

AMD 2.0 - New Sense of Urgency | MI450X Chance to Beat Nvidia | Nvidia's New Moat
Rapid Improvements, Developers First Approach, Low AMD AI Software Engineer Pay, Python DSL, UALink Disaster, MI325x, MI355x, MI430X UL4, MI450X Architecture, IF64/IF128, Flexible IO, UALink, IFoE
SemiAnalysis is expanding the AI engineering team! If you have an experience in PyTorch, training, inferencing, system modelling, SLURM/Kubernetes, send us your resume and 5 bullet points demonstrating your engineering excellence to letsgo@semianalysis.com.
Ever since SemiAnalysis published an article in December 2024 detailing mediocre AMD software and the lack of usability, AMD has kicked into a higher gear and has made rapid progress in the past four months on many items we laid out. We view AMD’s new sense of urgency as a massive positive in its journey to catch up to Nvidia. AMD is now in a wartime stance, but there are still many battles ahead of it.
In this report, we will discuss the many positive changes AMD has made. They are on the right track but need to increase the R&D budget for GPU hours and make further investments in AI talent. We will provide additional recommendations and elaborate on AMD management’s blind spot: how they are uncompetitive in the race for AI Software Engineers due to compensation structure benchmarking to the wrong set of companies.
We will also discuss how AMD’s product launch cadence has put their current generation products against Nvidia’s next-gen products. Launching the MI325X at the same time as B200 has led to mediocre customer interest. Customers are now comparing the 8-GPU MI355X to the rack-scale 72-GPU GB200 NVL72 solution. Our demand view in the Accelerator Model tracked Microsoft’s disappointment early in 2024 and lack of follow-on orders for AMD GPUs.
We now believe that, there is renewed interest in AMD GPUs from OpenAI via Oracle and a few other major customers, but still not Microsoft, on the condition that they reach a sweet-heart pricing with AMD. We will also outline how AMD’s window for fully catching up to NVIDIA could open in H2 2026, when AMD will finally bring a rack-scale solution to production. These SKUs, the MI450X IF64 and MI450X IF128, could be competitive to NVIDIA’s H2 2026 production rack-scale solution (VR200 NVL144).
SemiAnalysis is actively working with NVIDIA and AMD on inference benchmarking on Hopper and CDNA3 class GPUs and will publish an article on comprehensive benchmarks and comparisons within the upcoming months.
Executive Summary
We met with Lisa Su to present our findings from the December AMD article and she acknowledged the many gaps in the ROCm software stack & expressed a strong desire to improve.
Over the past four months, AMD has made rapid progress on its AI software stack.
In January 2025, AMD launched its developer relations (devrel) function, mainly led by Anush Elangovan, AMD’s AI Software Czar. His focus is interacting with external developers on Tech Twitter and In Real Life events.
In January 2025, AMD recognized that external developers community are what made CUDA great and has since adopted a Developer First strategy.
Before SemiAnalysis published our AMD article in December, AMD had zero MI300X in PyTorch Continuous Integration/Continuous Delivery (CI/CD). AMD has since added MI300 into PyTorch CI/CD. AMD has made great progress over the past four months on CI/CD.
AMD plans to take a page out of Google’s TPU Research Cloud (TRC) book and launch a developer cloud at their upcoming Advancing AI event in June. The metric for success is if an GPT-J moment happens on their AMD’s community developer cloud.
AI Software Engineering compensation is AMD’s management’s blind spot. Their total compensation is significantly worse than companies that are great at AI software, such as NVIDIA and AI Labs.
AMD's internal development clusters have seen significant improvements over the past four months, yet these enhancements still fall short of what is needed to compete effectively in the long-term GPU development landscape.
AMD should considerably increase & prioritize allocations of its investments into R+D CapEx and OpEx initiatives to give their teams significantly more GPU resources for software development. The current short-sighted focus on quarterly earnings compromises its capacity for long-term competitiveness. AMD needs to invest significantly more GPUs, they have less than 1/20th of Nvidia's total GPU count.
Making the entire Cuda ecosystem first class on Python has been a top priority for Jensen. NVIDIA now has a pythonic interface at every level of the stack. ROCm does not have this. This is a serious threat to AMD's usability long term with developers.
Although RCCL has made some decent progress, the delta between NCCL and RCCL continues to significantly widen due to the new NCCL improvements and features announced at GTC 2025.
AMD has made some progress in the last four months on its software infrastructure layer (i.e., Kubernetes, SDC detectors, health checks, SLURM, Docker, metrics exporters), but its rate of progress is nowhere near keeping up with the rate of progress of AMD’s ML libraries.
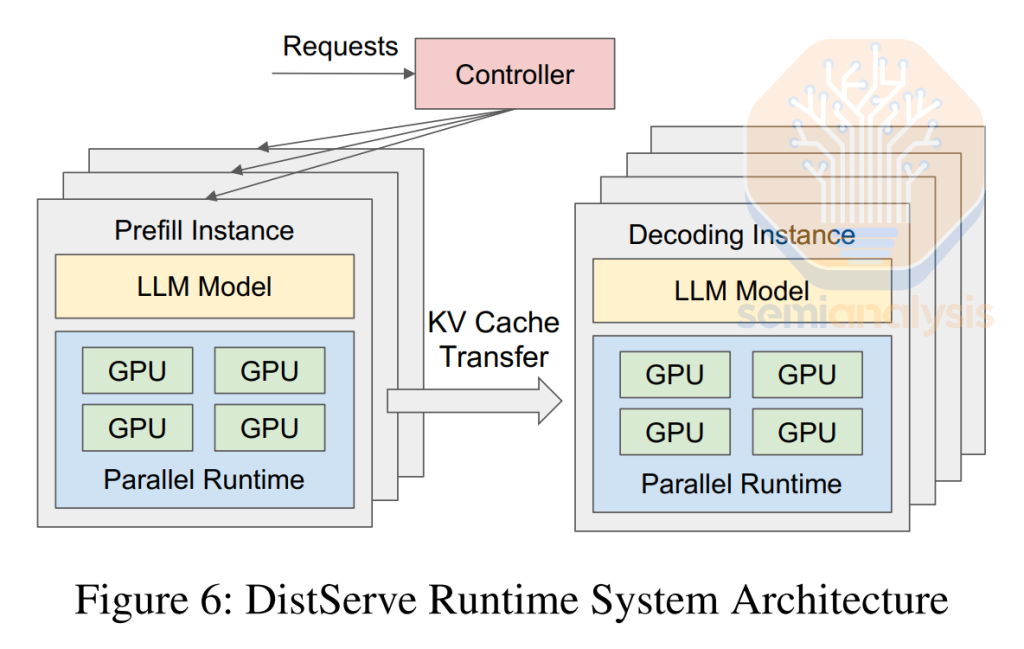
AMD is currently lacking support for many inference features, such as good support for disaggregated prefill, Smart Routing, and NVMe KV Cache Tiering. NVIDIA open-sourced Dynamo, a distributed inference framework, further democratizing disaggregated serving for NVIDIA GPUs.
The MI355X is still not competitive with NVIDIA’s rack scale GB200 NVL72 solution. Instead, AMD is pitching MI355X as being competitive to NVIDIA’s air-cooled HGX solutions, but this is not the purchasing comparison most customers are making.
By 2H 2026, AMD’s MI450X rack-scale solution, if executed properly, could be competitive against Nvidia’s VR200 NVL144.
SemiAnalysis is expanding the AI engineering team! If you have an experience in PyTorch, training, inferencing, system modelling, SLURM/Kubernetes, send us your resume and 5 bullet points demonstrating your engineering excellence to letsgo@semianalysis.com.
AMD is hiring engineers across the whole software stack. Drop Anush a note at anush+letsgo@amd.com.
What’s New Since our December AMD Article?
Hours after we dropped the AMD article, Lisa Su reached out to us to arrange a call with our engineering team to discuss in detail each of our findings and recommendations. The very next day at 7am PT, we presented our findings to Lisa and walked her through our experience during the prior five months working with the AMD team to try to fix their software to carry out various workload benchmarks.
We showed her dozens of bug reports our team submitted to our AMD engineering contacts. She was sympathetic to end users facing an unpleasant experience on ROCm and acknowledged the many gaps in the ROCm software stack. Furthermore, Lisa Su and her team expressed a strong desire for AMD to do better. To this end, for the next hour and a half, Lisa asked her engineering team and our engineers numerous detailed questions regarding our experience and our key recommendations.
This tone shift from the top has resonated across the organization. AMD is now in wartime mode, it is addressing software gaps and is working hard on closing them. This is a huge change from when AMD’s PR department in 2024 would not publicly acknowledge any major issues with software.
In 2025 thus far, AMD has acknowledged that their software has way more bugs are than Nvidia currently but are rapidly improving and are engaging the community to bring ROCm to parity. In particular, Anush Elangovan, the AMD AI Software Tzar, has been active in tackling the issues at AMD.
AMD’s Culture Shift – A Renewed Sense of Urgency
Acceptance is the final stage of grief. AMD has finally accepted its massive software gap and can now address its issues for its chance to beat NVIDIA in the software and hardware game. AMD has caught a second wind, but Nvidia is still at an all-out sprint, and AMD must match them and even outpace them to catch up. Nvidia’s staff clearly recognize that sometimes extra hours are needed for Nvidia to continue to be a leader in a competitive market. For AMD to win, it needs to work at least as hard and smart as Nvidia if not harder and smarter. We see clear signs of this starting to happen.
