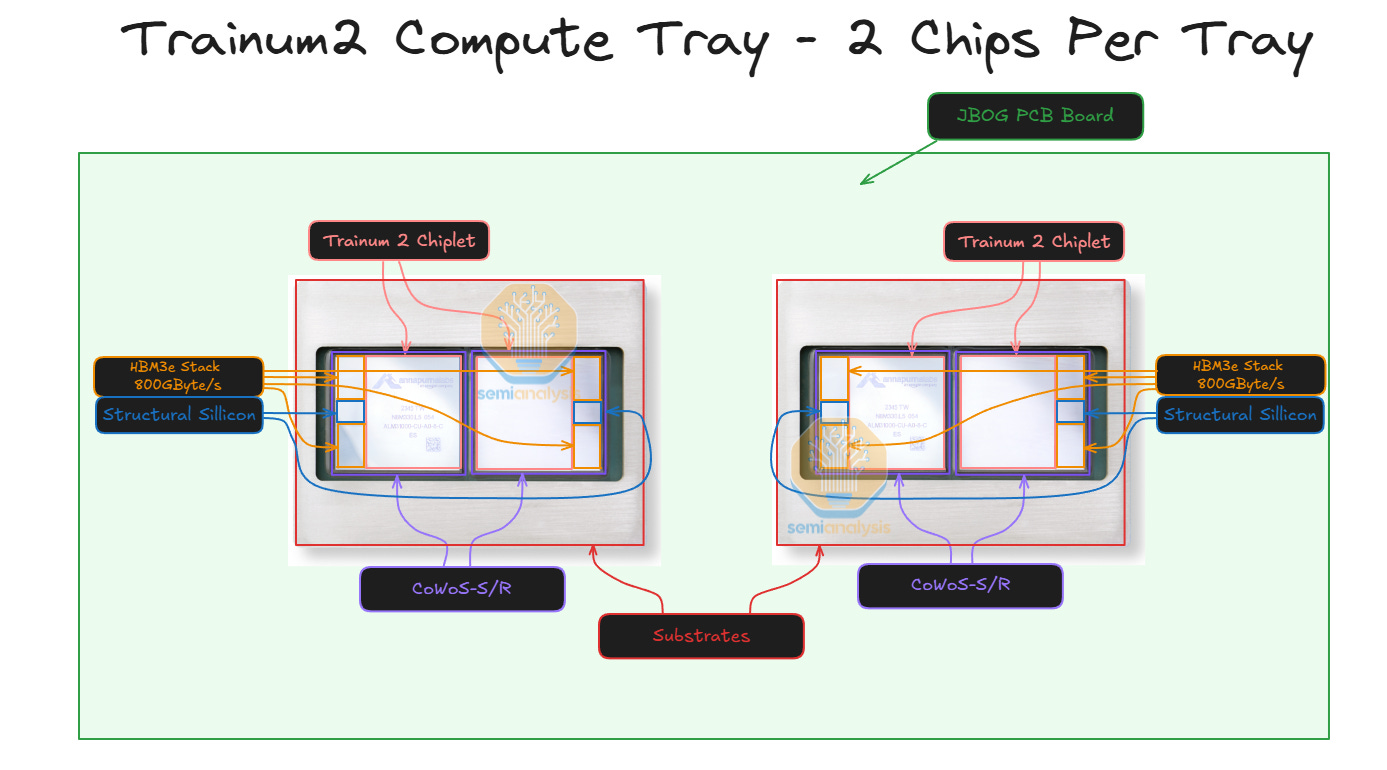
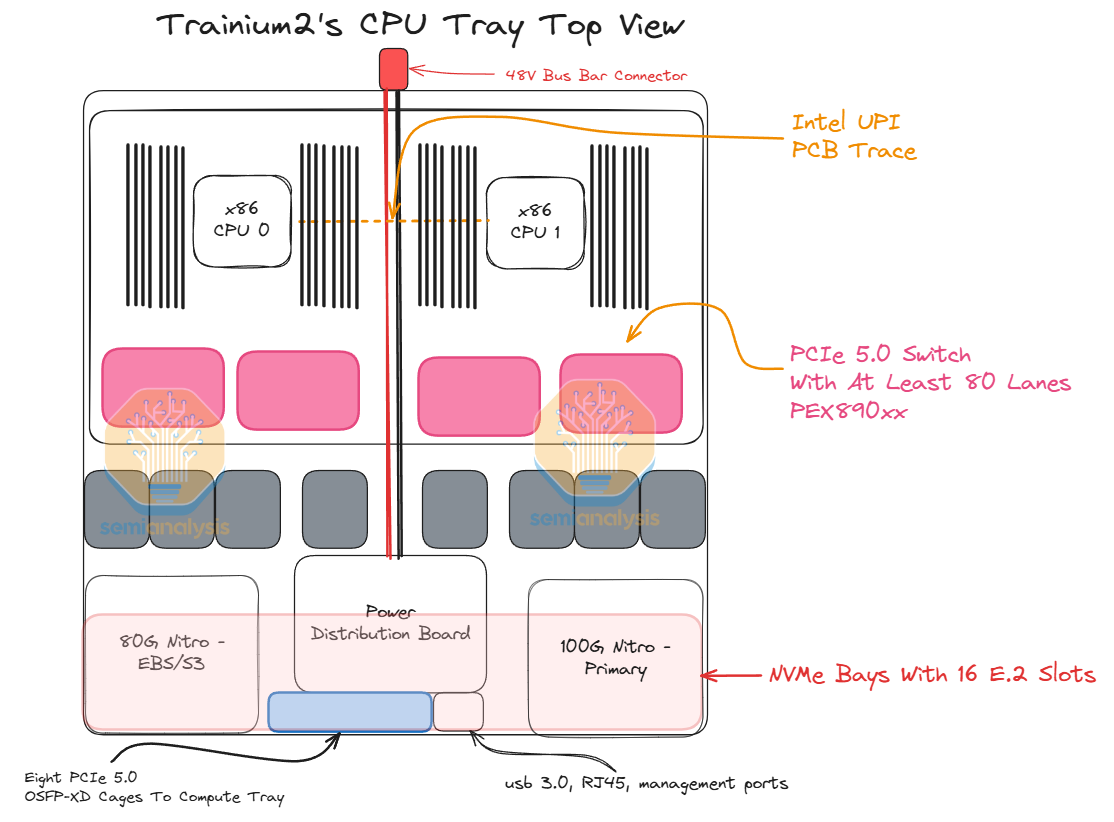
Each Trainium2 chip consists of two compute chiplets and four stacks of HBM3e memory. Each compute chiplet talks to its two immediate HBM3e stacks over CoWoS-S / R packaging, and the two halves of the chip connect to each other over an ABF substrate. There is a slight performance penalty when a compute chiplet tries to access the memory of non-immediately adjacent HBM stacks and that NUMA aware programming may be needed to achieve peak performance similar to that of MI300X chiplets. There are also two passive structural silicon dies.
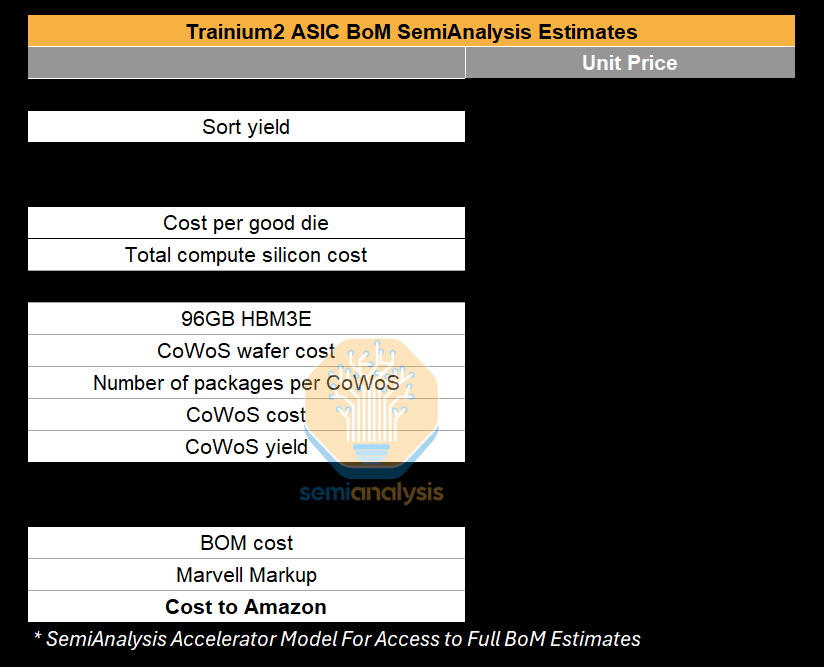
The SemiAnalysis Accelerator Model estimates all the associated cost per Trainium2 ASIC from the compute chiplet, HBM stack cost, to CoWoS packaging costs, etc.
AWS Trainium2 Microarchitecture
Just like on Trainium1 and Google TPUs, Trainium2 consists of a small number of large NeuronCores. This is in contrast to GPUs, which instead use a large number of smaller tensor cores. Large cores are typically better for GenAI workloads since they have less control overhead. On an H100 SXM, there are 528 tensor cores and on GB200, there are approximately 640 tensor cores. In each NeuronCore, there are four engines:
Tensor Engine
Vector Engine
Scalar Engine
GPSIMD
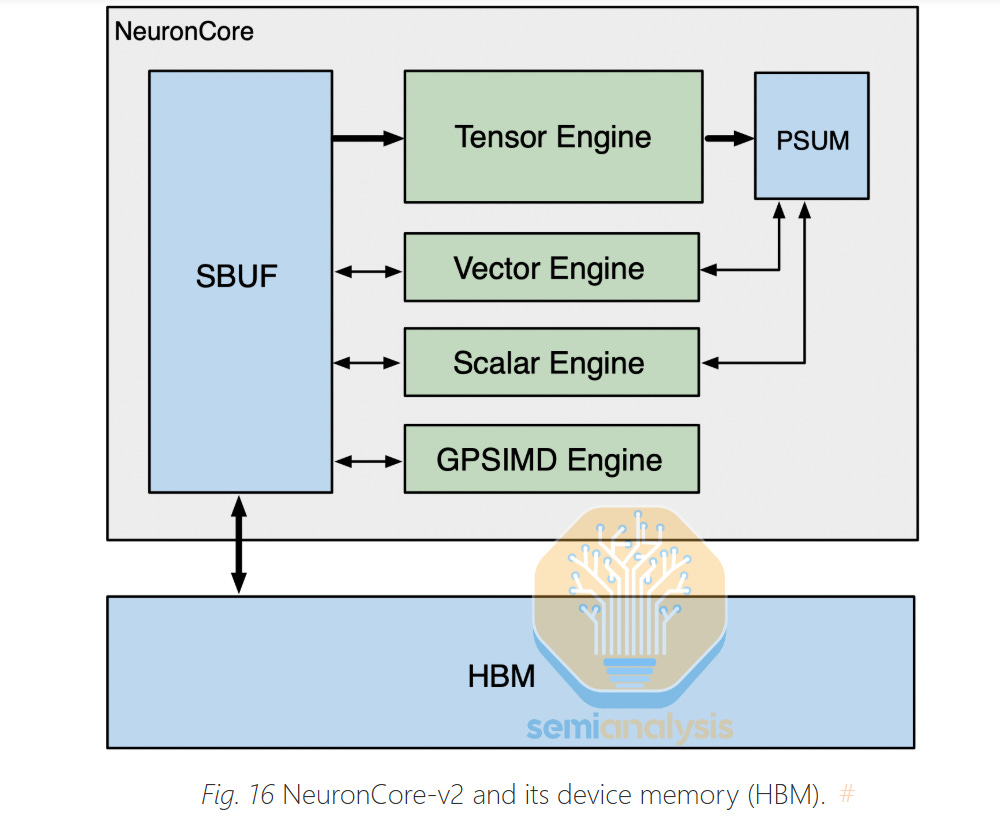
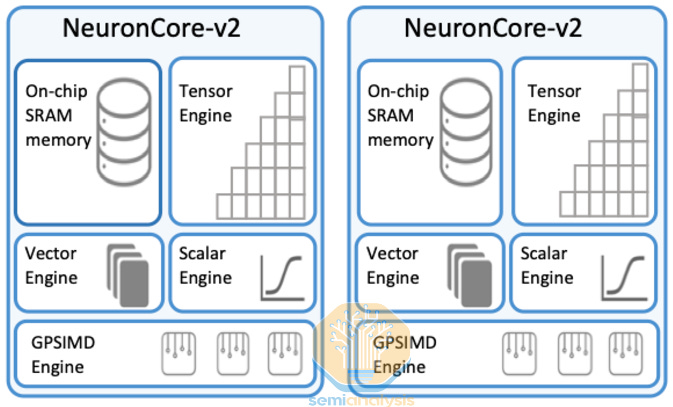
First is the Tensor Engine, which is a 128x128 Systolic Array that gathers its input from an SRAM buffer called “SBUF” and outputs its results into a partial sum SRAM buffer called “PSUM”. The tensor engine can loop over the K dimension of a matrix multiplication (matmul) and add up the partial sum of each result to get the complete result. The Tensor Engine / systolic array is where > 80% of the power and FLOPS of modern LLM workloads will be put towards.
Next is the Vector Engine, which is designed to accelerate vector operations – operations where each output element depends on multiple input elements, for example when calculating softmax in the attention layer or calculating moving averages and variance in layer/batch normalization layers. The NeuronCore Scheduler can parallelize such that all the engines are all working at the same time. For example in attention, the vector engine can be calculating the softmax for the current tile at the same time while the systolic array can be calculating the QxK^T matmul or the AxV matmul.

Third is the Scalar Engine, which is designed to do operations with a 1:1 mapping such as element wise operations like SeLU, or Exp or adding bias at the end of a Linear layer.
Lastly, inside the NeuronCore, there are multiple Turing-complete GpSimd Engines that can run any arbitrary C++ such that is easy for any C++ developer quickly run custom ops. For example, where a GpSimd Engine is used in a self-attention layer in which you need to apply a triangular mask so that the current token can see any future tokens and can only see the current and past tokens. However, it’s possible that with the Block Sparse Attention which was popularized by Tri Dao with Flash-Attention and Horace He with FlexAttention, over time, applying the triangular mask will be less important.
Furthermore, just like in Trainium1, with Trainium2, there are dedicated collective communication cores solely devoted to communicating with other chips. This is an excellent innovation as it allows for compute-communication overlapping without any contention between compute resources and communication resources.
In contrast, on Nvidia as well as AMD GPUs, communication operations run on the same cores (SMs) as the compute operations. Thus, the end user needs to carefully balance the ratio of SMs running communication ops with the SMs running compute ops. On GPUs, this is done using the “NCCL_MIN_NCHANNELS” env flag and is in practice a fairly complex tuning.
Due to this complexity, only the most advanced users will be doing comms/compute SMs ratio tuning. Furthermore, executing communication operations often decreases the L2 cache hint rate of the SMs running the compute operations. Thus, Nvidia PTX provides cache hints such that the collective communication kernel engineer can tell the GPU to skip storing their elements inside the L2 cache.
Overall, we believe that having dedicated collective-communication cores is a much cleaner design for optimizing communication-compute overlapping.
While having all these specialized engines may seem like a great idea due to specialized resources consuming less power and area versus generalized resources, it can also lead to bottlenecks. The ratio of various specialized resources must be chosen well ahead of time and this leads to the potential of that balance being wrong for various different workloads. Certain resources will always be underutilized, and other resources will always be capping the performance. In some ways, specializing your architecture too early while workloads are still evolving could be a risky decision.
