

Co-Packaged Optics (CPO) Book – Scaling with Light for the Next Wave of Interconnect
Scale-out and Scale-up CPO, CPO TCO and Power Budgets, DSP Transceivers vs LPO vs NPO vs CPO, TSMC COUPE, MZM vs MRM vs EAM Modulator Deep Dive, CPO Focused companies and CPO Supply Chain
Co-Packaged Optics (CPO) has long promised to transform datacenter connectivity, but it has taken a long time for the technology to come to market, with tangible deployment-ready products only arriving in 2025. In the meantime, pluggable transceivers have kept pace with networking requirements and remain the default path thanks to their relative cost-effectiveness, familiarity in deployment, and standards-based interoperability.
However the heavy networking demands that come with AI workloads mean that this time is different. The AI networking bandwidth roadmap is such that interconnect speed, range, density and reliability requirements, will soon outpace what transceivers can provide. CPO will provide some benefit and bring more options to scale-out networking, but it will be central to scale-up networking. CPO will be the main driver of bandwidth increases in scale-up networking for the latter part of this decade and beyond.
Today’s copper-based scale-up solutions, such as NVLink, provide tremendous bandwidth of 7.2 Tbit/s per GPU – soon to be 14.4 Tbit/s per GPU in the Rubin generation, yet copper-based links are limited in range to two meters at most, meaning the scale-up domain world size is limited to one or two racks at most. It is also increasingly difficult to scale bandwidth over copper. In Rubin, Nvidia will deliver another doubling of bandwidth per copper lane through bi-directional SerDes, but doubling bandwidth on copper by developing ever-faster SerDes is a highly challenging vector of scaling that is a slow grind. CPO can deliver the same or better bandwidth density and can provide additional vectors for scaling bandwidth, all while enabling larger scale-up domains.
A starting point for understanding the impetus for CPO is to consider the many inefficiencies and trade-offs when using a transceiver for optical communication. Transceivers can be used to achieve greater link range, but the cage on the front panel of a networking switch or compute tray that transceivers plug into is typically situated 15-30cm from an XPU or switch ASIC. This means that signals must first be transmitted electrically using an LR SerDes over that 15-30cm distance, with the electrical signal recovered and conditioned by a Digital Signal Processor (DSP) within the transceiver before being converted into an optical signal. With CPO, optical engines are instead placed next to XPUs or Switch ASICs, meaning that the DSP can be eliminated and that lower power SerDes can be used to move data from the XPU to the Optical Engine. This can reduce energy required to transmit data by more than 50% when compared to DSP Transceivers - with many aspiring to reduce energy requirements per bit by as much as 80%.
While scale-out CPO solutions like Nvidia and Broadcom’s are garnering more attention and are being closely looked at by end customers, major Hyperscalers are already starting to plan out their scale-up CPO strategy and are committing to suppliers. For instance, Celestial AI is estimating that they could generate a $1B revenue run rate by the end of calendar year 2028 - we believe this will primarily be driven by a CPO scale-up solution shipping with Amazon’s Trainium 4.
CPO focused companies are now well beyond papers, pilot projects and demonstrations and and are making key product decisions such as optical port architecture to solve for high volume manufacturing. CPO for scale-up is now not a matter of if and why, but when and how – how to bring these systems to volume production, and when key component supply chain companies like laser manufacturers can ramp up sufficient production.
This article will present an in-depth discussion on the benefits and challenges of CPO, how CPO architectures work, current and future CPO products, CPO focused companies, CPO-related components and their respective supply chains. This piece is intended to serve as a guide to practitioners, industry analysts, investors and everyone else who is interested in interconnect technology.
Table of Contents and Guide to this Article
We have segmented the article into five parts – readers are welcome to focus on sections that are most interesting or relevant to them.
In Part 1: CPO Total Cost of Ownership (TCO) Analysis, we start off by analyzing how adoption of CPO changes the total cost of ownership for scale-out and scale-up networks. We think that TCO, reliability, and equipment vendor bargaining power will be the primary considerations for adopting CPO in scale-out networks. We will explore whether CPO is ready for primetime when it comes to scale-out, touching on the data we have so far on solution reliability such as Meta’s CPO scale-out switch study presented at ECOC 2025.
In Part 2: CPO Introduction and Implementation, we will dive deeper into how CPO works. This section will explore the evolution of the market from copper to co-packaged copper and from digital signal processor (DSP) optics to linear pluggable optics (LPO) to CPO and the impetus and arguments for the adoption of CPO. SerDes scaling limits and Wide I/O as an alternative to SerDes – particularly when used in conjunction with CPO – will also be discussed.
In Part 3: Bringing CPO to Market, we will describe critical technologies that will enable CPO to gain traction and come to market. We first discuss Host and Optical Engine packaging and explain TSMC COUPE in detail and why it is emerging as the integration option of choice. Fiber Attach Units (FAUs), Fiber coupling as well as Edge Coupling vs Grating Couplers will be explained thoroughly. We will cover modulator types such as Mach-Zender Modulators (MZMs), Micro-Ring Modulators (MRMs) and Electro-Absorption Modulators (EAMs). This section will end with explaining the core of why CPO is being adopted – the many different vectors for scaling bandwidth with CPO: More fibers attached, using wavelength division multiplexing (WDM) and higher order modulation.
In Part 4: CPO Products of Today and Tomorrow, we will analyze CPO products available on the market today and their associated supply chain. We will start with Nvidia and Broadcom’s solutions before discussing major CPO companies. We cover Ayar Labs, Nubis, Celestial AI, Lightmatter, Xscape Photonics, Ranovus and Scintil, describing each provider’s solution in detail and weigh in on important puts and takes for each company’s approach.
Finally, in Part 5: Nvidia’s CPO Supply Chain, we will conclude this report by describing in detail the supply chain for Nvidia’s CPO ecosystem, naming key suppliers for Laser Sources, ELS Modules, FAU, FAU Alight Tools, FAU Assembly, Shuffle Box, MPO Connectors, MT Ferrules, Fibers, and E/O Testing.
Part 1: CPO Total Cost of Ownership (TCO) Analysis
One of the most highly anticipated topics at Nvidia’s GTC 2025 earlier this year was Jensen announcing the company’s first CPO-enabled scale out network switches. Notably, for scale-up, Nvidia is still pushing forward with copper and going to extreme lengths to avoid going to optics, even out to 2027 and 2028.
Let’s begin our discussion regarding these new CPO-enabled switches by examining their total cost of ownership, analyzing the cost and power savings for scale-out CPO can deliver.
Nvidia’s GTC 2025 keynote announced three different CPO scale-out switches that utilize two different CPO-enabled switch ASICs. While there are TCO, power, and deployment speed benefits – they are not compelling enough for customers to jump headfirst into an entirely different deployment regime, and we expect to see limited adoption for the first wave of CPO scale-out switches. Let’s go through why.
Typical AI Cluster Networking Configuration and TCO
A typical AI Cluster has three main networking fabrics, back-end, front-end and out of band management fabric. The most heavily utilized and technically demanding network fabric is the back-end fabric. The back-end fabric is used for scale-out communications between GPUs to communicate with one another and exchange data in collective operations to parallelize training and inference. Back-end networks typically use the InfiniBand or Ethernet protocols.
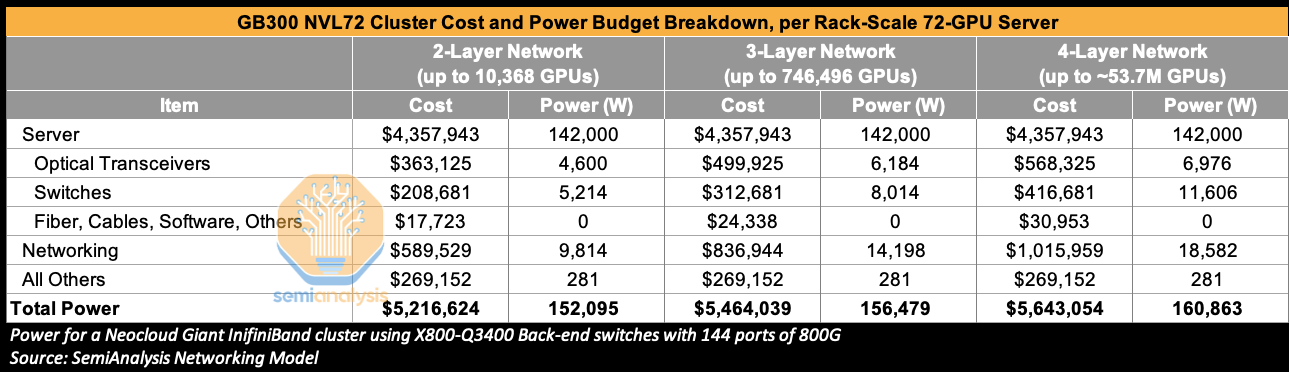
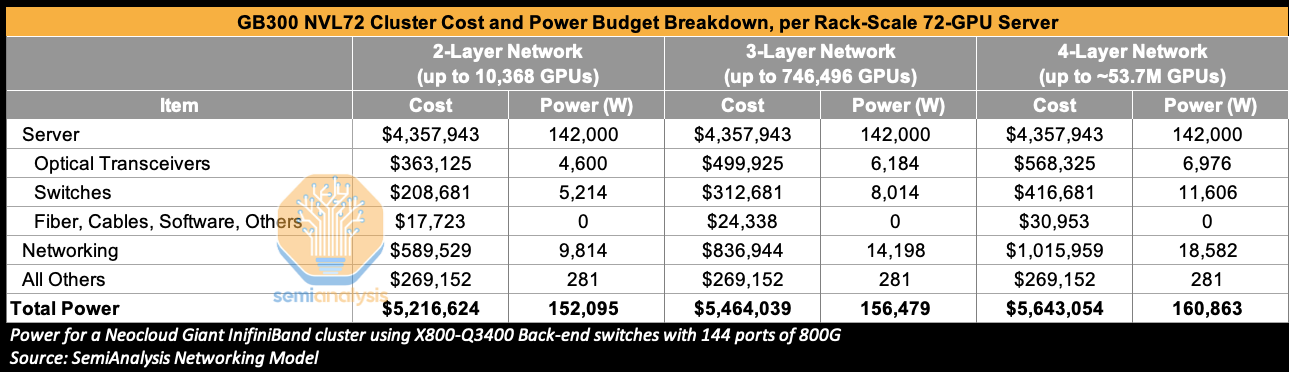
Because of its demanding nature, the back-end network accounts for a dominant share of total networking cost and power, representing 85% of networking cost and 86% of networking power for 3-layer GB300 NVL72 clusters deployed on InfiniBand using Nvidia’s X800-Q3400 back-end switches. CPO-based switches and networking solutions can be used in both the back-end and front-end network, but we think that the focus for deployment at this stage will be in the back-end network. Readers can find much more details on back-end network topology, port, switch, and transceiver counts in our Optical Boogeyman Article from 2024 as well as in our AI Networking Model. Those that would like to understand total networking cost of ownership can read our AI Neocloud Anatomy and Playbook article.


Zooming out – networking cost is the second largest component of total AI cluster cost behind the AI server itself. In a GB300 NVL72 Cluster with a 3-Layer InfiniBand network, this stands at 15% of total cluster cost, reaching 18% of total cluster cost for a 4-Layer network. Optical transceivers are a significant portion of this cost, accounting for 60% of networking cost for a 3-Layer network when using the relatively more expensive Nvidia LinkX Transceivers. They also consume 45% of total networking power for a 3-Layer network.
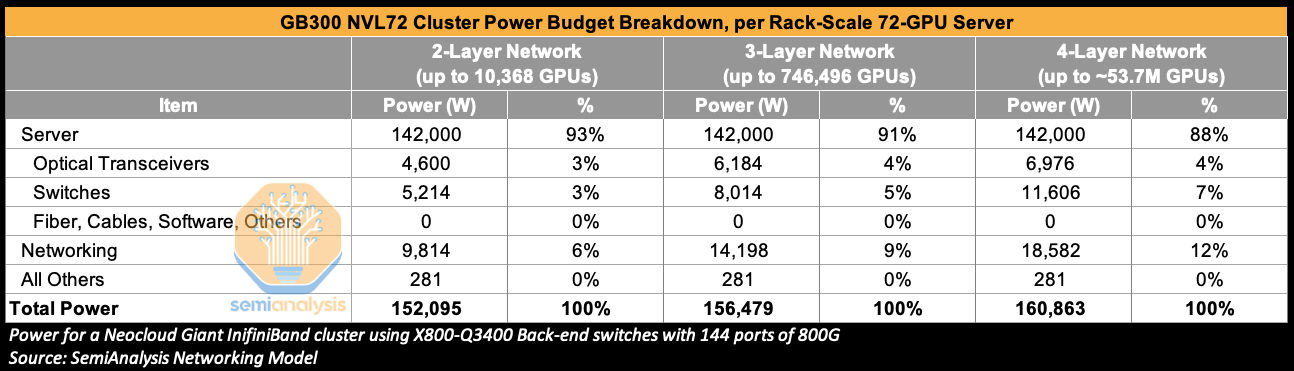
The greater the number of GPUs in an AI cluster, the more likely it is that more networking layers will be needed. Going from a two-layer to a three-layer network and beyond means higher costs and a greater power budget. CPO can both help reduce power and cost holding number of layers constant, and can reduce total power and cost requirements by expanding the number of GPUs that can be connected on a network of a given number of layers.
CPO Scale-out Power Budgets
Earlier this year, at GTC 2025, Nvidia’s CEO Jensen Huang highlighted the immense power consumption from transceivers alone as a key impetus for CPO. Using some of the per-rack power budgets from the above table, a 200,000 GB300 NVL72 (72 GPU packages and 144 compute chiplets per rack) GPU cluster on a three-layer network would consume 435 MW of Critical IT Power of which 17 MW would be consumed by optical transceivers alone. Clearly there is an immense amount of power that can be saved by eliminating most of the transceiver content.
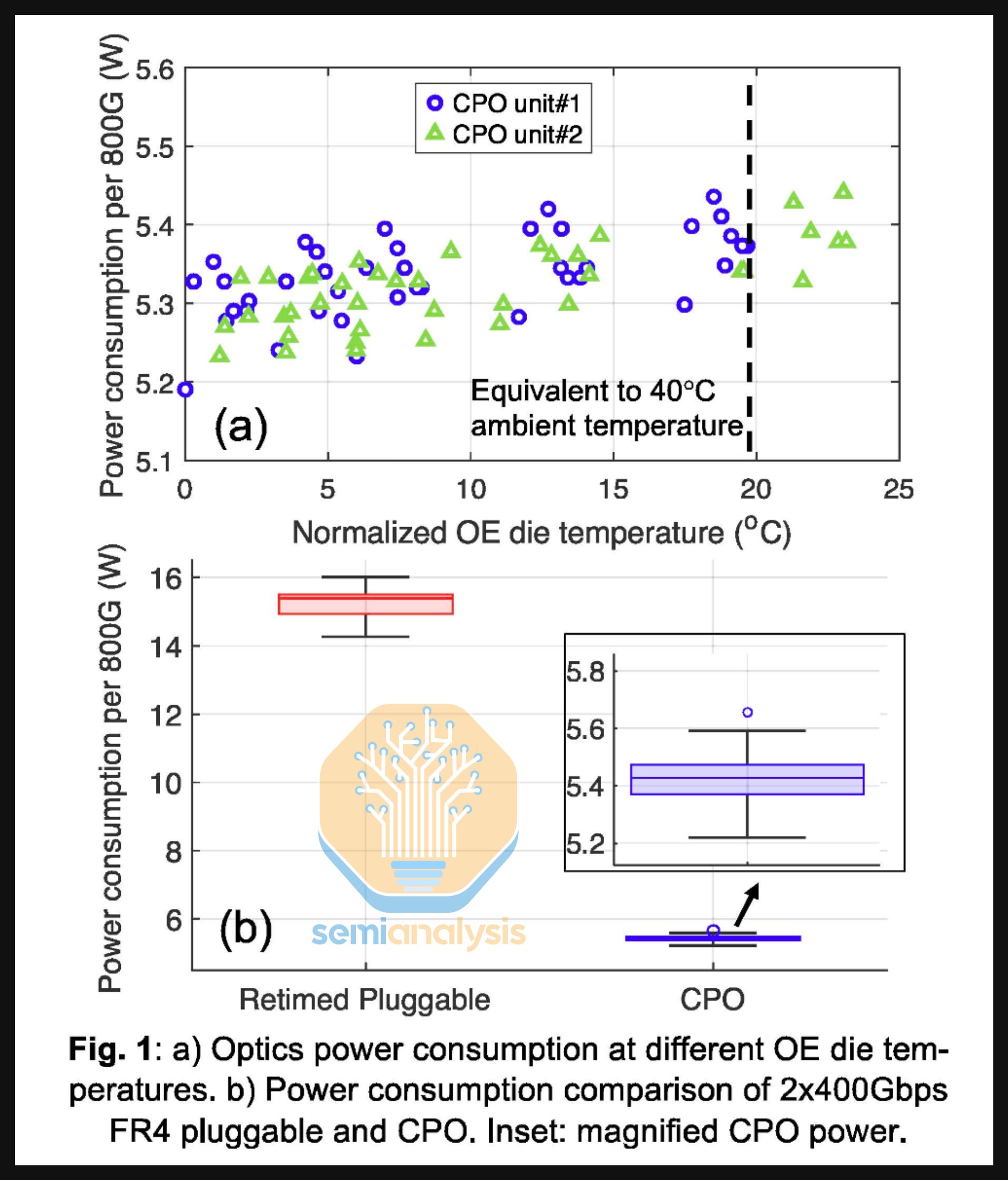
This can be easily seen by comparing the power used in just one 800G DSP transceiver to the power consumed by optical engines and laser sources (per 800G bandwidth) within a CPO system. While an 800G DR4 optical transceiver consumes about 16-17W, we estimate that the optical engine together with external laser sources used in Nvidia’s Q3450 CPO switch consume about 4-5W per 800G of bandwidth, a 73% reduction in power.
These figures are very close to those presented by Meta in its paper published and presented at ECOC 2025. In this report – Meta showed how an 800G 2xFR4 pluggable transceiver consumes about 15W while the optical engine and laser source within the Broadcom Bailly 51.2T CPO switch consumes about 5.4W per 800G of bandwidth delivered, a 65% power savings.
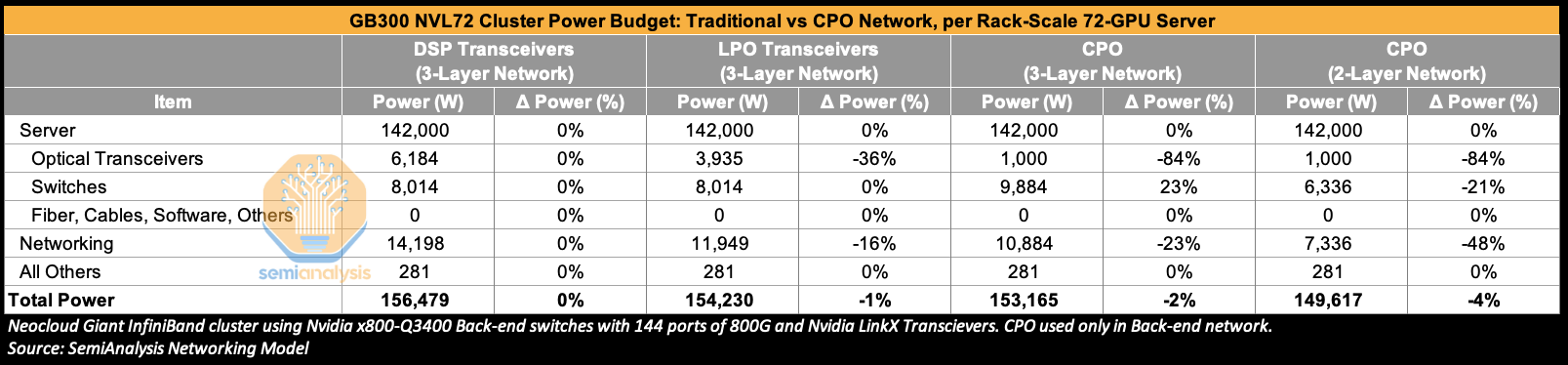
Let’s expand this analysis to the cluster level. Turning to a GB300 NVL72 cluster built on a three-Layer network, we see that moving from DSP transceivers to using LPO transceivers in the back-end network can reduce total transceiver power by 36% and total network power by 16%. A full transition to CPO yields even greater savings vs DSP optics – cutting transceiver power by 84% – though part of this power saving is offset by adding optical engines (OEs) and external light sources (ELSs) to the switches, which now consume 23% more power in aggregate. In the below example, optical transceiver power in the CPO scenario remains floored at 1,000W per sever because we assume that front-end networking will still use DSP transceivers.
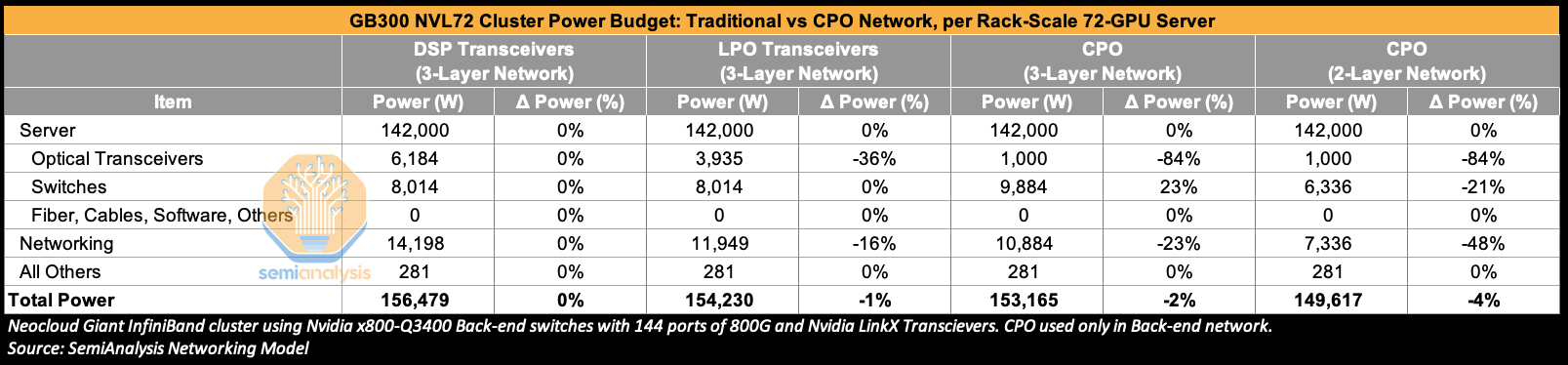
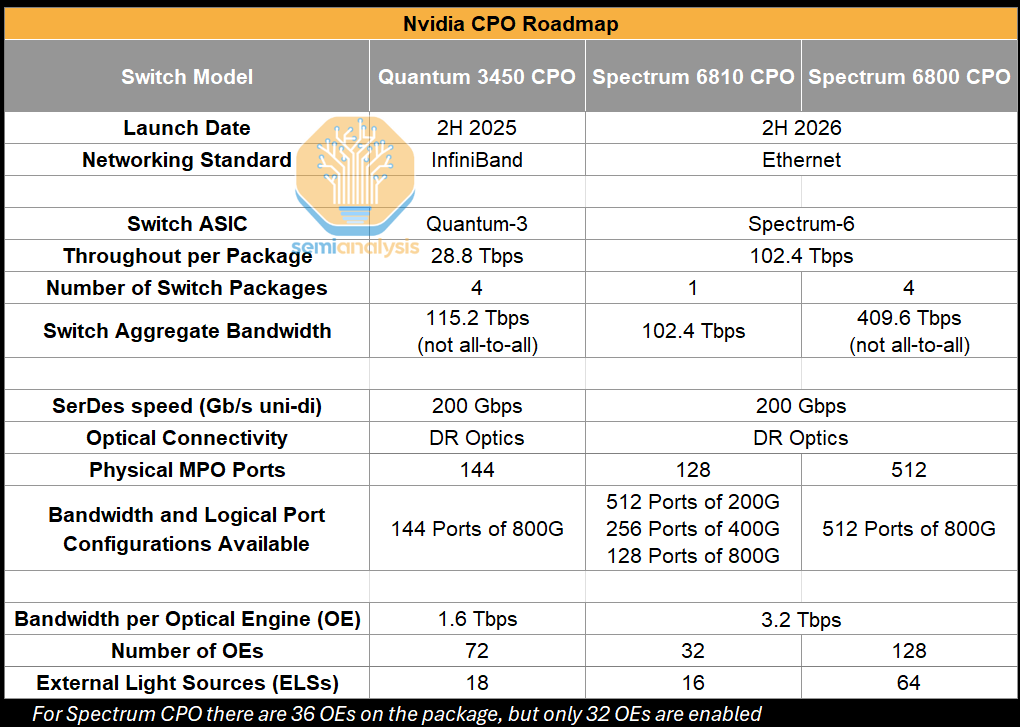
The use of Nvidia’s CPO scale-out switches implicitly means a high radix network is used by default, though this is “abstracted” from the end users because the shuffle happens inside the switch box as opposed to outside the switch box via patch panels or octopus cables when using high radix non-CPO switches. Instead, these Nvidia CPO switches present themselves as having a very high port count – the Quantum 3450 offering 144 ports of 800G, and the Spectrum 6800 offering 512 ports of 800G for example. We use the word “by default” because Nvidia’s non-CPO InfiniBand Quantum Q3400 switch also offers 144 ports of 800G, though its other InfiniBand switches such as the QM9700 only offer 32 ports of 800G - with only the former offering this “high radix in a box” to deliver a high number of effective ports. This high port count could potentially allow customers to flatten a network from a three-Layer to a two-layer network and is also saves customers the trouble of deploying shuffle boxes and patch panels or unwieldy octopus cables and could be a key selling point. In the two-layer case, transceiver power is reduced by 84%, switch power is down by 21% and total networking power can be reduced by 48% vs traditional DSP transceivers.
The Spectrum 6800 switch, with its large number of ports in both available logical configurations - 512 ports of 800G – specifically enables this when compared to the Spectrum 6810, which offers 128 ports of 800G, 256 ports of 400G or 512 ports of 200G. For the 128 ports of 800G option using the Spectrum 6810, a network could connect up to 8,192 GPUs for a two-layer network, while the Spectrum 6800 at 512 ports of 800G can connect 131,072 GPUs.
As a brief aside, the maximum number of hosts that can be supported using a switch of k ports on an L-layer network is given by:
The magic comes from the fact that the number of ports k is exponentiated by the number of layers. Thus, for a two-layer network, doubling the number of logical ports by assigning half the bandwidth per port (i.e. slicing an 800G port into two 400G ports) using either an internal shuffle (as is the case with the Spectrum 6800), breakout cables or twin-port transceivers means four times the hosts supported!
The power savings discussed in this section so far, 23% for a three-layer CPO network and 48% going down to a two-layer CPO network sounds fantastic, but the wrinkle is that networking is just 9% of total cluster power to begin with for a three-layer network. So, at the end of the day the impact of switching to CPO is diluted considerably at least for scale-out networks. Switching to use CPO for a three-layer network lowers networking power by 23% but only delivers 2% total cluster power savings. Moving to a two-layer network delivers 48% lower networking cost, but only 4% total cluster power savings.
It is a similar story when looking at total cluster capital cost.
CPO Scale-out Total Cost of Ownership (TCO)
Let’s briefly zoom into some of the cost details when comparing transceivers to a CPO solution. The first Nvidia CPO Switch, the Quantum X800-Q3450 CPO will use 72 optical engines each operating at 1.6Tbit/s; later versions of Quantum CPO switches will likely transition to 36 optical engines at 3.2Tbit/s each, costing ~$1,000 per unit (including FAUs), which translate to $36k of total OE cost per system.
To put this into perspective, consider the total cost if traditional optical transceiver modules were used instead. The non-CPO X800-Q3400 features 72 OSFP cages, and a 1.6T twin-port transceiver is used to provide 144 ports at 800G. Assuming a cost of $1,000 for a generic 1.6T DR8 transceiver, total transceiver cost to populate this switch would amount $72,000, which is double the estimated $35-40k cost of optical engines and ELS needed to deliver the same amount of bandwidth for CPO switch. However, this doesn’t take into account the switch vendor’s margin. If we were to apply a 60% gross margin, optical engine cost to the end buyer would end up at $80k-$90k USD – which is higher cost than the transceiver equivalent. There are still other components like fiber shuffles and other components that would be subject to such a margin stack. This explains why, depending on the cost paid for transceivers and the margin taken by the switch vendor, cost savings when moving to CPO may not be dramatic.
We can see in the table below, when switching from transceivers to CPO on a three-layer network, the additional margin taken on CPO components increases switch costs by 81% which detracts from the 86% savings by not purchasing transceivers. Total networking cost is still 31% lower for CPO than for using DSP transceivers, but as was the case with power, the server rack’s dominant share of cluster TCO means that total cluster costs only drop by 3%.
Flattening the network down to two-layers instead of three-layers can deliver more cost savings though – up to an 7% total cluster cost reduction, with transceiver cost down 86%, and total networking cost decreased by 46%.
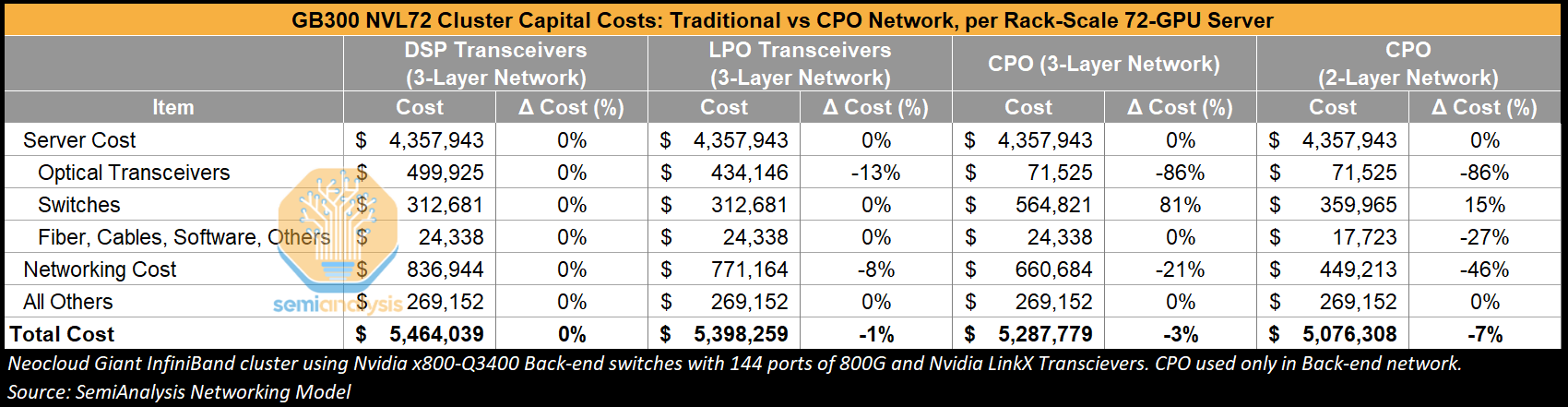
So – if CPO offers only up to 7% cost savings and up to 4% power savings on one hand, but on the other hand raises concerns about difficult field servicing, anxiety (justified or not) over reliability and blast radius, and the loss of bargaining power that one has with multiple transceiver vendors – why is it being adopted by GPU clouds? The simple answer is that it is not being adopted widely just yet – we do not expect a rapid adoption curve for scale-out CPO systems within hyperscalers in the near term.
CPO for Scale-up Networks
On the contrary, we see CPO for scale-up as the killer application. As mentioned earlier, major hyperscalers are already making commitments to suppliers for deployment of CPO-based scale-up solutions by the end of the decade.
Currently, the incumbent copper-based scale up paradigm is being pushed to its limits due to the limited reach of copper cables – two meters at best when running at 200Gbit/s per lane, as well as the increasing difficulty of doubling bandwidth per lane. CPO can solve these problems as it can meet bandwidth density requirements, provide multiple vectors for scaling bandwidth well into the future as well as unlock much larger scale up world sizes.
Once CPO is deployed for scale-up networking, the scale-up domain will no longer be limited by the interconnect reach. In principle, customers would be able to grow scale-up domains to arbitrarily large sizes. Of course, if one wants to keep the scale-up domain within a single-tier fan-out network that allows for all-to-all connections, the scale-up domain size would become limited by the switch radix.
Scale-out vs Scale-up TAM
Networking requirements of the scale up fabric are far more demanding than that of the back-end scale-out network. The GPU to GPU or switch links require much higher bandwidth and lower latency to enable the GPUs to be interconnected so that they can coherently share resources such as memory.
To illustrate, 5th generation NVLink on Nvidia Blackwell offers 900GByte/s (7,200 Gbit/s) of uni-directional bandwidth per GPU. That is 9x more bandwidth per GPU than the 100GByte/s (800Gbit/s) per GPU on the back-end scale out network (using the CX-8 NIC for the GB300 NVL72). This also creates the need for much higher shoreline bandwidth density from the host which has been the impetus for pushing GPU SerDes line speeds forward.
It is also important to realize that as the size of scale-up domains increases and as the speed of scale-up interconnect grows as well, the TAM of scale-up interconnect (and eventually, scale-up CPO) has already considerably dwarfed that of scale-out networking. CPO TAM is likely to be dominated by scale-up rather than scale-out networking applications.
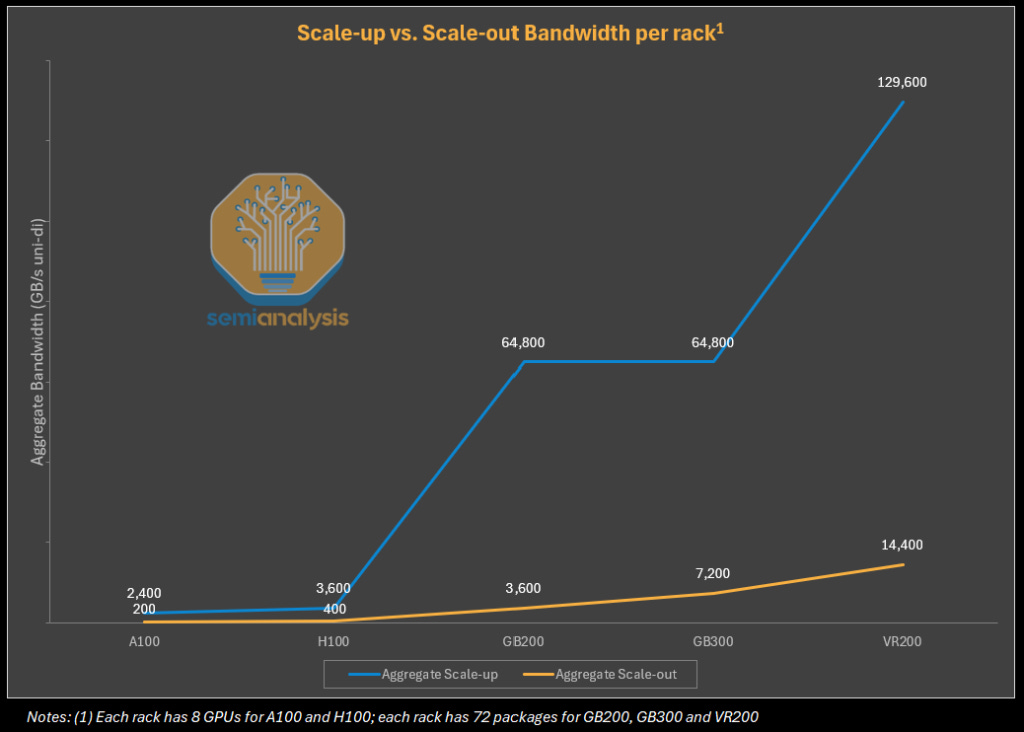
Copper vs Optics for Scale-Up: World Sizes, Density and Reach
Currently, scale up networks run entirely on copper for good reasons. Matching NVLink bandwidth with optical transceivers in the current pluggable paradigm would be prohibitively expensive in terms of cost and power as well as introducing unwanted latency. There also might not be sufficient face-plate space on the compute tray to even fit all of these transceivers. Copper excels at these low-latency, high-throughput connections. However, as mentioned above, copper’s limited reach restricts the “world size”—the number of GPUs that can be connected within a single scale-up domain.
Increasing scale-up world size is a vitally important avenue of compute scaling. Adding more compute, memory capacity, and memory bandwidth in a single scale up domain has become increasingly critical in today’s regime of inference-based model scaling and test time compute.
Nvidia’s GB200 system offered an immense performance boost because it brought the world size to 72 interconnected GPUs in an all-to-all topology from just 8 interconnected GPUs. The result was unlocking tremendous throughput gains through implementing more sophisticated collective communication techniques that are not feasible on the scale out network.
On copper, this could only be done within the footprint of a single rack creating immense demands on power delivery, thermal management and manufacturability. The complexity of this system has the downstream supply chain still struggling to ramp up capacity.
Nvidia will continue to persist with copper. They also need to push their scale up world size even higher to keep ahead of competitors such as AMD and the hyperscalers who are catching up with their own scale up networks. As such, Nvidia is forced to go to drastic lengths to expand the scale up domain within a single rack. Nvidia’s extreme Kyber rack architecture for Rubin Ultra that was shown at GTC 2025 can scale up to 144 GPU packages (576 GPU dies). This rack is 4x denser than the already dense GB200/300 NVL72 rack. With the GB200 already being so complicated to manufacture and deploy, Kyber takes it to the next level.
Optics enables the opposite approach, scaling across multiple racks to increase world size, rather than packing more accelerators in a dense footprint which is challenging for power delivery and thermal density. This is possible with pluggable transceivers today, but again the costs of optical transceivers along with their high power consumption makes this impractical.