There plenty of examples of the focused and hungry teams catching up. xAI vs OpenAI is an example of how a shift in culture to adopt a sense of urgency and take a wartime stance can lead to a company catching up with the competition at a ludicrous speed.
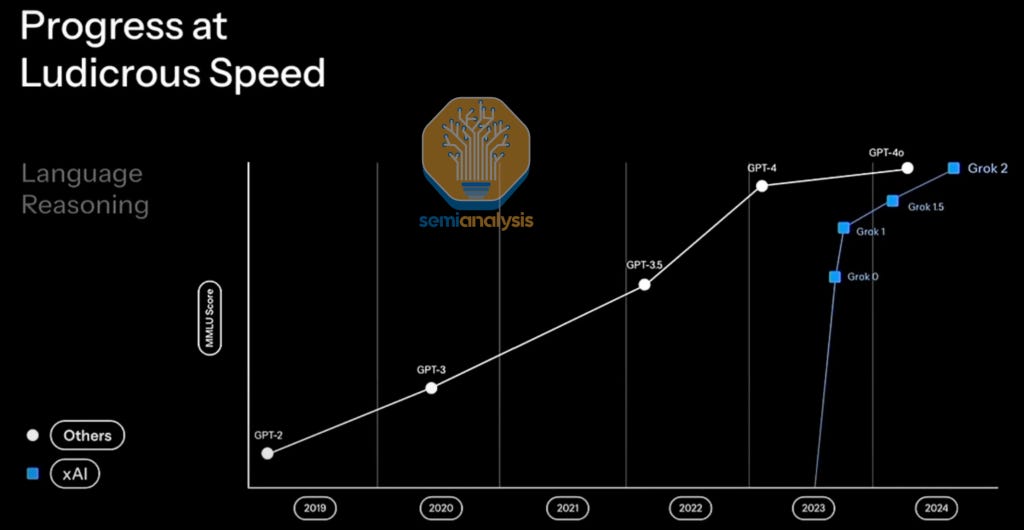
We see many concrete examples that show this dynamic starting to play out at AMD. One area where AMD was executing is their product roadmap to achieve parity with Nvidia on rack-scale solutions. We explain our estimates of their rack-scale MI450X solution later in the article.
Another example is AMD’s rapid progress on its AI software stack over the past four months. They have been showing significant improvements in both their training and inference performance, as well as their out-of-the-box experience. They even adopted SemiAnalysis code for their training benchmark.
In January 2025, AMD launched its developer relations (devrel) function as it has finally understood that developers are what made Nvidia’s CUDA great and now acknowledges that winning over developers will be critical to the success of ROCm. Currently, the developer relations team is led by Anush Elangovan, who is acting as the sole devrel for AMD at in-person events as well as on social media forums such as Tech Twitter.
AMD is going even further on the developer front. In June, AMD will launch a developer cloud focused on engaging with the overarching community. This is a direct result of SemiAnalysis’s suggestion for AMD to close the gap.

AMD now beats Nvidia in the reproducibility of benchmarks and performance claims. AMD has started posting easy-to-follow instructions that allow users and developers to replicate their benchmarking runs instead of publishing unrealistic or biased performance claims that can’t be verified. A great example is how AMD published a great blog on how to reproduce their MLPerf Inference 5.0 submission. NVIDIA did not provide such instructions as part of the latest MLPerf exercise.
What Makes CUDA Great?
CUDA’s greatest advantage isn’t just its internal software developers but also the ecosystem that includes 4 million external developers building on the CUDA platform, thousands of enterprises, and numerous AI Labs and startups. This creates a self‑reinforcing flywheel of tools, tutorials, and ready‑made kernels that lowers the barrier to adoption for every newcomer and keeps veterans moving fast. Due to this massive developer base, tribal knowledge is quickly shared with newcomers.
The result of this thriving ecosystem is that breakthrough ideas—whether new attention algorithms, state‑space models or high‑throughput serving engines—almost always appear on CUDA first, receive feedback sooner and get tuned harder on CUDA, which in turn attracts the next wave of developers.
The pay‑off from that collective energy is clear: when researchers publish a game‑changing kernel, the CUDA version typically launches day‑one. Tri Dao’s FlashAttention shipped reference CUDA code, and it took multiple quarters for ROCm to implement their own optimized attention. The selective‑state‑space model was the same, the authors only released a CUDA implementation but the authors themselves did not support or port it over to ROCm. The port of ROCm mamba was from AMD internal engineers and not the original authors. On the serving side, UC Berkeley’s vLLM and SGLang have their maintainers develop mainly on NVIDIA GPUs, and only after the CUDA path is stable do the maintainers then help AMD internal developers port to ROCm.
Another example is how bugs are discovered and patched faster thanks to the millions of external CUDA ecosystem developers. In contrast, on ROCm, it may take months before a bug is discovered, such as was the case with numerous bugs we discovered and reported last year. For example, ROCm’s torch.scaled_dot_product_attention API in 2024. Attention is the most important layer in start of the art transformer models.
Developers, Developers, Developers
Since January 2025 AMD has been vocal about a developers first approach, echoing Steve Ballmer’s famous mantra and mirroring Jensen’s approach too. At TensorWave’s “Beyond CUDA 2025” summit, Anush, AMD’s AI Software Tzar, framed ROCm’s future with three words—“developers, developers, developers” We believe this developers-first approach and messaging will be amplified on a broader stage at AMD’s June keynote event. AMD has finally understood that what made CUDA unbeatable was not just great silicon but a swarm of external developers. We feel extremely positive about AMD’s new developers-first approach.

In January 2025, Anush took this developers-first approach by engaging with external ROCm developers on Tech Twitter & GitHub collecting feedback, being customer support whenever ROCm craps out (which is often), and personally answering questions. This hands‑on engagement is real progress, but AMD’s developer relations still runs on a skeleton crew; aside from Anush, AMD has basically zero full‑time dev‑rel engineers. AMD has started hiring full time developer relations engineers, but to close the gap with NVIDIA’s army of evangelists, the company will need at least 20+ devrel engineers that host regular in‑person hackathons and meetups.
NVIDIA’s annual GTC developer conference, “Super Bowl of AI” packs more than 500 developer focused deep‑dive sessions and hands‑on labs into a single week. Those tracks—covering every layer of the stack from PyTorch to JAX to CUTLASS to CUDA C++ to Assembly to profiling tools —give external developers a reliable place to learn and push the frontier.
AMD, by contrast, still lacks a GTC style developer conference that has many developer focused sessions. The company’s June “Advancing AI” event will be great for roadmap reveals, but the event is essentially a few product keynotes plus a handful of prerecorded talks—nowhere near the multi‑track developer sessions, code‑lab depth developers get at GTC. If AMD is serious about its new developer‑first stance, it should launch an annual, in‑person ROCm Developer Conference: three to four days of parallel tracks that cover kernel authoring, graph compilers, HIP/Triton migration, MI300 cluster tuning, and real‑time debugging with the ROCm toolchain. Pair those talks with on‑site hackathons run by a beefed‑up (20‑plus‑strong) devrel team and follow‑up regional roadshows, and ROCm users would finally have a venue to share war stories, surface blocking bugs, and build the social fabric that made GTC indispensable to the CUDA community.

Although George Hotz could have settled for AMD’s earlier offer of cloud‑hosted MI300X systems with full BMC access, he insisted on physical hardware so he could “hack the metal” directly. AMD initially balked—even though Hotz’s goal was to help open‑source tooling on their GPUs. The stalemate turned into a public spectacle when the widely respected PyTorch co‑creator, Soumith Chintala, tweeted in support of Geohotz receiving the physical boxes.
We believe that this nudge worked, and a Geohotz March 8 blog revealed that AMD had relented, sending him the two MI300X boxes. With this, AMD finally passed Geohotz’s “cultural test.” For AMD, this is arguably a bigger reputational coup than a technical one—shipping real silicon to a high‑profile hacker signals a newfound, developer‑first ethos that marketing dollars alone can’t buy, and it finally turns a bruising Twitter saga into a story demonstrating AMD’s new developer-first ethos.
In addition to sending Geohotz boxes, we believe that AMD can also score another easy reputation and marketing win by donating physical AMD GPU boxes to academic labs. Jensen & Ian Buck has had a long history of donating GPUs to academics labs even going back as far as 2014. This year, Jensen continues to supporting academics labs such as CMU’s Catalyst Labs, Berekely’s Sky labs, UCSD’s HaoAI Lab and others for some time by donating physical gold plated B200 boxes to them in addition to providing free cloud access to NVIDIA GPUs.



Continuous Integration / Continuous Deployment (CI/CD)
Before SemiAnalysis published the AMD article in December, AMD had zero MI300X participating in PyTorch CI/CD. AMD has since added MI300 into PyTorch CI/CD. AMD had been well known for providing buggy software – adding MI300 into PyTorch CI will go a long way towards this effort of continuing to rid AMD’s software of bugs!
Previously, AMD’s did not want to spend money on investing in CI/CD resources, but we believe that this stance has changed over the past four months. At the ROCm SF developer meetup events, an AMD software engineer walked up to us, thanked us, and told us that they now have CI resources due to our efforts.