Server Architecture
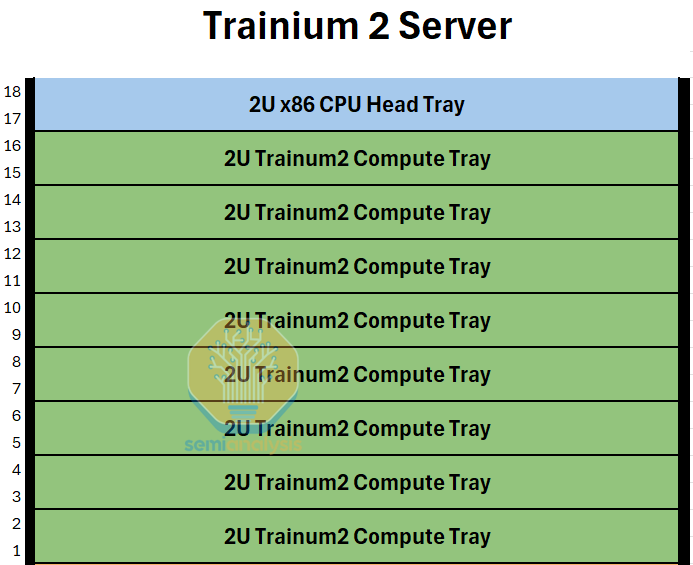
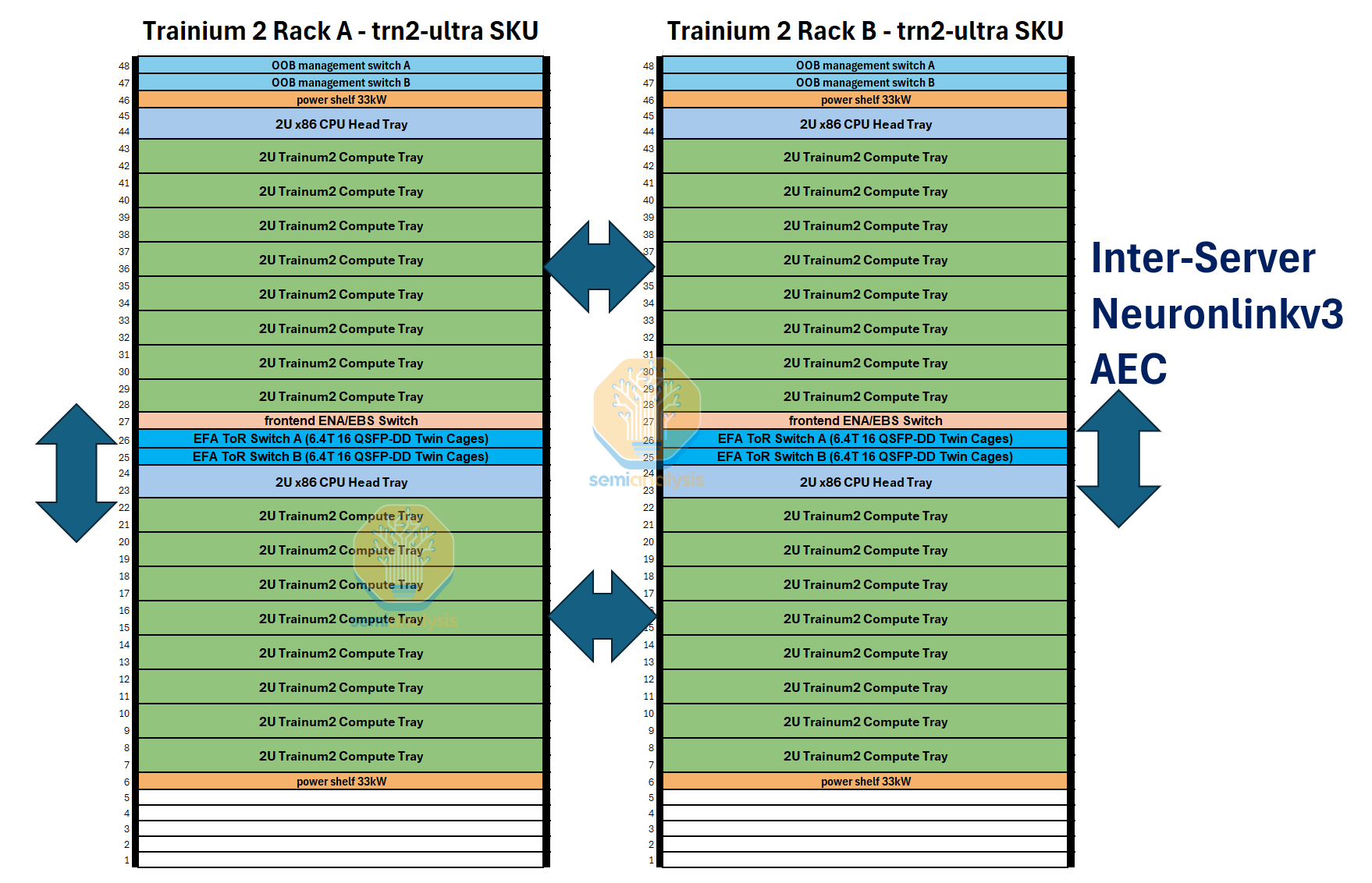
The building block of the Trainium2 and Trainium2-Ultra servers is what we refer to as a Trainium2 “Physical Server”. Each Trainium2 physical server has a unique architecture taking up 18 Rack Units (RUs) and consists of one 2 Rack Unit (2U) CPU head tray that is connected to eight 2U compute trays. On the rear side of the server, all of the compute trays connect together into a 4x4 2D torus using a passive copper backplane similar to GB200 NVL36, except while for the GB200 NVL36, the backplane connects each GPU to a number of NVSwitches, on Trainium2, there are no switches used and all connections are only point to point connections between two accelerators.
Each 2U compute tray has two Trainium chips and no CPUs. This differs from the GB200 NVL72 architecture, where each compute tray has both CPUs and GPUs in the same tray. Each Trainium2 compute tray is also commonly referred to as a JBOG, “just a bunch of GPUs”, since each compute tray does not have any CPUs and cannot operate independently.
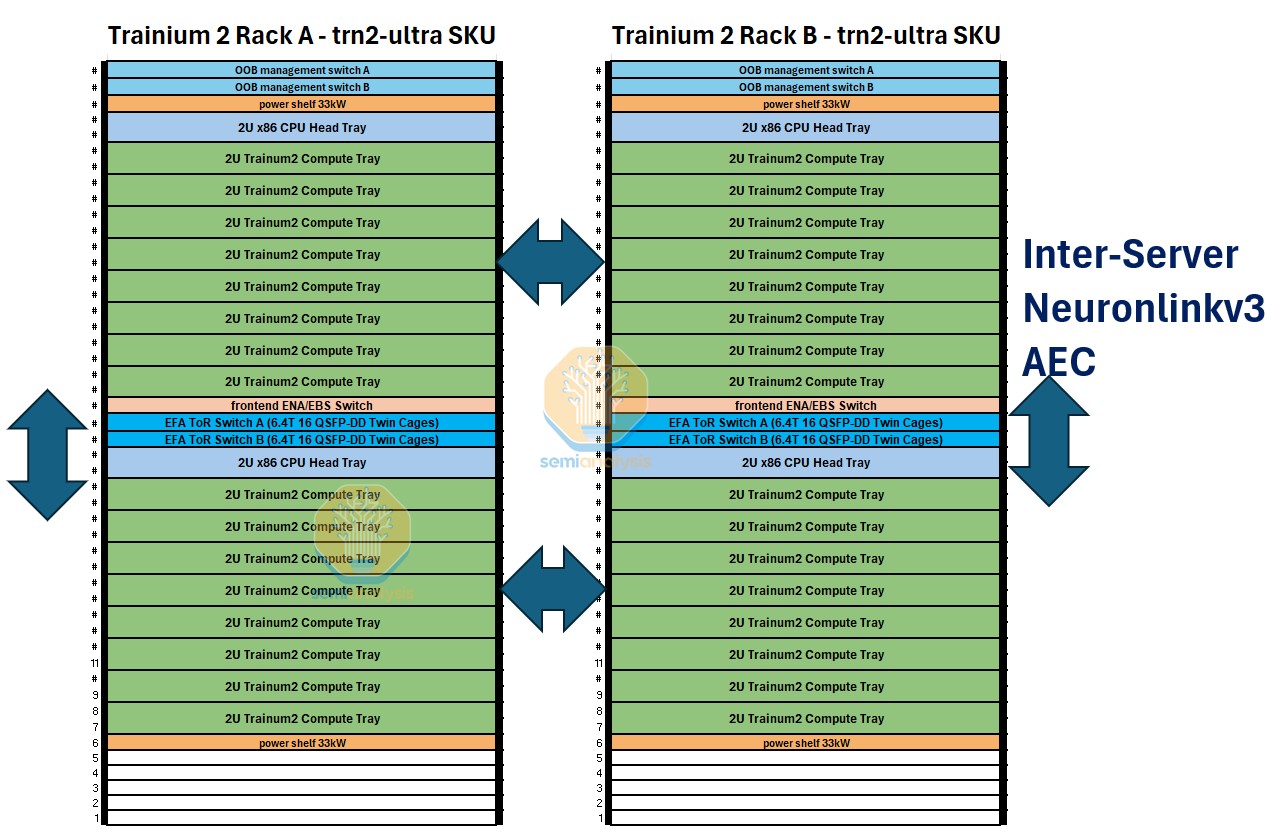
Each Trainium2 server thus holds 16 Trainium2 chips. Two 16-Chip Trainium2 servers fit into one rack. For the Trainium2-Ultra SKU, each server is made up of four Physical Servers of 16 Chips each, and thus will hold 64 chips in total and will take up two whole racks. We will describe the rack layouts in more detail and provide elevation diagrams below.
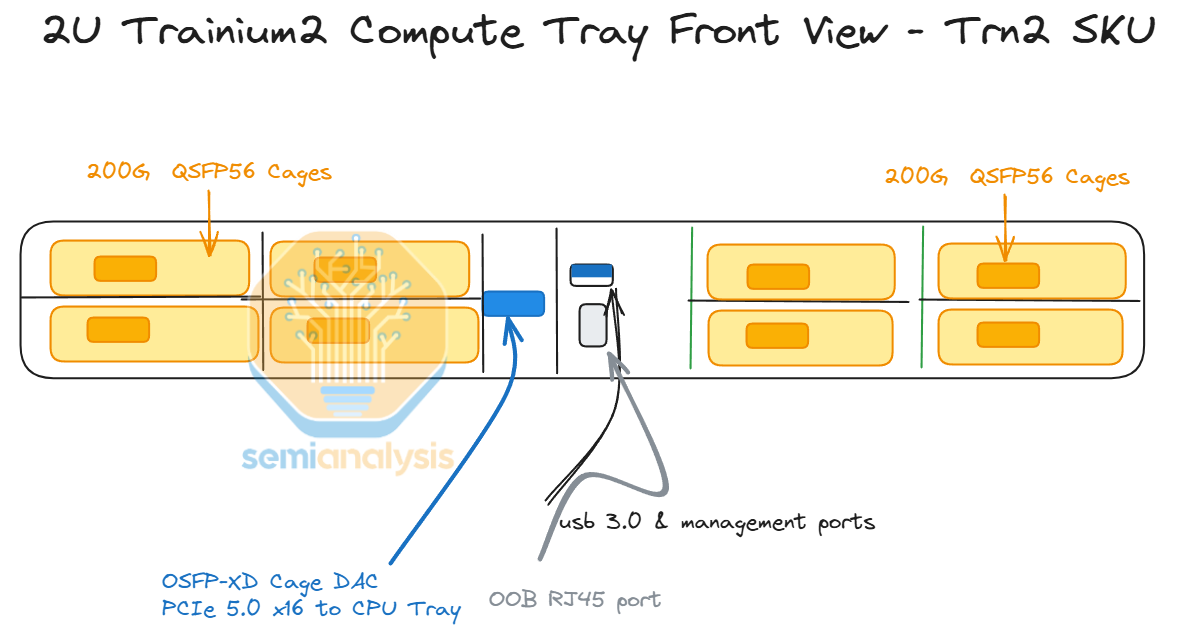
Each compute tray connects to the CPU tray via an external PCIe 5.0 x16 DAC passive copper cable on the front of the server.
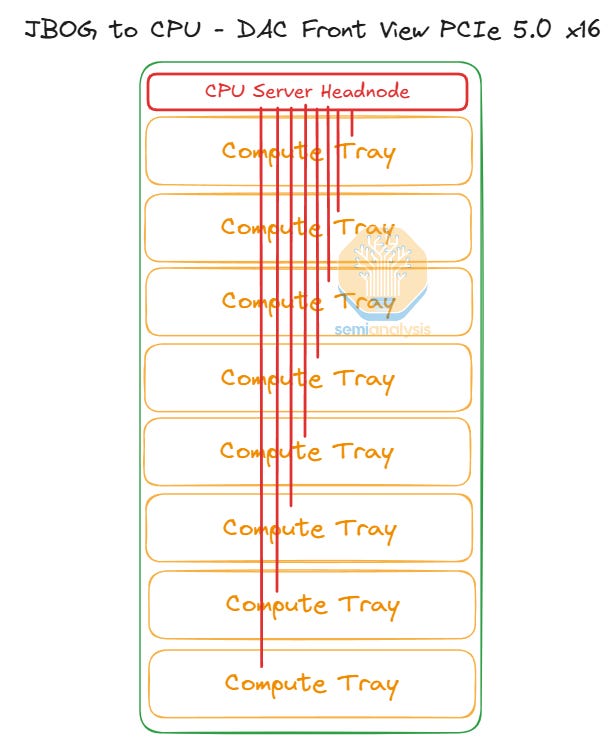
CPU Tray
Inside the CPU tray, there are PCIe switches that connect the compute trays with local NVMe disks such that the Trainium2 can access storage using GPUDirect-Storage without needing to go through the CPU.
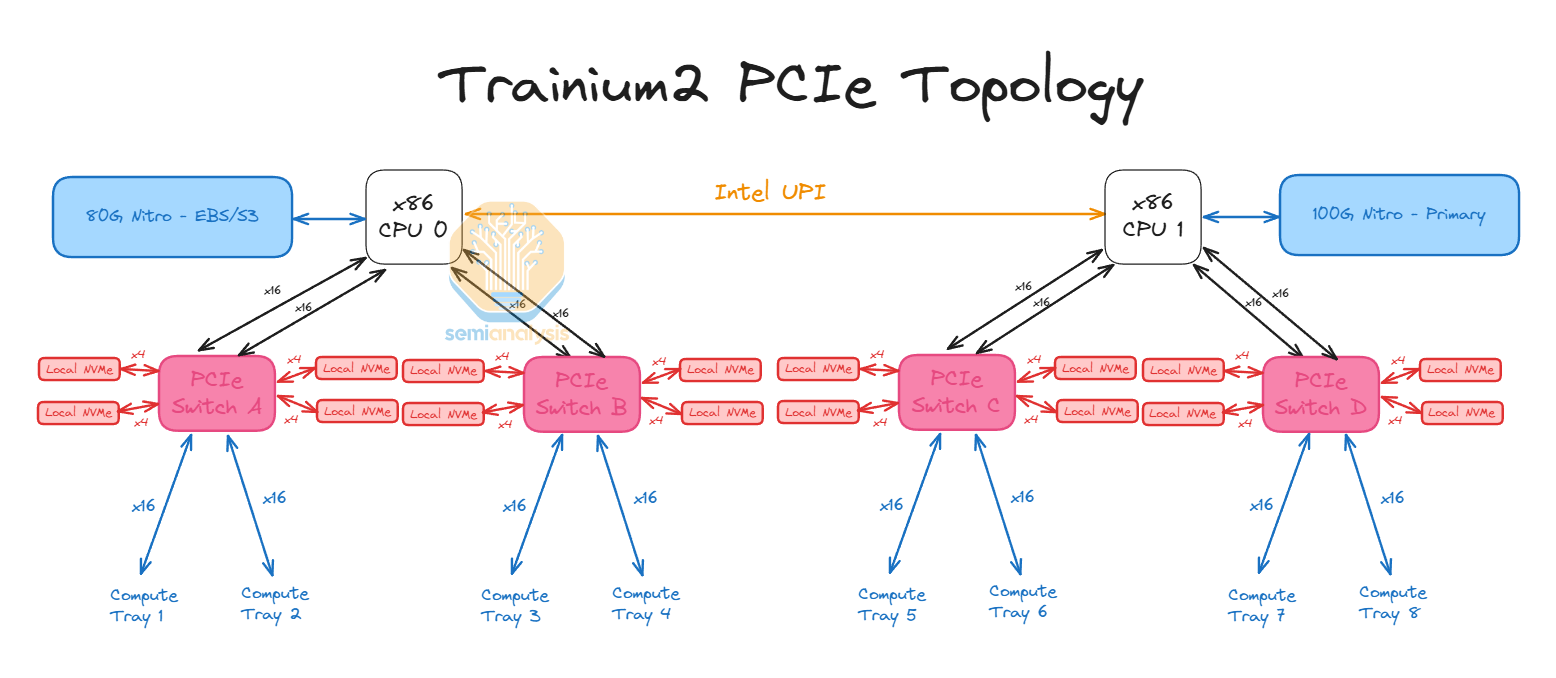
There are a total of 16 local NVMe per server and they are all directly accessible by the Trainium2 chips. Furthermore, there is the standard 80Gbit/s Elastic Block Storage link that is attached to the Primary CPU0 and a Primary 100Gbit/s Nitro card for the AWS frontend network called Elastic Network Adapter (ENA).