Copper vs Optics for Scale-Up: Scaling Bandwidth
Scaling bandwidth on copper is also increasingly difficult. With Rubin, Nvidia is achieving the doubling of bandwidth by implementing a novel bi-directional SerDes technology, where both transmit and receive operations share the same channel, enabling full-duplex communication at 224Gbit/s transmit + 224Gbit/s receive per channel. Achieving “true” 448G per lane on copper remains another challenging feat with an uncertain time to market. In contrast, CPO presents multiple vectors for scaling bandwidth: Baud rate, DWDM, Additional Fiber Pairs and Modulation – all of which will be discussed in detail later in this article.
When will CPO be ready for Primetime?
So, if CPO is the solution, why is Nvidia not pursuing it for Rubin Ultra and only for their scale out switches at first? This goes back to supply chain immaturity, manufacturing challenges, and customer hesitation around deployment. The Quantum and Spectrum CPO switches have been introduced to help ramp up the supply chain and get more real world data on reliability and serviceability in the datacenter.
In the interim, Meta’s CPO reliability data published around ECOC provides some helpful information. Meta collaborated with Broadcom for this study, with Broadcom publishing some useful slides as well. In this study, Meta carried out a reasonably sized test run spanning up to 1,049k 400G port device hours across 15 Bailly 51.2T CPO Switches and published the maximum non-zero KP4 forward error correction (FEC) bin:
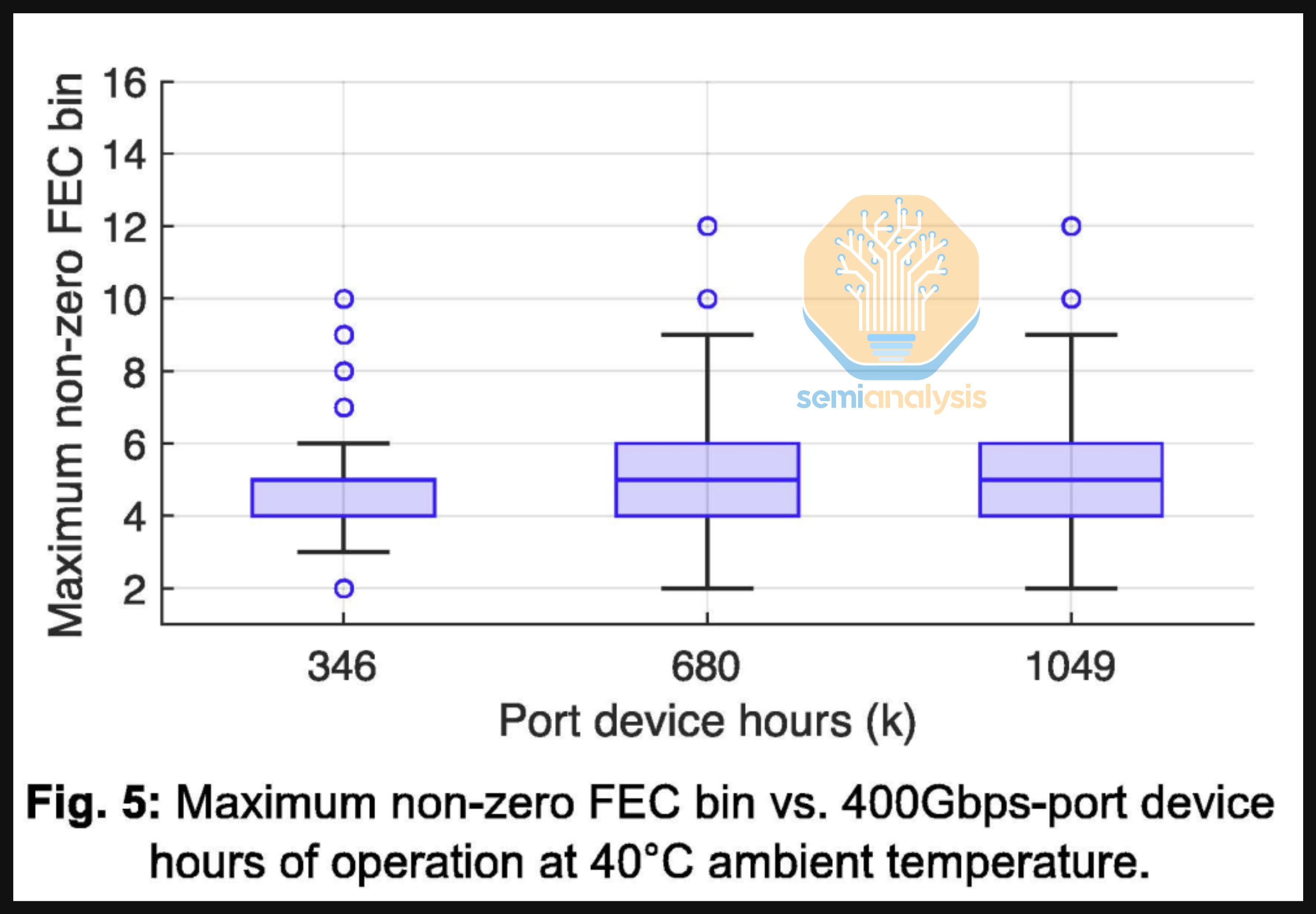
The paper also explained how during the test period, there were no failures or uncorrectable codewords (UCWs) observed in the links, citing only one instance of FEC bin > 10 being observed across the entire testing period up to 1,049k 400G port device hours.
Meta did not stop there, however. In the talk at ECOC presenting the same paper, they presented expanded results for up to 15M 400G port-device hours. These results showed that there were no UCWs for the first 4M 400G port device hours, and they also showed a 0.5-1M device hour mean time before failure (MTBF) for 400G 2xFR4 transceivers (550k for 2xFR4 globally) vs 2.6M device hour MTBF for CPO.
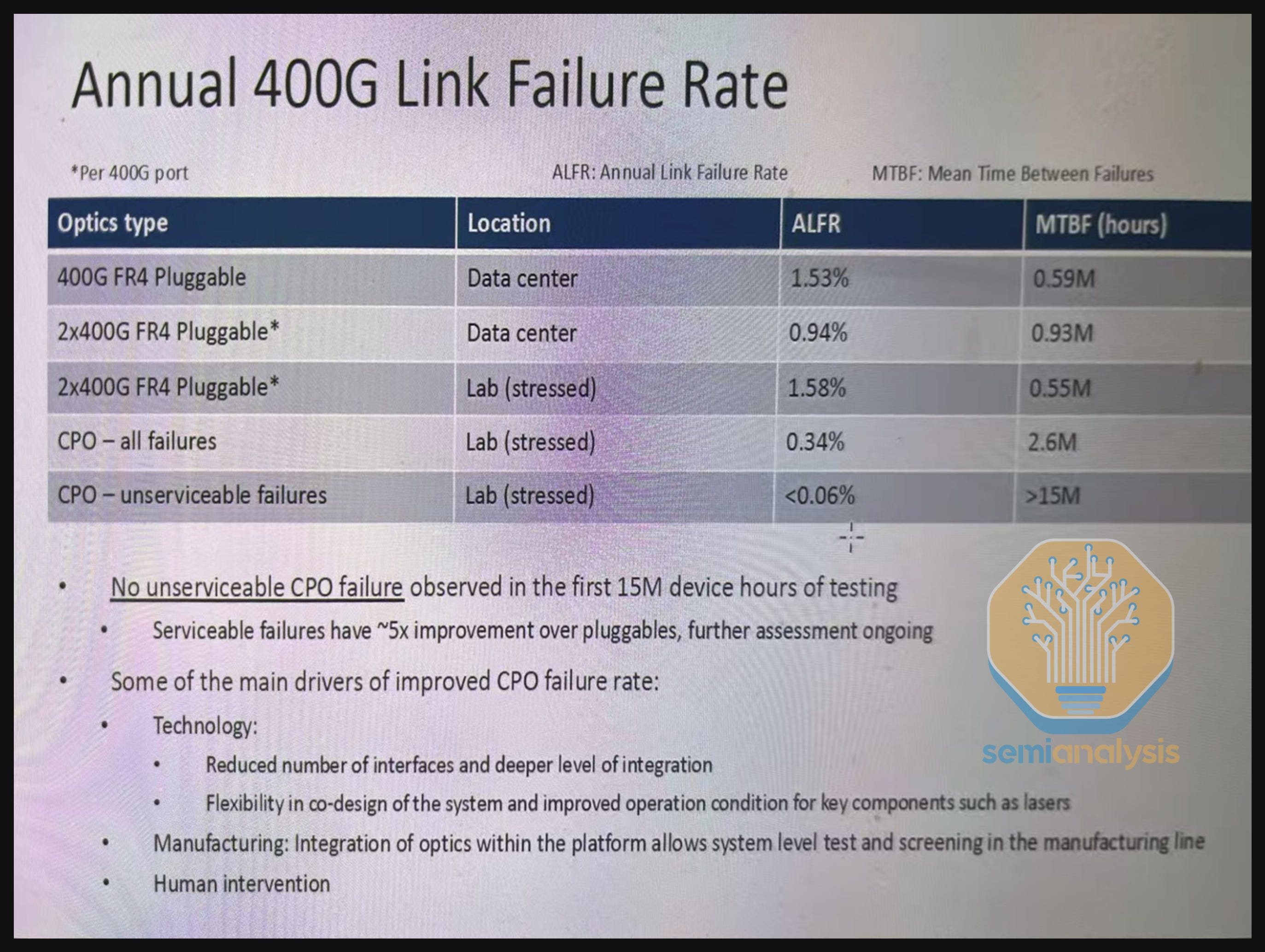
While 15M port device hours might sound like a large number, this is in units of 400G port hours. So – one 51.2T switch operated for one hour would mean 128 400G port hours. 15M 400G Port hours across 15 51.2T switches would mean 7,812 wall-clock hours or about 325 days. Indeed, this 15M hour number is often cited as simply “hours” or “device hours” with the “port” part left out. While the zero failure and zero UCW statistic up to 4M port device hours is very helpful – the industry needs far more than just 15 CPO switches tested for 11 months in a lab setting before it pivots towards CPO scale-out switching and commits billions of dollars to this technology.
Operating thousands of scale-out switches in a dynamic field environment is entirely different challenge and it remains to be seen how these switches will perform in a production environment. Temperature variation could be higher in a production environment vs a lab, leading to unanticipated variation in component performance or endurance. Meta’s own Llama 3 paper cited 1-2% temperature variations in the datacenter adversely affecting power consumption fluctuations – could such fluctuations affect an entire network fabric in ways that are hard to anticipate?

Even mundane sounding problems like dust in a datacenter are the bane of support technicians who can spend considerable time cleaning fiber ends – of course, CPO switches have either an LC or MPO type front pluggable connector, but what about dust inside of the CPO switch chassis? The 0.06% unserviceable failure rate sounds attractive, but such failures have a blast radius of 64 800G ports. This paper is also focused on FR optics based CPO switches, though the next generation of CPO switches will be based on DR optics. These are just a few known unknowns, and there are potentially more unknown unknowns that could come up in field testing.
Indeed, these results have been impactful in terms of convincing those in the industry by delivering tangible reliability data. Our point here is not to create fear, uncertainty or doubt (FUD) but rather to call for even larger scale field testing so that the industry can quickly understand and solve unforeseen problems thereby paving the way for broader CPO adoption, particularly for scale-up networking.
At the end of the day, Nvidia’s scale-out CPO product launch is serving as a practice run and pipe-cleaner for the real high-volume deployment. We think deployment will be far more sizable and impactful for scale up given the much more compelling TCO and Performance/TCO benefit for scale-up vs scale-out.
Moreover - when it comes to scale-out CPO, Rubin Ultra is targeting a launch in 2027 (we think that ends up being late 2027) and the supply chain won’t be ready to ship tens of millions of these CPO endpoints to support GPU demand. Even this timeline is too ambitious for Nvidia. This is why the Feynman generation appears to be the focal point for CPO injection into the Nvidia ecosystem.
Now let’s talk in depth about what CPO is about, the technical considerations, challenges, and state of the ecosystem today.
Part 2: CPO Introduction and Implementation
What is CPO about and why is everyone so excited?
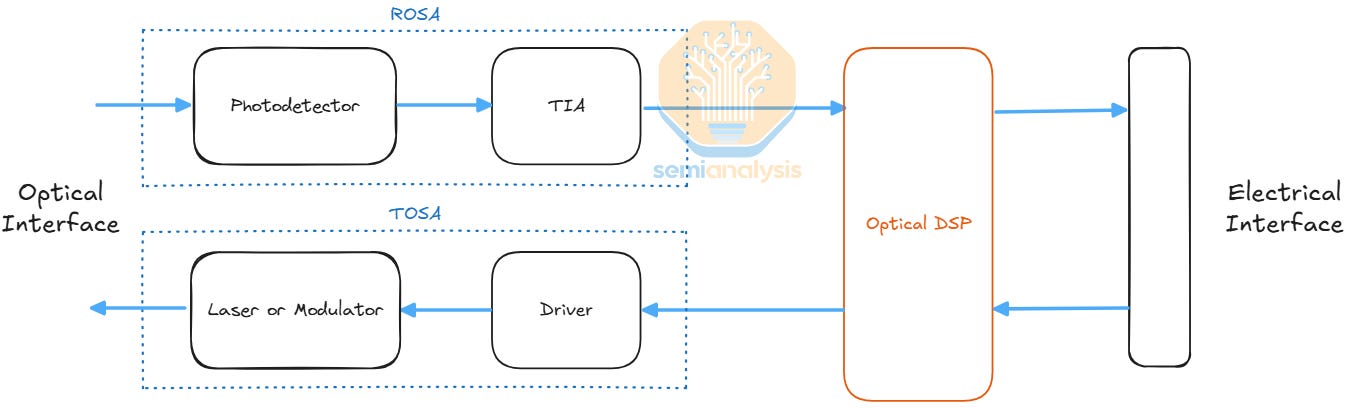
CPO integrates optical engines directly within the same package or module as high-performance computing or networking ASICs. These optical engines convert electrical signals into optical signals, enabling high-speed data transmission over optical links. Optical links must be used for data communication over distances beyond a few meters, as high-speed electrical communication over copper cannot reach beyond a few meters.
Today, most electrical to optical conversion occurs via pluggable optical transceivers. In such cases, an electrical signal will travel tens of centimeters or more from a switch or processing chip through a PCB to a physical transceiver cage at the front plate or back plate of the chassis. The pluggable optical transceiver resides in that cage. The transceiver receives the electrical signal which is reconditioned by an optical Digital Signal Processor (“DSP”) chip and then sent to the optical engine components which convert the electrical signal to an optical signal. The optical signal can then be transmitted through optical fibers to the other side of the link where another transceiver undergoes this process in reverse to turn the optical signal into an electrical signal all the way back to the destination silicon.
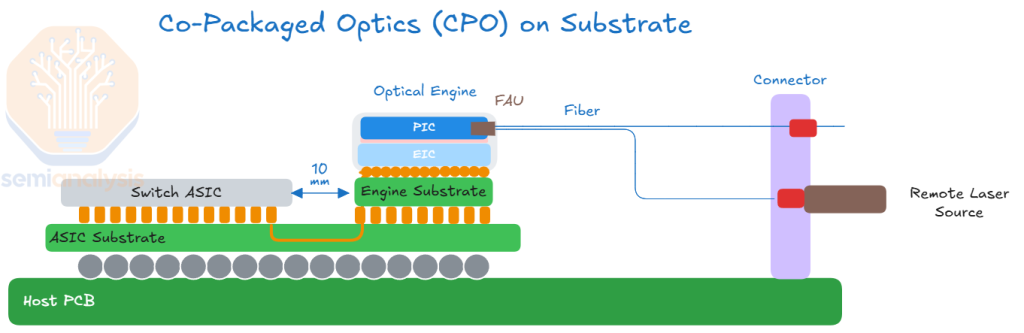
In this process, the electrical signal traverses over a relatively long distances (for copper at least) with multiple transition points before getting to the optical link. This causes the electrical signal to deteriorate and requires a lot of power and complicated circuitry (the SerDes) to drive and recover it. To improve this, we need to shorten the distance the electrical signal needs to travel. This brings us to the idea of “co-packaged optics” where the optical engine that was found in a pluggable transceiver is instead co-packaged with the host chip. This reduces the electrical trace length from tens of centimeters to tens of mm because the optical engine is much closer to the XPU or Switch ASIC. This significantly reduces power consumption, enhances bandwidth density, and lowers latency by minimizing electrical interconnect distances and mitigating signal integrity challenges.
The schematic below illustrates a CPO implementation, where there is an optical engine that resides on the same package as the compute or switch chip. Optical engines will initially be on the substrate, with OEs placed on the interposer in the future.