In addition to unit test CI, AMD has also enabled MI300X on TorchInductor Performance CI such that performance is tracked in inductor /torch.compile commit. According to a Meta CI engineer, AMD provided the MI300X nodes, while NVIDIA hasn't provided any resources, so Meta pays for all of the A100 and H100 capacity. For this specific compile CI, AMD is ahead of NVIDIA. However – there is still much progress to be had as AMD’s dynamic shapes torch.compile is only at a 77% pass rate compared to Nvidia’s 90%+.
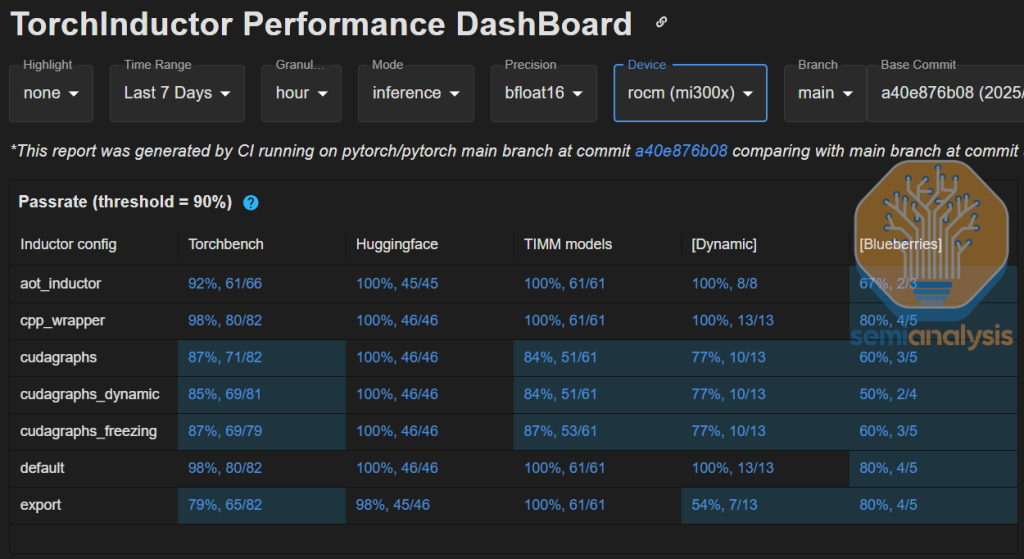
AMD should build on this progress by open sourcing and making all of their CI/CD and dashboards publicly accessible such that anyone can see the pass rate of AMD’s software across all ROCm libraries (HipBLASLt, Sglang, vLLM,TransformerEngine, etc). Currently, the only publicly accessible ROCm CI for their ML libraries is PyTorch.
Upcoming Community Developer Cloud
One of the reasons that Google’s TPU was able to gain external developer adoption was due to TPU’s free Colab access and because it provided large cluster access via TPU Research Cloud (TRC). This allowed the community quick and free access, enabling many interesting projects as shown in TRC’s spotlight and the many papers published as part of TRC. In fact, in 2020, well before the ChatGPT moment, a high schooler was able to train a model that was competitive with GPT-2 on a relatively giant TPU pod for free. In addition to providing plenty of smaller 8-16 chip pods, TRC also regularly provides free 1-2-week access to 1000+ chip pods to researchers.
The famous open source GPT-J model was also trained on TPUs for free leading to an complete open repo about how to use TPUs with JAX and furthering external community adoption of TPUs. TRC has been wildly successful at promoting the TPU and supporting the open-source community.
AMD’s developer cloud plans essentially take a page out of Google’s book. We believe that if AMD properly invests in enough GPUs for this developer cloud program such that its GPUs easily and freely accessible, AMD’s developer cloud will be able to help it broaden adoption of its GPUs. This is a key battle AMD must win in its race against NVIDIA.
The metric for success is if an GPT-J moment happens on their AMD’s community developer cloud.

AMD Management’s Blind Spot – AMD AI Software Engineer Compensation
AMD faces a critical challenge in its AI software division due to non-competitive compensation, significantly impacting its ability to attract and retain top talent. Other companies that are known for developing great AI software pay significantly better than AMD.
While compensation isn't everything, it remains a significant factor influencing engineers' decisions. Engineers often evaluate career opportunities based on multiple factors, including technical challenges, workplace culture, and growth opportunities. However, competitive compensation remains critical, particularly in highly specialized fields such as AI software engineering.
It is well known amongst AI engineers that the total compensation packages at AMD, which include base salary, RSUs (Restricted Stock Units), and bonuses, lag considerably behind competitors like NVIDIA, Tesla Dojo, OpenAI Chip Team, Google TPU, and xAI, etc.
In conversations with top AI software engineers about why they chose not to join AMD, many highlighted that working at AMD software feels like working on porting features that NVIDIA engineers developed two years earlier. In contrast, NVIDIA provides engineers with the opportunity to work on cutting-edge software and to build software for chips used in state-of-the-art models like o3, for both training and inference.
Additionally, engineers attracted to the "David" in a "David vs Goliath" scenario often choose Google TPU or the OpenAI Chip team over AMD. These teams offer significantly better compensation and arguably have a higher probability of success in competing against NVIDIA due to those companies having giant volume of internal workloads to be their own customers. This makes them more appealing options for ambitious engineers.
AMD's internal benchmarking of their compensation structure appears to cherry pick comparable companies. By benchmarking against semiconductor companies that aren't known for great software such as Juniper Networks, Cisco, and ARM, AMD may mistakenly perceive their compensation as competitive. However, when correctly benchmarked against companies renowned for AI software such as GPU kernels, GEMMs, PyTorch internals, distributed training infrastructure, and inference engines—the gap in pay becomes glaringly apparent.
When conducting a proper apples-to-apples comparison, for example, comparing an NVIDIA PyTorch Lead to AMD's PyTorch Lead or NVIDIA's NCCL engineers to AMD's RCCL engineers, NVIDIA pays significantly better and thus is able to attract and retain top talent.
This issue represents a critical blind spot in AMD management's strategy. We think that AMD understands how essential software engineers are to AMD’s long-term competitiveness and innovation and wants to place them at the core of their strategy, but we think the blind spot comes from inaccurate benchmarking and attempting to make comparisons in broad strokes – a fog of war, as it were. This unfortunately has resulted in a persistent undervaluation of software which risks further exacerbating the company's weaker software capabilities relative to its direct competitors.
AMD should keep AI software engineering base salaries stable but implement substantial increases in RSUs. By tying engineer compensation more closely to AMD’s future growth and, the company can more directly align the interests of their top talent with long-term organizational performance.
Given AMD’s financial position with over $5 billion in cash reserves, the company possesses ample capacity to invest strategically in software talent. Leadership must now decide to prioritize retaining and attracting high-caliber engineers through meaningful compensation enhancements. Without taking such action, AMD risks perpetuating its lag behind NVIDIA, undermining its progress in the rapidly evolving AI market.
Internal Development Clusters Needs More Budget
AMD's internal development clusters have seen significant improvements over the past four months, yet these enhancements still fall short of what is needed to compete effectively in the long-term GPU development landscape.
Currently, AMD claims to have rented an aggregate capacity of ~8,000 MI300 GPUs from CSPs distributed across several clusters and it claims that among this, the largest single cluster contains about 2,000 MI300 GPUs. However, deeper examination suggests the realistic consistent availability may be closer to 3,000 to 4,000 GPUs in aggregate across the whole company as AMD internally operates on a burst model. Internal developers now have adequate access to single-node development resources, but multi-node and comprehensive cluster development remain constrained. This limitation severely impacts larger-scale projects and collaborative development efforts, and there is still a need for a substantial increase in absolute quantity and consistency of GPU availability.
Moreover, with the new industry-standard approach of datacenter-scale disaggregated prefill optimization for inferencing, even developing inference solutions now requires resources at the cluster scale. AMD’s current limited cluster level resources for individual internal developers further complicates its ability to effectively innovate and compete in this evolving landscape.
A major impediment to further expansion and innovation at AMD is the short-term, burst-oriented model for procurement of clusters for internal use, with most contracts lasting less than a year. This contrasts starkly with NVIDIA's strategy, which employs persistent, multi-year cluster deployments, giving engineers greater freedom to pursue creative and high-risk projects without continuous oversight from financial controllers. NVIDIA, for example, operates extensive internal GPU resources including the A100 Selene cluster with thousands of GPUs, two EOS clusters (one with 4,600 H100 GPUs and another with 11,000 H100 GPUs) alongside dozens of smaller 64-1024 sized H100/H200 clusters located both on-premises and rented from cloud providers such as OCI, Azure, CoreWeave, and Nebius, etc. The massive scale of the GB200 clusters they will get this year. The above numbers also exclude the billions of dollars of clusters for DGX Cloud that they have.
AMD's current setup, where each GPU hour effectively carries a direct profit-and-loss consideration, discourages essential exploratory projects and strategic long-term developments.
AMD must urgently pivot from its current sub-year cluster strategy toward signing long-term, multi-year commitments, and it should specifically invest in a substantial cluster of 10,000+ flagship class GPUs. Such a commitment would demonstrate AMD's dedication to each GPU generation, like NVIDIA’s robust, long-term software and hardware support spanning multiple years for every GPU generation. The existing burst model is significantly damaging AMD’s internal development efforts and limiting innovation potential. Transitioning to a sustained, multi-year investment approach will enable AMD to pursue strategic innovation and competitive advantage effectively.