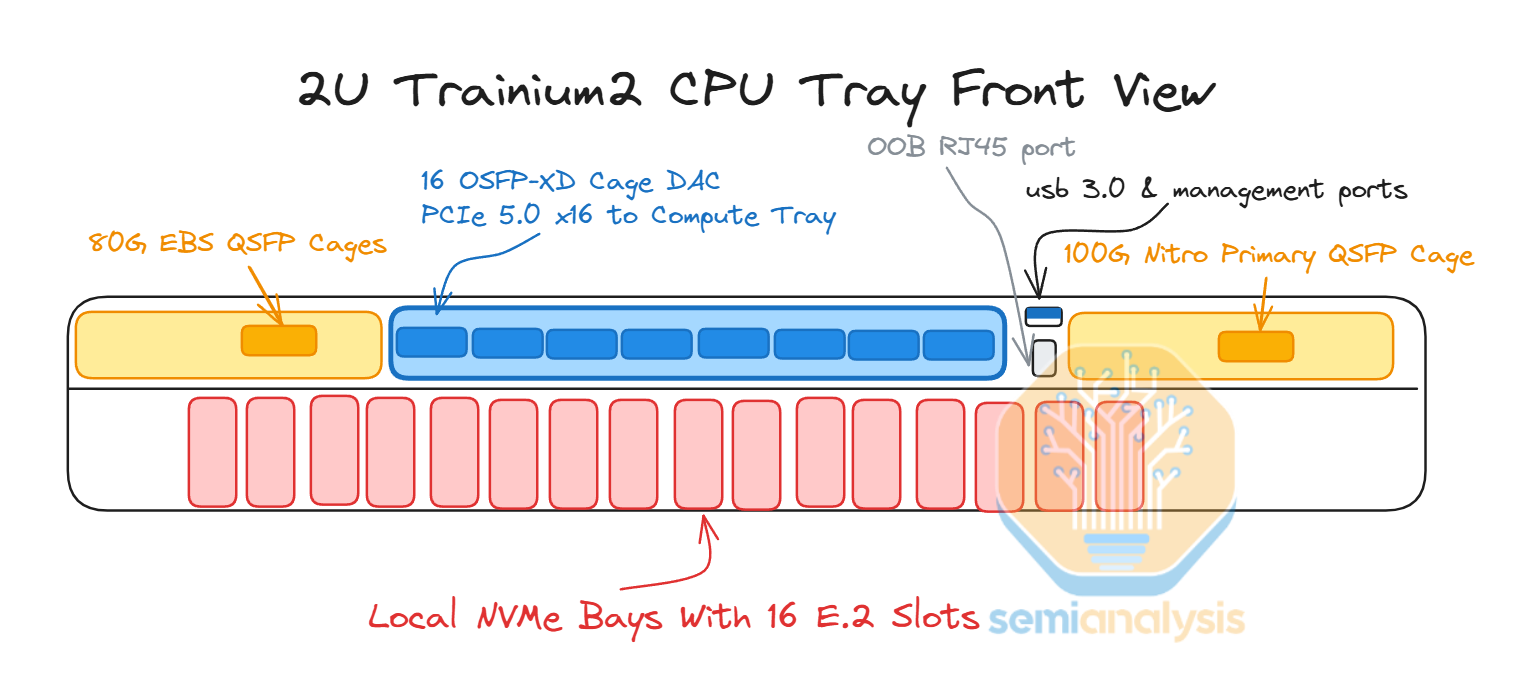
Each CPU tray consists of two Intel Xeon Sapphire Rapids CPUs and 32 DIMM slots for DDR5 RAM allowing for up to 2 TBs of CPU memory and uses a similar rack level 48V DC bus bar power distribution system.
Compute Tray
As mentioned in the beginning of the article, there is are two SKUs
Trainium2 (Trn2)
Trainium2-Ultra (Trn2-Ultra)
We will first talk about the compute tray for the normal Trn2 Trainium2 instance. Each Trn2 compute tray has two Trainium2 chips on a PCB and has 6 intra-server scale-up copper backplane connectors to connect to other compute trays in the same server.
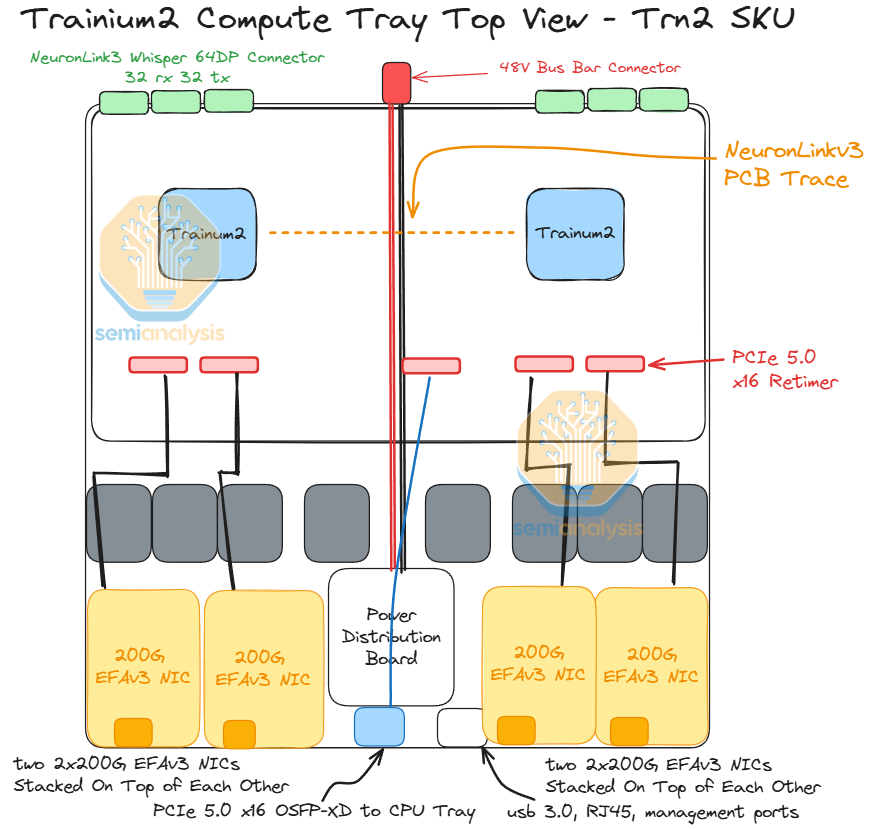
In addition, for the Trn2, each compute tray has up to eight 200G EFAv3 NICs which provide up to 800Gbit/s per chip of scale-out ethernet networking. The cage that connects from the compute tray to the CPU tray will also require a retimer. The Trainium2 chip on the left side of the compute tray will use the first 8 lanes of the connection to the CPU tray while the Trainium2 chip on the right side will use the last 8 lanes of the connection to the CPU tray.
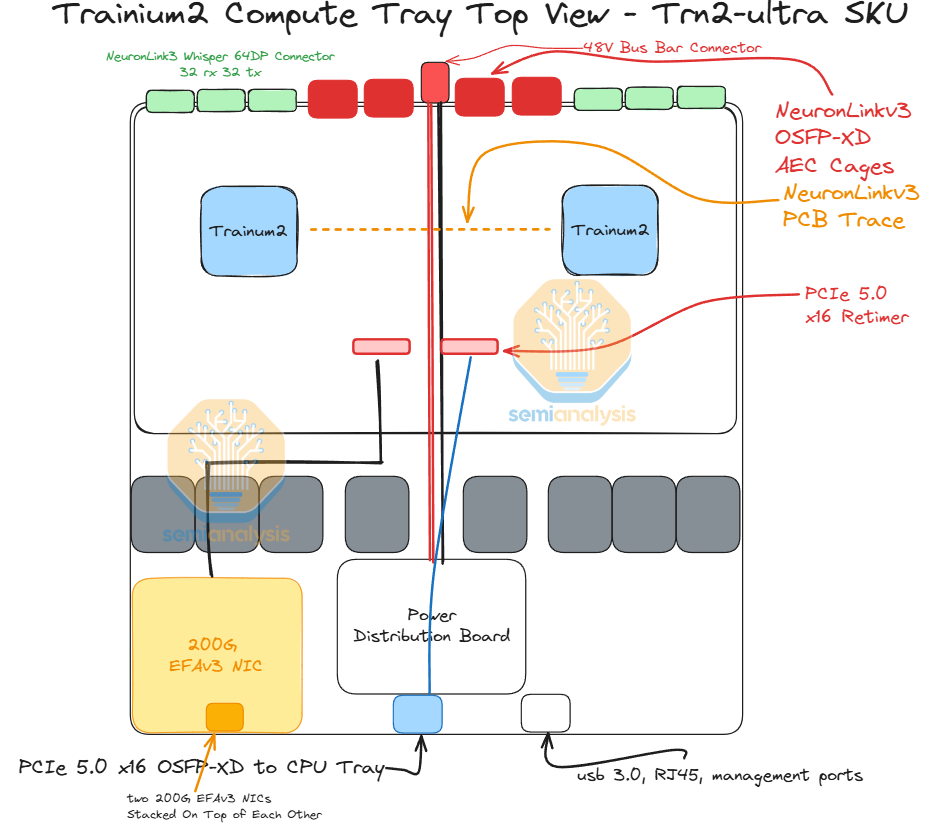
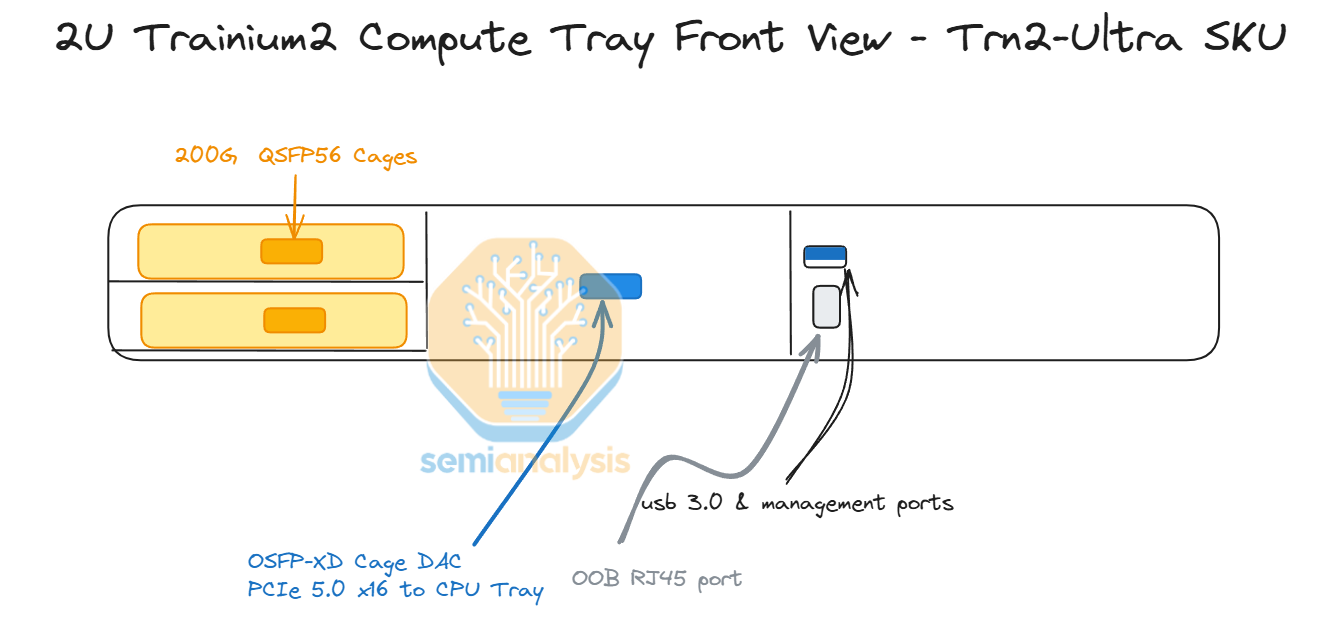
The Trn2-Ultra SKU is very similar to the normal Trn2 SKU, but instead fewer PCIe SerDes lanes on the Trainium2 chip are used for the scale-out network, with only 200Gbit/s scale-out bandwidth for the Trn2-Ultra chips vs the 800Gbit/s for the Trn2. These lanes are instead used to inter-connect 4 physical servers (of 16 chips each) together into a scale-up world size of 64. The scale-up network will be implemented with each chip having two 16-lane OSFP-XD cages into which active electrical copper cables will plug to connect four physical servers of 16 chips each together to make the Trn2-Ultra server with world size of 64 chips.
System/Rack Architecture
Moving on to the system/rack architecture, we will first discuss the normal Trn2 SKU. Each rack will consider of two Trn2 servers and four 12.8T ToR EFAv3 ethernet switches to provide up to 800Gbit/s of scale-out bandwidth per chip. This rack uses a similar 48V DC busbar architecture with AC to DC conversion happening at the rack level instead of each chassis performing the conversion individually.
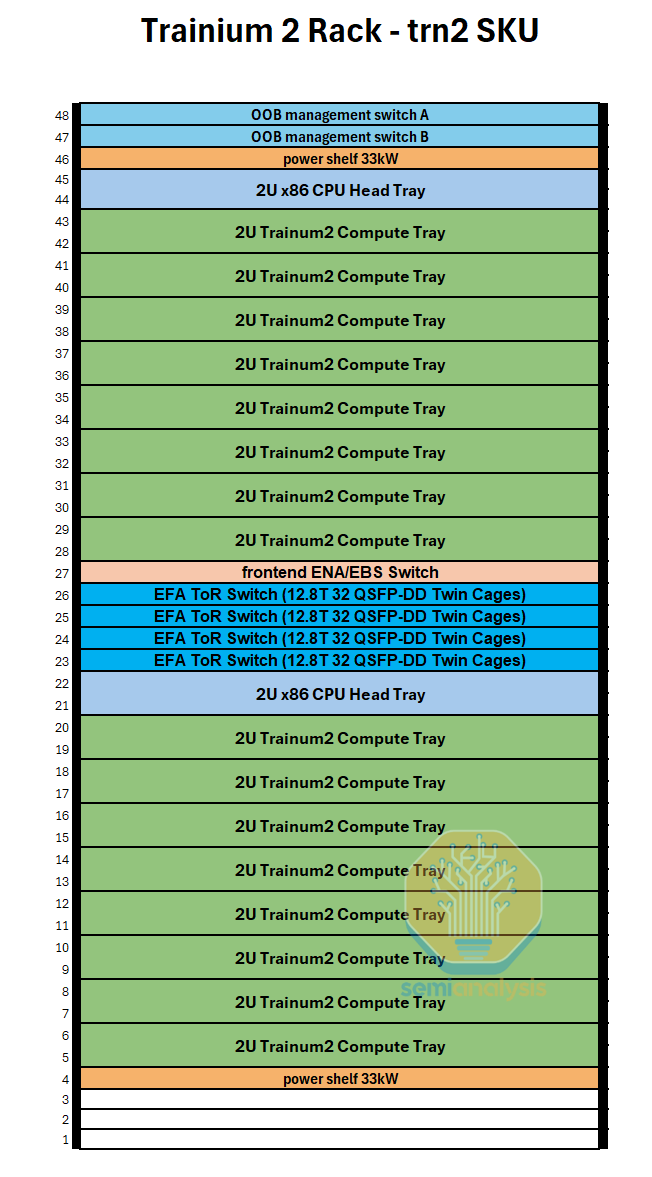
The Trn2-Ultra SKU, which consists of four 16-Chip Physical Servers per scale up domain and thus 64 chips per scale up domain, is made up of two racks in a configuration similar to that of the GB200 NVL36x2. To form a torus along the z-axis, each Physical Server connects to two other Physical Servers using a set of active electrical copper cables.
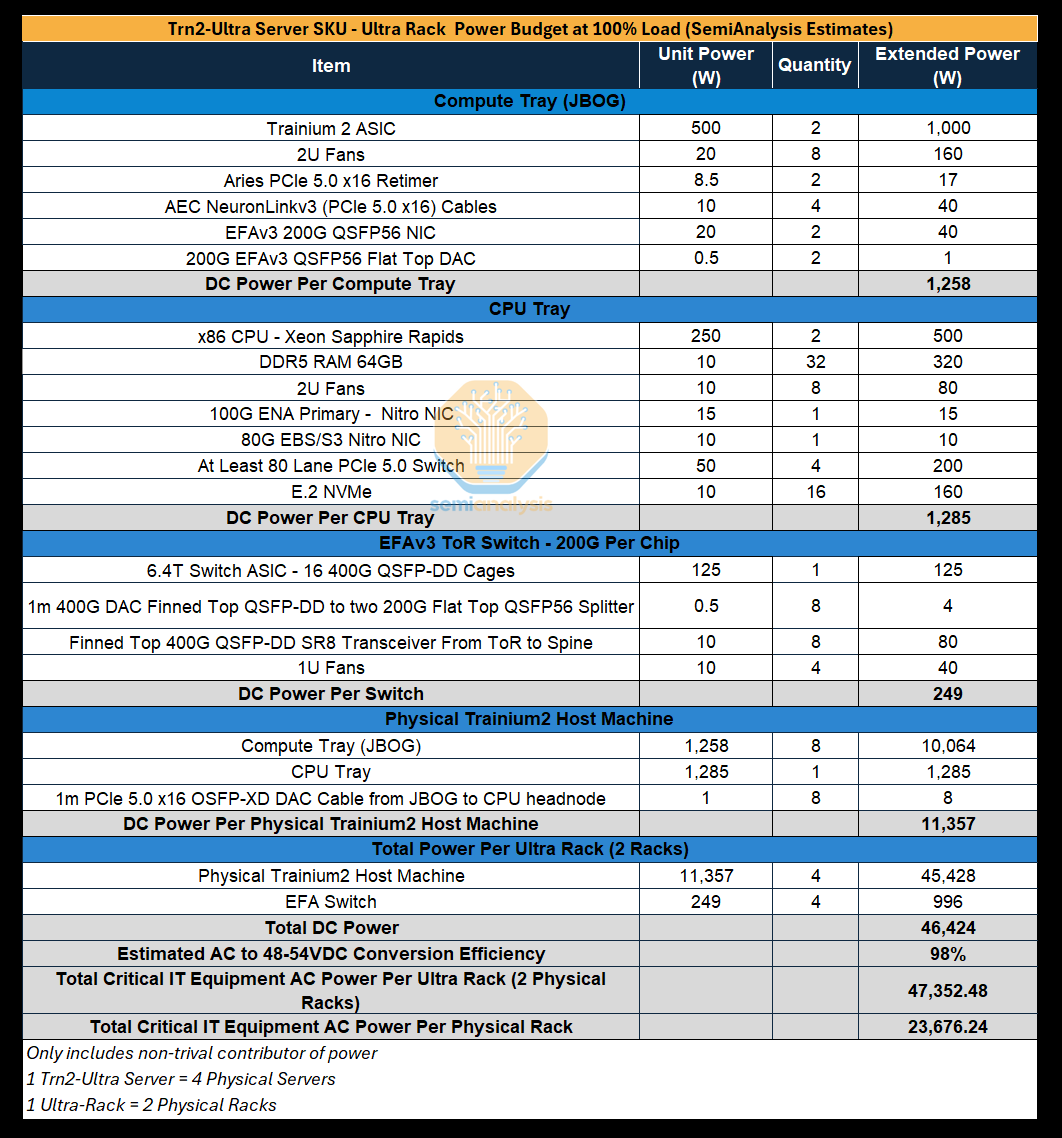
Power Budget
We estimate the rack power of each SKU, with each of the two racks within a Trn2-Ultra 64-Chip server requiring 24kW of power (48kW per Trn2-Ultra 64-Chip server).