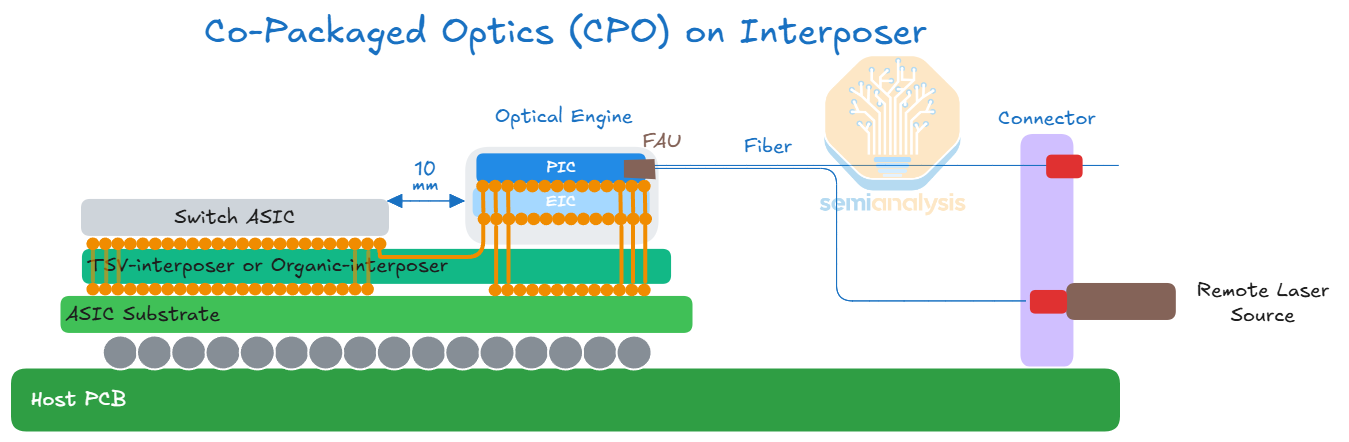
Today, the front pluggable optics solution, as illustrated in the diagram below, is ubiquitous. The main takeaway from this diagram is to illustrate that the electrical signal needs to traverse a long distance (15-30cm) across a copper trace or flyover cable before it gets to the optical engine in the transceiver. As discussed above, this also necessitates the need for long-reach (LR) SerDes to drive to the pluggable module.
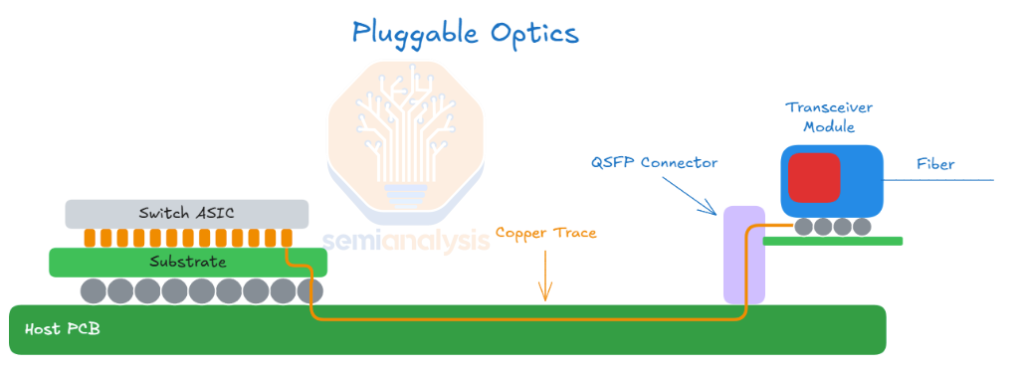
Additionally, there are intermediate implementations that fall between CPO and traditional front-pluggable optics, such as Near-packaged optics (NPO) and On-Board optics (OBO).
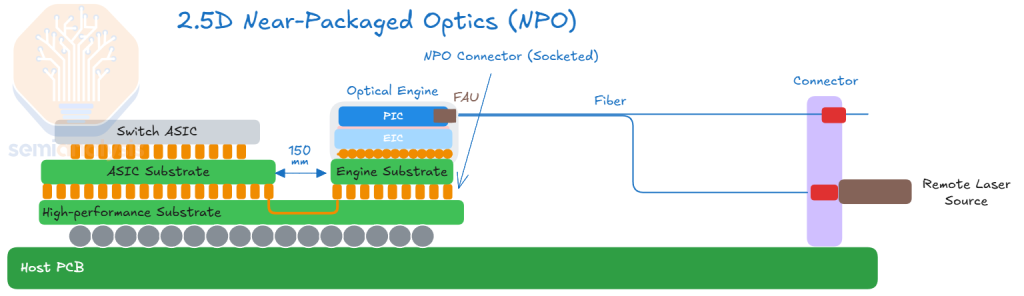
In recent years, NPO has emerged as an intermediate step toward CPO. NPO has multiple definitions. NPO is where the OE doesn’t sit directly on the ASIC’s substrate, but is co-packaged onto another substrate. The optical engine remains socketable and it can be detached from the substrate. An electrical signal will still travel from a SerDes on the XPU package through some copper channel to the Optical Engine.
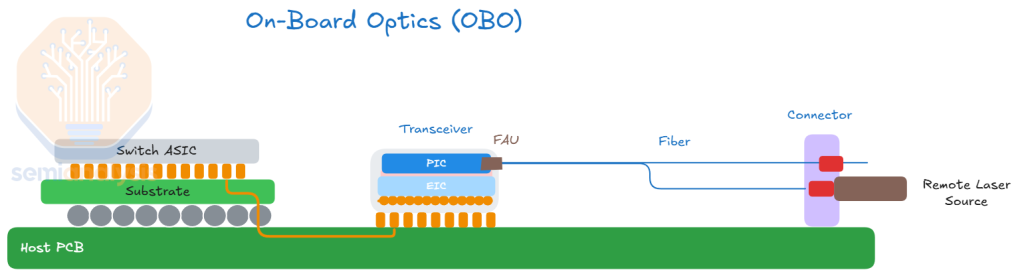
There is also On-Board Optics (OBO), which integrates the optical engine onto the system PCB inside the chassis, positioning it closer to the host ASIC. However, OBO inherits many of the challenges of CPO, while delivering fewer benefits in terms of bandwidth density and power savings. We view OBO as the “worst of both worlds” because it combines the complexity of CPO while inheriting some of the limitations of front-pluggable optics.
Co-packaged Copper
Another alternative to CPO is “Co-packaged Copper” (CPC). CPC uses copper cabling emerging directly from a connector on substrate. Cables use for CPC are the same cables as flyovers and have the same purpose: to bypass the PCB traces. CPC takes flyover cables further with the socket starting on the package substrate itself. The cables used are twin-axial cables (Twinax cables) that are well insulated to reduce cross-talk, resulting in significantly lower insertion loss compared to conventional electrical traces. Though this solution still uses copper, it offers a key advantage in signal integrity. CPC could provide a practical path to deploying 448G SerDes so as to allow another scaling of off-package interconnect.

The challenge with CPC lies in the added complexity of the package substrate. The substrate must route power and signals to thousands of these cables. Despite this challenge, CPC remains significantly simpler than CPO, which still has to overcome a number of manufacturing hurdles across multiple parts of the supply chain. We see CPC as particularly attractive for some short-reach applications such as in-rack scale up connectivity, which we will explore below. By bypassing lossy CCL traces, CPC could be the technology that enables 448G line speeds. CPC is also being looked at very broadly for enabling 448G as signals of this bandwidth experience unacceptable attenuation when running through PCBs.
Past obstacles to CPO market readiness: Why only now?
Despite its technical superiority, CPO has seen very limited real-world adoption due to several challenges that drive up cost. These include: the complexity of packaging (which costs more than the OEs themselves) and manufacturing, reliability and yield concerns, as well as thermal management issues arising from tightly integrated optical and electrical components. Another hang-up is the lack of industry-wide standardization. Additionally, customers are concerned about serviceability which hinders the transition from traditional pluggable optics to CPO solutions.
Another key customer anxiety is that by adopting CPO, they potentially surrender their ability to control costs. It is much easier to squeeze a larger number of transceiver companies on costs than a smaller set of switch vendors.
Meanwhile, pluggable optics—the incumbent technology that CPO would replace—continue to improve and still offers good enough performance for nearly all applications with far less end user anxiety.
In the remainder of Part 2, we will dive further into the impetus for adopting CPO. We will start with explaining how SerDes scaling is reaching a plateau, making other interface types such as Wide I/O coupled with CPO necessary, and then step into manufacturing considerations and go to market. We will discuss key individual CPO component such as Optical Engines, Fiber Coupling, External Laser Sources and Modulators. Lastly, we will cover the roadmap for scaling bandwidth from CPO.
Evolving beyond DSP-based Transceivers: From LPO to CPO
DSP Transceivers handle both the transmission and reception of optical signals and contain an “optical engine” (OE) which is responsible for electro-optical conversion. The OE consists of a driver (DRV) and modulator (MOD) to transmit optical signals, and a transimpedance amplifier (TIA) and photodetector (PD) to receive optical signals.
Another important component is the optical DSP chip, which sometimes integrates the Driver and/or TIA into one package. The high frequency electrical signal that is transmitted from the host switching or processing chip needs to travel a relatively long distance over lossy copper traces to reach the transceiver at the front of the server chassis. The DSP is responsible for retiming and reconditioning this signal. It carries out error correction and clock/data recovery to compensate for electrical signal degradation and attenuation as the signal passes from the switch or ASIC silicon through the substrate or other transmission medium. For modulation, in the case of PAM4 Modulation (Pulse Amplitude Modulation with 4 Levels), the DSP maps a binary signal into four distinct amplitude levels in order to increase the number of bits per signal, allowing higher bitrates and more bandwidth.
The DSP chip is one of if not the most power-hungry and expensive components within the transceiver. For an 800G SR8 Transceiver – the DSP accounts for nearly ~50% of the module’s total power consumption, which is why there has been so much focus on getting rid of the DSP.
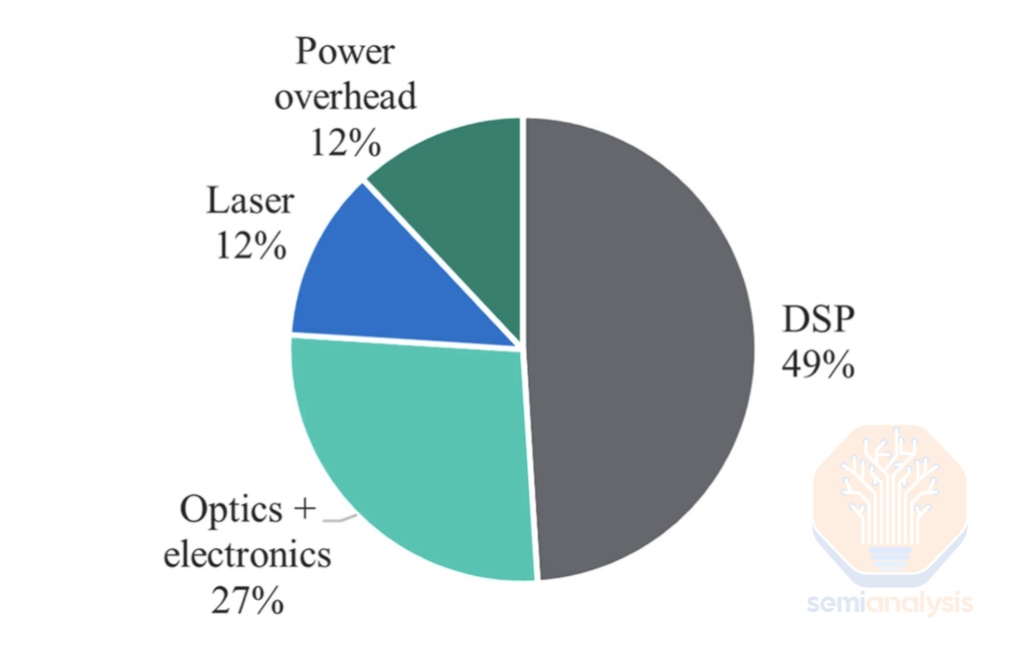
An 18k GB300 Cluster build with a two-layer InfiniBand network will require 18,432 800G DR4 transceivers and 27,648 1.6T DR8 transceivers. The extra cost and power requirements stemming from the use of DSPs can add considerably to the total cost of ownership. Budgeting 6-7W for the 800G DSP and 12-14W for the 1.6T DSP, this would add up to 480kW of DSP power for just the back-end network alone for this entire cluster, or about 1.8kW per server rack. When sourced from premium brand-name suppliers, transceivers can account for nearly 10% of the cluster’s total cost of ownership. So – accounting for 50% of the power draw and 20-30% of the BoM of a typical transceiver – some regard DSPs as public enemy number one of cost and power efficiency.
The Crusade Against DSPs
The high cost and power proportion taken up by DSPs has motivated the industry to find technologies that can disintermediate the DSP. The first wave of attack on the DSP was linear pluggable optics (LPO) – which attempt to remove the DSPs altogether and have the SerDes from the switches directly drive the TX and RX optical elements in the transceiver. However, LPO has not yet taken off as DSP Diviner Loi Nguyen correctly predicted in our interview with him back in 2023.

CPO takes the LPO concept to the next step by placing the optical engine on the same package as the compute or switch chip. A key benefit of CPO is that the DSP that was found in the transceiver is no longer required because the distance between the host and the optical engine is so short. CPO also goes further than LPO because it unlocks much greater chip shoreline density by eliminating the need for power and area-hungry LR SerDes in favor of shorter reach SerDes or even clock forwarded wide D2D SerDes in the case of wide I/O interface.
The oft-cited expression is that CPO has been just around the corner for the last two decades – but why has it failed to take off for so long. Why has the industry preferred to stick with pluggable DSP transceivers?
One key advantage of pluggable transceivers is their high interoperability. With standard form factors such as OSFP and QSFP-DD and adherence to OIF standards, customers can generally select transceiver vendors independent of switch and server vendors, enjoying procurement flexibility and stronger bargaining power.
Another huge advantage is field serviceability. Installing and replacing transceivers is simple as they can be unplugged from a switch or server chassis by a pair of remote hands. In contrast, with CPO any failures in the optical engine could render the entire switch unusable. Even serviceable failures could be complicated to troubleshoot and fix. Often, the laser is the most common point of failure, and most CPO implementations now use pluggable external laser source for better serviceability and replaceability, but anxiety remains regarding the failure of other non-pluggable CPO components.
Why CPO? The I/O challenge, BW density, and bottlenecks
Other than getting rid of power hungry and costly DSPs and minimizing or eliminating the use of LR SerDes, the other huge benefit of adopting CPO is greater interconnect bandwidth density relative to energy consumption.
Bandwidth density measures the amount of data transferred per unit area or channel, reflecting how effectively limited space can be utilized for high-speed data transmission. Energy efficiency quantifies the energy required to transmit a unit of data.
Thus, interconnect bandwidth density relative to energy consumption is a very important figure of merit (FoM) when determining the objective quality of a given interconnect. Of course, the optimal interconnect is the one that also fits within distance and cost parameters.
When examining the chart below, a clear trend emerges: this figure of merit degrades exponentially for electrical links as distance increases. Also, moving from purely electrical interfaces to those requiring optical–electrical conversion introduces a substantial drop in efficiency—potentially by an order of magnitude. This drop is caused because it requires energy to drive signals some distance from the chip to the front-panel where the transceiver is. It requires even more energy to power optical DSPs. The figure of merit curve for CPO-based communication lies squarely above pluggables. As indicated in the chart below, CPO offers more bandwidth density per area per energy consumed over the same ranges of distance making it an objectively better interconnect.
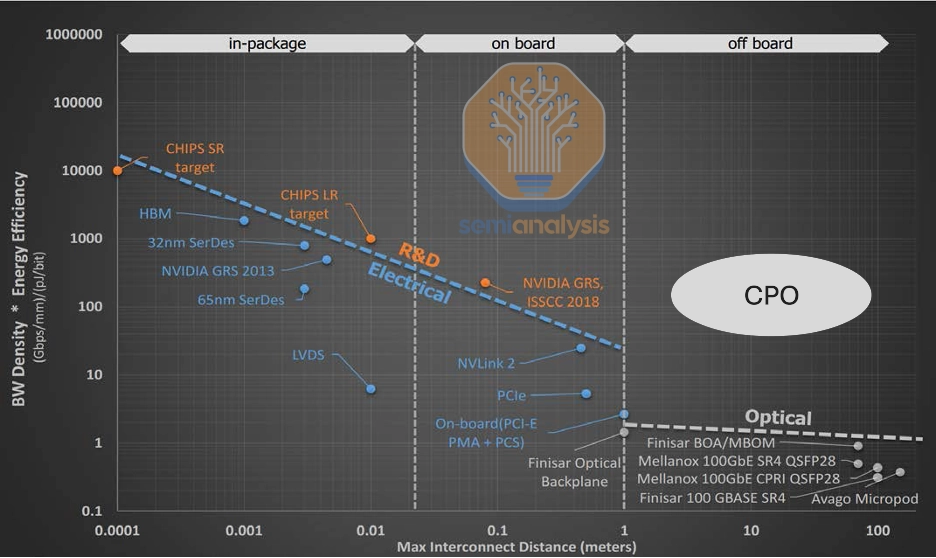
This chart also illustrates the adage “use copper where you can and optical when you must.” Shorter reach communication over copper is superior when available. Nvidia embraces this mantra with their rack-scale GPU architectures architected solely for the purpose of pushing the limits of intra-rack density to maximize the number of GPUs that can be networked together over copper. This is the rationale behind the scale-up network architecture used for the GB200 NVL72, and Nvidia is taking this idea even further in their Kyber rack. However – it is only a matter of time until CPO’s maturity makes accessing its part of the FoM curve viable for scale-up and worth it from a performance per TCO perspective.


Input/Output (I/O) Speedbumps and Roadblocks
While transistor densities and compute (as represented by FLOPs) have scaled well, I/O has scaled much more slowly, creating bottlenecks in overall system performance: there is only so much usable shoreline available for off-chip I/O as the data that goes off-chip needs to escape over a limited number of I/Os on the organic package substrate.
Additionally, increasing the signaling speed of each individual I/O is becoming increasingly challenging and power-intensive, further constraining data movement. This is a key reason why interconnect bandwidth has scaled so poorly over the past many decades relative to other computing trends.
Off-package I/O density for HPC applications has plateaued due to limitations on the number of bumps in a single flip-chip BGA package. This is a constraint on scaling escape bandwidth.
Electrical SerDes Scaling Bottlenecks
With limited number of I/Os, the way to realize more escape bandwidth is to push the frequency that each I/O signals at. Today, Nvidia and Broadcom are at the leading edge of SerDes IP. Nvidia shipping 224G SerDes in Blackwell which is what enables their blazing fast NVLink. Similarly, Broadcom has been sampling 224G SerDes since late 2024 in their optical DSPs. It’s no coincidence that the two companies that ship the most AI FLOPs in the industry also lead in high-speed SerDes IP. This reinforces the fundamental connection between AI performance and throughput, where maximizing data movement efficiency is just as critical as delivering raw compute power.
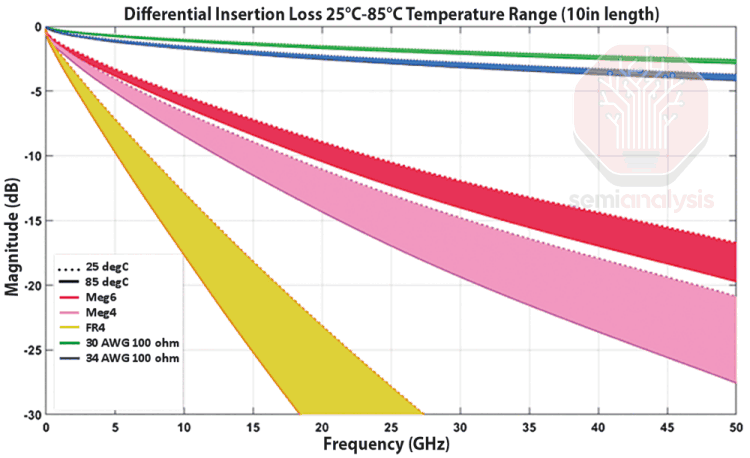
However, it is becoming increasingly challenging to provide higher line speeds at a desirable reach. As frequencies increase, insertion losses rise, as shown in the chart below. We see that losses increase at higher SerDes signaling speeds especially as the signal path lengthens.