With over $5 billion in available cash reserves, AMD clearly has the financial flexibility to shift toward a more strategic, long-term investment approach. The current short-sighted focus on quarterly earnings compromises AMD’s capacity for future innovation and development leadership. Adopting a multi-year commitment to GPU generations would significantly enhance long-term support, aligning AMD’s internal capabilities more closely with customer expectations. This strategic adjustment would also reassure customers regarding AMD’s commitment to sustained support and innovation, thereby strengthening market confidence and long-term partnerships.
ROCm’s Lack of First-Class Python Support
Making the entire CUDA ecosystem a first-class experience on Python has been a top priority for NVIDIA for the past 12 months. None other than Jensen himself is personally looped in and managing this effort. In the 2010s, Jensen was the first to understand that investing into making CUDA software great for AI would pay dividends. In 2025, Jensen’s key insight is to now understand that the de facto language of AI is Python, and that supporting every layer of NVIDIA’s current C++ CUDA stack into the Python world will yield a high return on investment. AT GTC this year, NVIDIA released dozens of Python libraries from GEMM libraries like nvmath-python libraries to cuda.binding cuBLASLt bindings to kernel DSLs like cuTile, Warp, Triton, CuTe Python. Unfortunately, ROCm libraries support in Python is nowhere near what NVIDIA has. NVIDIA has a python interface at every layer of the stack. AMD does not offer this.
By supporting Python first class in CUDA, end users can spend less time to get the same performance or spend the same amount of time to get even better performance. CUDA Python effectively shifts the pareto frontier curve on “Performance of Application versus Time Spent Optimizing”
To use a simple example, previously if a developer wanted to call cuBLASLt with a custom epilogue, they would need to write a C++ extension and then Pybind it to Python which is a bit convolved and adds another layer of indirection that an ML engineer needs to worry about. Now with nvmath-python, the same task can now be carried out and automatically tuned with just 3 python lines. The task is now turned from a 30-minute task to a 2-minute one. These NVIDIA Python libraries aren’t just half-baked bindings, they are first-class implementations with performance top of mind.

In another example, with the cuda.cooperative device side library, one can now access speed of light CUDA prebuilt algorithms such as block reduce through a python interface. This level of performance was previously only available in C++ CUDA through CUB.

For end users that want 1:1 Python bindings instead of higher order Pythonic libraries, NVIDIA also offers this through cuda.binding and cuda.core. NVIDIA has a python interface at every layer of the stack. AMD does not offer this.
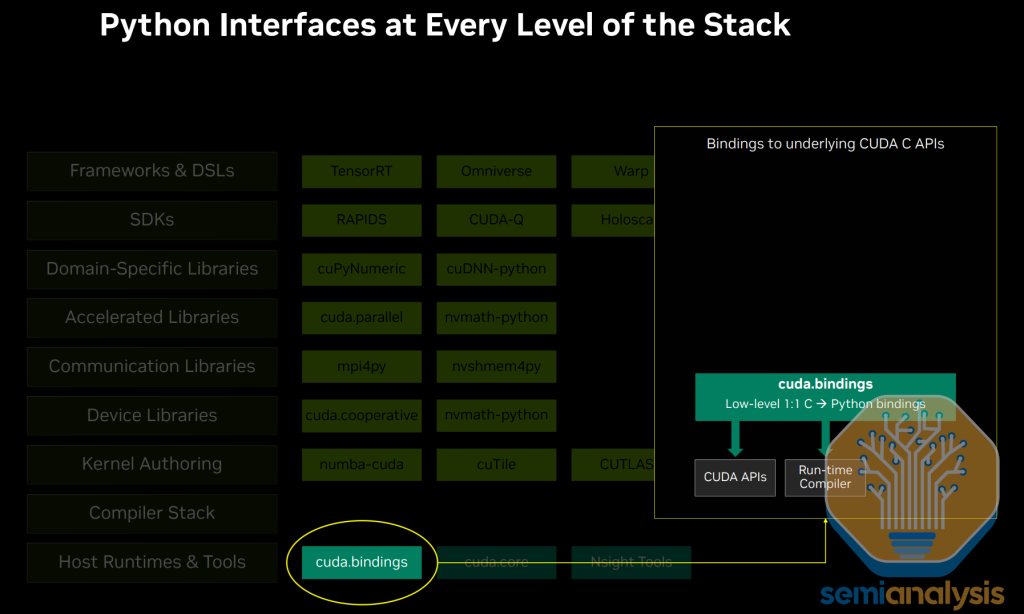
AMD has launched recently python interfaces for AITER which is the equivalent of cuDNN-python and supports OAI triton for kernel authoring but the rest of the layers of the stack, ROCm has no comparable product and they aren’t even thinking about supporting a first-class python experience yet.
Python GPU Kernel Authoring DSLs
At GTC 2025, in addition to debuting the overall Python CUDA libraries, NVIDIA also announced Python kernel authoring DSLs - namely Python CuTe 4.0, cuTile Python and Warp. And this is on top of Nvidia’s existing Triton DSL support! AMD is lacking and uncompetitive in the Python Kernel DSLs space to the extent that Nvidia teams are now competing against each other with multiple different NVIDIA DSLs now publicly launched. There are currently five different NVIDIA python DSLs (OAI Triton, CuTe Python, cuTile Python, Numba, Warp), with many more that are internally in the works that they haven’t announced publicly yet.
Python kernel DSLs can be categorized into two types based on the abstraction unit. Programmers describe single-thread behaviors in thread-based languages, while in tile-based languages, they describe operations on partitions of matrices.
CuTe Python is NVIDIA’s recommended path for writing speed-of-light kernels in for thread-based Python kernel DSLs. It provides low-level primitives as building blocks for custom kernels, and it uses a powerful abstraction cuTe (CUDA Tensor) to describe data and thread layouts. CUTLASS Python’s API design is based on CUTLASS, so new users can leverage CUTLASS’s extensive documentation of concepts and usage to get up to speed. While AMD has a CUTLASS-analogous C++ library CK (Composable Kernel), its documentation on concepts and usage is comparatively sparse and unclear. CK Python interface is coming for their high-level interfaces but none in the works for their CuTe-analogous atom layer.
More importantly, AMD in general currently has no Python DSLs for thread-based kernel programming which is needed for speed of light.

For Tile Based and SIMT based as well as hybrid Tile/SIMT mixed based kernel authoring Python DSLs, NVIDIA announced cuTile at GTC 2025. cuTile is not meant for 100% speed of light performance but is meant for 98% speed of light performance at 10% the time to write the kernel. It is relatively easy to write kernels in cuTile. Unfortunately, AMD has no offering for hybrid SIMT/Tile based python kernels DSLs.
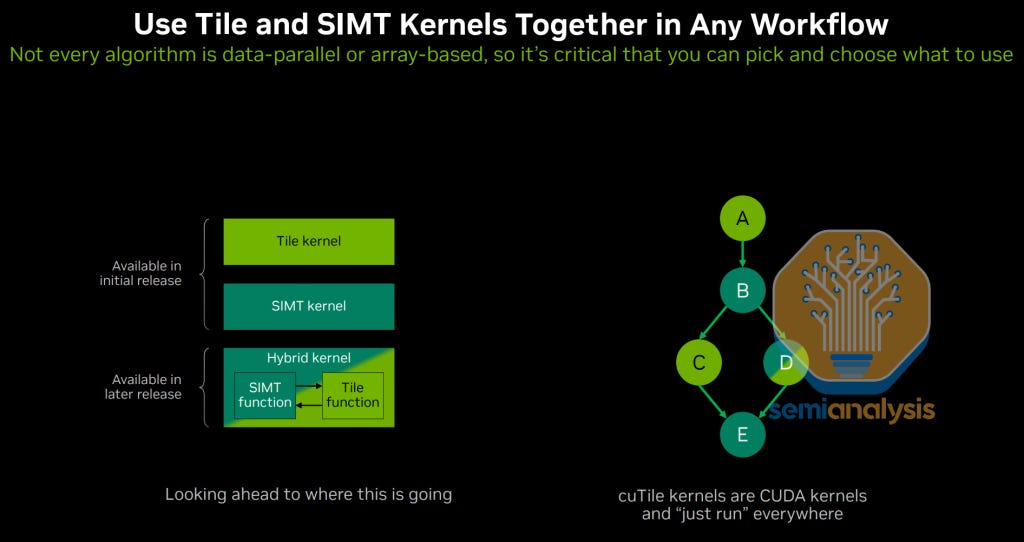
Triton popularized tile-based programming models in the age of tensor cores where the effective abstraction is at the layer of a Tile instead of on a per thread basis. Nvidia will continue to fully support Triton’s Tile based DSLs in addition to cuTile Tile based DSLs.

For differential simulation AI, NVIDIA announced Warp Python DSLs. Warp is a hybrid tile and SIMT based programming model useful for writing simulations and geometry processing. The great benefit of Warp over cuTile is that Warp is automatically differentiable which is extremely useful in simulation to automatically generate the backward pass. AMD has no offering for this hybrid SIMT/Tile based differentiable Python kernels DSLs either.
Nvidia continues to fully support OpenAI Triton Python DSL in addition to all their newly announced Python DSLs. The primarily maintainer of Triton is OpenAI whose mission is to build safe AGI. Indeed, at the SemiAnalysis Blackwell PTX Hackathon 2025, Phil Tilet, lead OpenAI maintainer of Triton, has even said that “AGI won’t come from 10% faster matrix multiplications”, & this is the ethos surrounding what features Triton will prioritize. Thus Triton isn’t the platform AI chip vendors should solely support if they want to have the fastest AI chip. We believe that AI chip vendors should still fully support Triton in addition to other Python DSLs.