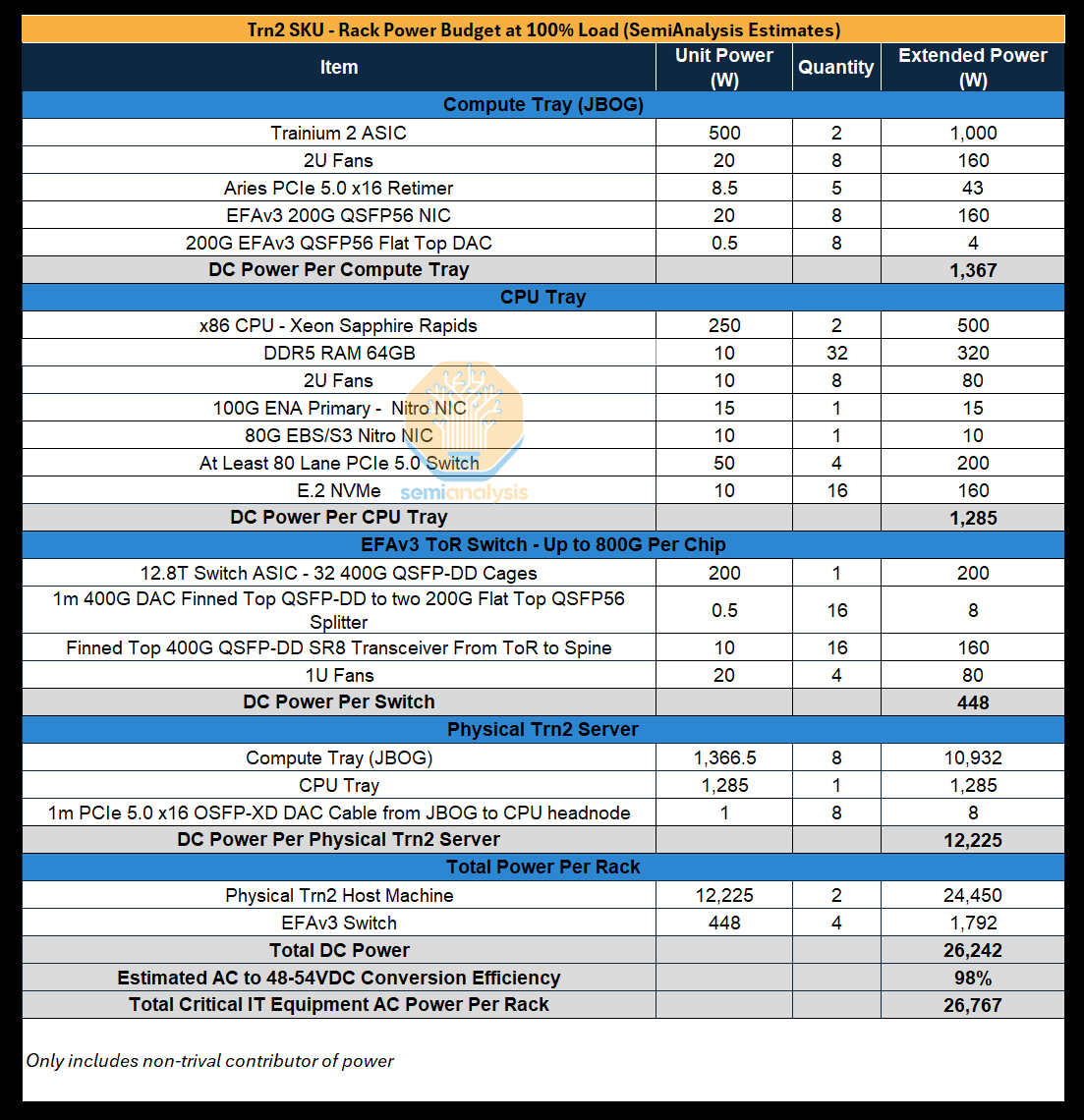
Racks used to house the normal Trn2 server will have a rack density of 27kW, but recall that there will be two 16-Chip Trn2 servers housed in one rack. The higher power density of racks housing the Trn2 server is due to the additional NICs and the use of more and higher radix ToR switches needed to support up to 800Gbit/s per Trainium2 chip of scale-out networking, which takes up more power when compared to the additional inter-server AEC NeuronLinkv3 cables of the Trn2-Ultra Server.
Project Rainier – 400k Trainium2 Cluster
We believe that one of the largest Trainium2 cluster deployments will be in Indiana. Here, AWS is currently deploying a cluster with 400k Trainium2 chips for Anthropic called “Project Rainier”.
This campus has completed construction of its first phase and there are currently seven buildings, each with 65MW of IT power, totaling 455MWs. Phase 2 of this Indiana AWS campus will add nine more 65MW buildings for a total of 1,040MW of power. We believe that the PUE for this campus is around 1.10-1.15 as the campus is located in northern Indiana. In addition to Trainium2 deployments, this datacenter campus will be shared with AWS’s traditional CPU oriented servers but as well AWS’s Blackwell cluster deployments.

We believe that AWS will deploy Trainium2 racks in containment pods of 16 racks with 4 additional racks at the end for networking switches, management switches and other servers co-located within the containment pod. Cool air will move through the front of the server while the rear of the server will blast the hot air out into a chimney.
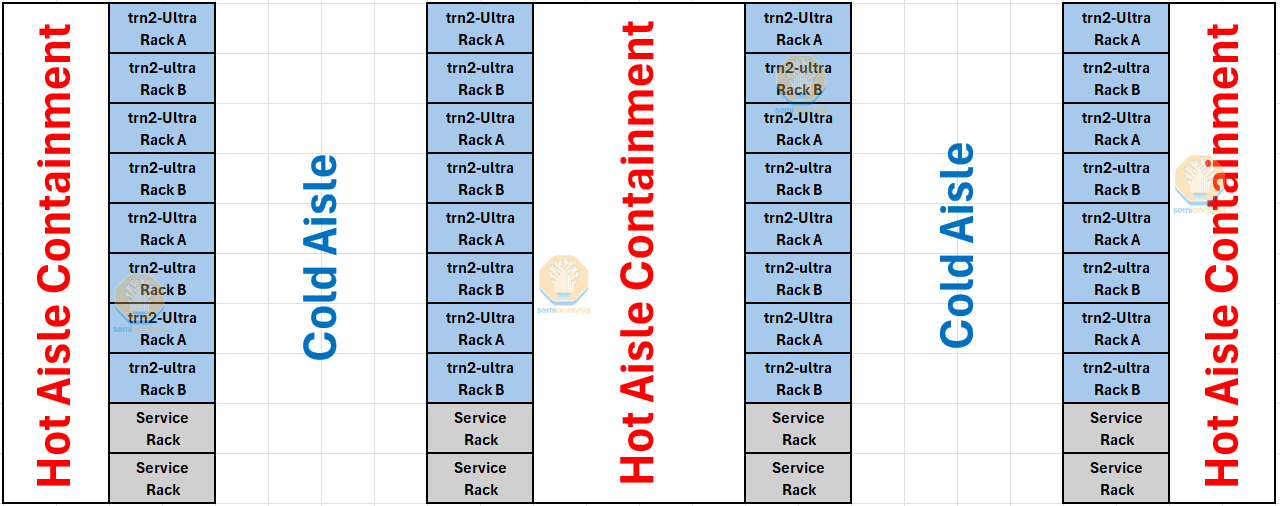
Note that 400k Trainium2 is less raw flops then a 100k GB200 cluster. This means that Anthropic will have a hard time matching the competing 100k GB200 clusters given Amdahl's law can eat their lunch. Doing all reduce across 400k Trainium2 and EFA will be difficult so Anthropic will need to innovate some pretty big advances in asynchronous training.
Networking Overview
We have mentioned and discussed various pieces of the networking puzzle above, but this section will be dedicated to a comprehensive explanation of all the networks in use with the Trainium2 architectures.
There are four different types of networking on a Trainium2 based instance:
Scale-up: NeuronLinkv3
Intra-Server NeuronLinkv3
Inter-Server NeuronLinkv3
Scale-out: Elastic Fabric Adaptor EFAv3
Front-end and Storage: Elastic Network Adaptor (ENA), Elastic Block Store (EBS)
Out of Band Management Networking
NeuronLinkv3 is a scale up network which is AWS equivalent of Nvidia’s NVLink interconnect. Unlike Nvidia’s NVLink interconnect, NeuronLinkv3 is divided into two types, intra-server and inter-server. The intra-server will connect the 16 chips within each Physical Server together while the inter-server NeuronLink will connect chips from different Physical Servers together for a total world size of 64 chips. Each chip will have 640GByte/s of unidirectional Bandwidth with up to 6 immediate neighbors.
In contrast to the limited 64 chip world size of NeuronLinkv3, the EFAv3 backend/compute fabric is used to scale out communications from tens of racks to thousands of racks. Even though EFAv3 can connect way more chips together, the downside is that it is much slower than the NeuronLink network. On Trn2 SKU, the EFAv3 fabric is 6.4x slower and on Trn2-Ultra SKU, the EFAv3 fabric is 25.6x slower.
As a quick refresher, the frontend network is simply a normal ethernet network that is used to connect to the internet, SLURM/Kubernetes, and to networked storage for loading training data and model checkpoints. Per physical server of 16 chips which contains one CPU Tray, there is 100Gbit/s of ENA frontend networking and 80Gbit/s of dedicated EBS block storage networking.
Lastly, there is the out of band management network. This is used for re-imaging the operating system, monitoring node health such as fan speed, temperatures, power draw, etc. The baseboard management controller (BMC) on servers, PDUs, switches, CDUs are usually connected to this network to monitor and control servers and various other IT equipment.
In the following sections we will dive deeper into and explain in detail a few of the above networking topics and fabrics.
NeuronLinkv3 Scale Up Networking
Each Trainium2 Physical Server has a copper backplane where each chip connects to one other chip using a PCB trace on the JBOG PCB board (i.e. left Trainium2 chip connects to right Trainium2 chip on the same JBOG) and each chip also connects to three other intra-server chips using the copper backplane. NeuronLinkv3 is based on PCIe Gen 5.0 which means 32Gbit/s per lane (unidirectional).
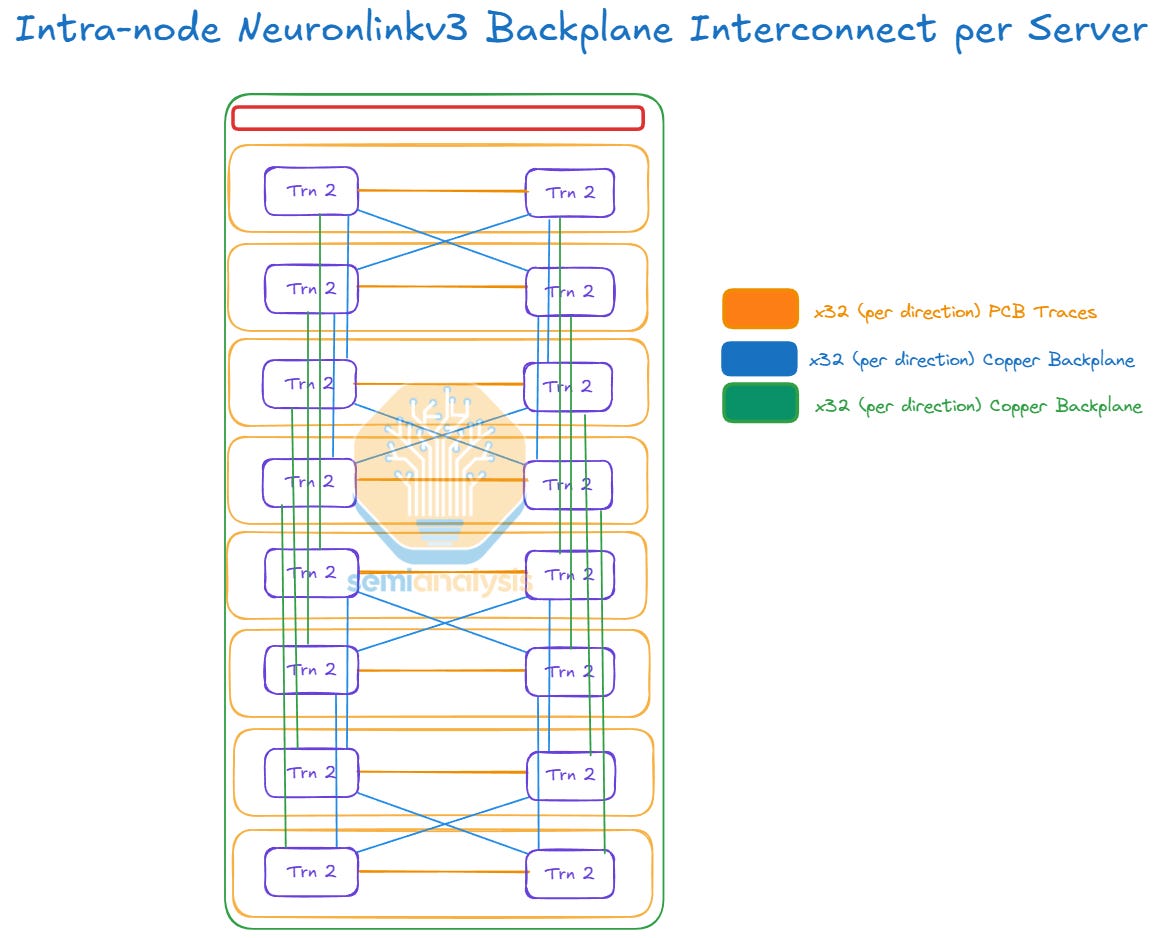
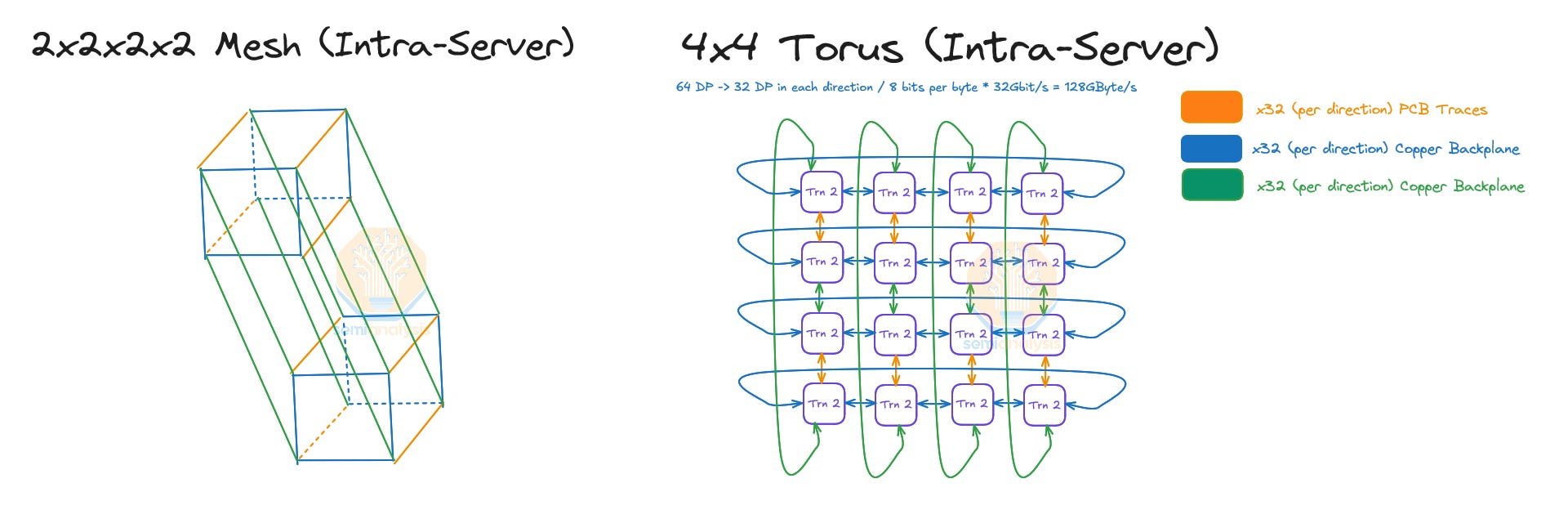
Each chip connects to other intra-server chips using 32 PCIe lanes meaning that each chip talks to each of its intra-server neighbors at 128GByte/s (unidirectional). The Intra-server NeuronLinkv3 is a 2x2x2x2 hypercube mesh.