SerDes scaling is approaching a plateau. Higher speeds can only be sustained over very short distances without additional signal recovery components—which in turn increase complexity, cost, latency, and power consumption. It has been difficult to get to 224G SerDes.
Looking ahead to 448G SerDes, the feasibility to drive beyond just a few centimeters remains more uncertain. Nvidia is delivering 448G per electrical channel connectivity in Rubin by using a bi-directional SerDes technique. Achieving true 448G uni-directional SerDes will require further development. We may need to move to higher orders of modulation such as PAM6 or PAM8 instead of the PAM4 modulation which has been prevalent since the 56G SerDes era. Using PAM4, which encodes 2 bits per signal, to get to 448G will require a baud rate of 244Gbaud that is likely untenable due to excessive power consumption and insertion loss.
SerDes Scaling Plateau as a Roadblock for Scaling NVLink
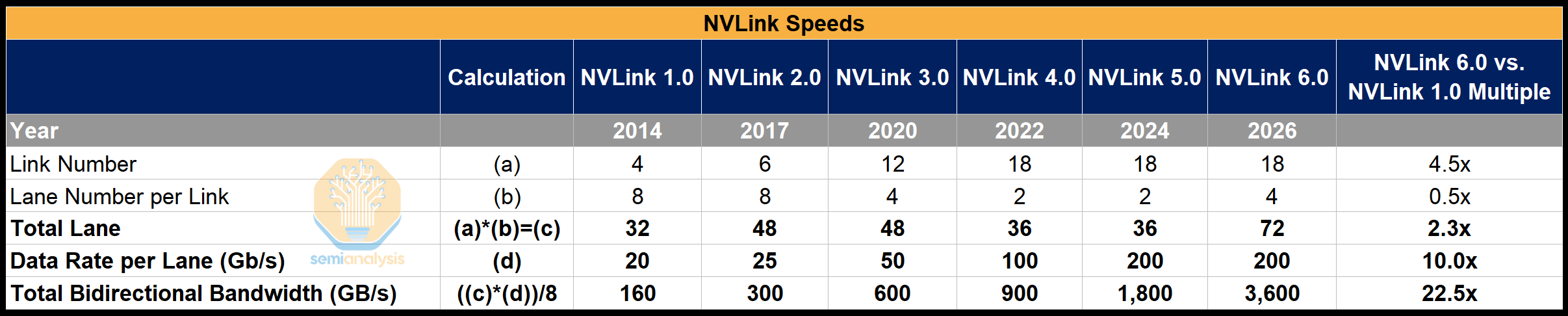
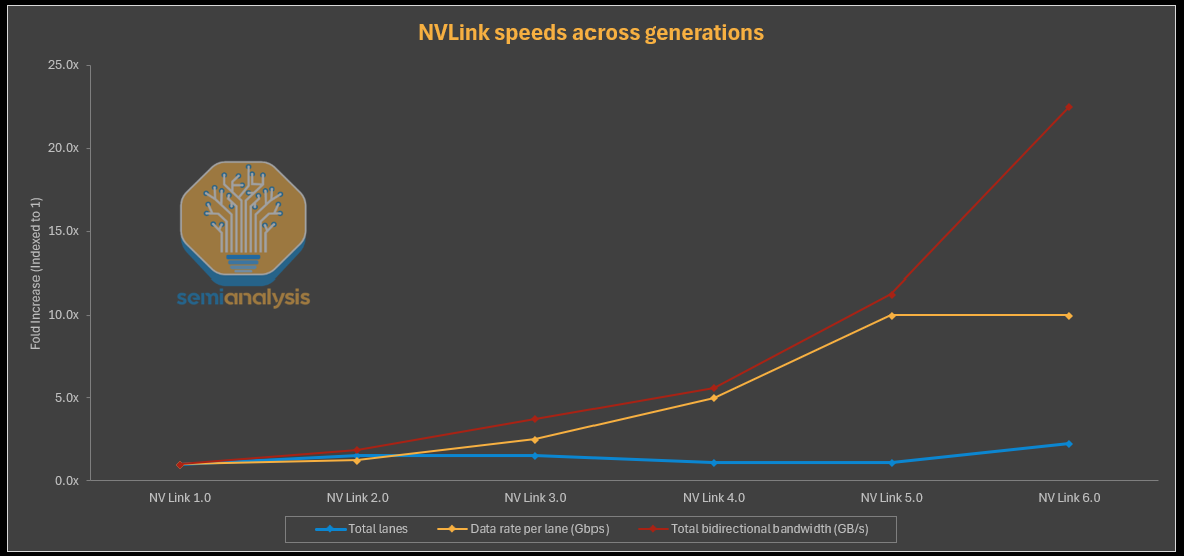
In the NVLink protocol, bandwidth in NVLink 5.0 has increased more than 11x compared to NVLink 1.0. However, this growth has not come from a significant increase in lane count, which has only risen slightly from 32 lanes in NVLink 1.0 to 36 lanes in NVLink 5.0. The key driver of scaling has been a 10x increase in SerDes lane speed, from 20G to 200G. In NVLink 6.0, however, Nvidia is expected to stay on 200G SerDes, meaning it will have to deliver a doubling in lane count - it delivers on this cleverly by using bi-directional SerDes to effectively double the number of lanes while using the same number of physical copper wires. Beyond this, scaling either SerDes speed and overcoming limited shoreline availability to fit more lanes lane count will become increasingly difficult and total escape bandwidth will be stuck.
Scaling escape bandwidth is critical for companies at the leading edge where throughput is a differentiator. For Nvidia, whose NVLink scale up fabric is an important moat, this roadblock could make it easier for competitors such as AMD, and the hyperscalers to catch up.
The solution to this dilemma – or put another way the necessary compromise – is to shorten the electrical I/O as much as possible and offload data transfer to optical links as close to the host ASIC as possible to achieve higher bandwidths. This is why CPO is considered the “holy grail” of interconnect. CPO allows optical communication to happen on the ASIC package, whether via the substrate or the interposer. Electrical signals only need to travel over a few millimeters through the package substrate, or ideally an even shorter distance through a higher quality interposer, rather than tens of centimeters through lossy copper-clad laminate (CCL).
The SerDes can instead be optimized for shorter reach which needs much less circuitry than equivalent long reach SerDes. This makes it easier to design while consuming less power and silicon area. This simplification makes higher-speed SerDes easier to implement and extends the SerDes scaling roadmap. Nonetheless, we remain constrained by the traditional bandwidth model, where bandwidth density continues to scale in proportion to SerDes speed.
To achieve much higher B/W density, wide I/O PHYs are a better option over extremely short distances, offering better bandwidth density per power consumed than SerDes interfaces. Wide I/Os also come at the cost of a much more advanced package. However, in the case of CPO, this is a moot point: the packaging is already highly advanced, so integrating wide I/O PHYs adds little to no additional packaging complexity.
Wide I/O vs SerDes
Once there is no longer a requirement to drive electrical signals to relatively long distances, we can escape serialized interfaces altogether by using wide interfaces that offer much better shoreline density over short distances.
One such example is with UCIe interface. UCIe-A can offer up to ~10 Tbit/s/mm of shoreline density, which is designed for advanced packages (ie. chiplets interfacing via an interposer with sub-2mm reach). On a long edge of a reticle sized chip this is up to 330 Tbit/s (41TByte/s) of off-package bandwidth. This is 660 Tbit/s of bi-directional bandwidth off of both edges. This compares to Blackwell which only has 23.6 Tbit/s of off-package BW, equivalent to around 0.4 Tbit/s/mm of shoreline density, which is a big difference.
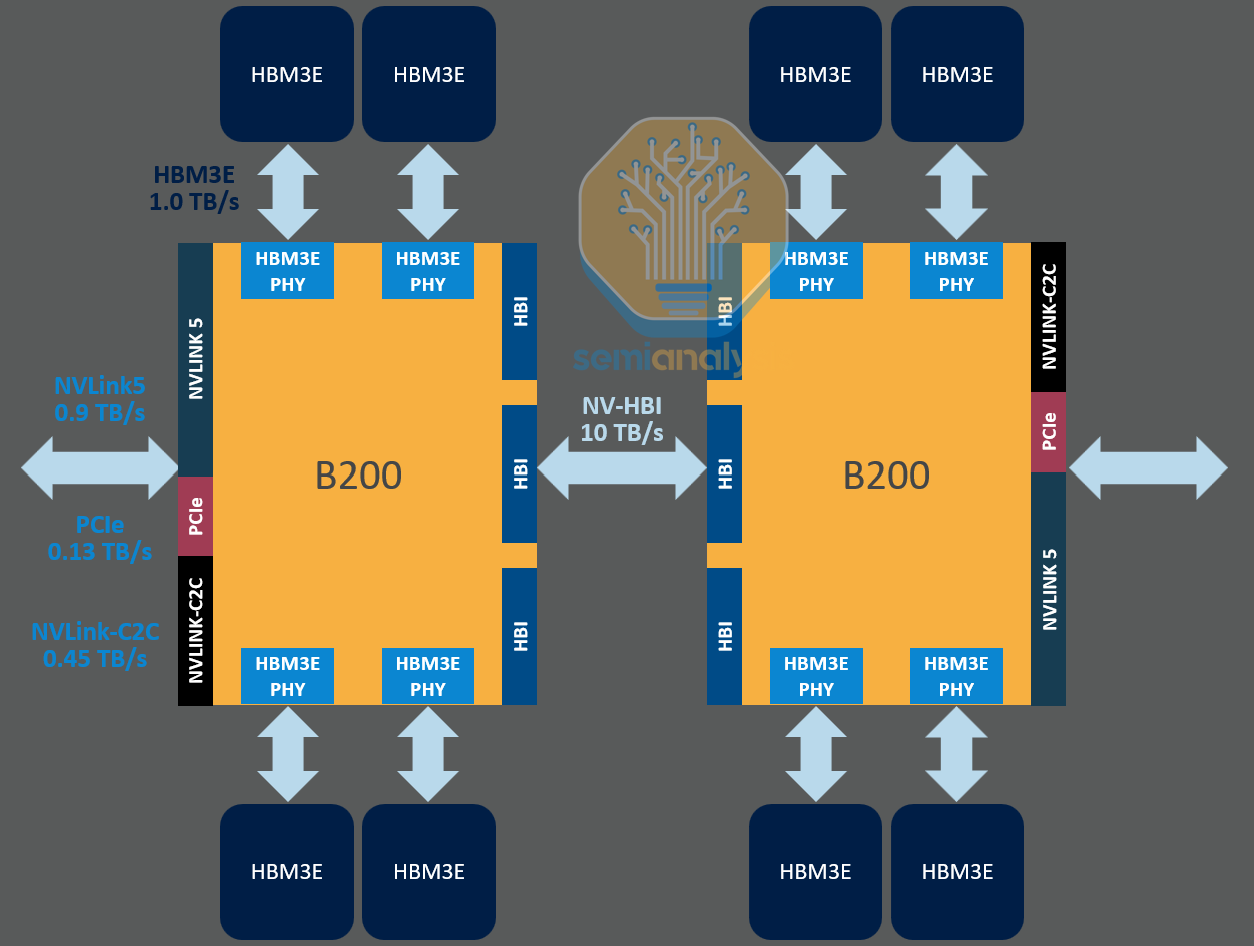
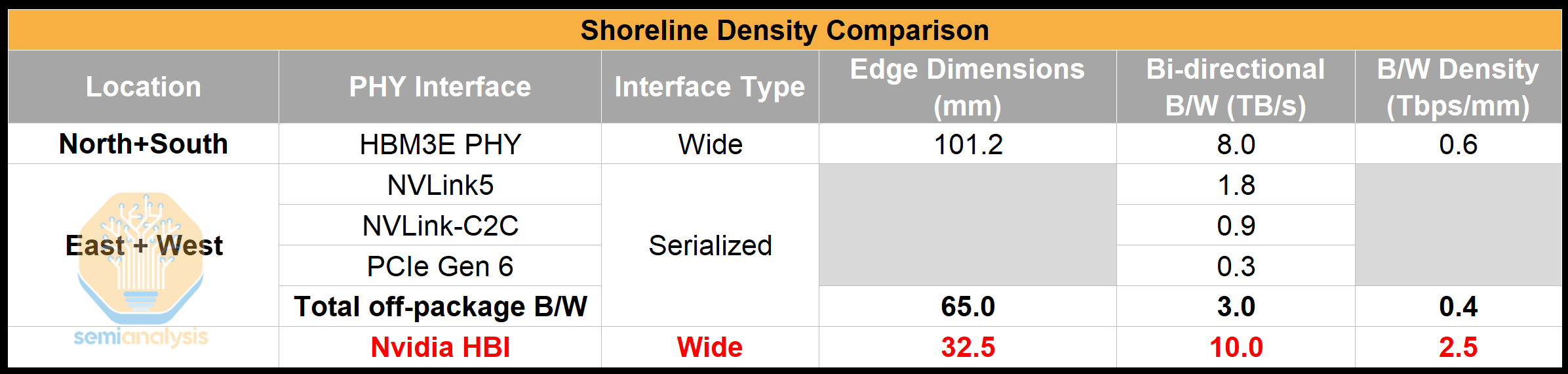
Of course – this is not a like-for-like comparison as these off-package PHYs are needed to drive a long distance. If anything, this is the very point that is being illustrated: with CPO, reach is no longer a consideration as signals are not being driven long distances electrically. At bandwidth densities of 10 Tbit/s/mm, the bottleneck is no longer on the electrical interface but at other parts of the link, namely how much bandwidth can escape on the fibers on the other side.
Getting to this constraint is an end state very far away from today’s reality and the OE will have to share an interposer with the host. Integrating CPO on the interposer itself is even farther off on the roadmap than reliably integrating OEs on the substrate. PHY performance on the substrate is of course inferior with UCIe-S offering about 1.8Tbit/s/mm of shoreline density. This is still a significant uplift over what we believe 224G SerDes offers at ~0.4Tbit/s/mm.
However, Broadcom and Nvidia are persisting with electrical SerDes on their roadmap despite the advantages a wide interface offers. The primary reason is they believe they can still scale SerDes and that they need to design for copper especially as adoption for optics is slow. It also appears more likely that hybrid co-packaged copper and co-packaged optics solutions will be here to stay, requiring them to optimize for both. This approach is taken so as to eliminate the need for multiple tape-outs for different solutions.
Link Resiliency
Link resiliency and reliability are other very important driving factors of CPO technology. In large AI clusters, link downtime is a significant contributor to overall cluster availability, and even small improvements in link availability and stability provides large return on infrastructure investment.
Today, in a large-scale AI cluster approaching 1M links with pluggable modules, there can be dozens of link interruptions per day. Some of these are ‘hard’ failures as a result of component failures or hardware quality, while many of these are ‘soft’ failures resulting from a diversity of root causes that results from the inherent complexity and variability of pluggable-based solutions. There is a long tail of failure modes, including but not limited to signal integrity issues and variation, connector and wirebond quality, contamination on components and pins, noise injection, and other transient effects. There is little correlation with component failures. 80% of optical modules that are returned due to some link failure are ‘no trouble found’.
CPO significantly reduces the inherent complexity and variability of the high-speed signal paths in large-scale AI networks by:
Significantly reducing the number of components in the optical interface. High levels of integration at both the photonic level and chip/package level reduce the complexity for critical high-speed assemblies and improve the reliability and yield at the system level. The number of E/O interfaces is also reduced, thereby minimizing the power loss that occurs at each interface
Significantly improving the signal integrity of the host electrical interface between the host ASIC (e.g. switch) and the optical engine. Insertion losses, reflections and other non-linear impairments are significantly reduced by packaging the optical engine on the first level package with very well defined and deterministic design rules and manufacturing tolerances
Reducing the port-to-port variation in high-speed signal path across the switch, which adds overhead and complexity to DSP signal processing, host and module equalization, host and module firmware and link optimization algorithms. All pluggable module solutions, and the host SerDes, must be designed to accommodate this variation in per-port performance which leads to complexity and points of failure
Removing the ‘human’ element of optical link provisioning. A CPO switch or optical engine is fully assembled and tested ‘known-good’ out of the factory and does not require significant on-site operations to provision the optics in the switch, which can lead to installation variation, damage, contamination, and compatibility issues between systems and optical modules.
Part 3: Bringing CPO to Market and deployment challenges
CPO optical engine manufacturing considerations and go to market
CPO has not yet been manufactured at quantities commensurate with wide-scale adoption. Broadcom was the only vendor to have shipped production systems featuring CPO, with its Bailly and Humboldt switches, but now Nvidia is joining the fray. These have been shipped at very low volumes. CPO introduces many new manufacturing processes and significant manufacturability challenges. Understandably, given the immaturity of the supply chain and lack of data on reliability, customers are also reluctant to take the plunge in adopting the technology.
For CPO to gain traction, an industry leader must invest in shipping these products, driving the supply chain to develop scalable manufacturing and testing processes. Nvidia is the one taking the plunge and their intention is to get the supply chain ready, identify and work out the issues, and prepare datacenter operators for what we think will be the ‘killer’ application: Scale-up networking. There are a few key components and considerations to focus on regarding CPO, all of which have implications on performance and manufacturability. These are:
Host and Optical Engine packaging
Fibers and Fiber coupling
Laser Sources and Wavelength Multiplexing
Modulator Type
Host and Optical Engine Packaging
As the name suggests, “Co-packaged optics”, is fundamentally a packaging and assembly challenge.
An optical engine has both optical and electrical components. The photodetector and modulators are optical components contained in the contained in the “PIC” (photonic integrated circuit). The Driver and Transimpedance Amplifier are electrical circuitry contained in the “EIC” (electric integrated circuit). The PIC and EIC need to be integrated for the OE to function. Multiple packaging methods exist to accomplish this PIC–EIC integration.
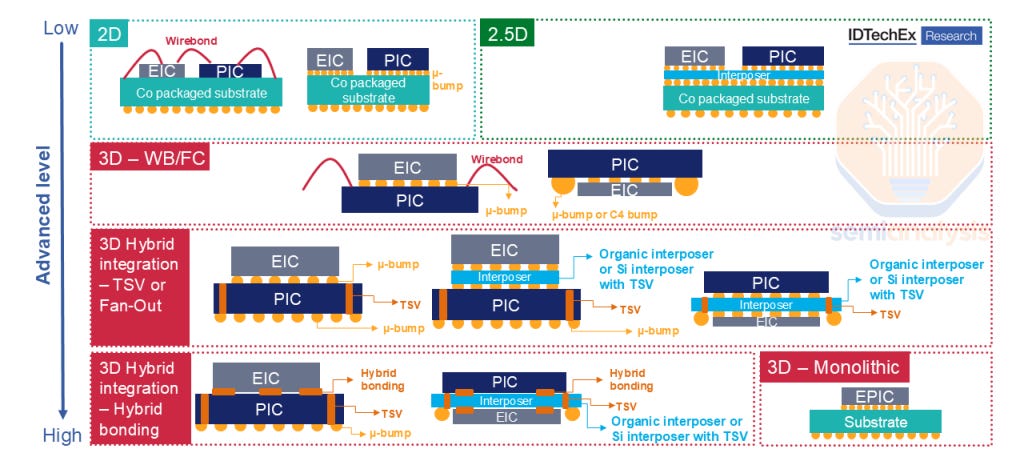
Optical engines can be monolithic by having both the PIC and EIC manufactured on the same silicon wafer. Monolithic integration is the most elegant approach in terms of parasitics, latency, and power. This is the approach taken by Ayar Labs for their second-gen TeraPHY chiplet (though their next-gen chiplet does pivot to TSMC COUPE). GlobalFoundries, Tower and Advanced Micro Foundry are foundries that can offer a monolithic CMOS and SiPho process. However, monolithic processes stop at geometries below around 35nm as photonics processes cannot scale like traditional CMOS. This limits the EIC’s capabilities, especially with the higher lane speeds expected in CPO systems. Despite the inherent simplicity and elegance, this makes monolithic integration a dealbreaker for scaling. This is why Ayar Labs is also moving their roadmap to heterogeneously integrated OEs to allow for further scaling.
Heterogenous integration is becoming the mainstream approach which involves fabricating the PIC using a SiPho process and integrating that with an EIC from a CMOS wafer through advanced packaging. Various packaging solutions exist, with more advanced packaging solutions delivering higher performance. Among them, 3D integration offers the best bandwidth and energy efficiency. A big issue when it comes to EIC to PIC communication is parasitics which erodes performance. Reducing trace length drastically reduces parasitics and therefore coupling efficiency: 3D integration is the only way to reach the performance goals of CPO from a bandwidth and power perspective.
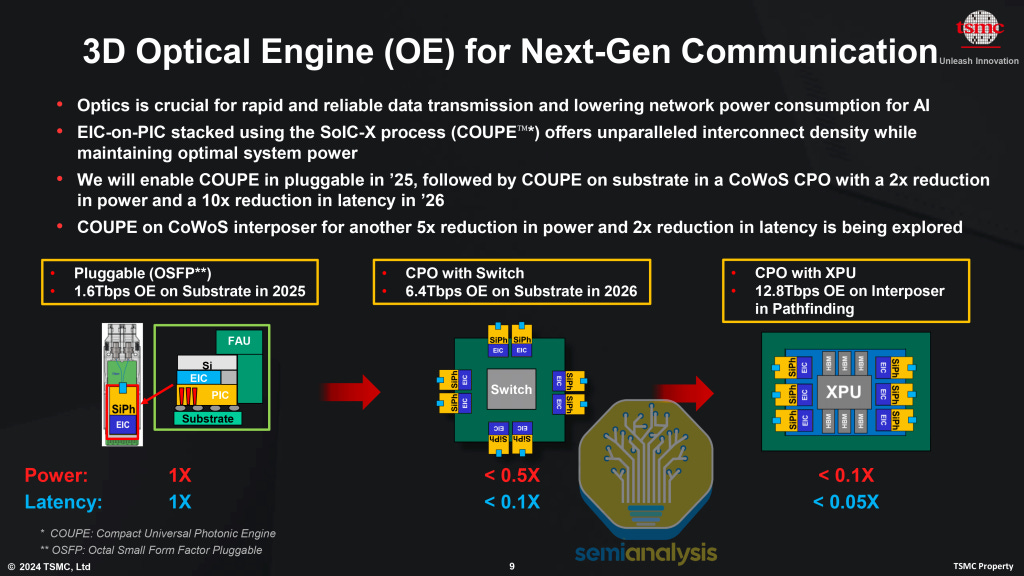
TSMC COUPE is emerging as the integration option of choice
TSMC is racing ahead as the foundry partner of choice for the next generation of OEs for both the fabless giants and startups. The first high-volume products featuring CPO endpoints are being introduced under the name “COUPE” - short for “Compact Universal Photonic Engine”. This includes the fabrication of EICs and PICs, as well as heterogeneous integration under TSMC’s COUPE solution. Nvidia proudly displayed their COUPE optical engines at GTC 2025, and these will be the first COUPE products to ship. Broadcom is also adopting COUPE for their future roadmap, despite having existing generations of their OEs with other supply chain partners. As mentioned earlier, Ayar Labs, who has previously relied on Global Foundries’ Fotonix platform for monolithic optical engines, now also has COUPE on their roadmap.
Unlike its dominance in traditional CMOS logic, TSMC previously had a limited presence in silicon photonics, where Global Foundries and Tower Semi were the preferred foundry partners. However, in recent years, TSMC has been quickly catching up when it comes to their photonic capabilities. TSMC also brings its unquestionable strength in leading edge CMOS logic for the EIC component, as well as its leading packaging capabilities – TSMC is the only foundry that has successfully demonstrated die-to-wafer hybrid bonding capabilities at reasonable scale, having shipped various AMD hybrid bonded chips in volume. Hybrid bonding is a more performant approach to bond the PIC and EIC, though it does comes with a significantly higher cost. Intel is working to develop a similar capability but has faced significant challenges in pioneering this technology.
Overall, TSMC has now become a very key player in CPO despite its previously weaker standalone SiPho capabilities. Like other major players, TSMC aims to capture as much of the value chain as possible. By adopting TSMC’s COUPE solution, customers effectively commit to using TSMC-manufactured PICs, as TSMC does not package SiPho wafers from other foundries. Many CPO focused companies have indeed pivoted decisively towards making TSMC’s COUPE as part of their go to market solution for the next few years.
Die fabrication: TSMC offers a comprehensive suite of solutions for die fabrication. The EIC is manufactured on the N7 node, integrating high-speed optical modulator drivers and TIAs. It also incorporates heater controllers to enable functions such as wavelength stabilization. The PIC, on the other hand, is fabricated on the SOI N65 node, and TSMC provides extensive support for photonic circuit design, photonic layout design and verification, as well as simulation and modeling of photonic circuits (which covers aspects such as RF, noise, and multi-wavelength).
EICs and PICs are bonded using the TSMC-SoIC-bond process. As we mentioned previously, longer trace lengths mean more parasitics, which degrades performance. TSMC’s SoIC is a bumpless interface offering the shortest trace length possible without being monolithic and is therefore the most performant possible way to heterogeneously integrate the EIC and PIC. As shown below, at iso-power, SoIC based OEs offer more than 23x the bandwidth density of an OE integrated with bumps.

COUPE supports the whole optical engine design and integration process. For optical I/O, it supports µLens design, enabling the integration of micro-lenses at the wafer or chip level, as well as optical I/O path simulations covering mirrors, µLenses, grating couplers (GC), and reflectors. For 3D stacking, it supports 3D floorplanning, SoIC-X/TDV/C4 bump layout implementation, interface physical checking, and high-frequency channel model extraction and simulation. To ensure seamless development, the company provides a complete PDK and EDA workflow for COUPE design and verification, enabling designers to implement their technologies efficiently.
Coupling: As we will detail more later, there are two main coupling methods – grating coupling (GC) and edge coupling (EC). COUPE uses one common EIC on PIC bumpless stacking structure for both GC and EC. However, the COUPE-GC structure will distinctively use Silicon lens (Si lens) and MR (metal reflector), while COUPE-EC will uniquely have EC facet (for terminating EC to fiber). In the case of GC, the Si lens is designed on a 770µm silicon carrier (Si-carrier) and the MR is positioned directly underneath the GC, along with the optimization dielectric layers required for optical performance. The Si-carrier is then WoW (wafer-on-wafer) bonded to a CoW (chip-on-wafer) wafer.

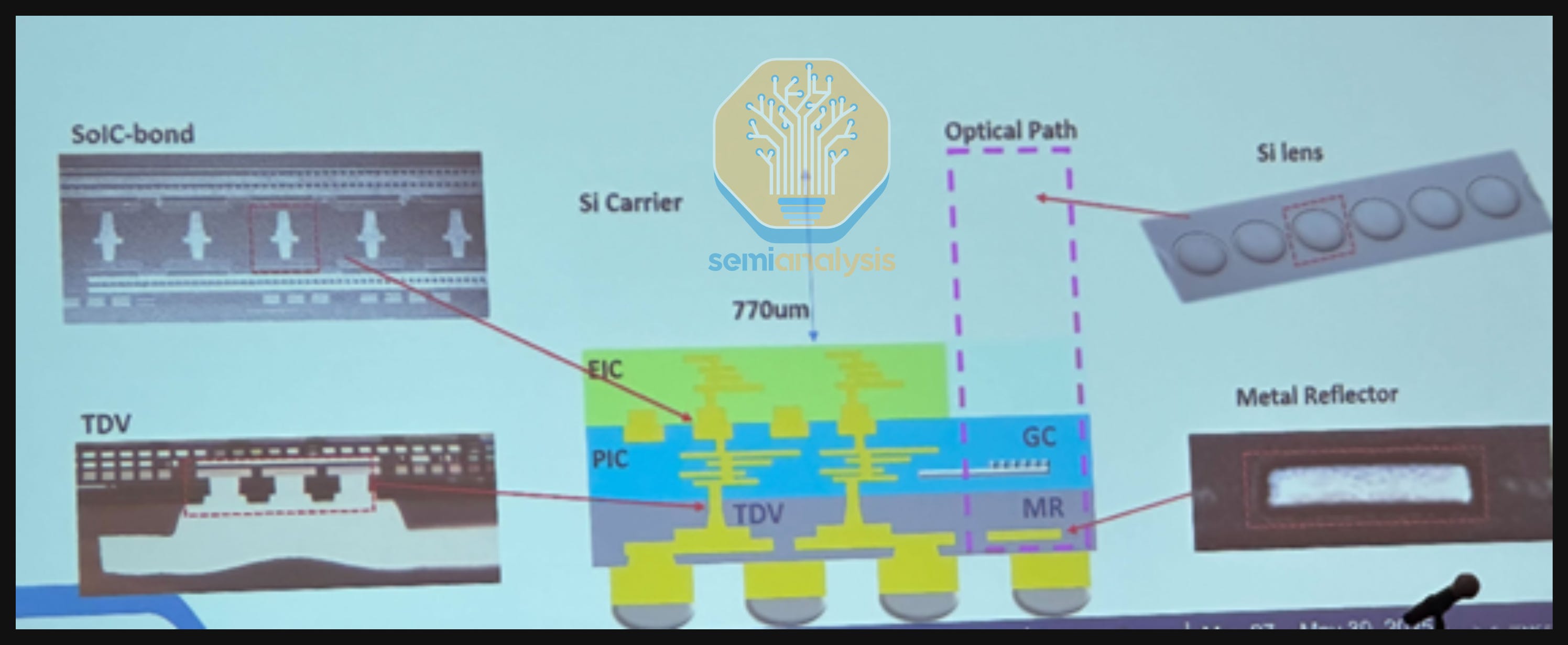
Fiber Attach Unit (FAU): The FAU needs to be co-designed according to the optical path of COUPE. The purpose of the FAU is to couple the light from Si lens into the optical fiber at low insertion loss. The manufacturing difficulty increases as number of I/O increases, but development time and costs are reduced if industry can adhere to specific standards. Overall, each component requires an optimized design to achieve the best optical performance.