This stance has led to a misalignment of objectives where OpenAI Triton does not care about getting absolute speed of light peak performance while AI Chip vendors like Nvidia, MTIA, MAIA, AMD care a lot about getting peak performance in their kernel language.
Nvidia’s Triton performance isn’t close to speed of light while AMD’s Triton performance is even further away from speed of light. AMD needs to heavily hire and invest into making Triton performance much stronger in addition to supporting/inventing in other python kernel DSLs.
AMD has an experimental kernel language called wave that uses a warp based programming model but it seems to be still very early stage and doesn’t have the full backing of the company. This is a far cry from cuTile, CuTe, Warp, all of which have the full backing of Jensen and Nvidia, who are all in on making CUDA Python great. Furthermore, it is questionable if warp-based kernel DSLs add the right abstraction layer considering the industry is moving towards warp-group based MMAs hardware & 2-CTA MMAs hardware instead of warp based MMAs.
The Widening Gap Between AMD RCCL and NVIDIA NCCL
Collective communication libraries are extremely important for AI training and inference as these libraries let multiple GPUs work on the same workload. Nvidia’s collective communication library is called NCCL. AMD’s library is a “ctrl+c, ctrl+v” fork of NCCL and it is called RCCL. Ever since we shared our thoughts on RCCL in our December 2024 article, RCCL team has made some decent progress. More than a year after the MI300X went into production, the RCCL team has now finally supported the LL128 protocol on MI300X. This is a great improvement but by comparison, Blackwell on day one already supports all three collective protocols (SIMPLE, LL, LL128).
Furthermore, RCCL finally supports rail optimized trees which improves networking performance by reducing traffic away from spine switches, leading to fewer path collisions. This feature has been supported by NCCL by countless years already.
Although RCCL has made some decent progress, the delta between NCCL and RCCL continues to significantly widen due to the new NCCL improvements and features announced at GTC 2025. TheRCCL team will need more access to proper resources like large compute clusters to catch up with NCCL. They should be given exclusive access to a persistent cluster of at least 1,024 MI300 class GPUs. Furthermore, AMD leadership needs to invest into massively increasing RCCL engineer RSUs compensation in order to attract and retain key talent in what is one of the most mission critical software libraries.
Because AMD’s RCCL library is a carbon copy fork of Nvidia’s NCCL, NCCL 2.27 and 2.28 massive refactor will continue expanding the CUDA moat and will force AMD’s RCCL team to expend thousands of engineering hours to sync Nvidia’s major refactor into RCCL. While AMD’s engineering team is bogged down having to spend thousands of engineering hours to sync the changes, Nvidia will be using that time instead to continue advancing the frontier of collective communications software stack and algorithms. This dynamic makes it virtually impossible for AMD to sustain RCCL’s existing development efforts while working towards achieving parity with NCCL, let alone surpassing NCCL.
AMD has indicated that they are currently in the planning phase of rewriting RCCL from scratch to stop being a fork of NCCL.
At his GTC 2025 talk, as a joke, we asked NCCL chief Sylvain Jeaugey, if in the spirit of open-source development, he would lend a helping hand to RCCL as its currently mostly a copy paste library.
He rebuffed our suggestion:
SemiAnalysis: Will Nvidia provide support to the AMD team's RCCL fork due to this big of a refactor in the upcoming 2.28?
Sylvain: Are we going to also help RCCL move to that? I don't think so - usually we don't really take part in that development.
Source: Nvidia – timestamp 33:48
During this talk, Sylvain also announced many new NCCL features in the upcoming massive refactor. These new features include supporting symmetric memory natively in NCCL as well as new algorithms that run much faster and use fewer SMs thus allowing more SMs for compute.
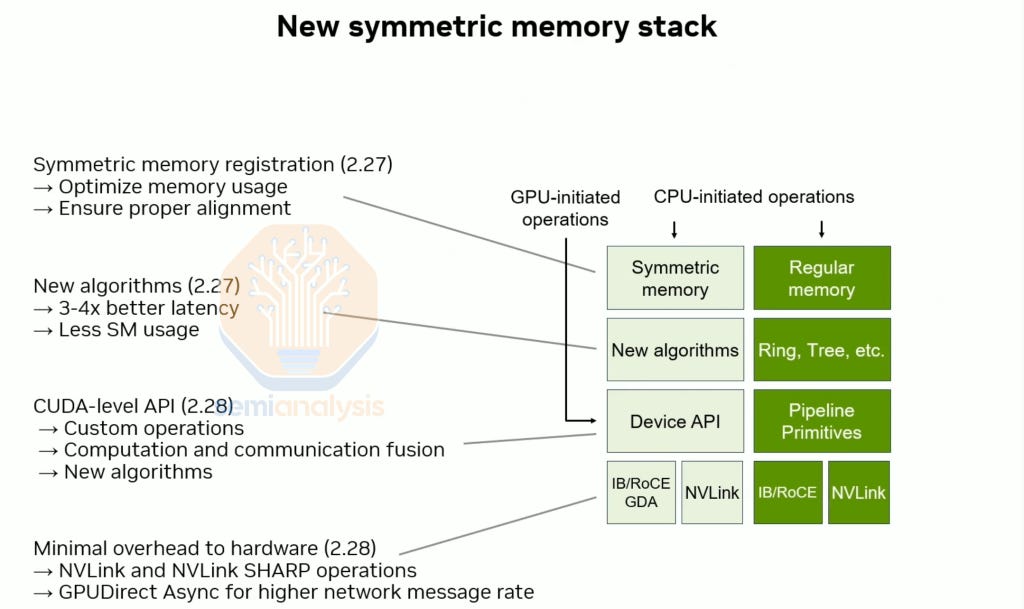
PyTorch introduced SymmetricMemory API that enable users to harness multi-GPU scale up programmability with ease and write collectives or fused compute/communication kernels in CUDA or Triton. Previously, writing multi-GPU fused compute/communication kernels required a ton of work, but the work needed has been reduced considerably with the use of PyTorch SymMem. Performant inference kernels like one-shot and two-shot collectives as well as all gather fused matmul kernels can be written in SymmetricMemory easily.
This feature has been available on NVIDIA GPUs for the past 8 months while AMD GPUs still don’t support it. AMD has indicated that they will land initial support for PyTorch SymmetricMemory API in Q2 2025.
In the upcoming 2.27 release, allreduce achieves a 4x lower reduction at the same message size and attains the same algorithm bandwidth at 4x smaller message sizes.
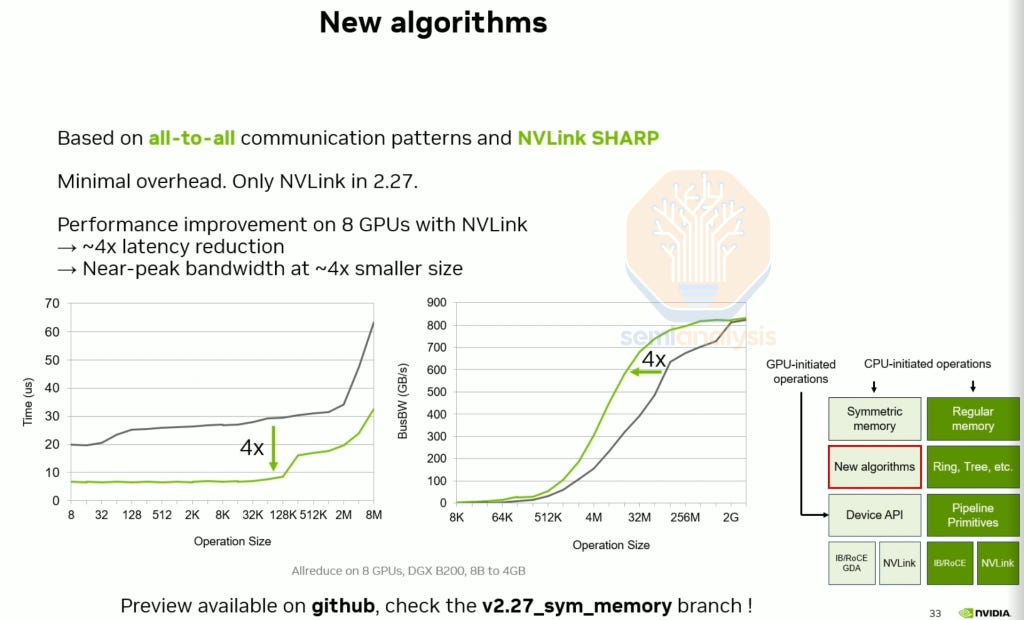
In the upcoming 2.28 release, NCCL offers device-side APIs allowing end users to easily write custom communication/compute fusion kernels.