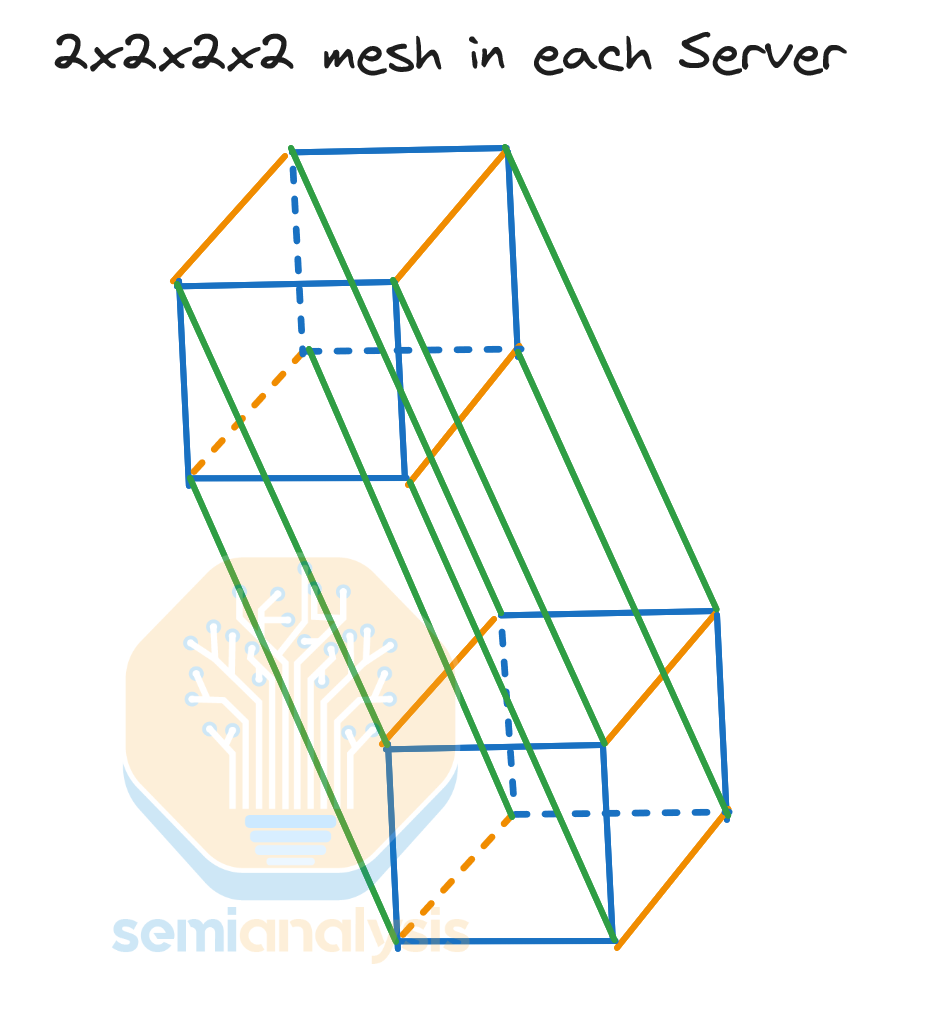
Isomorphic proof of 2x2x2x2 Hypercube == a 4x4 Torus
Interestingly, a 2x2x2x2 4D hypercube is isomorphic to a 4x4 2D torus, meaning that each Trainium2 physical server is a 4x4 2D torus.
The mathematical proof for isomorphism is quite simple. We just need to check that the total number of vertices and edges is the same, and that each of the vertices has the same number of orange, blue, and green neighbors in each graph. We can clearly see in the visualization below that both graphs have 16 vertices, 32 edges and each vertex in both graphs have one orange edge, one green edge and 2 blue edges. Since they meet all these conditions, it is indeed isomorphic.
Inter-Server NeuronLinkv3 Scale-Up
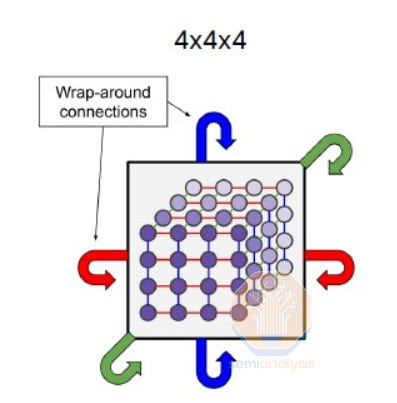
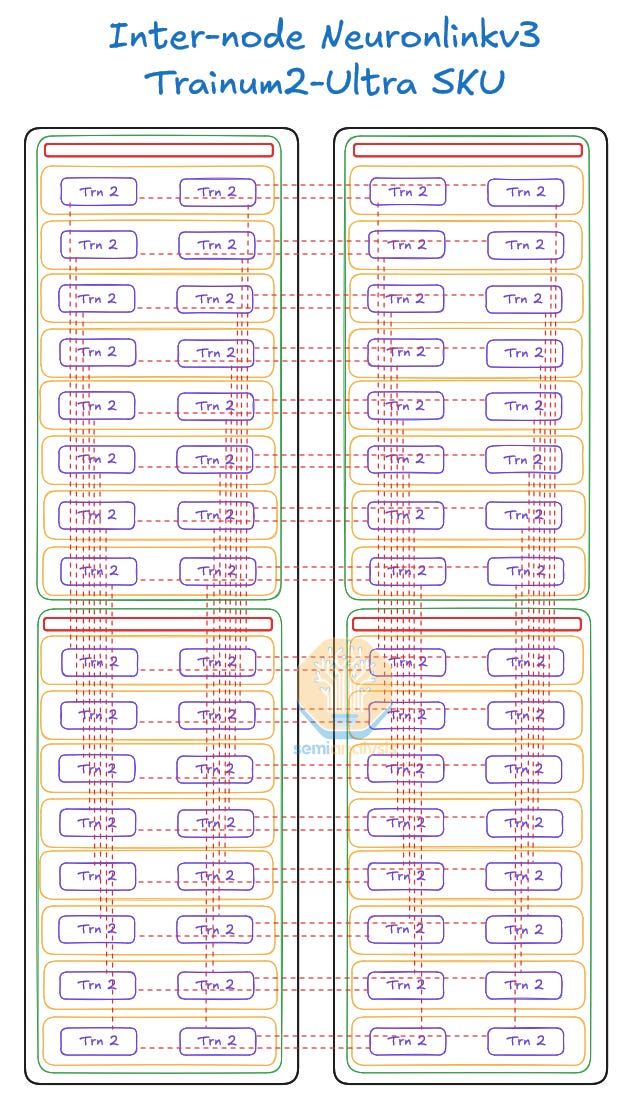
In the Trainium2 Trn2-Ultra SKU, four Physical Servers are connected together to form an “Ultra Server” with 64 chips within a scale up domain. These 64 chips are connected together in a 4x4x4 3D torus where the Z-axis has only 64GByte/s of point-to-point bandwidth compared to 128GByte/s on the x and y axes which have twice as much point-to-point bandwidth. Each chip connects to two other chips in other Physical Servers using an OSFP-XD active electrical cable per connection. This way, the chips are able to form a chain with wrap-around connections in the Z-Axis (Physical Server A -> Physical Server B -> Physical Server C -> Physical Server D -> Physical Server A).
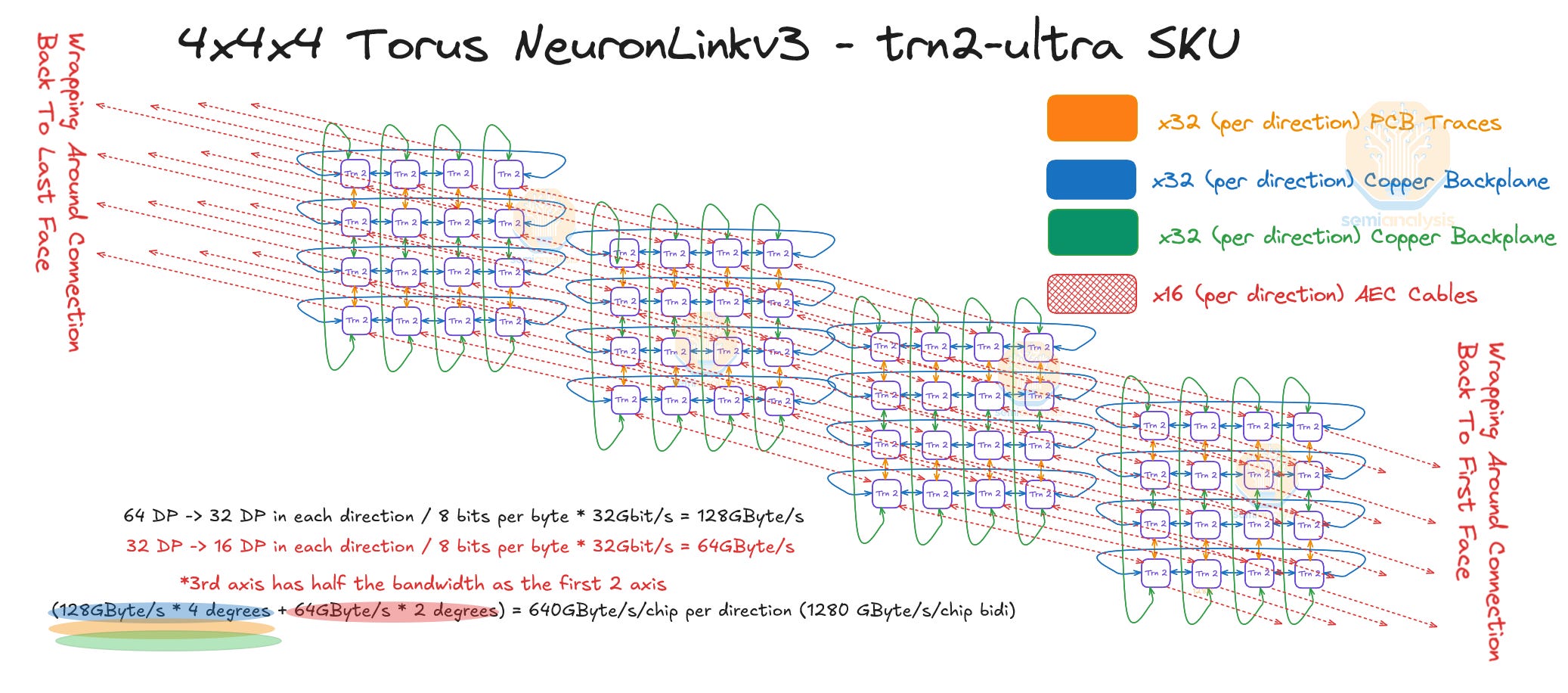
This 4x4x4 3D torus is very similar to a TPU cube rack design which is also a 4x4x4 3D torus and features symmetric point to point bandwidth on all 3 of the axes. Another difference between the Trainium2 topology and the TPU topology is that TPU cubes can connect on all six faces to other TPU cubes over optics with OCS whereas Trainium2 does not allow for this.
Amazon and Anthropic likely came to a compromise regarding scale up versus scale out bandwidth as they are transferable due to the PCIe physical layer allowing reallocation between NIC’s and NeuronLinkv3. Trainium2 only has enough NeuronLinkv3 lanes to create a 4x4x2 3D torus with a world size of 32 with symmetric point-to-point bandwidth on all 3 axes, but having a world size of 64 with asymmetric BW is likely much better than a smaller world size of 32 for frontier LLM training and inference.
No NeuronLinkv3 PCIe Optics
Since there are two Physical Servers per rack, the Physical Servers are able to form a ring within less than a 2-meter distance and as such can stay within the range of a PCIe AEC.
If AWS had designed the Trainium2 architecture with a lower rack power density and therefore would be able to only fit one server per rack, they would have had to create a four Physical Server Ring to form a 64-Chip Ultra Server, then AWS would need to use PCIe optics since the longest connection would span four racks now, beyond the range of a PCIe AEC.
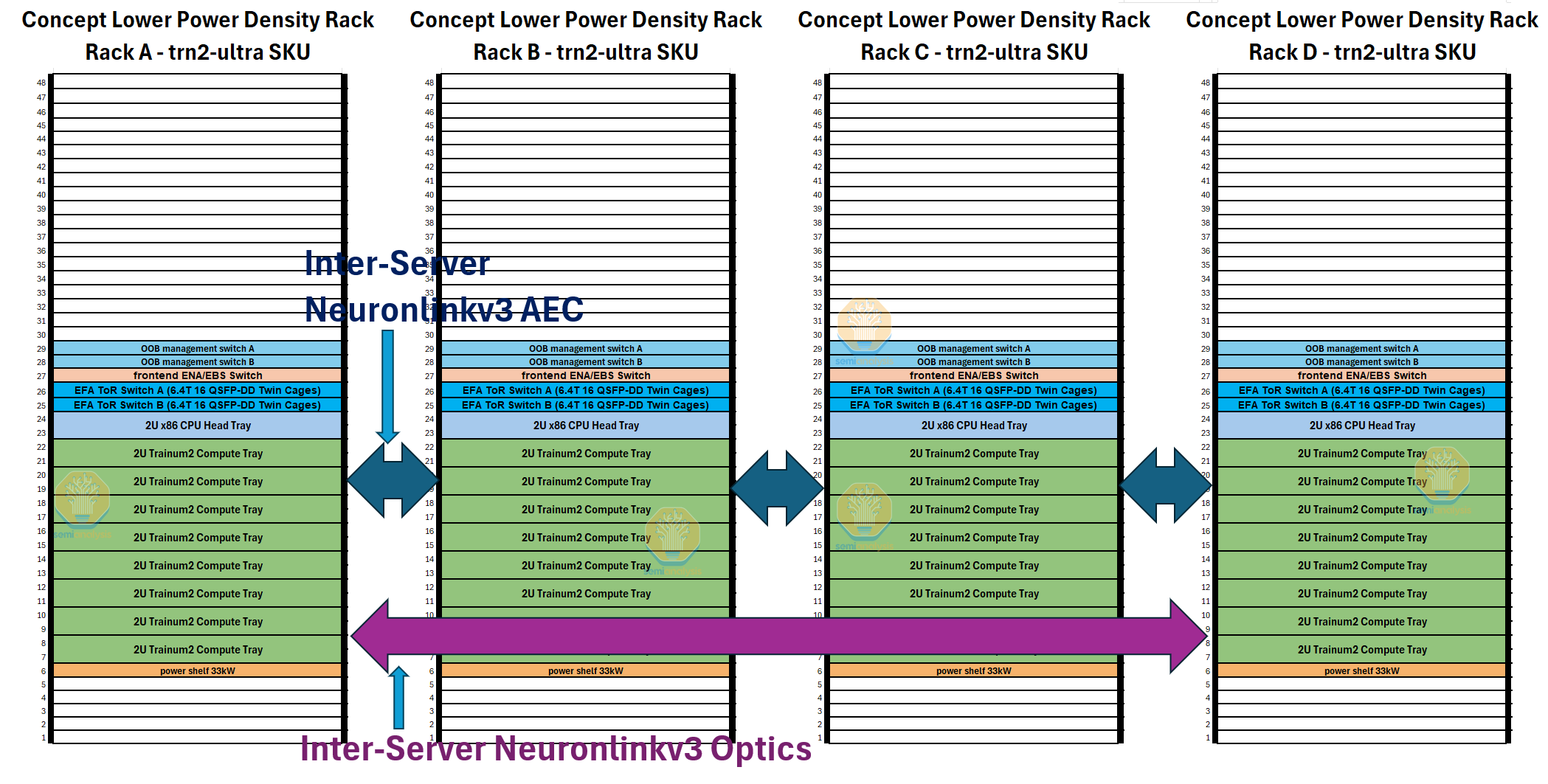
The introduction of PCIe optics would have caused orders of magnitude decrease in reliability and orders of magnitude increase in cost for the NeuronLinkv3 inter-server networking compared to the actual design chose, which uses much cheaper much more reliable AECs.
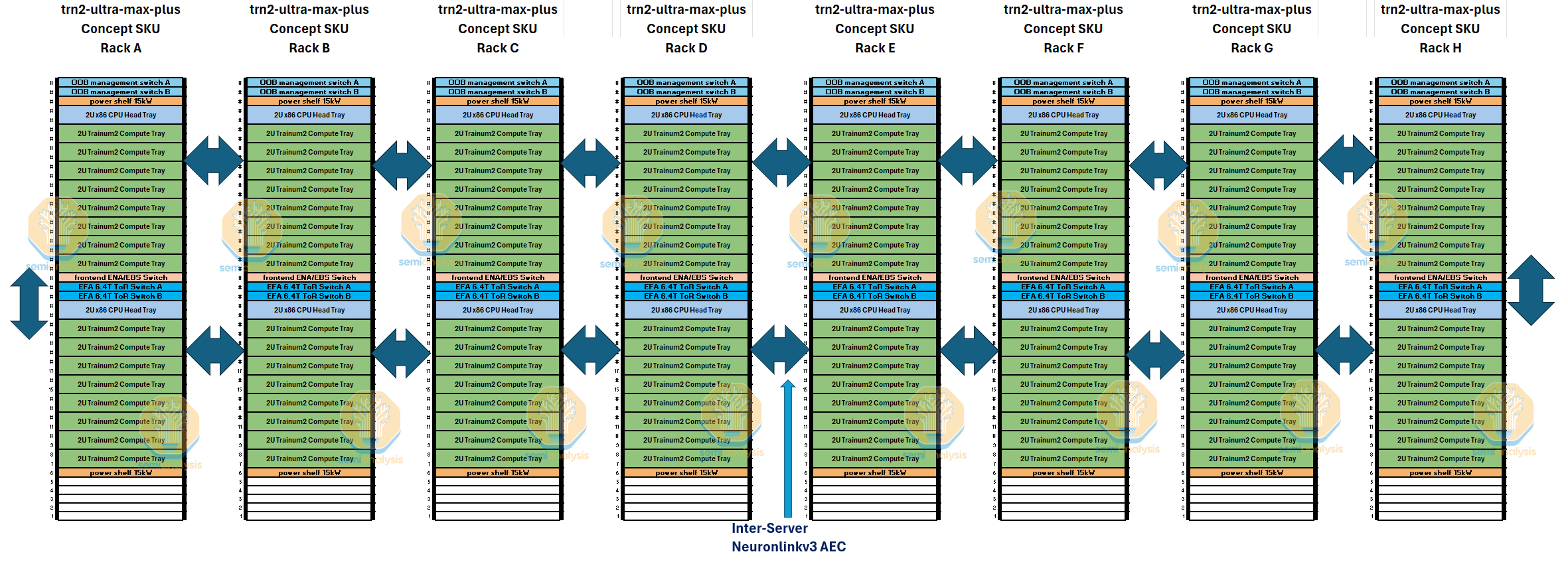
Trn2-Ultra-Max-Plus 4x4x16 Concept SKU
Because the NeuronLink inter-server architecture is a 3D torus with AEC connections on the 5th and 6th neighbor along the z-axis, we believe that it is possible to extend the z-axis from just 4 servers to 16 servers along the physical row of servers within in the hot aisle containment side.