Product roadmap: The first iterations of COUPE will be optical engines on the substrate with the ultimate goal being able to put the OEs on the interposer. The interposer offers far more I/O density, therefore enabling greater bandwidth between the OEs and the ASIC PHYs, with the possibility of individual OEs having up to 12.8Tbit/s of bandwidth each, translating to approximately 4 Tbit/s/mm. The challenge for integrating the interposer is scaling the interposer size (which is more expensive than the package substrate) to accommodate the OE.
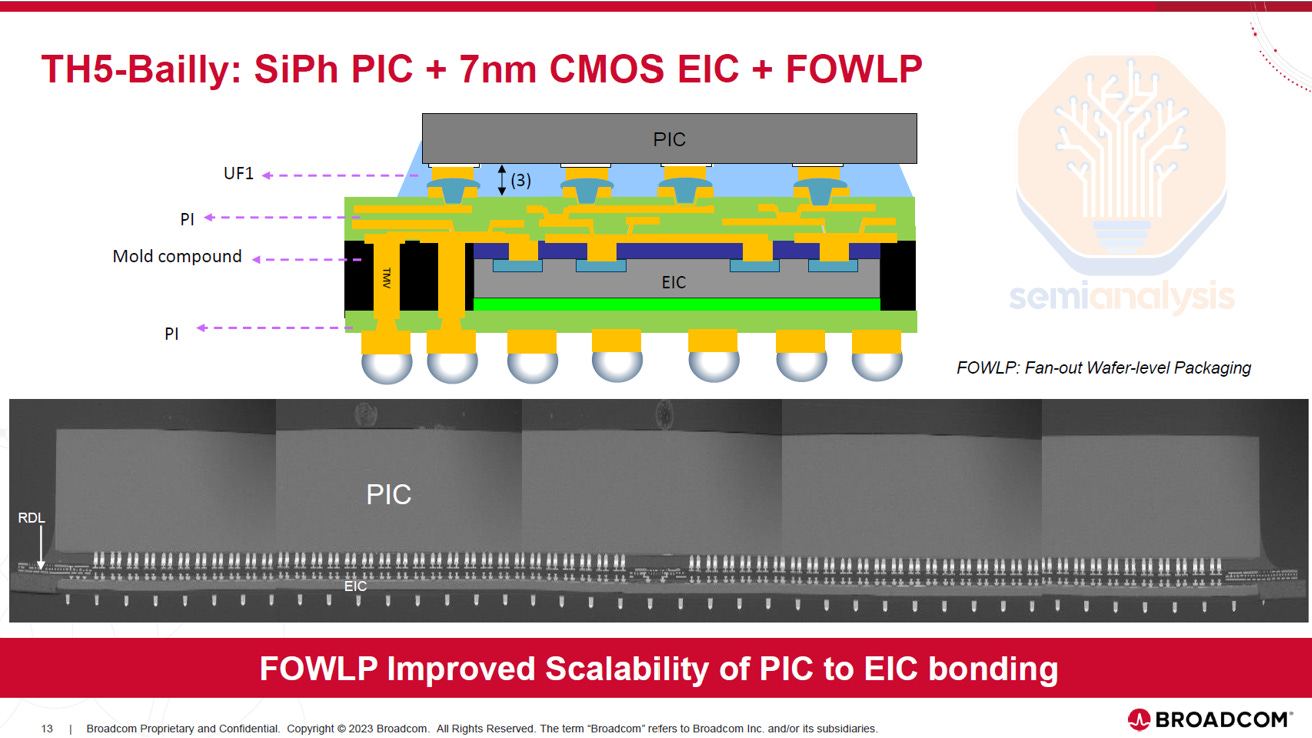
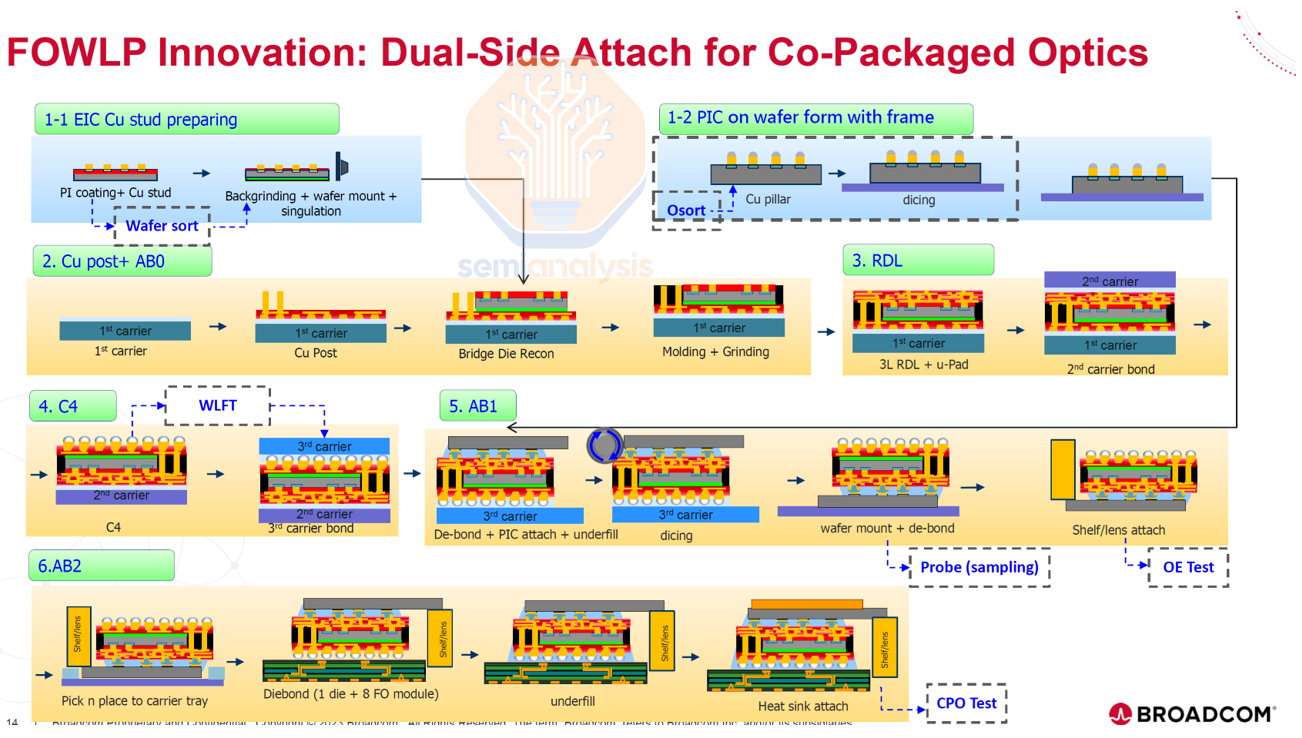
This is why Broadcom is transitioning to TSMC COUPE for its CPO solutions, despite having iterated multiple generations of CPO using a Fan-Out Wafer-Level Packaging (FOWLP) approach developed by SPIL. Notably, Broadcom has committed to COUPE for its future switch and customer accelerator roadmaps. We understand that the FOWLP approach doesn’t allow scaling beyond 100G per lane due to excessive parasitic capacitance, as electrical signals must pass through the Through-Mold Vias (TMV) to get to the EIC. To maintain a competitive roadmap, Broadcom must transition to COUPE, which offers superior performance and scalability. This highlights TSMC’s technological edge, enabling them to secure wins even in optics, a domain where they have historically been considered weaker.
Packaging the OEs with the host
The OEs themselves are placed on a substrate, after which the substrate is flip-chip bonded to the host package. For co-packaging the OEs a lot of package area is required. This necessitates significantly enlarging either the package substrate or interposer, depending on where it is placed. For Nvidia’s Spectrum-X Photonics switch ASIC package, the substrate will measure 110mm by 110mm. For context, this compares to the Blackwell package at 70mm by 76mm which is a very big chip in its own right.
Additionally, attaching more elements to the substrate presents yield challenges. Again, for Spectrum-X, 36 known good OEs need to be flip-chip bonded onto the substrate first – before bonding the interposer module for the ‘on Substrate’ step to complete the CoWoS assembly.
Similarly, for the interposer, the need to manufacture a much larger interposer is costly and it requires bonding many more elements, presents yield challenges. Additionally, these challenges are exacerbated by warpage issues, which become more pronounced as interposer/substrate size scales.
FAUs and Fiber Coupling
Fibers come out of the OE for the data to transmit. One optical lane is comprised of two fibers or one fiber pair (transmit plus receive). Fiber coupling – aligning the fibers precisely with on-chip waveguides for smooth and efficient light transmission – is a crucial and challenging step in CPO, and Fiber Array Units (“FAUs”) are widely used in CPO to assist in that process. There are two main ways to do this, namely edge coupling (EC) and grating coupling (GC).
Edge Coupling
Edge coupling aligns the fiber along the chip’s edge. From the image below, we can see that the fiber end must be precisely aligned with the polished edge of the chip to ensure that the light beam enters the edge coupler accurately. A microlens at the fiber tip focuses and directs the light toward the chip, leading its entry into the waveguide. The waveguide taper gradually widens, allowing for a smooth mode transition that reduces reflections and scattering to ensure coupling efficiency. Without such a lens and taper, there will be significant optical loss at the interface between fiber facet and waveguide facet.
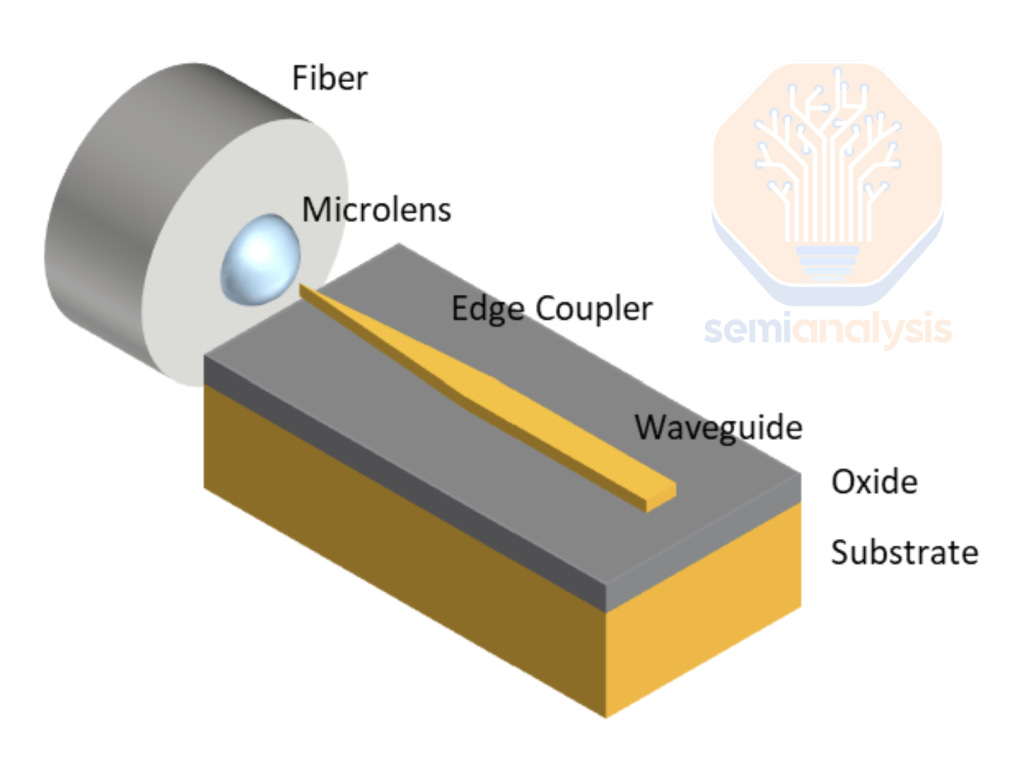
Edge coupling is favored for its low coupling loss, ability to work with a wide range of wavelengths, and polarization insensitivity. However, it also comes with a few disadvantages:
The fabrication process is more complex, and requires undercut and deep etching;
Fiber density can be limited because it’s a 1D structure;
It is incompatible with die stacking (as TSV needs thinning);
Challenges on mechanics reliability on form factor, mechanical stress, warpage, and fiber handling;
It offers less thermal reliability; and
There is a lack of ecosystem compatibility in general.
Global Foundries (GFS) demonstrated a monolithically integrated SiN edge coupler that enables 32 channels and 127µm-pitches on its signature 45nm “Fotonix” platform at this year’s VLSI conference.
Grating Coupling (GC)
In grating couplers (GCs), light enters from the top and the fiber is positioned at a small angle above the grating. As the light reaches the grating, the periodic structure scatters and bends the light downward into the waveguides.
The major benefit of grating/vertical coupling is the ability to have multiple rows of fibers, allowing more fibers per optical engine. GCs also do not need to be placed at the bottom of the substrate, making it possible to place the OE on the interposer. Lastly, GC does not need to be positioned with extreme precision and it can be more easily manufactured with a simple two-step etched process. The drawbacks of GC is that single-polarization grating couplers only work for a limited range of wavelengths and are highly polarization sensitive.
Nvidia had a preference for GC due to its several advantages – it enables 2D density, offers a smaller footprint, is easier to manufacture, and allows for simpler wafer-level testing compared to EC. However, the company is also aware of GC’s several drawbacks – it generally introduces higher optical loss and has a narrower optical bandwidth than EC (the latter can generally accommodate a broader spectral range).
TSMC also clearly has a higher preference for GC, which is supported in their COUPE platform.

Laser Type and Wavelength Division Multiplexing (WDM)
There are two main ways to integrate lasers into CPO.
The first approach, on-chip lasers, integrates the laser and modulator on the same photonic chip, typically by bonding III‑V (InP) materials onto silicon. While on-chip lasers simplify design and reduce insertion loss, there can be a few challenges:
Lasers are known to be the one of the most failure prone components within the system – failures would have a high blast radius if integrated into the CPO engine as it would take down the whole chip;
Lasers are also sensitive to heat, placing them on a co-packaged OE would expose a laser to high heat as it would be very close to the hottest part of the system, the host silicon, which would only exacerbate the issue;
On-chip lasers typically struggle to deliver high enough power output.
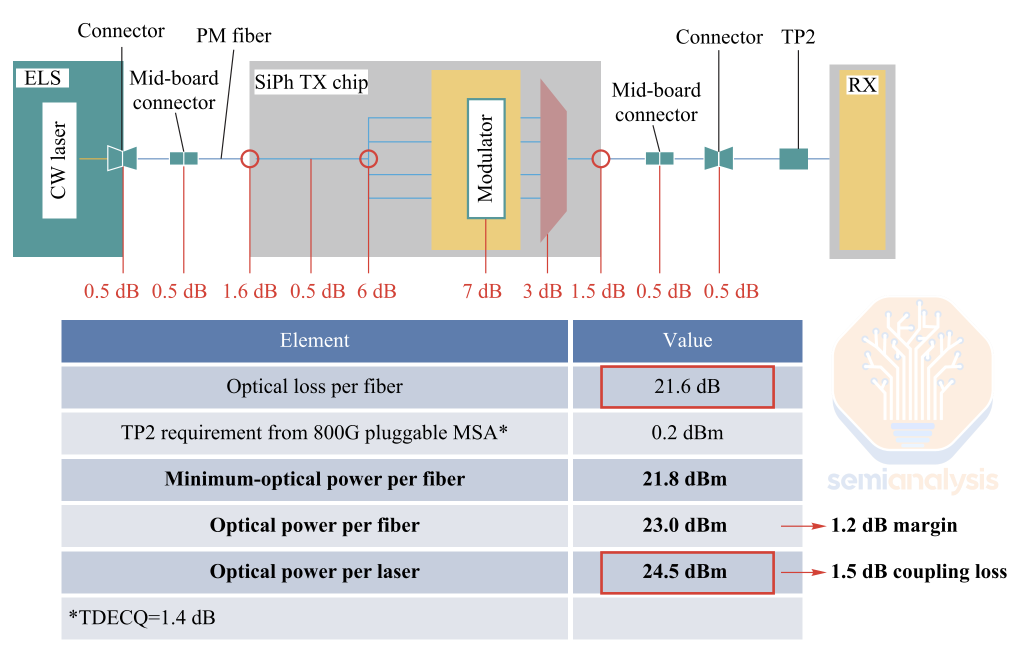
The one approach where the industry has come to a consensus is to use an External Light Sources (ELS). The laser is in a separate module connected to the optical engine via fiber. Often times, this laser is in a pluggable form factor like OSFP. This setup simplifies field servicing in the fairly common case of laser failures.
The downside of the ELS is higher power consumption. As seen in the diagram below, in an ELS based system, output power is lost at multiple stages due to various factors like connector losses, fiber coupling losses and modulator inefficiencies. As such, each laser in this system must provide 24.5 dBm of optical power to compensate for losses and ensure reliable transmission. High-output lasers generate more heat and degrade faster under thermal stress, with lasers and thermo-electric coolers accounting for ~70% of ELS power consumption. While incremental improvements in laser design, packaging, and optical paths help, the issue of high power requirements of lasers has not been fully solved.
At this year’s VLSI conference, Nvidia highlighted several laser partners within its ecosystem: Lumentum for single high-power DFBs, Ayar Labs for DFB arrays, Innolume for quantum-dot mode-locked combs, and Xscape, Enlightra, and Iloomina for pumped nonlinear resonant combs.
Nvidia has also discussed exploring VCSEL arrays as a potential alternative laser solution. While the per-fiber data rate would be lower and there may be some thermal issues, VCSELs may offer power and cost efficiency and can be suitable for “wide-and-slow” applications. That said, we don’t see this as an immediate priority for Nvidia.
Wavelength Division Multiplexing (WDM) is when multiple different wavelengths, or lambdas, of light are transmitted over the same strand of fiber. The two common variants of WDM are Coarse WDM (CWDM) and Dense WDM (DWDM). CWDM typically carries fewer channels spaced relatively far apart (typically 20 nm spacing), while DWDM packs many lanes with very tight spacing (often <1nm spacing). CWDM’s wider channel spacing limits its capacity, while DWDM’s narrower spacing can accommodate 40, 80, or even more than 100 channels. WDM is important because most implementations of CPO proposed today are limited by the number fibers that can be attached to the optical engines. Limited fiber pairs means each fiber pair must be maximized.
Modulator Types
When the lasers enter the PIC, they undergo a modulation phase (driven by drivers) where electronic signals are encoded into laser’s wavelength. The three primary types of modulators used for this process are Mach-Zender Modulators (MZMs), Micro-Ring Modulators (MRMs), and Electro-Absorption Modulators (EAMs). Each individual lambda (individual wavelength on an individual optical lane) requires one modulator.
Mach-Zehnder Modulator (MZM)
MZM encodes data by splitting a continuous-wave optical signal into two waveguide arms whose refractive indices are varied by an applied voltage. When the arms recombine, their interference pattern modulates the signal’s intensity or phase.
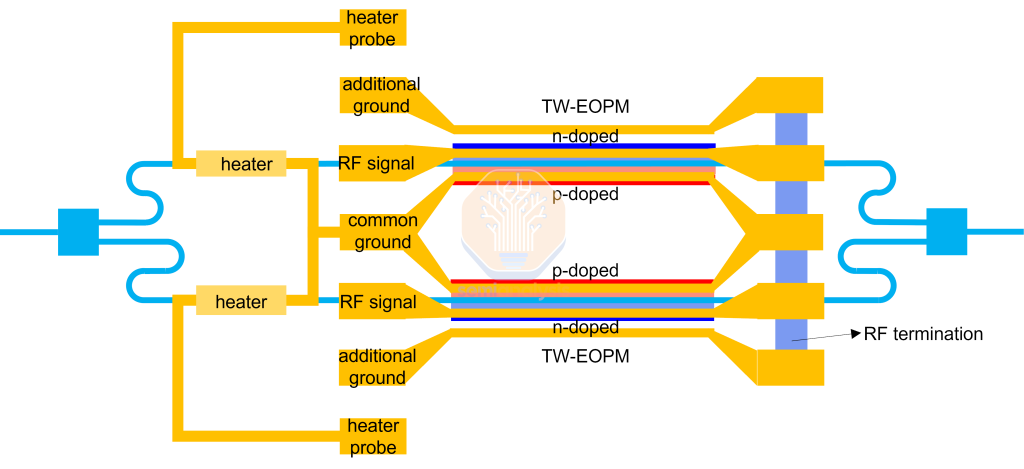
MZMs are the easiest of the three to implement and have low thermal sensitivity, reducing the need for precise temperature control. Their high linearity supports advanced modulation formats like PAM4 and coherent QAM (although QAM is not suitable for HPC/AI workloads). MZM’s Low chirp improves signal integrity for higher-order modulation and long-distance transmission. MZMs also enable higher bandwidth per channel: 200G per lane has been proven working, and 400G per lane is believed possible with non-coherent PAM modulation.
However, MZM’s drawbacks are:
Large form factor with dimensions measured in millimeter scale for length (compared to MRM in micron scale), since they require two waveguide arms and a combining region, consuming more chip area and limiting the density of modulators (and thus channels) contained in an OE PIC. MZM sizes are on the order of ~12,000µm2, GeSi EAMs at around 250µm2 (5x50µm) with MRMs at between 25µm2 and 225µm2 (5-15µm2 in diameter). This is one critical drawback of MZMs that can limit scaling. However, if one considers the size of a full PIC/EIC combination, including drivers and optical/ electrical control circuitry around the modulators, MZMs size disadvantage could appear less notable,
High power consumption, as the phase-shifting process demands significant energy. It also has higher bias conditions – basically initiating voltages – than MRM (which operates at sub-voltage). However, firms like Nubis are trying to develop clever designs to ameliorate the power disadvantages of MZMs.
In the startup ecosystem, Nubis is one of the firms that mainly utilize MZM for their scale-up CPO solutions. MZMs are not widely selected in the startup ecosystem due to its large form factor and limited number of lambdas.
Micro-Ring Modulators (MRMs)
MRM uses a compact ring waveguide coupled to one or more straight waveguides. An electrical signal alters the ring’s refractive index, shifting its resonant wavelength. By tuning resonance to align or misalign with the input light, MRMs modulate the optical signal’s intensity or phase, thereby encoding data.
A light source is passed into the ring from the input port – for most wavelengths of light, there will be no resonance in the ring such that the light will pass through the device, from the input port to the through port. If the wavelength satisfies the resonance condition, then light will constructively interfere in the ring, and will be instead pulled into the drop port. As illustrated in the normalized power graph below, light of a specific wavelength will cause a sharp peak in transmission power at the drop port and a corresponding drop in transmission at the through port. This effect can be used for modulation.