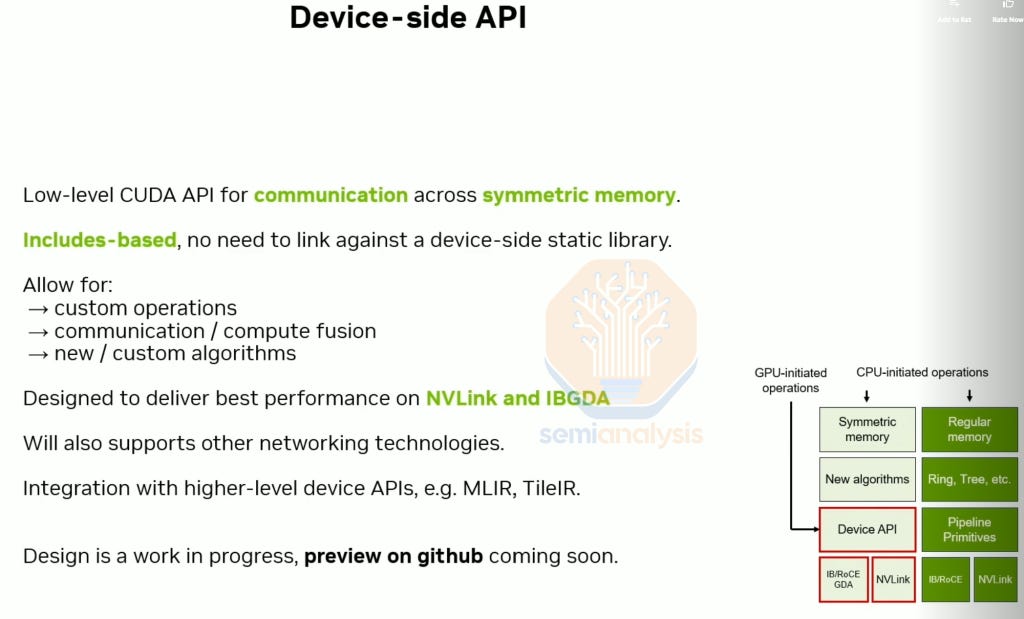
The upcoming NCCL 2.28 release will also support GPUDirect Async (IBGDA) on both InfiniBand and RoCEv2 Ethernet. Currently, in NCCL and RCCL, a CPU proxy is used to control flow for scale-out communication. Although the dataflow doesn’t go through the CPU, sending the control flow through the CPU still limits the real world achieved performance. With NVIDIA NCCL’s 2.28 integration with IBGDA – supported in both RoCEv2 and InfiniBand - the control flow is initialized by the GPU and does not go through the CPU, leading to better performance on all2all and all2all based algorithms across small and medium message sizes.
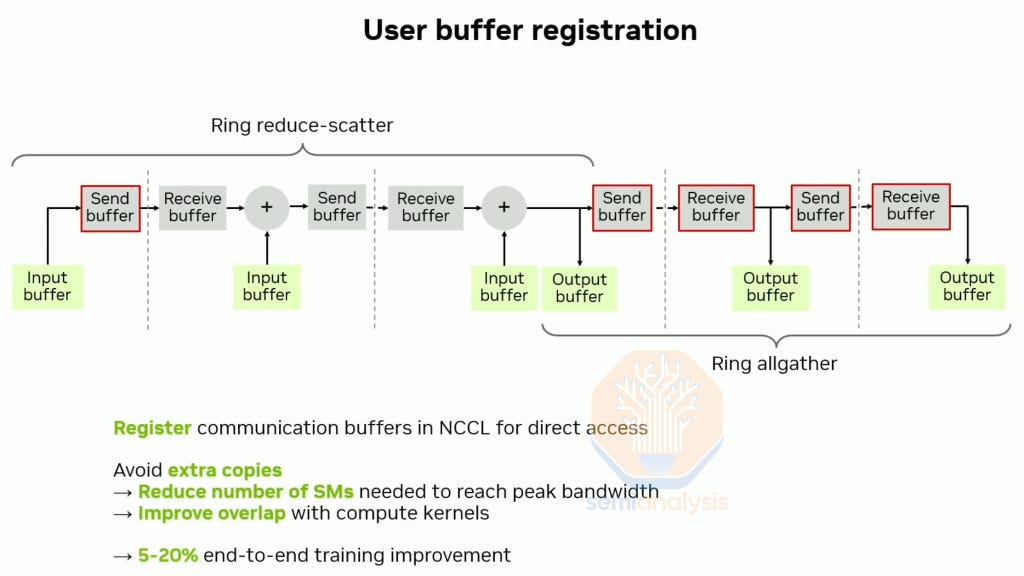
Another feature that is currently only available on Nvidia is user buffer registration. This feature avoids creating extra copies between the user’s tensor and NCCL’s internal buffers. This helps with reducing the number of collective SMs needed and with alleviating memory pressure, leading a 5-20% end to end training improvement.
Most experienced ML engineers have seen the dreaded NCCL_TIMEOUT/RCCL_TIMEOUT or NCCL/RCCL stalling. NVIDIA NCCL supports ncclras, which simplifies debugging these issues. Unfortunately, RCCL does not currently include any features to help with debugging.

Infrastructure Software Progress Not As Fast
AMD’s has made meaningful progress in the last four months on its software infrastructure layer (i.e. kubernetes, SDC detectors, health checks, SLURM, docker, metrics exporters), but the rate of progress is nowhere near keeping up with the rate of progress of AMD’s ML libraries.
Until seven months ago, AMD had no GPU metrics export function at all, meaning that cluster operators had no way to gain observability into their GPUs. Although ROCm claimed to be an open-source ecosystem, AMD’s GPU metrics exporter was not open source until SemiAnalysis took this point up with AMD executives, advocating for them to adopt a sense of urgency for AMD to live by the ethos of their claimed commitment to the “open source” ecosystem.
Fortunately, after many follow-ups, AMD has finally open sourced their GPU exporter. Note that their GPU exporter is still a work in progress and many features are still missing and are not at parity with NVIDIA’s GPU open-source metrics exporter yet. For example, AMD’s GPU exporter currently has still does not support the metric for matrix core activity, CU occupancy or CU active. These are extremely important metrics to proxy how workloads are performing. The only current utilization metric available in AMD’s GPU exporter is GPU_UTIL which, as most experienced ML engineers know, doesn’t actually measure util at all for both Nvidia and AMD GPUs.
As mentioned in our December AMD article, the AMD Docker UX is extremely poor compared to Nvidia’s UX. AMD has acknowledged this shortcoming and has mentioned to us that they are working on this. They have indicated that they will announce a roadmap for this later this quarter.

Unlike on Nvidia’s stack, the current state of Slurm+Container on AMD’s stack is disappointing. On Nvidia with open source pyxis Slurm, launching container through Slurm is as easy as running “srun –container-name=pytorch”. In contrast, when working on AMD, one must through an extremely convolved process that requires the use of lots of indirections.
When considering how all AMD’s internal AI engineers use SLURM with containers, it is distressing to see the amount of indirection that are needed and how poor the current AMD Slurm+Container UX is.
We have recommended on multiple occasions that AMD prioritize fixing this and focus on supporting a first-class Slurm+Containers experience by putting some money to work and paying for SchmedMD’s (the maintainers of Slurm) consulting services. We have yet to see any concrete timelines or roadmap on when AMD plans to fix this issue.
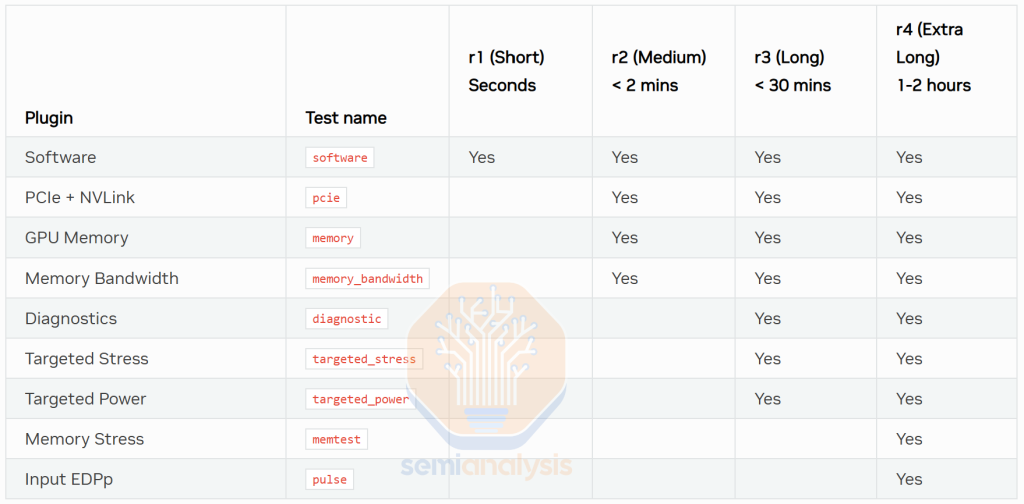
Moreover, Nvidia’s datacenter-manager tool (DCGM) has directly integrated NVVS (Nvidia Validation suite) such that running diagnostics is as simple as running “sudo dcgmi diag -r <diag_level>”. In contrast, on AMD, the RVVS (ROCm validation Suite) is separate from their Datacenter tool (RDC), forcing the end user to download yet another library. We recommend that AMD integrate RVVS into RDC to make the user experience as simple as that of Nvidia’s DCGM.
Also, AMD’s UX and validation coverage is not as good as DCGM’s. Nvidia’s DCGM utilizes notation denoting different levels (r1,r2,r3,r4) while AMD’s NVVS does not use any such notation.
AMD’s Lack of Disaggregated Prefill Inferencing and NVMe KV Cache Tiering
AMD is currently lacking support for many inference features such as disaggregated prefill, Smart Routing, and NVMe KV Cache Tiering. Disaggregated serving has been an industry standard for year, and last month NVIDIA open-sourced Dynamo, a distributed inference framework, further democratizing disaggregated serving. Disaggregated prefill splits the prefill stage and decode stage into different GPUs. Even Google has launched their own disaggregated inferencing framework.