We propose a concept SKU called “trn-2-ultra-max-plus” which connects 256 chips together in a 4x4x16 3D torus instead of 64 chips together in the General Availability Trn2-Ultra SKU. The point-to-point bandwidth in this concept SKU would still be 128GByte/s in the x and y axis and it would still be 64GByte/s in the z-axis.
We believe that 256 chips would be the maximum range that AECs and passive copper cables could reach before needing to use PCIe optics to connect between rows of racks outside of a single hot aisle containment zone.
This larger scale up world size would allow for more efficient training of relatively large models that can’t fit within a single Trn2-Ultra 64 chip server. One downside of this concept is that it means many chips will be permanently attached to each other in a point-to-point topology like a torus.
Job Blast Radius
When there are many chips attached together in a point-to-point torus topology, if just one chip in the torus fails, the whole torus scale-up domain becomes useless. This leads to poor goodput as was seen in the TPUv2 pods and TPUv3 pods. For Trn2-Ultra, if just one out of the 64 chips within the Trn-2-Ultra Server fails, all 64 chips will not be able to contribute any useful work. In our concept SKU, trn2-ultra-max-plus, given there are 256 chips chained together, if just 1 out of the 256 chips fails, all 256 chips will be considered down.
For TPUv4, Google introduced a solution for this giant job blast radius problem. The solution is to use reconfigurable optical switches between cubes of 4x4x4 tori to limit the blast radius of each chip failure to just 64 chips despite a scale up pod size of 4k.
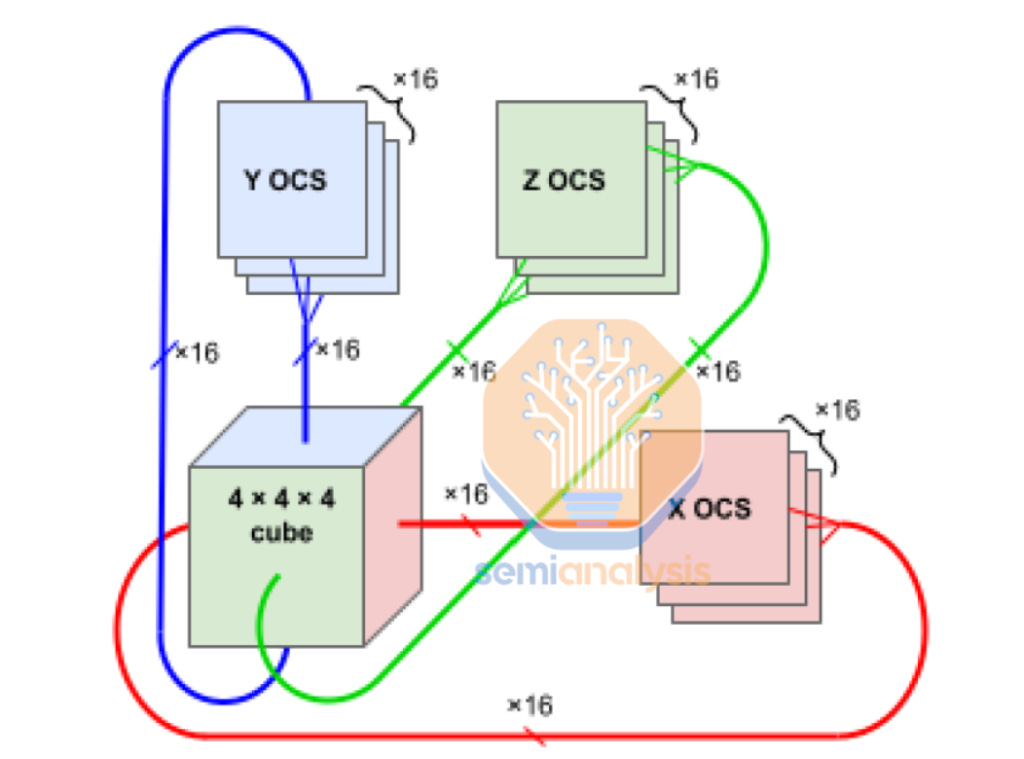
As you can see below in the TPU pod cube map, different users can form a 3D torus that routes around the failed cube (the red cube). Although this is a clever solution, we believe that AWS did not pursue this path of having a giant world size with OCS between each 4x4x4 cube because OCS is very complicated to deploy from a software and hardware perspective and involves the use of expensive optics. Optical links require transceivers, which remain in shortage due to high demand and are often 10x more expensive per bandwidth than passive DAC copper cables. It is because of this very high cost of optics that you see mostly DAC copper cables used within a TPU cube and is a key reason why Nvidia GB200 NVL72 used copper for their scale up networking as well.
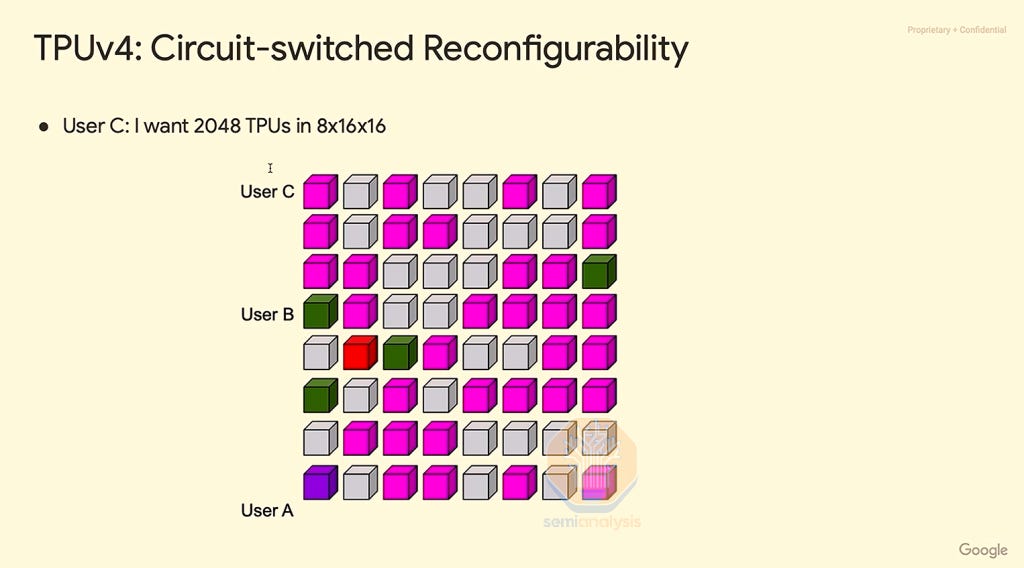
Although within a cube, a single chip failure means that the whole cube is out of service, failures of the networking links between chips can often be routed around. With that said, we expect high networking link reliability and as such we don’t expect Trainium2 NeuronLinkv3 networking links to fail or flap much since all links use passive copper cables and active copper cables.
There is a dramatic difference in mean time to failure (MTTF) comparing networking links over Optical Transceivers vs for passive and active electrical copper. The MTTF could be 1-10 million hours due to transceiver laser failure while for copper, a typical MTTF is around 100 million hours, a 10-100x better reliability rate.
Potentially even more important than a much longer MTBF is the fact that passive/active electrical copper cables have orders of magnitudes lower likelihood of flapping compared to optics. Flapping is a common issue in optical systems where the links will break for a period that could range from a couple of microseconds to seconds due to issues with the lasers and/or module overheating. Flapping causes massive issues for training jobs that rely on a stable network to communicate between chips.

Since TPUs use optical links between cubes, Google had to create fault tolerant routing when transceivers and/or the OCSs fail. With fault tolerant routing, instead of the whole pod being out of service due to broken optical links, the pod can still function at just small slowdown for LLM training workloads. This small decrease in slowdown compared to having a cube do zero useful work is great for goodput for the entire physical TPU system.
However, it is important to note that Fault tolerant TPU routing only helps deal with broken links but when there is a chip level failure, this will still result in a 64 chip blast radius due to the fact that JAX/Pytorch requires cuboid shaped topologies with 0 holes.
We believe that in practice Trainium2 will not need to implement fault tolerant routing since there will be practically zero NeuronLink faults due the links running on passive and active copper which will result in 100x better link reliability than the TPU cross-cube optical system. If, for whatever reason, these passive and active copper links start being a significant source of error, then the Trainium2 Neuronx collective team would need to start implementing fault tolerant routing.
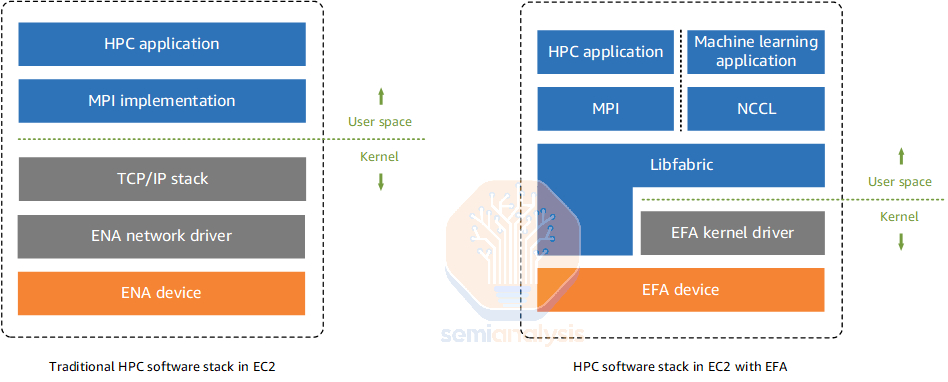
EFAv3 Scale-Out Ethernet Networking
For Trainium2, in order to scale out to tens of thousands of chips within a single interconnected cluster, AWS will be using their in-house flavor of ethernet called Elastic Fabric Adapter Version (EFAv3). This will support up to 800Gbit/s per chip of EFAv3 BW for normal Trn2 (16 chip) instances and 200Gbit/s per chip of EFAv3 bandwidth for Trn2-Ultra (64 chips). As mentioned above, the Trn2-Ultra SKUs will be the most common instance used for the largest frontier training and inference workloads. Compared to EFAv2 NIC’s massive 9 microsecond packet latency, EFAv3 NICs has a lower 6.5 microsecond packet latency. Packet latency is one of the major factors that determine how fast the algorithmic bandwidth of collectives can run at. We will explain these concepts in much greater detail in our upcoming NCCL collective deep dive article.
Unlike the Nvidia reference network design, Amazon will not be currently using a rail optimized network. That means that all chips with a server will connect to the same immediate switch in the same rack called a “Top of Rack” (ToR) network design.
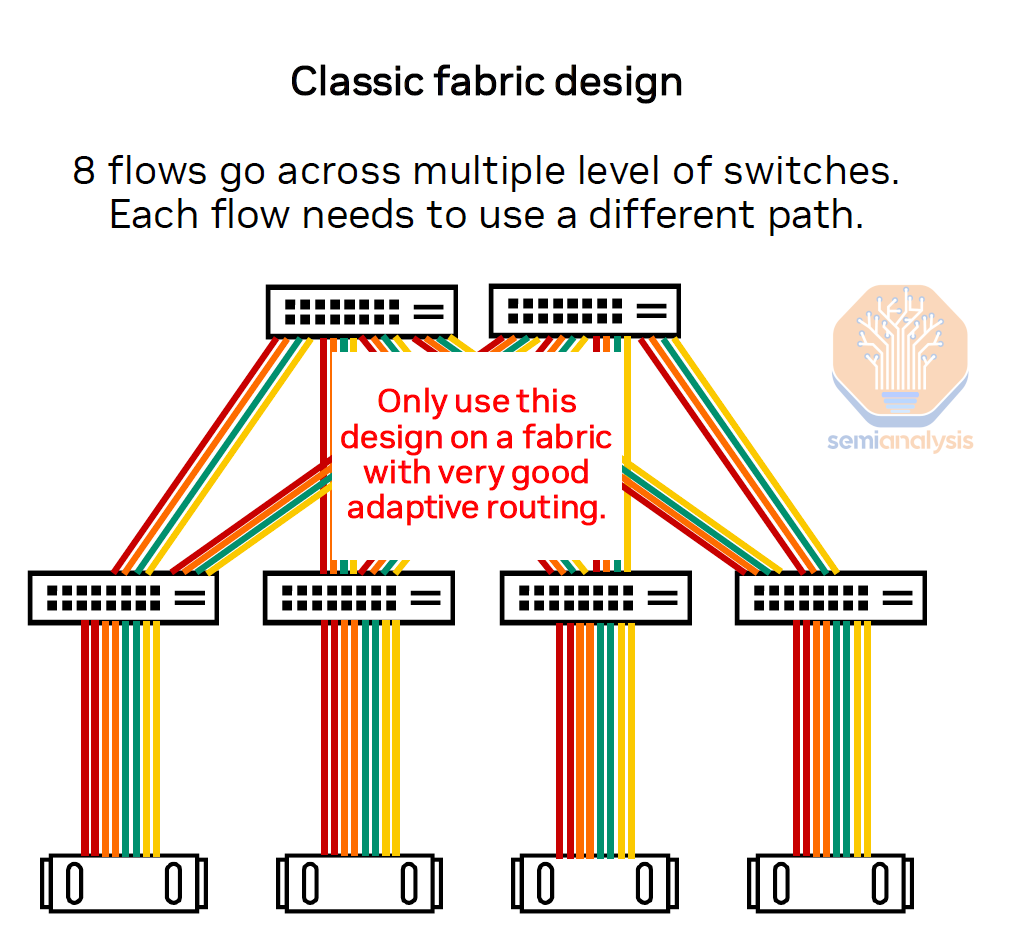
This means that on average, each flow will require more hops throughout the network compared to in a rail optimized topology, where most flows will be one hop only. In a ToR design, there must be extremely good adaptative routing to avoid path collisions between different concurrent flows. Techniques such as hashing in the queue pair ID instead of the standard tuples will allow for increased entropy in the network to limit the number of flow collisions.
The diagram below shows our simulated heatmap of this non-blocking top of rack fabric where the lighter blue color indicates less bandwidth due to congestion and dark blue means near full line rate. As you can see, using a ToR topology, it is possible to reach line rate but there is still considerable congestion due to all 8 flows going into one switch, with throughput becoming far more jittery and high congestion resulting in less bandwidth for these flows.

Although ToR networks have worse performance, we believe that reason AWS chose to use ToR based networking instead a rail optimized design is due to a ToR being cheaper and enjoying increased reliably as a ToR architecture can use copper from the AI chip to the first immediate switch. In contrast, with rail optimized, each AI chip may be connecting to distant racks, necessitating the use of optics for many links. AWS has internally experimented with rail optimized but due to the reliability implications discussed above and out of a desire to deploy rapidly, they chose to stick with a ToR architecture. Reducing the usage of optics also reduces exposure to issues caused by the ongoing worldwide shortage of optical transceivers due to the unprecedented increase in demand from the AI boom.
Yet another benefit of ToR is that usually in AI clusters, the scale-out NIC to its first immediate switch has one single point of failure. In a ToR architecture, the passive DAC copper cables that connect the scale-out NIC to the ToR switch have 100x better MTTF and 100x less flapping. AWS will be using a 400G QSFP-DD to two 200G QSFP56 passive copper cable between the NIC and the ToR switch.
For the in-rack ToR switch, we believe that most of the switches will be white box switches based on the Marvell Teralynx 6.4T and 12.8T switch chips. AWS does multi-vendor sourcing between Broadcom and Marvell merchant switch ASICs, for the ToR switch.
For the Leaf and Spine switches, AWS will use 1U 25.6T white box switches based on Broadcom Tomahawk4 silicon.
AWS does not use multiple switches to form a chassis based modular switch due the large blast radius of such a setup. If the chassis fails, then all the line cards and links that the chassis is connected to fail. That could be in the order of hundreds of Trainium2 chips. Most hyperscalers are generally allergic to these physical chassis modular switches due to the large potential blast radius.

Instead, AWS prefers to use virtual modular switches that connect up multiple pizza box 1U switches in a single rack with passive and active electrical copper cables to form what is essentially a modular switch. This way, there is no single fault that will affect a large blast radius. We explain more about virtual modular switches in the our Neocloud Anatomy article and discuss their pros and cons.