Optical Engines typically use multiple MRMs, and each of these rings can be tuned to a different wavelength, enabling wavelength division multiplexing (WDM) using the rings themselves as opposed to requiring an additional set of devices to accomplish WDM.
MRMs have a few key advantages:
The are extremely compact (scale in the tens of microns), allowing far higher modulator density than MZMs. MZM sizes are on the order of ~12,000µm2, GeSi EAMs at around 250µm2 (5x50µm) with MRMs at between 25µm2 and 225µm2 (5-15µm2 in diameter);
Rings are very well-suited for WDM applications (including DWDM with 8 or 16 wavelengths), and built-in mux/demux functionality;
MRMs can be highly energy efficient (lower power per bit);
And finally - rings have low chirp, which improves signal quality.
However, MRMs also come with a few challenges:
MRMs can be 10-100 times more temperature-sensitive than MZMs and EAMs, requiring very precise control systems that are challenging to design and manufacture;
They are non-linear, complicating higher-order modulation like PAM4/6/8;
MRMs’ sensitivity and tight temperature control tolerances can make standardization difficult, since each design has precise requirements.
Among the solution providers, Nvidia has a clear preference for MRMs. They claimed to be the first to design and put MRMs in CPO systems. The company believes MRM’s key advantages are its compact size and low driving voltage, which helps reduce power consumption. However, MRM technology is also known to be difficult to control, making design precision crucial for successful implementation – which is indeed an strength of Nvidia.
In terms of fabrication, TSMC’s advanced CMOS expertise is well suited for fabricating MRMs with high-precision and great Q-factor. In addition, Tower also bring strong fabrication capabilities to their photonics nodes.
MRMs are challenging to implement but is certainly feasible. They can potentially enable higher bandwidth densities than MZMs. That’s why TSMC, Nvidia, and many CPO companies such as Ayar Labs, Lightmatter, and Ranovus, focus on this technology roadmap.
Electro-Absorption Modulators (EAM)
EAMs modulate signals by altering their ability to absorb light based on the voltage applied. More specifically, when low or no voltage is applied to an EAM, the device allows most of the incoming laser light to pass through, making it appear transparent or “open.” When a higher voltage is applied, the band gap of a GeSi modulator shifts to cover the high C-band range (above 1500nm), increasing the absorption coefficient for those wavelengths and attenuating “closing” the optical signal that is passing through the nearby waveguide. This is known as the Franz-Keldysh effect. This switching between “open” and “close” states modulates the intensity of the light, effectively encoding data onto the optical signal.
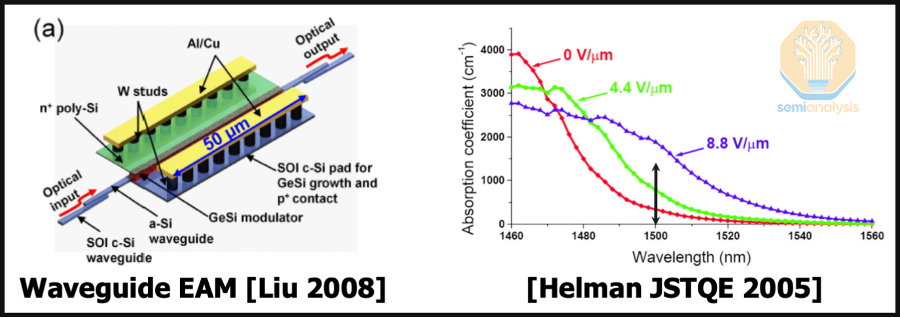
The same principle is used today in transceivers that use Electro-Absorption Modulated Lasers (EMLs) for modulation. A continuous wave (CW) distributed feedback (DFB) lasers and an InP based EAM is coupled together to build up a single discrete EML, which can modulate one lane. For example, an 800G DR8 transceiver uses 8 EMLs across 8 individual fiber lanes, each using PAM4 modulation (2 bits/signal) and signaling at ~56 GBaud. Unlike GeSi based modulators, the band gap of an InP modulator corresponds to the O-band (1310nm) which is the standard wavelength used is all Datacom DR optics, allowing a great degree of interoperability.
InP modulators have a few downsides that make it less than ideal for use in CPO. InP wafers tend to be small (3” or 6”) and suffer from low yields – both factors drive up unit costs for InP-based devices when compared to Silicon which can be built on 8” or 12” processes. Coupling InP to Silicon is also far more difficult than coupling GeSi to other silicon devices.
EAMs have several advantages compared to MRMs and MZIs:
Clearly – both EAMs and MRMs have control logic and heaters that act to stabilize both against variations in temperatures, but EAMs have fundamentally less sensitivity to temperature. Compared to MRMs, EAMs have much better thermal stability above 50° C while MRMs are very sensitive to temperature. A typical stability of 70-90 pm/C for MRMs mean that a 2° C variation shifts resonance by 0.14nm, well beyond the 0.1nm resonance shift at which MRM performance collapses. In contrast, EAMs can tolerate an instantaneous temperature shift of up to 35° C. This tolerance is important in particular for Celestial AI’s approach as their EAM modulator resides within an interposer beneath a high-XPU power compute engine that dissipates hundreds of watts of power. EAMs can also tolerate high ambient temperature ranges of around 80° C which may be applicable for chiplet applications which sit next to the XPU and not beneath it.
Compared to MZIs, EAMs are much smaller in size and consume less power as the relatively large size of MZIs requires a high voltage swing, amplifying the SerDes to achieve a swing of 0-5V. Mach Zender Modulators (MZMs) are on the order of ~12,000µm2, GeSi EAMs at around 250µm2 (5x50µm) with MRMs at between 25µm2 and 225µm2 (5-15µm2 in diameter). MZIs also require more power usage for the heaters needed to keep such a large device at the desired bias.
On the other hand, there are a few drawbacks in using GeSi EAMs for CPO:
Physical modulator structures built on Silicon or Silicon Nitride such as MRMs and MZIs have been perceived to have far greater endurance and reliability than GeSi based devices. Indeed, many worry about the reliability of GeSi based devices given the difficulty of working with and integrating Germanium-based devices, but Celestial argues that GeSi based EAMs, which are essentially the reverse of a Photodetector, are a known quantity when it comes to reliability given the ubiquity of photodetectors in transceivers today.
GeSi modulators’ band edge is naturally in the C-band (i.e. 1530nm-1565nm). Designing quantum wells to shift this to the O-band (i.e. 1260-1360nm) is a very difficult engineering problem. This means that GeSi based EAMs will likely form part of a book-ended CPO system and cannot easily be used to participate in an open chiplet-based ecosystem.
Building out a laser ecosystem around C-band laser sources could have diseconomies of scale when compared to using the well-developed ecosystem around O-band CW laser sources. Most datacom lasers are built for the O-band but Celestial points out that there are considerable volumes of 1577nm XGS-PON lasers manufactured. These are typically used for consumer fiber to the home and business connectivity applications.
A SiGe EAM has an insertion loss of around 4-5dB vs 3-5 dB for both MRMs and MZIs. While MRMs can be used to directly multiplex different wavelengths, EAMs require a separate multiplexer to implement CWDM or DWDM, adding slightly to the potential loss budget.
Overall, EAMs are not widely used in current CPO implementations, with Celestial AI standing out as one of the few companies actively pursuing this approach.
OE roadmap – scaling OEs
The Optical Engines available today typically offer between 1.6T and 3.2T of aggregate bandwidth. Nvidia’s Quantum CPO includes a 1.6T engine, with a 3.2T version planned for Spectrum. Broadcom has shown off their 6.4T OE for Bailly, but the form factor is very big (2-3x the width of Nvidia) and it requires two FAUs so its bandwidth density may be similar to what Nvidia’s offering. This is the same case for Marvell’s 6.4T OE, requiring 2 FAUs, so it occupies a large footprint. Marvell’s OE is not going into any production systems that we know of anytime soon either.
As we’ve discussed, the 3.2T OE implementation in Nvidia’s Spectrum-X photonics switches does not offer more shoreline bandwidth density than pluggables that are driven by long reach SerDes. In other words, optical engine density must scale multiple times to deliver a compelling performance advantage and drive customer adoption. This means scaling both the electrical interface between the host silicon and the OE EIC, as well as scaling the amount of bandwidth coming out of the fibers.
But what if we were able to design the next generation of interconnect with a free hand – what could be approaches for unlocking greater bandwidth for this generation and beyond?
Key approaches for scaling bandwidth
Let’s discuss the key approaches for scaling bandwidth from co-packaged optical engines:
Continue with electrical SerDes based PHYs: leverage simpler design implementation, reduced area and lower power by using short reach (“SR”) SerDes over long reach SerDes. This will eventually still be limited by SerDes speed at the electrical interface where we are running out of runway. This idea here is to go with an interim solution as silicon designers can avoid having to rearchitect their I/O. In addition, using electrical SerDes offers the flexibility to use existing pluggable optics and/or copper with the same silicon.
Use a wide I/O PHY such as UCIe operating at a lower Baud rate such as 56G with NRZ modulation. This is less demanding on the optical engine’s EIC and may even eliminate the need for expensive hybrid bonding as parasitics are less of an issue at low speeds. However, using a low signal rate means that the number of fibers leaving the optical engine can more quickly become a bottleneck. Wavelength-division multiplexing helps address this by allowing each fiber to carry multiple data streams in parallel.
Use wide I/O PHY such as UCIe, then have the EIC serialize to a smaller number of optical fiber lanes. Continuing to use a high Baud rate with PAM4 modulation to maximize the speed of each optical lane, add multiple wavelengths if needed using a WDM scheme, allowing multiple lambdas per fiber pair to further increase bandwidth.
With the electrical side addressed, the next challenge is how much escape bandwidth can be carried through the fibers. The total fiber bandwidth depends on three key factors: 1) the number of fibers (which defines the optical lanes); 2) the speed per lane, and 3) the number of wavelengths per fiber – each representing a vector for scaling.
Lately the industry has divided concepts into two main approaches: Fast and Narrow vs Slow and Wide. Fast and Narrow envisions a lower number of fibers per FAU – in the high double digits at most and fast links on each fiber pair, while Slow and Wide is based on the idea of a far greater number of fiber pairs (likely with much finer pitch) and much slower bandwidth per individual fiber pair.
More fiber pairs. Fiber density is limited by fiber pitch and the total number of fibers within a single FAU is limited by what’s manufacturable before yield becomes an issue. Currently, the minimum pitch of a fiber is 127 microns (µm), meaning a maximum of 8 fibers per mm. The industry is working toward 80-µm pitches and multicore fibers to further scale the number of fibers a certain area can accommodate. However, attaching more fibers bring manufacturability challenges:
A) Aligning fibers, which still involves a lot of manual process, is prone to yield loss, and the FAU yield suffers with each successive fiber that needs to be aligned; there are automation tools provided by companies like Ficontec, but they still suffer from low throughput,
B) coupling choices also matter: edge coupling limits the fiber array to a single row, while grating coupling can support multiple rows. Currently the most sizable fiber array we’ve seen is Nubis’ 2D FAU with 36 fibers.Speed per lane. There are two dimensions that can impact lane speed:
A) Baud rate: defines the number of symbols sent per second; today’s advanced systems operate at 100 Gbaud, while the industry is pushing for 200 Gbaud. A higher baud rate, however, places higher requirement on modulator to switch at higher frequencies; among the various types, MZM is the most capable in this metric and has a relatively clear path toward achieving 200 Gbaud.
B) Modulation: defines the number of bits carried per symbol. NRZ (1 bit per symbol) and PAM4 (2 bits per symbol via 4 different amplitudes) are widely adopted today. Research is extending to PAM6 (~2.6 bits per symbol) and PAM8 (3 bits per symbol). Higher order modulation schemes are accessible by signalling using different phases of light in addition to multiple amplitude levels. DP-16QAM enables two orthogonal planes each with 4 different amplitudes, 4 different phases for a total of 256 possible signals – delivering 8 bits per signal.Wavelength Division Multiplexing (WDM). Optical fibers can carry multiple wavelengths of light simultaneously. For example, a fiber with 8 wavelengths, each carrying data a 200Gbit/s, can transmit an aggregate capacity of 1.6 Tbit/s. Commercially available DWDM solutions today typically offer 8-lambda or 16-lambda configurations. Researchers are also exploring broad-spectrum, band multiplexing, and interlaying techniques to increase the lambda counts. One key challenge in scaling the number of wavelengths is developing reliable laser sources that can generate multiple lanes of light reliably and efficiently. Ayar Labs’ Supernova light source has a laser capable of 16 wavelengths (the laser is supplied by Sivers). Scintil’s wafer-scale InP laser similarly provides up to 16 wavelengths, and Xscape Photonics is working to develop a tuneable comb laser with up to 64 wavelengths. Among modulators, MRM are most well suited for handling multiple wavelengths and has built in multiplexing (mux) and demultiplexing (demux) functionality.
The table below outlines several approaches to scale optical engines to 12.8T and beyond.
CPO adoption pace and deployment challenges
Nvidia’s first CPO products will be for backend scale out switches with their InfiniBand CPO available in 2H 2025 and Ethernet CPO switch available in H2 2026. We think this initial phase will primarily serve as a market test and a preparatory phase to bring up supply chain maturity. We expect total shipment volume to range from 10-15k units in 2026.
There will have to be a more compelling rationale for adopting CPO for deployments to advance further and faster and become truly ubiquitous. Two possibilities could be a dramatic total cost of ownership advantage from adopting CPO, or if the electrical LR SerDes needed to drive the signal from the switch ASIC to the front panel of a switch box hits a hard speed or range wall.
Offsetting any TCO benefits are two major things that datacenter operators dislike about deploying CPO-based systems: the lack of interoperability and serviceability challenges.
The challenges of CPO extend to outside the package and into the whole system. Managing fibers, front plate density, external lasers are all essential parts that are challenges. To enable CPO the chip company needs to provide an end-to-end solution which the customer can deploy. This is a continuation of the trend we are seeing, especially with Nvidia, who is focused on system design to scale performance.
Proprietary solutions vs standards
One key challenge to CPO adoption is achieving interoperability while overcoming the industry’s deep-rooted reliance on the well-established and highly interoperable pluggable optics model.
There are three key flavors of interoperability: (1) electrical, (2) optical, and (3) mechanical. For pluggables, interoperability:
Is typically handled by the OIF (Optical Internetworking Forum),
is typically handled by IEEE (and sometimes the OIF). IEEE plays a central role through its IEEE 802.3 standard, which defines the Ethernet Physical Medium Dependent (PMD) layers. These specifications cover key parameters such as modulation formats, lane speeds, lane counts, reach and media types, and wavelengths for optical signals. By conforming to these standardized PMDs, transceivers from different vendors can operate interchangeably, ensuring true plug-and-play compatibility across a multi-vendor ecosystem,
and is typically handled by MSAs (Multi-Source Agreements). MSAs define specialized solutions and ensure multi-vendor interoperability outside of official IEEE standards.
Through the combination of OIF, IEEE standards and MSAs, pluggable transceivers achieve broad interoperability and a robust multi-vendor ecosystem. For CPO:
It’s critical that CPO modules be compliant electrically, as otherwise they cannot speak with state-of-the-art SerDes.
Compatibility on optical is helpful because it can then be compatible with standard pluggables elsewhere in the cluster.
It is important to understand that CPO is in the “wild west” phase, with some solutions and architectural decisions leading towards completely proprietary form factors. This is what the new OIF high-density interconnect efforts (such as the CPX paradigm) are trying to address.
Once (1)+(2)+(3) are covered, CPO can become operationally very similar to pluggables, which will help enable widespread adoption.
However, at this moment, CPO is not yet embracing standards to the same extent that puggables are and cannot yet guarantee interoperability to extent optical transceivers can. Part of the challenge is that vendors are pushing system level solutions rather than selling the silicon alone to the box makers. This is because the challenges of CPO extend to outside the package and into the whole system. Managing fibers, front plate density, modulator architecture and external lasers are all essential parts that are challenges. To bootstrap CPO adoption, companies like Nvidia need to start by providing an end-to-end solution.
One approach to this end could be to adopt standardized solutions at the component level where co-packaged OEs followed a standardized fiber interface with photonic components—such as lasers, modulators, and photodiodes—that align with Ethernet standards or MSAs for wavelength, speed, and modulation. This would enable true interoperability, letting customers mix and match products from various vendors without having to source all their equipment from one vendor. If OEs are socketable, operators could easily swap them out in the case of failure. Such standardization would also create a more competitive and robust multi-vendor market that could drive down costs for customers. It would also allow customers to choose various vendors based on lead times, prices, or unique features without being beholden to one vendor.
Serviceability and reliability
An issue that must be addressed before CPO can be widely adopted comes from fiber coupling. Connecting fiber to a silicon photonics device in a pluggable optical module is relatively straightforward, whereas coupling fiber to an optical engine for CPO is much more challenging. In CPO systems, fibers must be precisely aligned with sub-micron accuracy to couple light into very small waveguides (often submicron in both width and height) on the chip, while pluggables present less hassle as they use pre-aligned, standardized connectors. Furthermore, in CPO based systems, fiber coupling happens within the cramped and thermally active switch chassis, unlike pluggables where the fiber coupling happens far away from the device’s main package.
While copper-based electrical communication suffers from inferior insertion loss and signal integrity when compared to optical, copper is generally reliable in other ways. Optical devices are inherently temperature sensitive. Changes in operating temperature can alter laser wavelengths, reduce component efficiency, and negatively affect reliability, often requiring specialized temperature control or calibration mechanisms. Additionally, photonic components also naturally degrade over time, gradually losing optical efficiency due to aging, contamination, or mechanical stress, further challenging long-term reliability. Environmental factors, such as dust, humidity, and mechanical disturbances, disproportionately impact optical systems, which are more vulnerable than copper-based electrical links.
These environmental and operational challenges extend directly to the physical fibers themselves. Fiber performance is highly sensitive to physical disturbances, particularly bending, which not only increases optical insertion loss but also accelerates breakages and failures. In a chassis containing multiple fiber arrays—typically two per engine, one for the connector and one from the ELS for the light source—each array must be routed with strict topological considerations. Every individual fiber link requires a unique length, accounting for variations in the distance from the faceplate to each optical engine and the routing constraints imposed by adjacent arrays.
We can see in the close-up image of the Quantum-X CPO switch below that the fiber ribbons coming out of the OEs need to be routed through the fiber cassettes to manage the fiber properly. FAUs are detachable to provision for breakages that need replacing. But the more complicated routing of fiber within the switch means that fiber/FAU replacement is far more onerous than replacing a broken pluggable transceiver which is simply a hot swap at the front of the face plate. In the case of the CPO switch, the engineer will need to go inside the box/chassis, remove the broken FAU, and then properly re-attach the new FAU through the cassette. This needs to be done without disturbing the other fibers. While Nvidia has been emphasizing the reliability benefits of CPO, serviceability is another element that is worth discussing at more length.

Part 4: CPO Products of Today and Tomorrow
In this part, we will start by introducing CPO products that are on the market today or are shortly coming to market, starting with Nvidia and Broadcom’s portfolios and moving to explaining the offerings from various CPO focused companies. We cover Intel CPO, MediaTek’s CPO work, Ayar Labs, Nubis, Celestial AI, Lightmatter, Xscape Photonics, Ranovus and Scintil, describing each provider’s solution in detail and weigh in on important puts and takes for each company’s approach. Finally, we will circle back to discuss the supply chain, covering manufacturing, testing and assembly of the key CPO components such as Optical Engines and External Laser Sources.
Nvidia CPO
At GTC 2025, Nvidia debuted their first CPO-based switches for scale-out networks. Three different CPO-based switches were announced. We will walk through each of them in turn, but we first present a neat table aggregating all the important specifications:
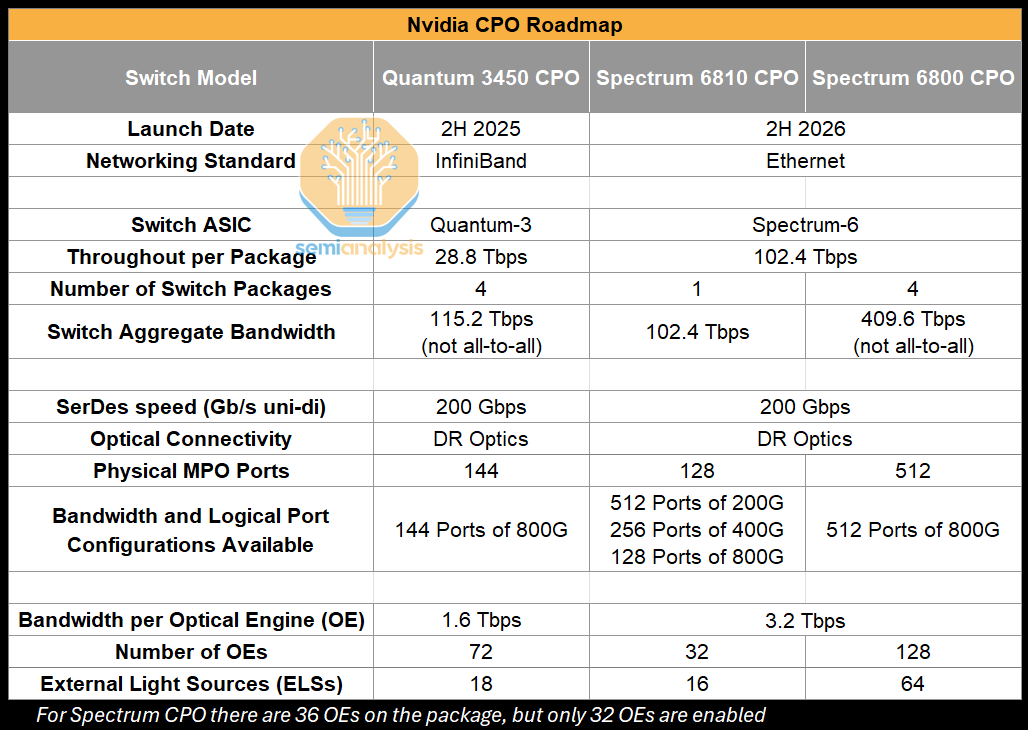
Quantum-X Photonics
The first CPO switch to come to market by 2H 2025 will be the Quantum X800-Q3450. It features 144 Physical MPO ports which enables 144 logical ports of 800G or 72 logical ports of 1.6T, for aggregate bandwidth of 115.2T. Its resemblance to a spaghetti monster has the authors’ stomachs rumbling.

The Quantum X800-Q3450 achieves this high radix and high aggregate bandwidth by using four Quantum-X800 ASIC chips with 28.8 Tbit/s bandwidth each in a multi-plane configuration. In this multi-plane configuration, each physical port is connected to each of the four switch ASICs, allowing any physical port to talk to another one by spraying the data across all four 200G lanes via the four different switch ASICs.
When it comes to the maximum cluster size for a three-layer network, this delivers the same end result as theoretically using four times as many 28.8T switch boxes but with 200G logical port sizes – both allow a maximum cluster size of 746,496 GPUs. This difference is that when using the X800-Q3400 switch, the shuffle happens neatly inside the switch box, while setting up the same network with discrete 28.8T switch boxes will require far more individual fiber cables going to a greater number of destinations.
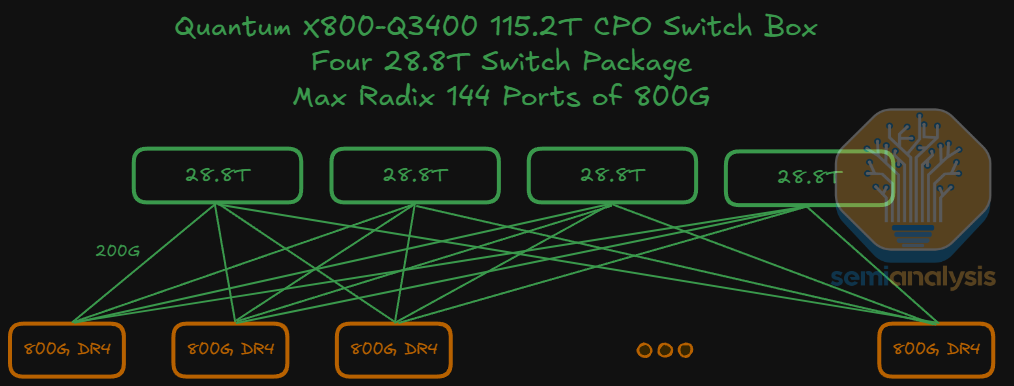
Each ASIC in the Quantum-X800-Q3450 is surrounded by six detachable optical sub-assemblies, with each sub-assembly housing three optical engines. Each optical engine delivers 1.6 Tbit/s of bandwidth, resulting in a total of 18 optical engines per ASIC and an aggregate optical bandwidth of 28.8 Tbit/s per ASIC. Note that these sub-assemblies are detachable, so purists may consider this to be technically “NPO” not strictly “CPO.” While there is a bit of extra signal loss associated with the detachable OE, in effect we believe this will not considerably impact performance.

Each engine operates with 8 electrical and optical channels, driven by 200G PAM4 SerDes on the electrical side and on the optical side, 8 Micro-Ring Modulators (MRMs) use PAM4 modulation to achieve 200G per modulator. This design choice was one of the big takeaways of the announcement: that Nvidia and TSMC can ship 200G MRMs in production. This matches the fastest MZMs today and disproves the industry notion that MRMs are limited to NRZ modulation. It’s quite an impressive engineering achievement by Nvidia to reach this milestone.

Each optical engine integrates a Photonic Integrated Circuit (PIC) built on a mature N65 process node, and an Electronic Integrated Circuit (EIC) fabricated on an advanced N6 node. The PIC leverages the older node because it contains optical components such as modulators, waveguides, and detectors—devices that do not benefit from scaling, and often perform better at larger geometries. In contrast, the EIC includes drivers, TIAs, and control logic, which benefit significantly from higher transistor density and improved power efficiency enabled by advanced nodes. These two dies are then hybrid bonded using TSMC’s COUPE platform, enabling ultra-short, high-bandwidth interconnects between the photonic and electronic domains.

Two copper cold plates sit atop the ASICs in the Quantum-X800-Q3450 as part of a closed-loop liquid cooling system that efficiently dissipates heat from each of the switch ASICs. The black tubing connected to the cold plates circulates coolant fluid, helping to maintain thermal stability. This cooling system is essential in maintaining thermal stability not only for the ASICs but also for the adjacent, temperature-sensitive co-packaged optics.

Spectrum-X Photonics
Spectrum-X Photonics is set for release in the 2nd half of 2026, with two separate switch configurations products to be released, an Ethernet Spectrum-X variant of the X800-Q3450 CPO switch with 102.4T aggregate bandwidth, the Spectrum 6810 offering 102.4T aggregate bandwidth, and its larger cousin the Spectrum 6800 offering 409.6T aggregate bandwidth by using four discrete Spectrum-6 multi-chip modules (MCMs).
The Quantum X800-Q3450 CPO switch utilizes four discrete switch packages connected to the physical in a multi-plane configuration, and each switch package is a monolithic die containing the 28.8T switch ASIC together with required SerDes and other electrical components. In contrast, Spectrum-X Photonics switch silicon is a multi-chip module (MCM) with a much larger reticle size 102.4T switch ASICs at the center, surrounded by eight 224G SerDes I/O chiplets – two on each side.

Each Spectrum-X photonics multi-chip module switch package will have 36 optical engines in a single 102.4T switch package. This package will use Nvidia’s second generation optical engine with 3.2T bandwidth, with each optical engine having 16 optical lanes of 200G each. Note that only 32 optical engines are active, with the additional 4 being there for redundancy purposes in case an OE fails. This is due to the OEs being soldered on the substrate, so they are not easily replaceable.
Each I/O chiplet delivers 12.8T of total unidirectional bandwidth, comprising of 64 SerDes lanes, and interfaces with 4 OEs each. This is what allows the Spectrum-X to deliver far more aggregate bandwidth than Quantum-X Photonics, with much more shoreline and area for the SerDes.

The Spectrum-X 6810 Switch Box uses one unit of the above switch package to deliver 102.4T of aggregate bandwidth. The larger Spectrum-X 6800 Switch Box SKU is a high-density chassis with an aggregate bandwidth of 409.6T achieved by utilizing four of the above Spectrum-X switch packages which are also connected to the external physical ports in a multi-plane configuration.

Much like the four ASIC 115.2T Quantum X800-Q3450, the Spectrum-X 6800 uses an internal breakout to physically connect each port to all four ASICs.

The Broadcom CPO Switch Portfolio
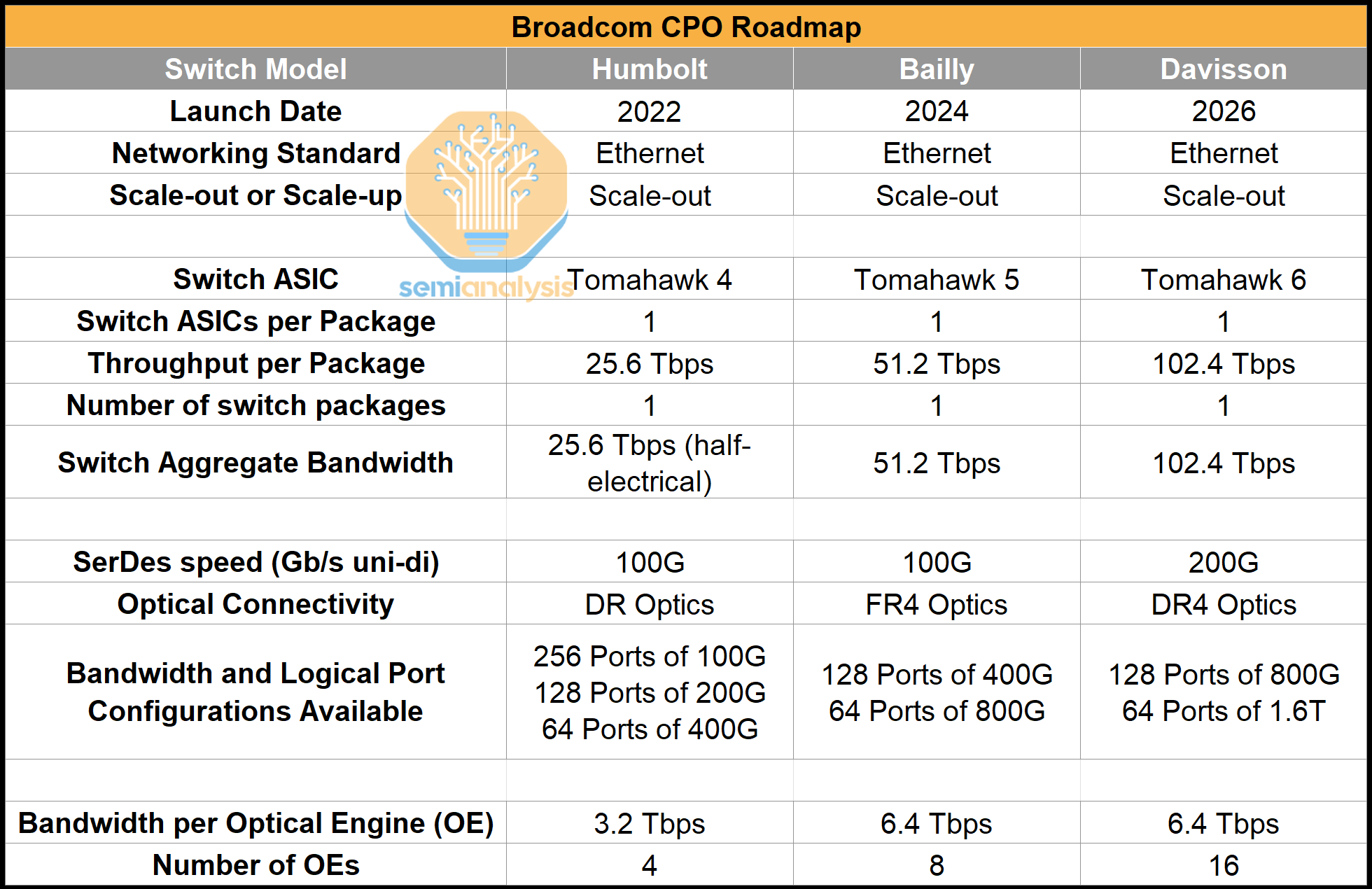
Broadcom was among the first companies to offer real CPO-enabled systems and as such is considered a leader in CPO. Broadcom’s first‐generation CPO device, known as Humboldt, served largely as proof of concept. Dubbed “TH4‐Humboldt”, it is a 25.6Tbit/s Ethernet switch that equally divides its total capacity between traditional electrical connections and CPO. Of that, 12.8Tbit/s is handled by four 3.2 Tbit/s optical engines, each delivering 32 lanes of 100 Gbit/s. This hybrid design of copper and optics has some prominent uses cases. In one scenario, top‐of‐rack (ToR) switches rely on electrical interfaces for short‐distance copper connections to nearby servers, while their optical ports uplink to the next tier of switching. In another scenario, at the aggregation layer, electrical ports interconnect the various switches within a rack, and optical links extend to switching tiers above or below that layer.