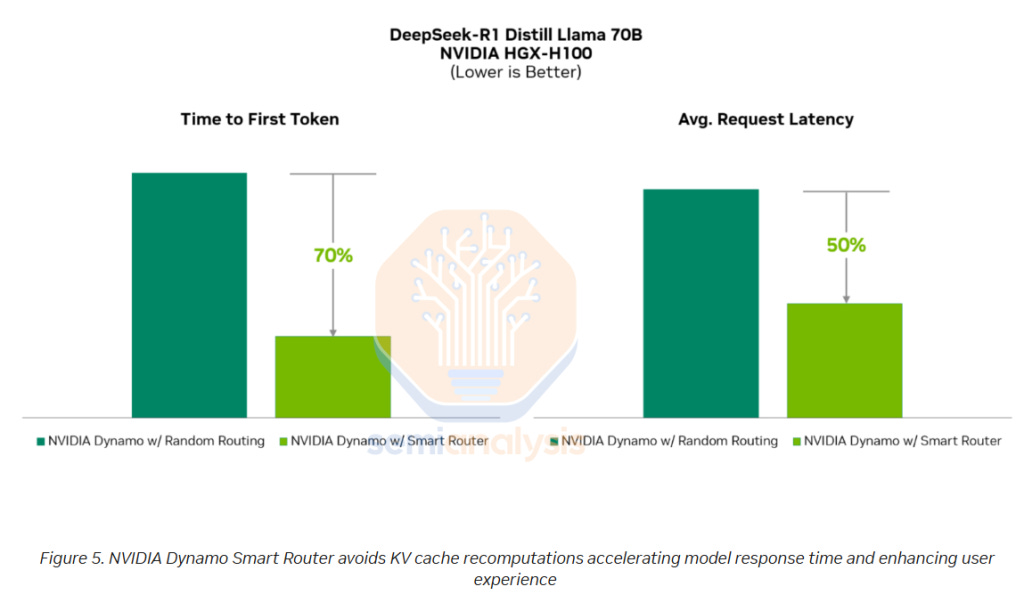
NVIDIA’s Dynamo Smart Router intelligently routes each token in a multi-GPU inference deployment to both available instances. For the prefill phase – this means ensuring that incoming tokens are equally distributed to the different GPUs serving prefill to avoid bottlenecks on any given experts in the prefill phase.
Similarly – in the decode phase – it is important to ensure sequence lengths and requests are well distributed and balanced across GPUs serving decode. Some experts that are more heavily trafficked can be replicated as well by the GPU Planner provided by Dynamo to help keep the load balanced.
The router also load balances across each replica serving the model which is something AMD’s vLLM and many other inference engines do not support.
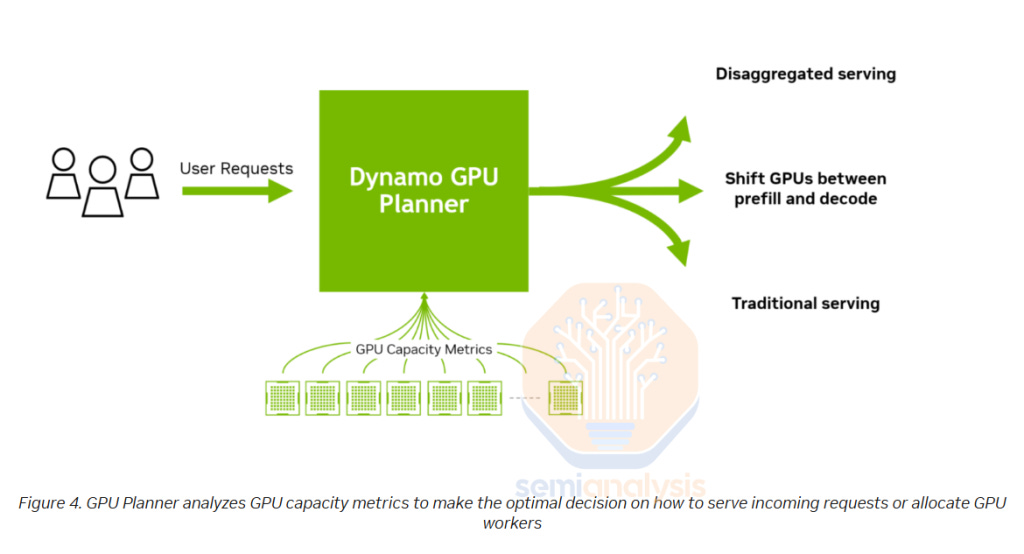
Dynamo’s GPU Planner is an autoscaler of both prefill and decode nodes, spinning up additional nodes with fluctuations in demand that are natural over the course of the day. It can implement a degree of load balancing among many experts in an MoE model in both prefill and decode nodes. The GPU planner spins up additional GPUs to provide additional compute to high-load experts. It can also dynamically reallocate nodes between prefill and decode nodes as needed, further maximizing resource utilization.
This additionally supports changing the ratio of GPUs used for decoding and for prefill – this is especially useful for cases like Deep Research, where more prefill is required as opposed to decoding, as these applications need to review a huge amount of context but only generate a comparatively small amount.
NVIDIA Dynamo’ KV-Cache Offload Manager allows more efficient overall execution of prefill overall by saving the KVCache from prior user conversations in NVMe storage rather than discarding it.
When a user engages in an ongoing multi response conversation with an LLM, the LLM needs to factor in the prior questions and responses earlier in the conversation, taking these as input tokens as well. In the naïve implementation, the inference system will have discarded the KV Cache originally used for generating those earlier questions and responses, meaning that the KV Cache will have to be computed again, repeating the same set of calculations.
Instead, with Dynamo’s NVMe KVCache offload feature, when a user steps away, the KVCache can be offloaded to an NVMe storage system until the user returns to the conversation. When the user asks a subsequent question in the conversation, the KVCache can be quickly retrieved from the NVMe storage system, obviating the need to calculate the KVCache again.
This frees up capacity on the prefill nodes to handle more incoming volume, or alternative could reduce the size of the prefill deployment needed. The user will also have a much better experience with faster time to first token as there is now much less time needed to retrieve the KV Cache vs computing it.
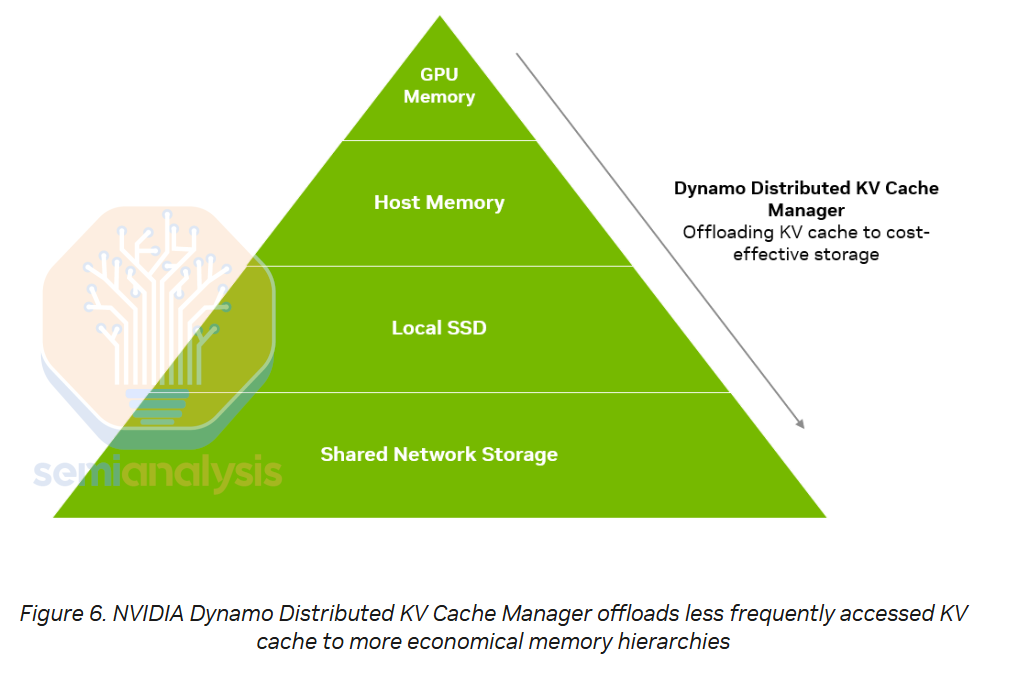
These features for KVCache offload will matter more and more as RLVR and multi-agent systems with tool use become more common.
Summary of Recommendations to AMD
We genuinely want to see another effective competitor to Nvidia and want to help AMD get to that spot. AMD has made great progress over the past four months but there are still a lot of changes that AMD needs to make to be competitive with Nvidia. Earlier in the article, we have outlined in detail our recommendations to Lisa Su and the AMD Leadership Team, and we provide a summary here:
AMD needs to maintain (if not intensify) their sense of urgency to even have a chance at being on par with NVIDIA.
AMD leadership team’s biggest blind spot is low total compensation (base + RSU + bonus) for their AI software engineers due to incorrect compensation structure benchmarking to semiconductor companies instead of companies that are great at AI software. We have discussed how our recommendation will help strengthen the alignment of engineers’ compensation to AMD’s success (or failure). We strongly believe that if AMD does not significantly increase their AI Software Engineer pay, AMD will continue losing to Nvidia.