EBS+ENA+OOB
Each Trainium2 Physical Server will have a dedicated 80Gbit/s link to AWS managed block storage called “Elastic Block Storage” (EBS) and have a 100Gbit/s frontend link called “Elastic Network Adapter” (ENA). These will provide fast access to normal networking traffic such as container pulling, SLURM/Kubernetes management traffic. Both networks use AWS’s in house Nitro DPU card that offloads VPC and security functions to the hardware, thus freeing up CPU resources. Most importantly, these Nitro cards can accurately measure the amount of traffic going through the NIC and thus accurately bill for that traffic! Note that physical tensors and AI traffic will not run over these networks but instead will only run on the EFAv3 scale out and NeuronLinkv3 scale up networks that we previously discussed.
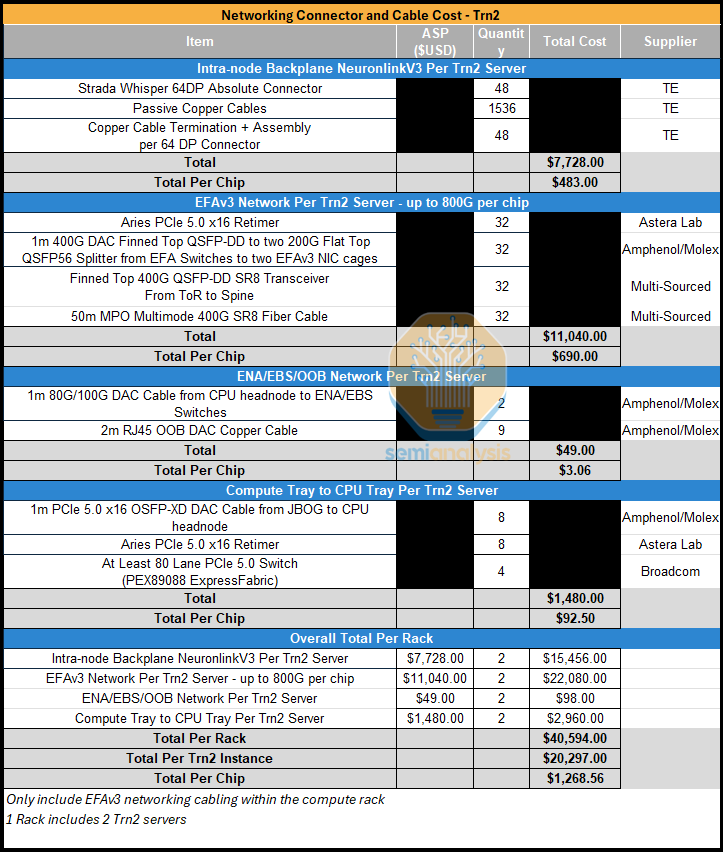
Networking Connector and Cable Costs
For both SKUs of Trainium2, TE will be the sole supplier of the backplane and each server will include 48 connectors and 1,536 copper cables. Unlike the GB200 NVL72 where the NVLink cables go from the GPU to an NVLink Switch, for the Trainium2, the cables are point to point between each chip. The Trn2-Ultra SKU will also have AEC cables which Astera Labs will be supplying. We believe that the total networking connector and cabling cost will come up to nearly $1,000 per chip.
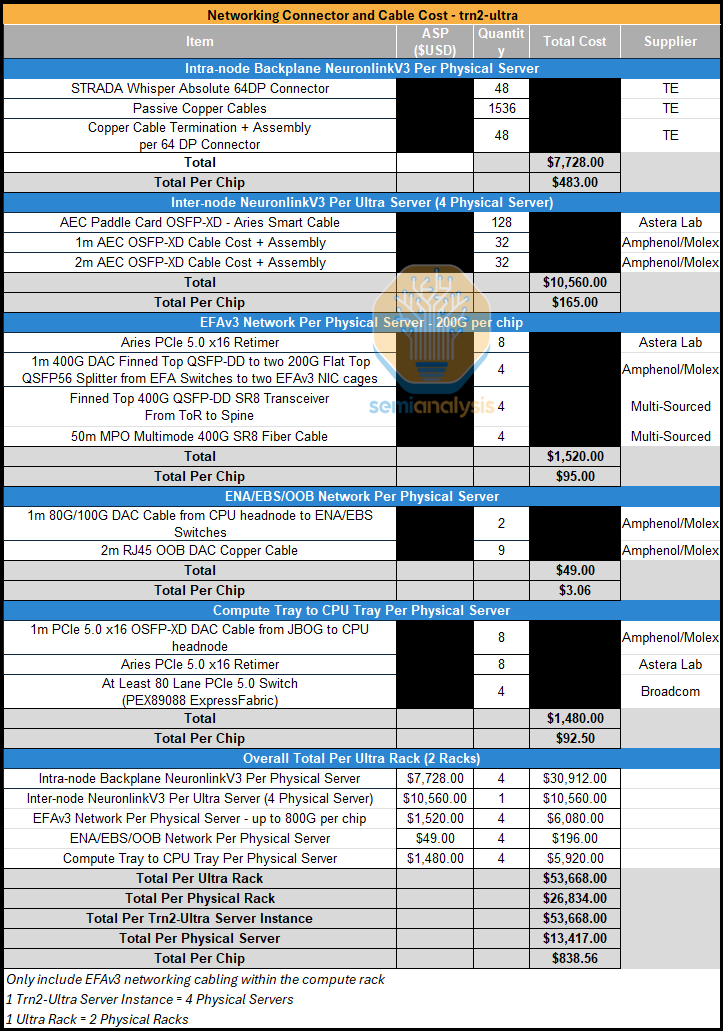
For the Trn2 SKU, although there is no inter-server NeuronLinkv3 AEC cables, the increase of EFAv3 bandwidth to up to 800Gbit/s per chip will more than offset that savings, increasing the total cost for networking connector and cables costs to ~$1.2k per chip.
Software
One of the most challenging aspects of designing a custom AI chip is the software, where the ML Compiler and a strong user experience when integrating into existing ML scientist workflows are both of paramount importance.
Previously, on Trainium, the only path to using the AI chip was through the Pytorch XLA Lazy Tensor ML Compiler which is a very poor API that gives rise to a considerable number of bugs and suffers from a lack of portability. We believe that the AWS Trainium team has since course corrected by offering direct access to writing Kernels in a Triton-like tile programming language. Furthermore, the Trainium software team now has beta support for JAX which is an ML framework more oriented towards XLA ML compilers and torus topology statically compiled AI chips. Trainium and Trainium2 is very similar to TPU in the sense all are giant systolic array chips with torus topologies so Trainium software now supporting JAX through XLA will be a more fitting software stack.
Generally, since the complete ISA assembly is exposed to the end user in Trainium2, bad software can be bypassed by advanced users such as at Anthropic. At Anthropic, they have extremely smart programmers that write assembly in order to take full advantage of Trainium2, despite the current lacking software
XLA
The dream of Pytorch XLA is to use lazy tensors to trace the compile computation graph and all the Pytorch operations, only running the graph on the Trainium device when it hits a part of the graph that requires materialization. This works well for simple models but the problem with lazy tensors is that there are lots of bugs that arise as soon as you add any sort of complexity to your ML model architecture. Using lots of control flow statements will break lazy tensors, especially if data dependent control flow statements are used a lot. Furthermore, for giant computation graphs (such as in large LLM models) with hundreds of thousands of computation operations, lazily tracing the graph will result in high overhead as well due to the generally slow speed of Python.
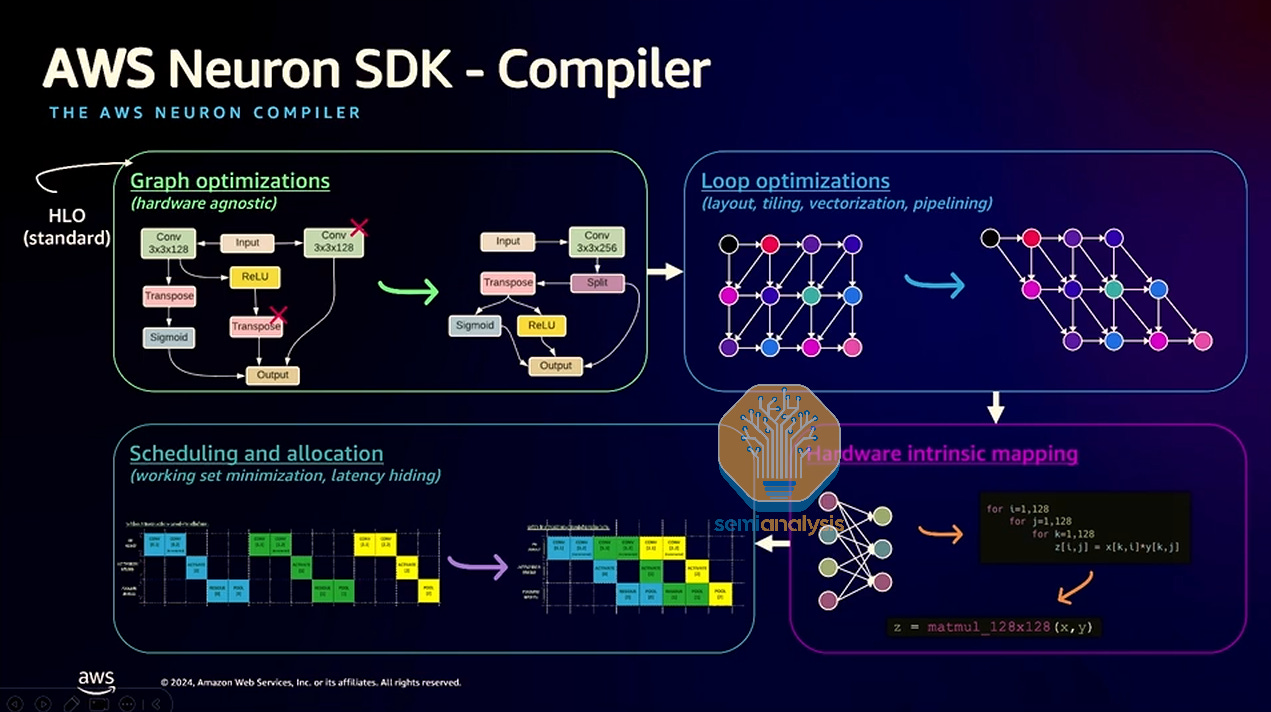
The target goal for Pytorch XLA is once Pytorch<>XLA traces the computation graph into StableHLO, XLA is then able to do perform graph optimizations such as deleting subgraphs that form an identify and doing vertical + horizon fusion. Then XLA will lower it to a hardware dependent graph for vectorization and pipelining optimizations into kernels that are high performing.
Pytorch 2.0 has introduced a new way of capturing computation graphs using python bytecode interpretation called “TorchDynamo”.
TorchDynamo is able to capture a computation graph into an IR called “Aten IR” where each node in the computation IR is an Aten operation. A compiler backend can then take this Aten IR graph in as an input and lower it into a domain specific internal IR such as StableHLO for XLA or Inductor IR. We believe that this API fits the Trainium XLA much better and support for Pytorch through the Dyanmo API will be much better.
The unfortunate news about TorchDyanmo XLA is that currently, TorchDynamo breaks the training graph into three graphs (forward, backward, optimizer step) instead of having one full graph, leading to sub optimal performance compared to LazyTensor XLA. The good news here is that the Meta team is working on capturing the full graph in TorchDynamo and this work will be extendable to TorchDynamo XLA.
The bad news for Trainium is that generally Pytorch<>XLA codepath is not used extensively internally by Meta and as such is mostly maintained by the AWS and Google Pytorch team which is the main reason there are a lot of bugs for the Pytorch<>XLA codepath. Furthermore, both Google and AWS Pytorch teams are second class compared to their Jax teams because workloads from labs such as Deepmind and Anthropic run through the Jax stack.
Similarly, Meta does not extensively internally field-test the Pytorch AMD codepath. We will talk more about AMD performance in our upcoming article “Training of MI300X vs H100 vs H200 Comparsion”. The AWS team should work with Meta to internally field-test Trainium2 for Meta’s in-house production training workloads to make the Pytorch Trainium2 software experience amazing!
JAX has traditionally only worked for Google’s TPU chip when using Google’s internal XLA ML compiler, but we believe that JAX’s programming model is well suited towards Trainium2 as well since TPU and Trainium2 are both AI chips with giant systolic arrays and statically compiled graphs that use a 3D torus. This means that it is intuitive for Trainium to hook into the XLA Compiler plugin and PRJT runtime. JAX’s logical cuboid mesh and axis fits the Trainium topology very well. AWS has recently announced an open beta for their JAX <> Trainium integration, which is a very exciting direction.
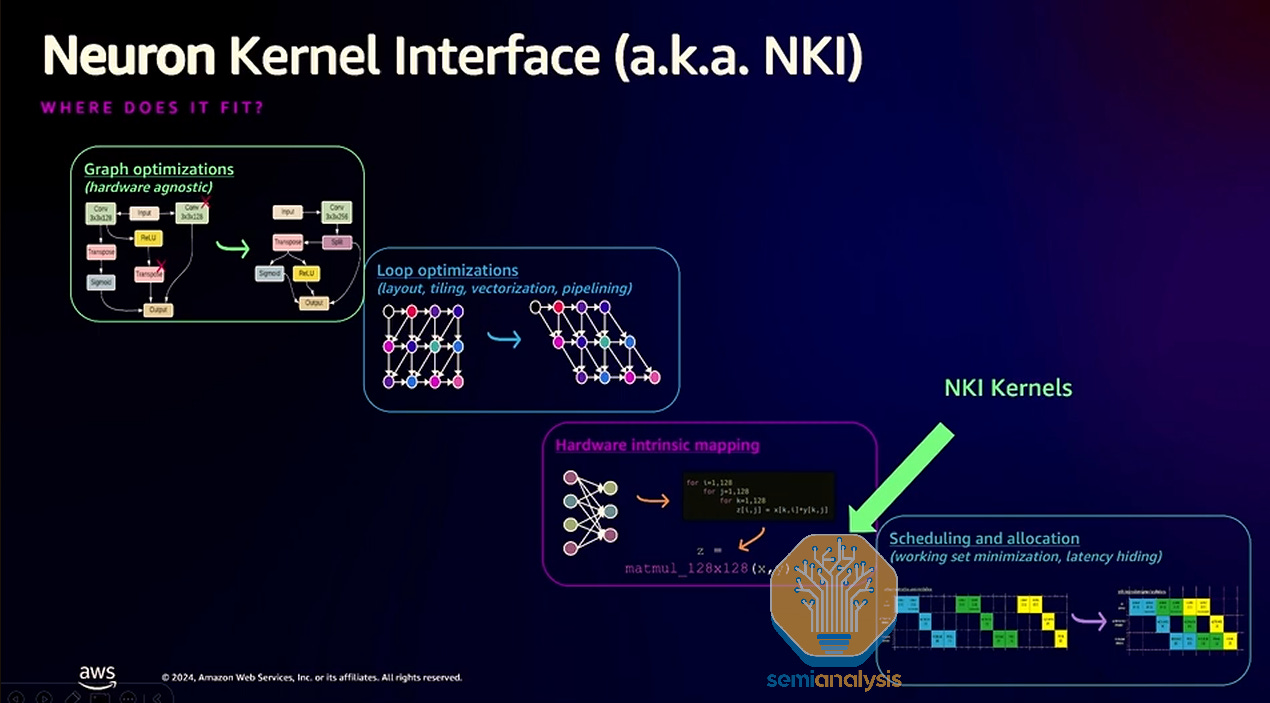
NKI Kernel Language
The Neuron Kernel Language (NKI) - pronounced “Nicky” – is Trainium domain specific language for writing kernels similar to NVIDIA’s CUDA and OpenAI’s Triton language. Unlike Nvidia’s CUDA language, NKI is based on tiles programming like OpenAI’s Triton programming language. NKI will allow expert programmers to be able to achieve near speed of light (SOL) performance on the Trainium2 chip.
In addition to AWS’s own public documentation and kernel examples, in order to spread the knowledge and education of the NKI kernel language, Amazon has collaborated with Stanford to give students assignments that focus on writing real world kernels such as fused convolution + max_pool. We like the direction they are heading in as in order to be competitive with the CUDA ecosystem, AWS must take an ecosystem and open-source approach towards educating around the NKI kernel language.
Distributed Debugging and Profiling Tools
Amazon also provides extremely fine-grained kernel level and distributed system level debugging and profiling tools similar to what Nvidia offers on their GPU ecosystem. We believe that this is the correct direction since it enables expert end users to notice the bottlenecks of their training and inference workloads and fix it.
Similar to Nvidia Nsight Compute, you can view the kernel level profiling and see the activity of the Tensor Engine, as well as SRAM register pressure, among other items.
Where the Nvidia ecosystem has the Nvidia Nsight Systems and Pytorch Perfetto profiler equivalent tool, the Trainium2 ecosystem has Neuron Distributed Event Tracing. This will allow ML Engineers to debug distributed performance issues and see how well communication is overlapping with compute. In some ways, this is better than the out of the box Pytorch profiler since it will automatically merge all traces from all ranks instead having the end user manually write scripts for merging together ranks which themselves may contain bugs.