In this design, Broadcom employed a silicon germanium (SiGe) EIC but switched to CMOS in the next generation (i.e. Bailly).

Broadcom’s second‐generation CPO device, Bailly, is a 51.2 Tbit/s Ethernet switch that—unlike its half‐optical predecessor—relies entirely on optical I/O. It consists of eight 6.4Tbit/s optical engines, each delivering 64 lanes of 100 Gbit/s. Another notable change is that instead of using a SiGe EIC, it now uses a 7nm CMOS EIC. Moving to a CMOS EIC allowed for a more complex, integrated design with additional control logic, which in turn enabled higher lane counts—scaling from the previous 32 lanes up to 64 lanes in the new optical engine.

Another notable shift from the first to the second generation is the transition from a TSV process to fan‐out wafer‐level packaging (FOWLP). In this design, the EIC leverages through‐mold vias (TMVs) to route signals up to the PIC while copper pillar bumps connect it to the substrate. A major reason for adopting FOWLP is that it’s already proven in the mobile handset market and widely supported by OSATs, giving the technology greater scalability. ASE/SPIL was the OSAT partner for this FOWLP process.
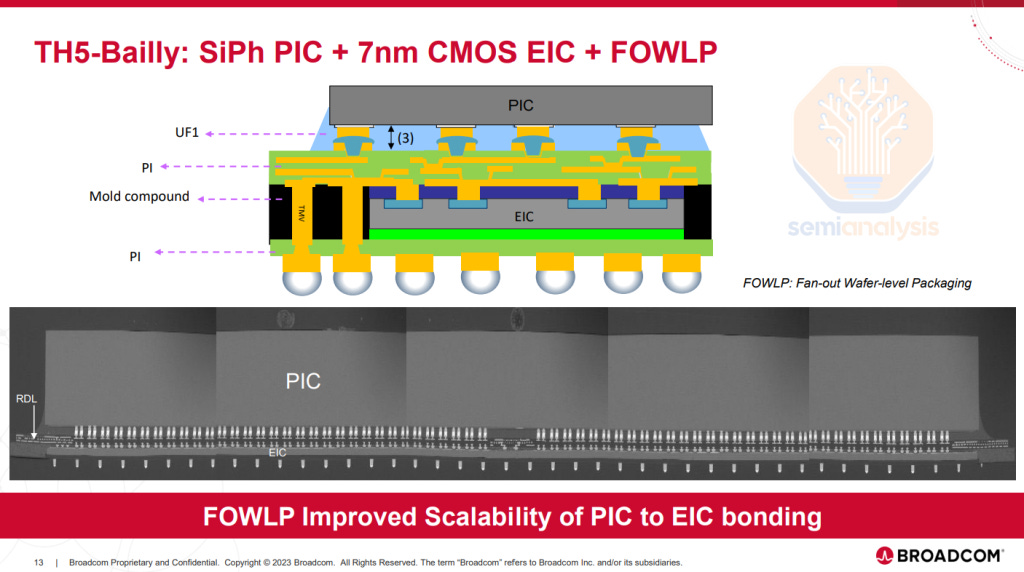
Broadcom revealed at Hot Chips 2024 an experimental design that integrates a 6.4 Tbit/s optical engine onto a package with one logic die, two HBM stacks, and a SerDes tile. They proposed using a fan‐out approach that places HBM on the east and west edges of the substrate, allowing room for two optical engines on the same package. By moving from CoWoS‐S to CoWoS‐L, you move to substrates that exceed 100 mm on an edge. As such, they will be able to accommodate up to four optical engines and achieve 51.2 Tbit/s of bandwidth.
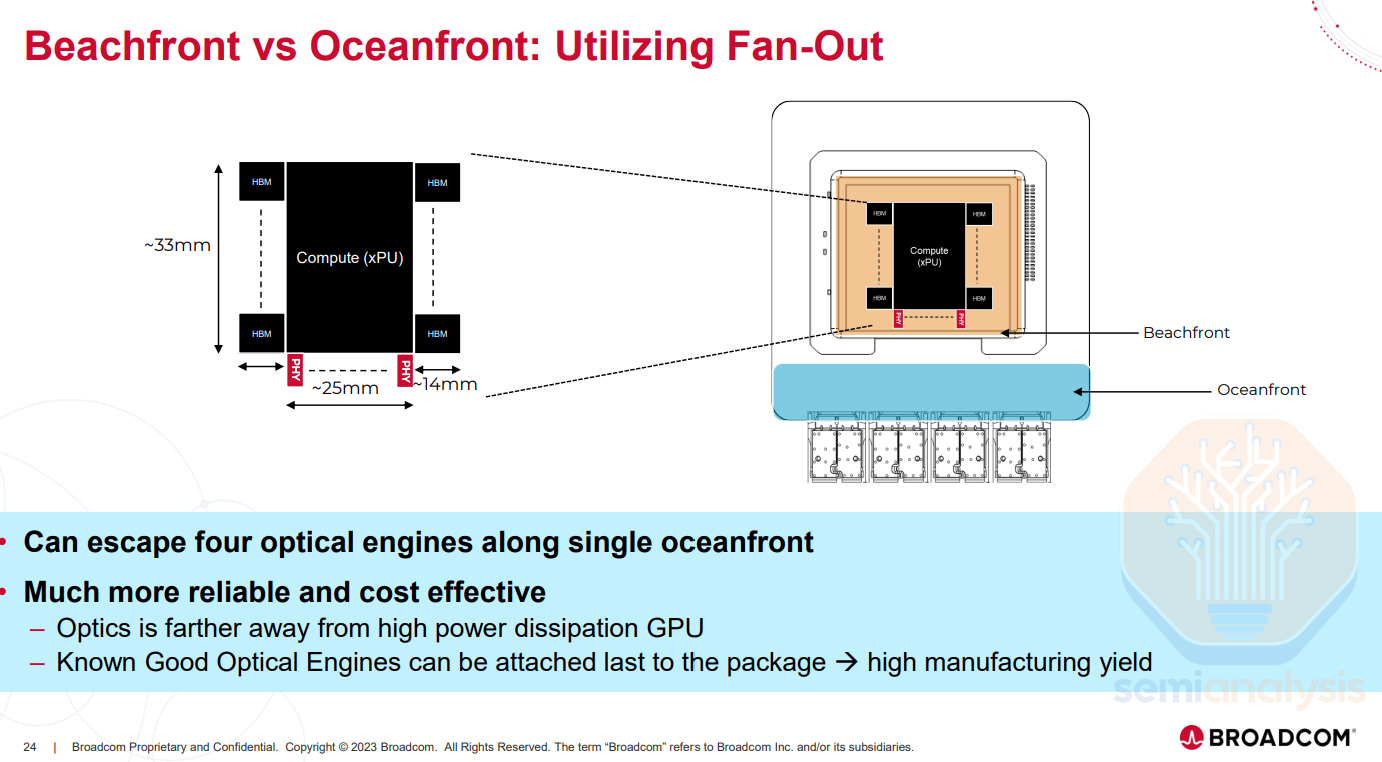
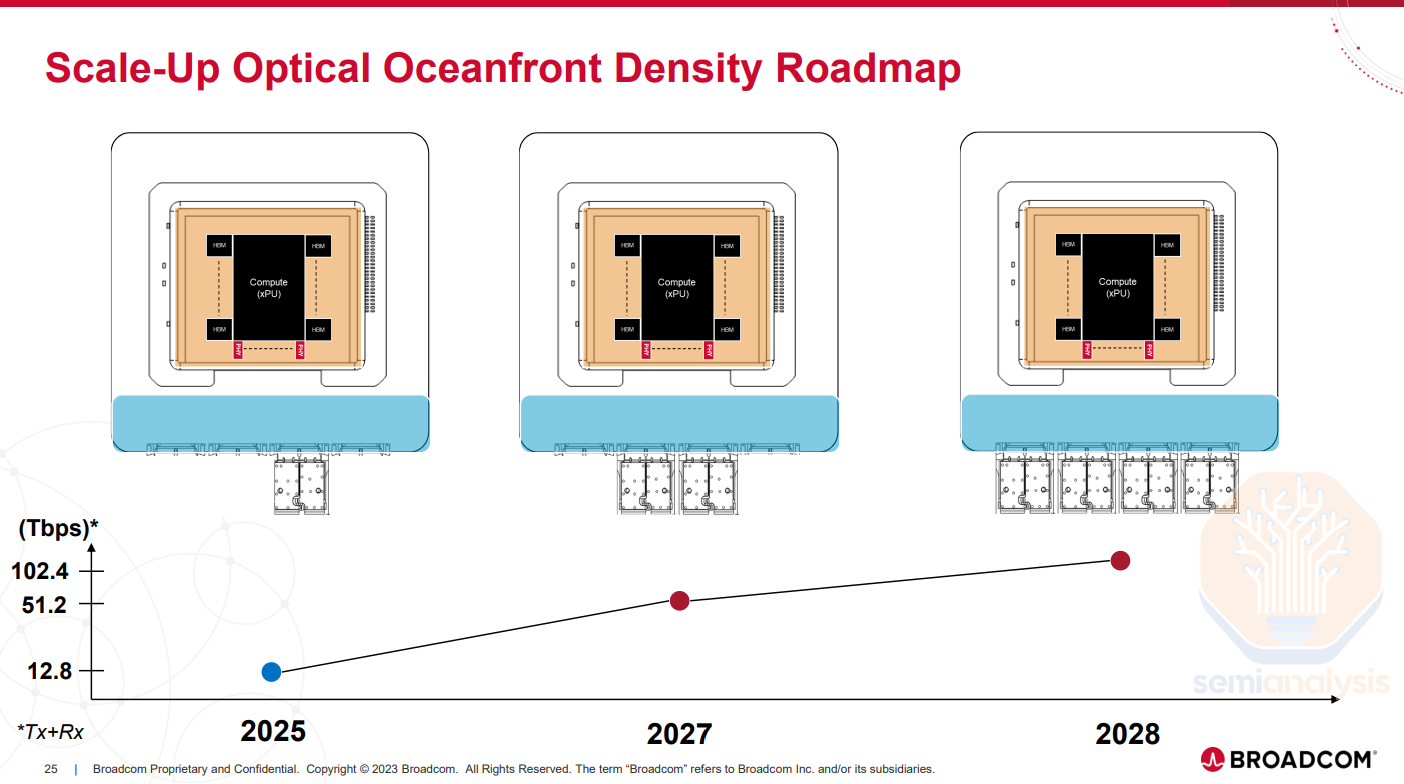
This year, Broadcom is launching its Tomahawk 6-based Davisson CPO switches, which incorporates sixteen 6.4T OEs. The switch ASIC is fabricated using TSMC’s N3 process node and delivers 102.4 Tbit/s of bandwidth per package. Broadcom uses contract manufacturers (CMs) such as Micas and Celestica for box assembly. Additionally, NTT Corp (Japan) is reportedly purchasing Broadcom’s TH6 bare dies and building its own CPO systems using proprietary OEs and optical solutions not sourced from Broadcom. This approach expands the potential business opportunities for TH6-based CPO systems and encourages a more open vendor ecosystem.

As we see greater value for CPO in scale-up fabrics, we believe the first mass-produced CPO system delivered by Broadcom will be in their customers’ AI ASICs. Broadcom’s experience with CPO makes them an attractive design partner for customers who see CPO on their ASIC roadmap in the medium term. We understand this was a key factor that led OpenAI to choose Broadcom. Interestingly, Google, Broadcom’s largest ASIC customer, is the hyperscaler that is most hesitant to deploy CPO in their datacenters. Google’s infrastructure philosophy places more emphasis on reliability over absolute performance, and CPO’s reliability is a deal breaker for them. We do not expect Google to adopt CPO any time soon.
Future generations of Broadcom CPO endpoints are also moving to the TSMC’s COUPE platform – a clear signal that the features COUPE offers provides a path to bandwidth scaling. This will not only be a change in how they package the OE, but also Broadcom’s previous generations have used edge coupling as well as MZMs – both of these choices were simpler from an implementation standpoint, but also less scalable as we discussed above. COUPE is biased towards grating coupling and MRMs which is a dramatic change from their existing approach. Despite Broadcom having the most CPO experience, this change in technical approach means that Broadcom must essentially start fresh on some aspects of their technology. The question is how much help TSMC can provide to make designing easier for Broadcom.
Intel’s CPO Roadmap

Intel unveiled its CPO roadmap in this year’s Intel Foundry Direct Connect and outlined a 4-stage development roadmap
2023: In 2023, Intel outlined a concept for advanced electrical package-to-package I/O connectivity as a precursor to optical integration. This milestone focused on enabling high-bandwidth, short-reach electrical links directly between chip packages (bypassing traditional PCB traces) to support multi-die systems. It set the stage for integrating photonics by establishing a package-level I/O infrastructure that could later be augmented with optical channels.
2024: Intel demonstrated its first-generation CPO solution featuring direct fiber attach. In this approach, optical engine chiplets are coupled directly to optical fibers without any external connector, simplifying the link. At OFC 2024, Intel showcased a 4 Tbit/s (bi-directional) Optical Compute Interconnect (OCI) chiplet co-packaged with a concept Xeon CPU, running error-free data over a single-mode fiber link and delivering 64 lanes at 32 Gbit/s each. The optical interface achieved great efficiency at ~5 pJ/bit.
2025: Intel’s second-generation CPO solution incorporates a detachable optical package connector instead of permanent fiber pigtails. Intel engineers developed a glass optical bridge that slots into the side of the package, containing embedded 3D waveguides and mechanical alignment features to interface the on-package photonics with standard fiber connectors. This optical package connector design enables modular assembly, marking a transition toward a more connectorized, serviceable form factor.
2027: Intel is targeting a breakthrough in 3D-integrated photonics: vertically stacking photonic components using vertical expanded beam coupling. In this envisioned 3rd-generation design, optical I/O would be routed vertically between die layers (for example, between a photonic interposer layer and logic die) via short free-space or in-glass optical paths. By coupling light vertically through the package, Intel aims to further reduce electrical bottlenecks and enable ultra-high bandwidth chiplet fabrics in the latter part of the decade.
MediaTek CPO plans
MediaTek, as a custom ASIC design house, is working to integrate CPO capabilities into its design platform. They aim to offer PIC/EIC designs that can work seamless with their custom accelerators. They think that at 200G-per-lane generation, NPC (Near-Packaged Copper) can be an effective solution with fiber pitches >900 µm; as data rates rise to the 200-300G range, CPC with denser pitches >400 µm may become preferrable. However, once speeds reach 400G-per-lane or higher, moving toward CPO architecture – with even denser fiber pitches at ~130 µm and more compact interconnect IPs – will likely be necessary.
CPO Focused Companies
While Nvidia, Broadcom and Marvell are forging ahead on their own path, creating their own proprietary solutions, several CPO focused companies are exploring yet another set of approaches. The question for these companies is how they will compete with major switch silicon and GPU/ASIC providers—particularly since most of these incumbents have already announced or demonstrated proprietary solutions. AMD remains the exception: it has not showcased any offerings, though it is known to be developing photonic IP internally.
For OE chiplet providers such as Ayar Labs, Lightmatter, Celestial AI, Nubis, and Ranovus, the challenge is to overtake the established players and deliver solutions compelling enough to be integrated. Ayar Labs and Celestial AI supply fully “bookended” systems, meaning customers must adopt their complete end-to-end solutions. Nubis, by contrast, is focusing on more open, standards-based solutions, aiming to streamline implementation and make adoption simpler. Ranovus is another CPO supplier that also provides interoperable systems. On the other hand, there are more radical approaches that form an important part of some companies’ product roadmaps – namely the optical interposers from Lightmatter and photonic bridge from Celestial AI. These solutions require a fundamental rethink of both package and host silicon design to unlock their full potential. However, with these approaches comes with elevated costs and significant uncertainty, especially regarding seamless integration with CMOS-based silicon and high-volume manufacturing.
Let’s start our tour through each of these companies’ architecture and go to market plans.
Ayar Labs
Ayar Labs’ product is their TeraPHY optical engine chiplet, which can be packaged into XPU, switch ASIC, or memory. The first generation of TeraPHY can deliver 2Tbit/s of uni-directional bandwidth while using just 10W of power. The second gen TeraPHY provides 4 Tbit/s of unidirectional bandwidth. It is the world’s first UCIe optical retimer chiplet, performing E/O conversion within the chiplet for transmitting the host signal optically onward. The choice of UCIe should make it attractive for customers as it has a standardized interface that can be easily implemented into their host chips.

Ayar Labs manufactured the first two generations of TeraPHY on GlobalFoundries’ 45 nm process as a monolithic solution that integrates both electronics and silicon photonics, while the third generation of TeraPHY instead adopts TSMC COUPE. This close integration of ring modulators, waveguides, and control circuitry helps reduce electrical losses. However, the mature monolithic nodes used in the first two generations constrain the performance of the EIC and is why the first few generations of TeraPHY used a low modulation rate.

In the 4 Tbit/s unidirectional second generation code-named “Eagle”, TeraPHY integrates eight 512 Gbit/s I/O ports, each powered by a 32 Gbit/s NRZ x 16-wavelength architecture, modulated by MRM. The external laser source, called SuperNova, is supplied by Swedish company Sivers. The laser combines 16 lambda (“colors”) into one fiber using DWDM. Each port then uses one single-mode fiber pair for transmit (Tx) and receive (Rx), meaning each 4T chiplet connects to a total of 24 fibers – 16 for Rx/Tx and 8 for laser inputs. The company employs edge coupling (EC) in its packaging process, though it is also capable of supporting grating coupling (GC).
For scaling bandwidth per chiplet, the company noted that fiber density (currently 24 per chiplet) could realistically double over the next few years as connector technology advances. Additionally, bandwidth per port/fiber could double as well by increasing the per-wavelength data rate, contributing to an overall 4x bandwidth expansion in the near future roadmap.
The SuperNova laser is MSA (Multi-Source Agreement) compliant, allowing it to interoperate with other CW-WDM standard optical components.

Ayar’s third generation of TeraPHY pivots to using TSMC COUPE and can deliver more than 3x the bandwidth of the second generation at 13.5 Tbit/s uni-directional per each optical engine, with 8 optical engines providing the ~108Tbit/s of total package scale-up bandwidth for the XPU solution featured in the Ayar Labs – Alchip collaboration below. This ~13.5+Tbit/s is achieved using ~200Gbit/s of bandwidth per lambda using PAM4 Modulation.
Though Ayar Labs has not disclosed the exact port architecture (i.e. the number of DWDM wavelengths, fibers per FAU, etc), its use of bi-directional optical links means that it will need at most ~64 fiber strands for Tx and Rx, and at most dozens more to connect to the external laser source. However – Ayar’s strategy has always been focused on WDM, meaning that that total fiber count per FAU could be as low as 32 in total. Like the first two generations, the third generation of TeraPHY continues to use Microring Modulators to enable optical chiplets to remain small while enabling CWDM or DWDM as a vector for future bandwidth scaling.

Ayar Labs has also partnered with Alchip and GUC to enable integration of their chiplet into Alchip and GUC’s XPU solutions. The above example illustrates an XPU with two reticle size compute dies and 8 TeraPHY optical engines, which could enable up to 108 Tbit/s uni-directional of bandwidth.
At Hot Chips 2025, Ayar Labs shared results a slow thermal cycling link test – showing over four hours of thermal cycling at a rate of about 5C/min, demonstrating strong link BER throughout.
However, studying the MRM’s resilience against rapid changes in temperature is just as important as demonstrating the stability of the link over a wide temperature range over a long period of time. In the same Hot Chips talk, Ayar explained how they opted to emulate a fast temperature ramp by sweeping laser wavelength in lieu of having an on-package ASIC that can actually perform the 0 to 500W step. Control circuits detect whether the ring resonance drifts – this can be caused by either the incoming laser changing wavelength or by a change in ring temperature, so they sweep the laser wavelength at rate that corresponds to an equivalent change in temperature. For example a 20nm/s sweep would simulate a 64C change over 0.2 seconds, amounting to 320 C/s. This study showed no bit errors for up to 800C/s of temperature change.