We recommend that AMD invest heavily in Python interfaces at every layer of the ROCm stack, and not just in Python Kernel Authoring DSLs.
AMD needs to invest heavily in a team of 20+ developer relations engineers hosting In Real Life events and interacting with the community at a deeper level.
Unlike NVIDIA GTC, AMD doesn’t hold any developer-focused conferences and only holds product launch keynote events, for instance “Advancing AI”. We recommend that AMD host an in‑person “ROCm Developer Conference”.
NVIDIA has launched their Dynamo disaggregated prefill inference framework called and their NIXL inference KV cache tiering library. AMD does not have first-class support for disaggregated prefill or NVMe KVCache tiering. They need to rapidly make progress on this, or they will fall behind on inference.
AMD should give ROCm collective engineers a persistent cluster of at least 1,024 MI300 class GPUs that are for the exclusive of this team. This will go a long way towards helping RCCL catch up to NCCL.
Nvidia overstates TFLOP/s in their chip specifications, but AMD overstates TFLOP/s specifications even more. Even in AMD’s own blog, they have admitted to a significantly larger gap between their marketed TFLOP/s and what is achievable than users might experience with NVIDIA.
AMD should state their Model FLOPS Utilization (MFU) and TFLOP/s/GPU whenever they publicly announce a new in-house model training run. AMD does not currently do this. We have asked AMD repeatedly about their MFU but so far, we have not received a satisfactory answer. This could lead one to assume their MFU is quite low.
In contrast to Nvidia’s Pyxis solution, first-class support for AMD SLURM for containers is non-existent. AMD’s should invest in SchedMD (maintainers of SLURM) consulting to help get containers in AMD SLURM to be on par with NVIDIA.
AMD should open source and make all of their CI/CD and dashboards publicly accessible across all ROCm libraries (HipBLASLt, Sglang, vLLM,TransformerEngine, etc). Currently, the only publicly accessible ROCm CI for their ML libraries is PyTorch.
Currently AMD has internal clusters on a short-term basis on a burst model. But since demand for compute matches the available supply of compute, that means that there is a lot of development projects and efforts that can’t be carried out. This happens often when engineers are not able to convince capacity gatekeepers to provide burst compute capacity to carry out this research. The roadblock is the fact that there is an effective P&L attached to every GPU hour. The situation at Nvidia is completely different as their internal clusters are persistent and multi-year. This gives Nvidia’s engineers a large degree of freedom to be creative and work on higher risk projects on spare capacity on the cluster without an accountant hovering over them. AMD has over 5 billion dollars of cash on hand, and has the financial ability to invest more heavily into internal clusters.
Most of AMD’s internal cluster are rented for sub-1 year basis. This means that their customers will still be using MI300 in 2027 at which point AMD’s internal MI300 volume will be very low given contract expiries, leading to poor long-term support for “vintage” generations of GPUs. AMD should change their internal cluster procurement strategy to commit to multi-year procurement so as to enable long-term support of each GPU generation. If AMD internal clusters aren’t even committing multiple years to each GPU generation, why should their customers commit to long-term ownership of AMD GPUs?
AMD’s software infrastructure layer (i.e. Kubernetes, SDC detectors, health checks, SLURM, docker, metrics exporters) has made some progress over the past four months but the rate of progress is much slower than the rate of progress of AMD’s ML libraries. We recommend AMD executives investigate investing more engineering resources into AMD’s AI software infrastructure layer.
Jensen has been donating DGX B200 boxes to academic labs like Berkeley Sky lab, CMU Catalyst Research Group and many other university labs. We recommend that AMD also support the academic ecosystem. It is incredibly easy win for AMD marketing to ship boxes and post photos with PhD students grinning next to a shiny AMD box.
Recommendations to NVIDIA
For the past couple of years, NVIDIA leadership has internally viewed Huawei as the company with the highest probability of being competitive with NVIDIA. Due to the rapid improvement and sense of urgency from AMD, we believe that NVIDIA should instead think of AMD as their main competitor as well. We make the following recommendations to Jensen if they want to continue being the market leader:
Continue to rapidly expand the API surface area with useful new features. If NVIDIA expands their API surface area faster than AMD can copy/port to make it ROCm compatible, NVIDIA will continue to be the market leader. Recent launches across the CUDA Python stack was a great example of NVIDIA massively increasing its API surface area with useful new features.
For many developers, working on Nvidia consumer GPUs is a gateway to working on the broader CUDA ecosystem. Unfortunately, due to NVIDIA consumer EULA, PyTorch and most other ML libraries are unable to host consumer NVIDIA GPUs in their CI/CD, leading to a suboptimal experience on NVIDIA GPUs. We recommend that NVIDIA explore a strategy to get NVIDIA consumer GPUs into PyTorch CI/CD.
NCCL User Buffer Registration reduces memory pressure which allows for larger batch sizes and less activation recomputation leading to ~5-10% increase in performance. Although basic integration with low level PyTorch APIs is supported, there is currently no integration into the common APIs such as DistributedDataParallel (DDP), DTensors, or FullySharedDataParallel (FSDP). We recommend that NVIDIA integrates the user buffer registration feature across the whole PyTorch stack.
Although NVIDIA’s out of box experience is better than AMD, there is still room for improvement. For example, for developer to get optimal performance for RMSNorm, they need to use NVIDIA/apex library instead of having it out of the box in PyTorch. RMSNorm is an extremely common layer in SOTA LLMs. We recommend NVIDIA work with the Meta PyTorch team on figuring out a strategy to integrate fast RMSNorm kernels and other cuDNN kernels directly into PyTorch.
NVIDIA needs to pay for additional CI H100s so that PyTorch can enable H100 for their TorchInductor Benchmark CI. Even AMD has enabled already MI300 for this Benchmark CI.
Over the past four months, AMD has done a great job making most of their benchmarks easily reproducible by the community. For example, AMD wrote a great blog on how to reproduce their MLPerf Inference 5.0 submission. If NVIDIA wants the ML community to have confidence in the benchmarks that NVIDIA posts, we recommend that NVIDIA provide reproducible instructions and an explanatory blog post whenever they post benchmark results.
A meaningful number of NVIDIA’s open source libraries are very poor at following the “open source” ethos and do code dumps at every release. Examples include NCCL and CUTLASS. We have seen progress in some open-source libraries such as trt-llm when they moved towards a Github first approach. We recommend that NVIDIA embrace the open-source ethos across all the open libraries.
Stop promoting marketing Jensen Math 2:4 sparsity FLOPs specifications, curtail the unannounced use of bi-directional bandwidth conventions so as to reduce confusion across the whole ecosystem. Avoid overstating dense FLOP/s specifications and instead move to publishing a FLOP/s metric that reflects what is achievable for a real-world normal input distribution rather than for an unrealistic [-4, 4] uniform discrete integer distribution.
Look into hiring AMD’s engineers that contribute to libraries such as RCCL, ComposableKernels, hipBLASLt, ROCm/PyTorch, etc. by looking the contributor tab on Github and searching on the "[ROCm]" PR tag on Github.
![unrealistic [-4, 4] uniform discrete integer distribution.](https://github.com/NVIDIA/cutlass/blob/main/media/images/cutlass-3.8-blackwell-gemm-peak-performance.svg){kind=link}
MI325X and MI355X Customer Interest
There has been a lack of interest from customers in purchasing the MI325X as we've been saying for a year. It was supposed to be a competitor to H200, but the MI325X started shipment in Q2 2025, about three quarters after the H200 and at the exact same time as Blackwell mass production. The obvious customer choice has been the much lower cost per performance Blackwell and so the release of the MI325X was too little too late and AMD was only able to sell minimal volumes of the MI325.
Our demand view in the Accelerator Model tracked Microsoft’s disappointment early in 2024 and lack of follow on orders throughout the rest of 2024. We believe that there is renewed interest in AMD GPUs from OpenAI via Oracle and a few other major customers, but still not Microsoft, on the condition that they reach a sweet-heart pricing with AMD. To be clear, MI355X is still not competitive with NVIDIA’s rack scale GB200 NVL72 solution because the MI355X’s scale-up world size is still only 8 GPUs while for NVIDIA’s GB200 NVL72 the world size is 72 GPUs.
AMD’s pitch on the competitiveness of MI355X centers around the fact that it doesn’t require direct to chip liquid cooling (DLC). There certainly is merit to some point, but there is a degree of irony to the fact that AMD is still pitching the next gen MI355X as a competitor to Nvidia’s last-gen economy-class products. AMD’s MI355X cannot compete head on with NVIDIA’s flagship GB200 NVL72 for frontier reasoning inferencing due to the smaller scale-up world size mentioned above, so it is instead positioned to compete with the air-cooled HGX B200 NVL8 and the air-cooled HGX B300 NVL16.
With that said, this product segment will ship meaningful volumes and depending on the MI355X’s software quality and the price that AMD is willing to sell at, the MI355X could be decently competitive on performance per TCO basis when compared to NVIDIA’s HGX. This is particularly true for small to medium models that do not benefit from large scale-up world sizes. However, we believe that GB200 NVL72 will win on performance and perf per TCO when it comes to reasoning models and frontier inferencing that do benefit from large disaggregated deployments or mixture of experts that best harness large scale-up networks.
Below, we will discuss what we see on MI355X, MI420X, MI450X, UALink, Infinity Fabric over Ethernet, and pricing.
 | A guest post by
|