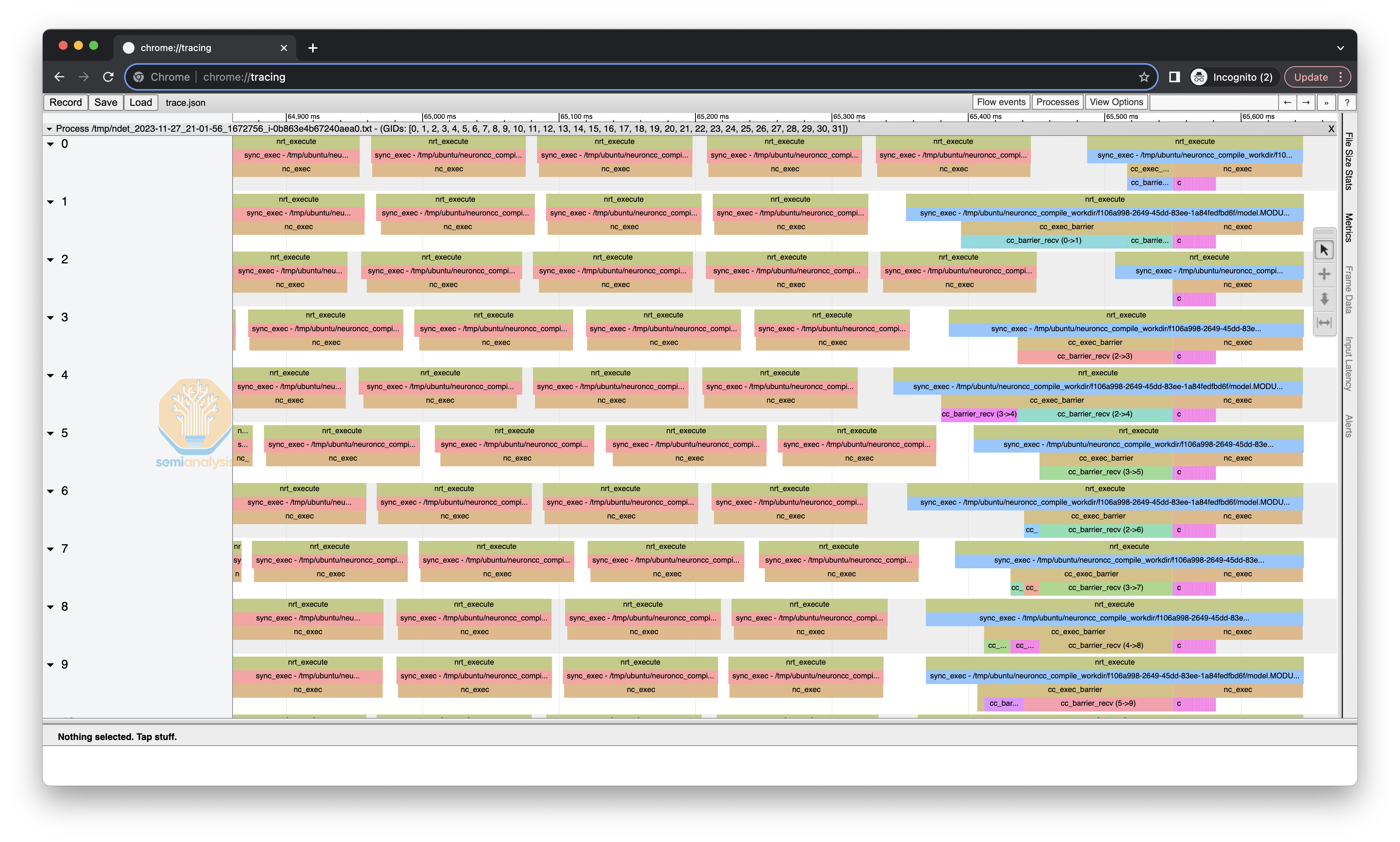
Furthermore Amazon is publishing much of the ISA and exact cycle times, which enables very developers to have a much more positive experience when debugging and profiling compared to developing on Nvidia based GPUs. This means extracting the true speed of light out of hardware is much easier relative to Nvidia GPUs where details are purposely obfuscated away from the user.
Collective Communication Library
For collective communication, AWS created a Trainium specific library called NeuronX Collective Communication Library. This library is similar to Nvidia’s NCCL in that it provides a set of collective communication algorithms and collectives such as All Reduce, All Gather, Reduce Scatter, etc. that are purpose built for the Trainium2 2D/3D torus topology. End users can access this library directly through a C++ interface (or through Python bindings) and the XLA ML Compiler can also automatically insert collective calls during complication phase. Trainium2 will also be able to directly talk to its EFAv3 NIC without going through the CPU using a technology called “GPUDirect RDMA”. Furthermore, with AWS’s in house libfabric, they are able to do kernel OS bypass reducing packet latency even more.
The Trainium NeuronX Collective Communication library does not currently support All to All collectives. All to all collectives are extremely important for expert parallelism used in Mixture of Experts (MoE) models. This issue was opened on October, 2022 and has been inactive since about 3 weeks ago due to AWS wanting to support DataBrick’s DBRX MoE model and other upcoming models. Databricks has recently announced their “partnership” with AWS to use Trainium2 chips for training and inference. We believe that Databricks will be the second largest external Trainium2 customer for GenAI inferencing.
Since the posting of this article, the AWS team has since closed the issue citing that all to all has been supported a year ago, but the issue did not reflect the ground truth
Async Checkpointing Between Ultra-Server Pairs
In order to speed up checkpointing, the Trainium NeuronX package provides support for cross host checkpoint redundancy. Instead of having Trainium2 chips sit idle while checkpointing to relatively slow S3 or AWS Managed Lustre storage, Trainium2 chips will quickly checkpoint to their own server’s CPU RAM and/or local NVMe storage after which the Trainium2 chips will continue with their workloads.
The problem with this approach is that if a server hard crashes, there will be no redundancy or other backup of the checkpoints, leading to many Trainium-hours of lost compute time.
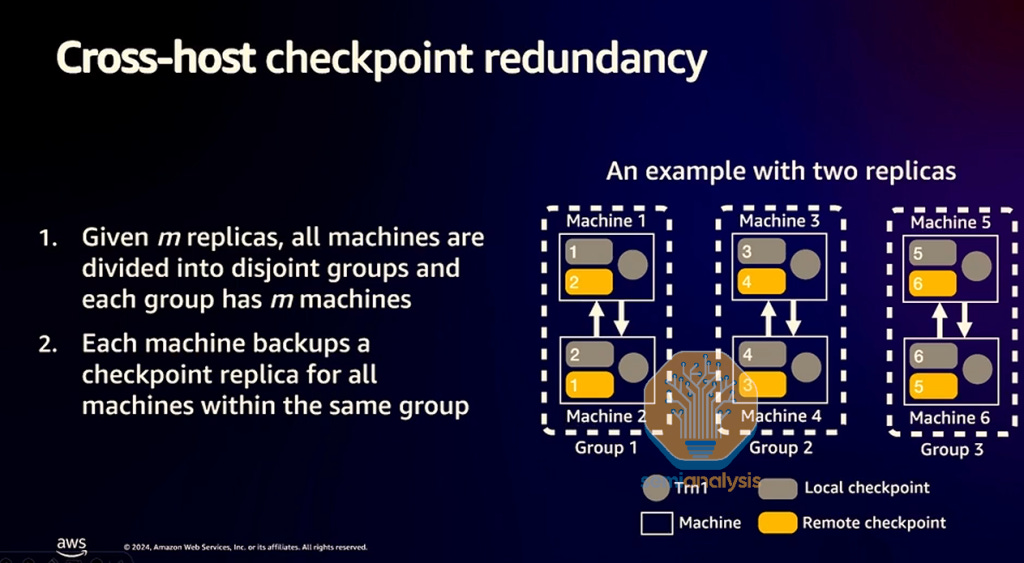
In order to deal with that issue, Trainium2 servers will be able to slowly replicate the checkpoint to other servers in a pair wise fashion. In addition, so as to not cause training slowdowns when Trainium2 servers copy their checkpoint to a neighboring server, AWS claims to be able to schedule the checkpoint copying traffic during times when there is no communication from the training workload.
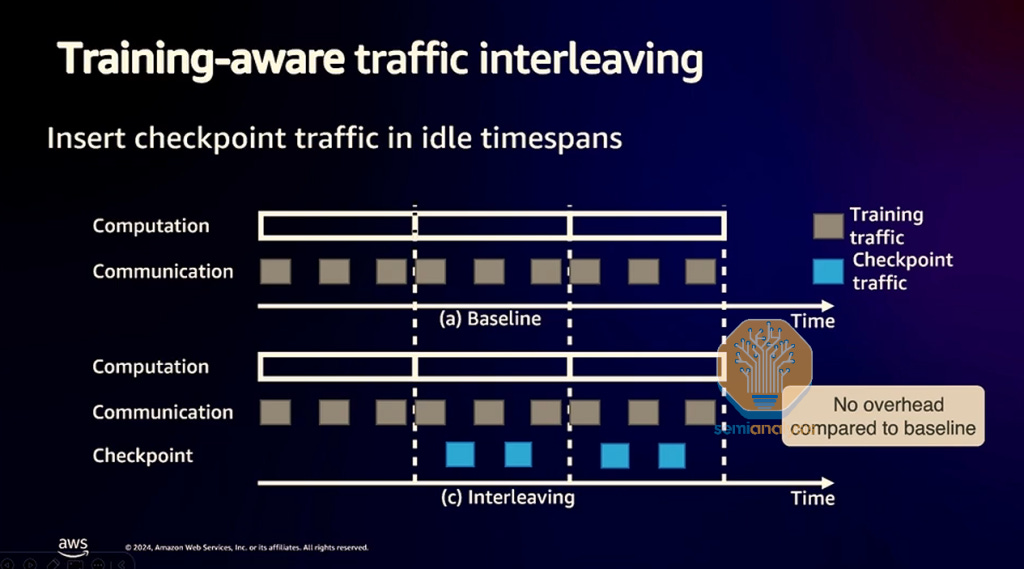
This is something sophisticated users may already be doing on their training runs with other async checkpointing strategies, but it dramatically lowers the bar for less sophisticated users.
Workload Orchestration
End users of Trainium2 will be orchestrating their workload either with a SLURM-like approach or with a Kubernetes-like approach.
In terms of the SLURM-like approach, AWS offers two managed services, AWS ParallelCluster and AWS Batch. AWS ParallelCluster is basically just managed SLURM. SLURM is just a near Linux/bash primitive orchestrator. A lot of ML engineers/scientists that come from the academic lab environment have a srong preference for SLURM because it is uses bash and Linux primitives. It is an amazing experience when running interactive jobs and for code development. This is in contrast to the Kubernetes containers approach, which doesn’t truly support interactive jobs out of the box.
In terms of a Managed Kubernetes like approach to workload orchestration, AWS offers Elastic Kubernetes Service (EKS) and Elastic Container Service (ECS). Kubernetes is not built out of the box for batch jobs such as training workloads which require gang scheduling. Kubernetes is great for service-oriented workloads such as inferencing where each replica is most of the time just one server and thus can just be one Kubernetes pod.
It takes a lot of work to get Kubernetes working for training’s batch/gang scheduling and it also takes a lot of work to get Kubernetes working for interactive workloads too. Thus, we only really see the largest AI labs such as OpenAI and ByteDance taking this approach given that they can afford to have in house cluster engineers build tools to make Kubernetes work for gang training and interactive workloads.
Lastly, Kubernetes is generally better for agent training/inferencing and spinning up and down containers for AI Agents. We hope that these containers are hopefully hardened to prevent AGI from leaking.
Automated Passive and Active Health Checks
When scaling to tens of thousands of AI chips within a single workload, reliability is an important aspect to ensure training workloads complete successfully. That is why Nvidia released a tool called DCGM. With DCGM diagnostics, end users can detect 80% of silent data corruptions (SDCs) that occur in a cluster through numeric and full chip self-tests. Another interesting and related feature we have seen is at Nebius, a Neocloud Giant, which has implemented a feature in their operator workload scheduler where they are able to schedule active health checks through CRON jobs.
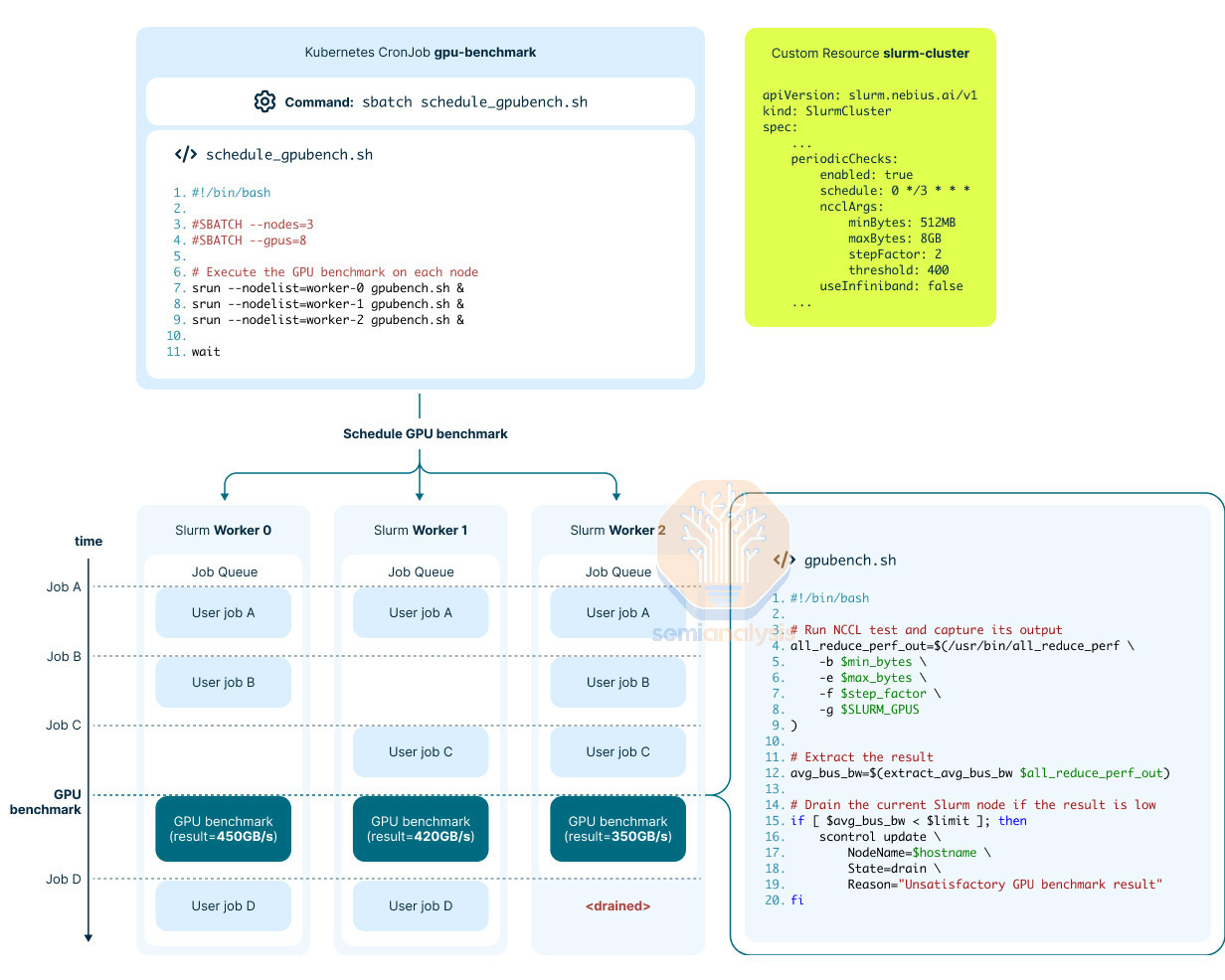
These active health checks can check Nvidia GPU’s NVLink networking and run a host of other checks. Furthermore, they are able self test their InfiniBand fabric with just a single node by disabling NVLink instead of what other users are doing when testing IB, which is using multiple nodes.
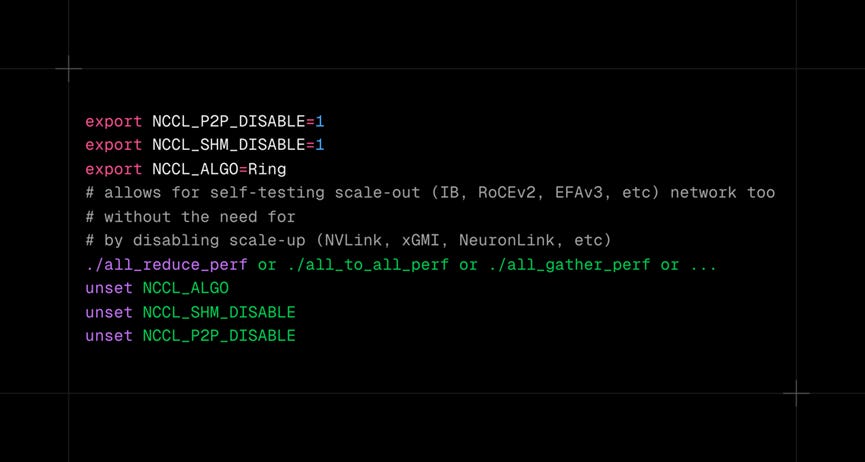
When it comes to the Trainium2 software stack, there are also similar tools. One can use NCCOM local tests to self test the NeuronLink and/or the scale-out EFAv3 links. Furthermore, AWS has provided a test that runs a mini training workload and ensures that the actual outputs of that workload matches that of the golden workload.
Next we will talk through the Trainium2 bill of materials for the various different server configurations, network costs, storage costs, power costs, and much more. We will also compare total cluster costs for 4k chips across both Nvidia and Amazon based solutions. The total cost of ownership is investigated to ultimately compare to our performance estimates. Understanding the performance TCO trade-off here is critical to the future viability of Amazon’s custom silicon efforts.