Ayar Labs has a wide array of strategic backers including GlobalFoundries, Intel Capital, Nvidia, AMD, TSMC, Lockheed Martin, Applied Materials, and Downing.
Nubis
Nubis was recently acquired by Ciena in October 2025. Similar to Ayar, Nubis offers optical engine chiplets to integrate with customer host silicon, but with an emphasis on single wavelength connections. Nubis has focused on interoperability – both protocol and mechanical (I.e., pluggable) – which has determined their technology choices. Nubis also has a broader mission to address the I/O wall in general, and their solutions encompass both optics and copper.
Their existing optical engine product is the Vesta 100 1.6T NPX optical engine. It is a socketable module that offers 1.6T of bi-directional bandwidth with 16 lanes of 100G. The module has a footprint of 6x7mm. Nubis, unlike other companies, are using MZMs in large part due to the interoperability, reliability, and maturity of the modulator. The other major design choice is that the Nubis is designed to be compatible with IEEE/OIF standards-compliant electrical interfaces as they believe most ASIC developers will continue to utilize these technologies.
A key point of differentiation for Nubis is how they couple fiber. Nubis couples the surface of the PIC, and specifically they use a thin piece of glass to help route and align the fibers. Unlike edge coupling where optical fibers are connected to the chip’s edge, Nubis’s 2D fiber array approach involves connecting optical fibers from the top of the silicon photonics die.
Looking at the diagram below: the PIC (green at bottom) contains modulators, photo detectors and waveguides with EICs mounted on top. The red poles are optical fibers, while the block that contains the optical fibers is a glass block (FAU) which is used as a fiber holder. The FAU has laser-drilled holes at the top of the block to ensure exact fiber positioning. By employing a 2D fiber array, they are able to connect 36 optical fibers (16 for transmit, 16 for receive, 4 for lasers) to the PIC and avoid the need for WDM to get more lambdas over fewer fibers. This makes the Nubis FAU one of the densest currently shipping.
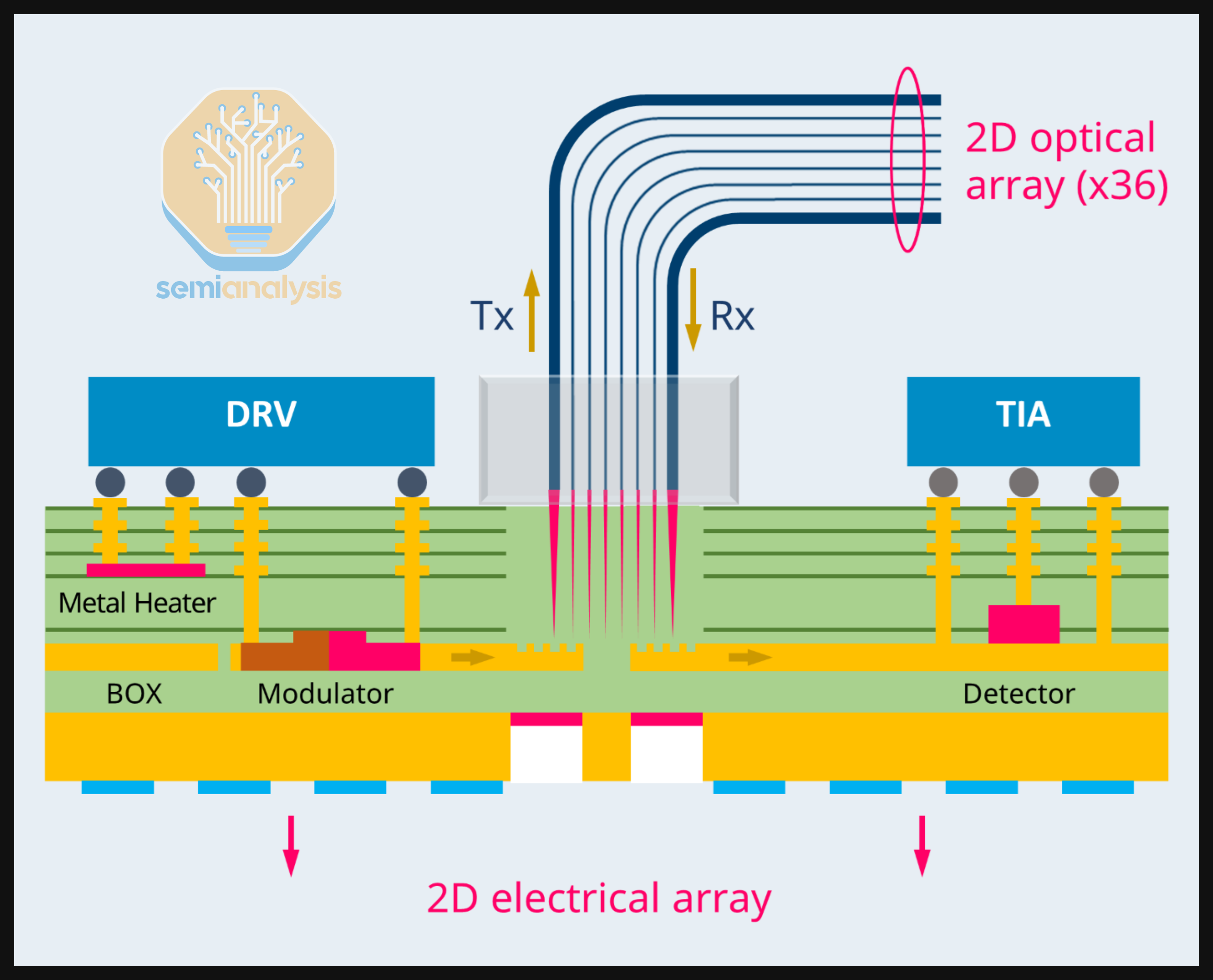
While 2D fiber arrays are on the roadmap for companies like TSMC and a key advantage to vertical coupling, no one apart from Nubis is shipping this yet which distinguishes them, though others plan to move to 2D arrays later on.
The optical fibers go up and they bend sideways by employing special optical fibers, termed FlexBeamGuidE, developed by Sumitomo Electric that is able to exhibit high reliability and low loss whilst being bent at a 90-degree angle.
Another benefit of using a 2D array rather than edge coupling is that you are less physically limited by the number of fibers that can be connected. As seen in the diagram below, using Nubis’s 2D Fiber array structure, multiple rows of optical engines can be placed around the ASIC, increasing bandwidth density provided the package permits that.
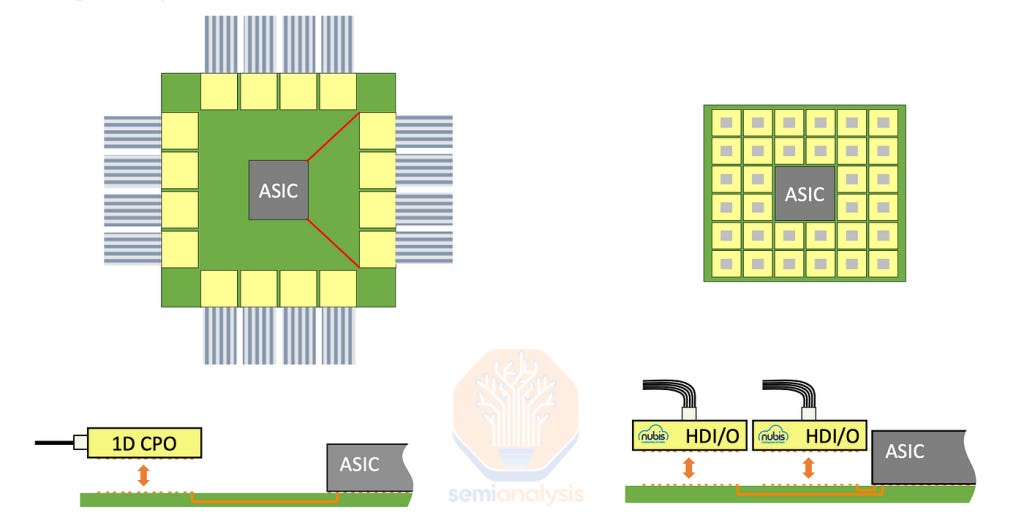
In April 2025, Nubis announced the availability of its next generation PIC, a 16 x 200G per lane silicon photonics IC with unidirectional beachfront density of 0.5Tbps/mm (which matches electrical host interface densities). In addition, Nubis announced a partnership with Samtec whereby Nubis would sample a 32x 200G (6.4T) optical module snap-in compatible with Samtec Si-Fly HD Co-Packaged copper connector. Compared to alternative CPO approaches, this approach enables a common copper and optical footprint; this also over time could create an open pluggable ecosystem for deploying CPO.
Lastly, in copper, Nubis has also announced and demonstrated at OFC their linear redriver chip, Nitro, for active copper cables (ACC’s) that can extend the reach of 200G over copper to several meters. This is done in partnership with Amphenol who will build ACC’s based on the Nitro linear redriver.
Celestial AI
Celestial AI is an IP, products, and systems company specializing in optical interconnect solutions for AI scale-up networks. The main goal of the company’s technology is to build photonic devices (modulators, PDs, waveguides, etc.) into interposers coupled with an interface with the outside world (GC with an FAU). The diagram below is a good representation of Celestial AI’s suite of photonics-based interconnect solutions which Celestial AI calls their “Photonic FabricTM” (PF).


Photonic FabricTM (PF) Chiplets are TSMC 5nm chiplets incorporating die-to-die interfaces like UCIe and MAX PHY, enabling XPU-to-XPU, XPU-to-Switch, and XPU-to-Memory connectivity. They can be co-packaged by customers alongside their XPUs, delivering higher bandwidth density and lower power consumption than CPO products based on electrical SerDes interfaces. Celestial AI develops these chiplets on a per-customer basis to accommodate specific D2D interfaces and protocols. The first generation of PF Chiplet supports a bandwidth of 16 Tbit/s, while the second generation will deliver 64 Tbit/s.
Optical chiplets offer a strong power advantage compared to traditional copper traces. Traditional copper cables with linear SerDes at 224G require ~5 pJ/bit. With two ends required, the total power consumption is ~10 pJ/bit. Celestial AI’s solution requires just ~2.5 pj/bit for the entire electrical-optical-electrical link (plus ~0.7 pJ/bit for the external laser).
Next, the Photonic FabricTM Optical Multichip Interconnect BridgeTM (OMIBTM) is essentially a CoWoS-L style or EMIB style packaging solution. It adds photonics directly onto the embedded bridge in the interposer so that the bridge can move data directly to point of consumption. It offers higher overall chip bandwidth than PF Chiplets, as it is not limited by beachfront constraints.
In traditional interposers or substrates with metal interconnects, placing I/O at the center of the chip is impractical because it would create excessive routing complexity and severe crosstalk issues due to high-density signal congestion. However, with the OMIB optical interposer, Celestial AI is able to place the interposer right beneath the ASIC, bypassing shoreline limitations and enabling faster, more efficient data movement with minimal crosstalk.
Optical interposers allow I/O to be placed anywhere on the chip, as optical waveguides experience negligible signal degradation over distance, removing the traditional constraint of shoreline as we know it. They also eliminate crosstalk since light signals in different waveguides do not interfere like electrical signals in densely packed copper traces as they are highly confined within the waveguide core with only a small evanescent field outside in the cladding. This ground-up rearchitecting of I/O design and placement fully takes advantage of the potential that optics provides.

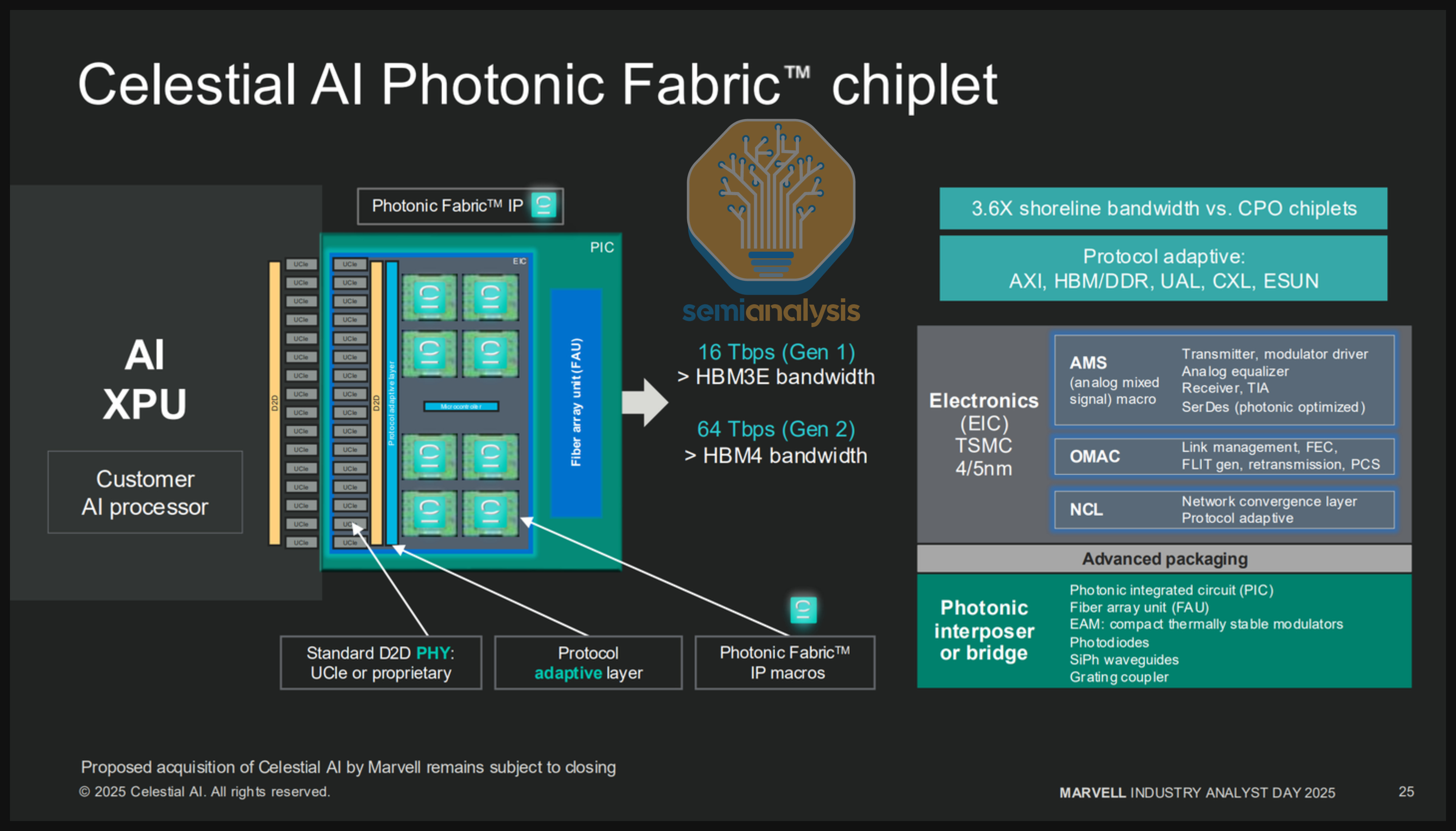
The idea of an optical interposer or channeling optical signals through an advanced package has a few similarities to Lightmatter’s solution in that they both route optical signals below the logic chips thereby avoiding shoreline constraints, but there are a few key differences. Celestial AI adopts a photonic bridge that is akin to a silicon bridge (think like the CoWoS-L silicon bridge) whereas Lightmatter uses a large multi-reticle photonic interposer that sits below a number of individual chips. Lightmatter’s concept is more ambitious in scope – aiming for 4,000 mm2 interposer sizes in its M1000 3D Photonic Superchip while also aiming to support optical circuit switching within the interposer and a very high 114 Tbit/s of total aggregate bandwidth.
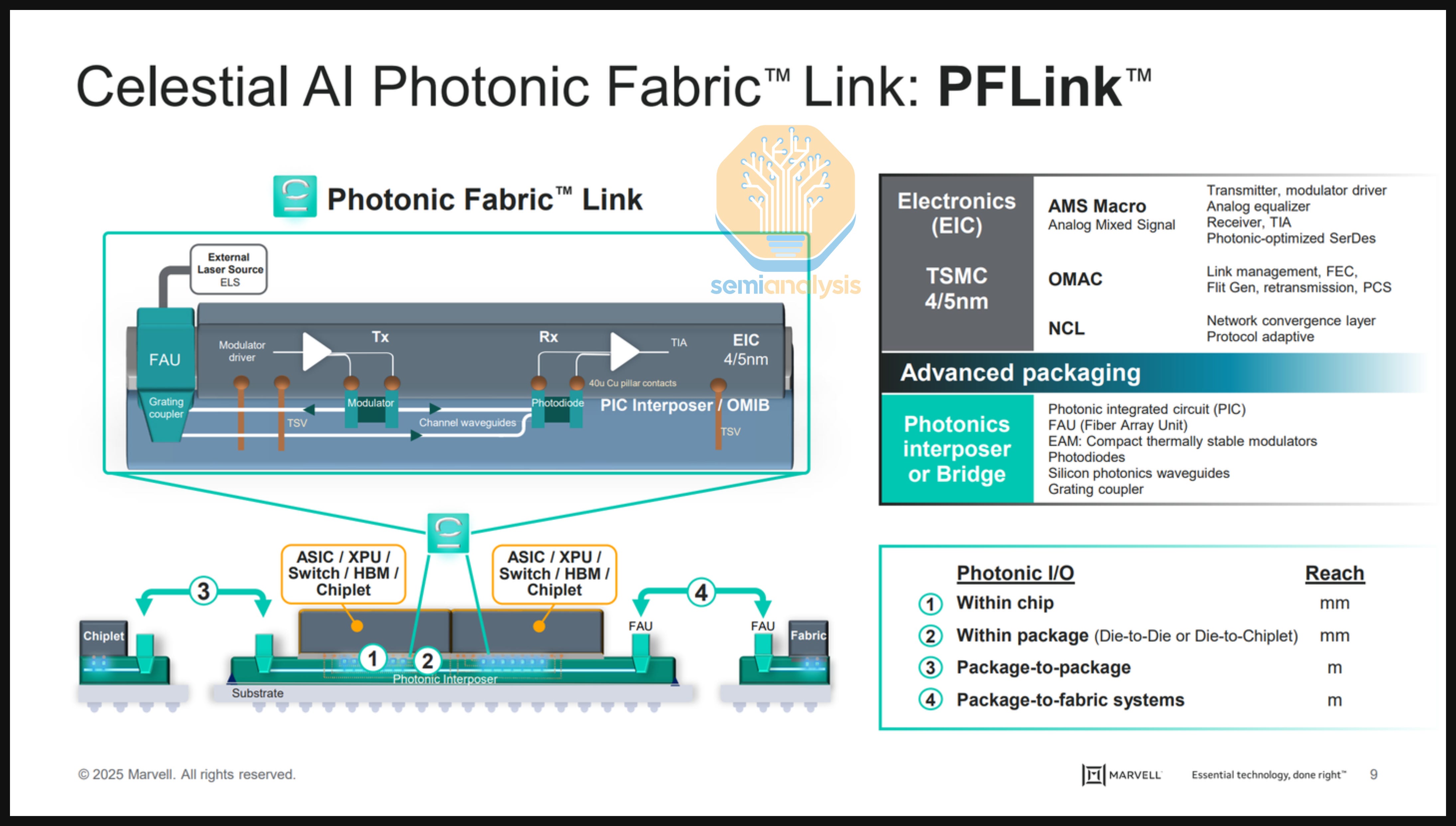
Lastly, Celestial AI offers the Photonic FabricTM Memory Appliance (PFMA), a high-bandwidth, low-latency scale-up fabric with in-network memory built on TSMC 5nm with 115.2T total bandwidth that can connect 16 ASICs at 7.2T scale-up bandwidth per each ASIC. Notably, PFMA is the world’s first silicon device with on-die optical I/O located in the center of the chip, leaving scarce perimeter physical I/O’s for memory controllers. This positions the PFMA as a “warm” memory tier between host CPU memory and storage for KVCache offloading.
A key differentiator of Celestial AI’s technology is its use of an Electro Absorption Modulator (EAM). Part 3 of this article described in more detail how EAMs work and discusses the advantages and trade-offs when it comes to EAM. We repeat the bulk of this discussion here as understanding the pros and cons of EAMs is key to understanding Celestial’s go to market.
EAMs have several advantages compared to MRMs and MZIs:
Clearly – both EAMs and MRMs have control logic and heaters that act to stabilize both against variations in temperatures, but EAMs have fundamentally less sensitivity to temperature. Compared to MRMs, EAMs have much better thermal stability above 50° C while MRMs are very sensitive to temperature. A typical stability of 70-90 pm/C for MRMs mean that a 2° C variation shifts resonance by 0.14nm, well beyond the 0.1nm resonance shift at which MRM performance collapses. In contrast, EAMs can tolerate an instantaneous temperature shift of up to 35° C. This tolerance is important in particular for Celestial AI’s approach as their EAM modulator resides within an interposer beneath a high-XPU power compute engine that dissipates hundreds of watts of power. EAMs can also tolerate high ambient temperature ranges of around 80° C which may be applicable for chiplet applications which sit next to the XPU and not beneath it.
Compared to MZIs, EAMs are much smaller in size and consume less power as the relatively large size of MZIs requires a high voltage swing, amplifying the SerDes to achieve a swing of 0-5V. Mach Zender Modulators (MZMs) are on the order of ~12,000µm2, GeSi EAMs at around 250µm2 (5x50µm) with MRMs at between 25µm2 and 225µm2 (5-15µm2 in diameter). MZIs also require more power usage for the heaters needed to keep such a large device at the desired bias.
On the other hand, there are a few drawbacks in using GeSi EAMs for CPO:
Physical modulator structures built on Silicon or Silicon Nitride such as MRMs and MZIs have been perceived to have far greater endurance and reliability than GeSi based devices. Indeed, many worry about the reliability of GeSi based devices given the difficulty of working with and integrating Germanium-based devices, but Celestial argues that GeSi based EAMs, which are essentially the reverse of a Photodetector, are a known quantity when it comes to reliability given the ubiquity of photodetectors in transceivers today.
GeSi modulators’ band edge is naturally in the C-band (i.e. 1530nm-1565nm). Designing quantum wells to shift this to the O-band (i.e. 1260-1360nm) is a very difficult engineering problem. This means that GeSi based EAMs will likely form part of a book-ended CPO system and cannot easily be used to participate in an open chiplet-based ecosystem.
Building out a laser ecosystem around C-band laser sources could have diseconomies of scale when compared to using the well-developed ecosystem around O-band CW laser sources. Most datacom lasers are built for the O-band but Celestial points out that there are considerable volumes of 1577nm XGS-PON lasers manufactured. These are typically used for consumer fiber to the home and business connectivity applications.
A SiGe EAM has an insertion loss of around 4-5dB vs 3-5 dB for both MRMs and MZIs. While MRMs can be used to directly multiplex different wavelengths, EAMs require a separate multiplexer to implement CWDM or DWDM, adding slightly to the potential loss budget.
Overall, Celestial AI has been working to innovate its custom links – they don’t rely on any gearbox components, offering better latency and power efficiency, and are adaptive to different types of protocols. As mentioned earlier, Celestial AI is the only major player that is mainly using EAMs for modulation. One key implication is that they will also have some work ahead of them integrating their EAM design into a foundry whereas other CPO companies can lean on TSMC COUPE where MRMs and related heaters are already part of the PDK.
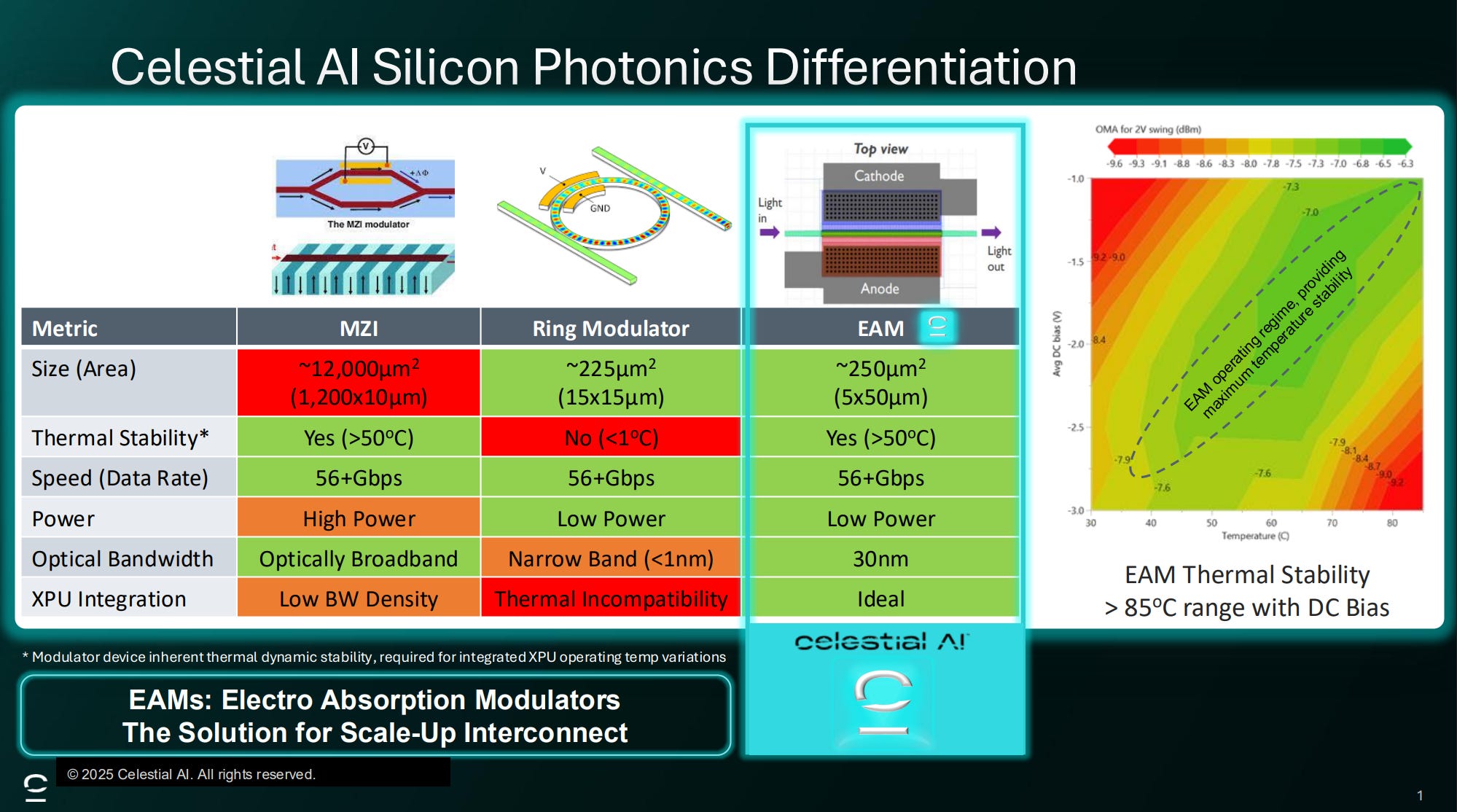
In the immediate term, Celestial AI is committing to an ambitious timeline for the release of the chiplet. Marvell announced in the transaction summary that their estimated revenue run rate from Celestial at the end of January 2028 (the end of Marvell’s Fiscal Year 2028 – i.e. F1/28) is expected to reach $500 million. At the Barclay’s Global Technology Conference, they further added that this run rate is expected to double to $1B by the end of Calendar Year 2028 (with most of CY28 falling into Marvell’s FY ending Jan 2029 – i.e. F1/29), implying a 2-year period from now to the end of 2027 for the product to achieve commercial viability.
As part of the deal terms, an additional $2.25B of payout to Celestial AI’s equity holders is contingent upon the company achieving a cumulative revenue of at least $2.0 billion by January 2029 (the end of Marvell’s Fiscal Year 2029 – i.e. F1/29). This first milestone towards that full payout is achieving $500M of cumulative revenue by January 2029 for one third of the payout. The $1B revenue run rate expected exiting F1/29 is half of the earn-out amount – implying that Celestial will need to add additional customers to the order book to achieve the $2B earn-out target.

In connection with the Celestial AI acquisition, Marvell filed an 8-K report on December 2, 2025 issuing Amazon warrants with an exercise price of $87.0029 through December 31, 2030. These warrants vest “based on Amazon’s purchases of Photonic Fabric products, indirectly or directly, through December 31, 2030”, strongly suggesting that AWS’s Trainium will be the target product as this starts to ramp in late 2027. At Marvell’s Industry Analyst Day, Celestial AI discussed how a major hyperscaler selected them for optical interconnectivity for advanced AI systems that will move into volume production in that hyperscaler’s next generation processor. This, together with the earn-out timing and product revenue guidance in the transaction summary suggests that Celestial AI is targeting to deploy its solution within Trainium 4.

Let’s conclude our discussion on Celestial AI by elaborating further on its first scale-up solutions to come to market which will be oriented around its 16Tbit/s Photonics Link that will be connected to a chiplet. An FAU is connected to the channel waveguides via the grating coupler. A Scale-up switch ASIC – possibly Marvell’s 115.2T scale-up ASIC – will be optically connected to an XPU via the Photonics link and the PF chiplet. Though Celestial expects most of its initial go-to-market revenue to be contributed by its chiplet, it positions itself as a systems company and has pitched several optical-based memory expansion solutions that can come to market after this first scale-up networking solution.
Using optics to increase the scale-up world size through multiple switch layers is not a new concept, though of course it has yet to come close to being productized. Such a concept could have topologies that mirror the NVL576 concept of the GB200, where there are two switch layers and each switch layer is connected to the other via OSFP transceiver modules and optical fiber. Celestial AI’s approach of using multiple switch layers is similar but skips the use of actual transceivers.
The biggest difference from the NVL576 concept, however, is that the scale-up ASIC can double as both a router and a memory endpoint, whereas an NVSwitch only routes high-bandwidth links between GPUs. This is an important distinction because Celestial AI’s pitch is that its scale-up solution is able to sidestep the silicon beachfront constraint that limits the number of HBM stacks one can attach to the XPU.
To achieve this, the HBM stack attached to the XPU is replaced with a chiplet that connects to the Photonic Fabric, which is a shared HBM pool. The shared HBM pool is a Photonic Fabric Appliance (PFA) a 2U-rack-mountable system made up of 16 Photonic Fabric ASICs consisting of one port each.
Each ASIC is a 2.5 layer package integrated with two 36GB HBM3E memory and eight external DDR5.

The optical I/O (Photonic Fabric IP) is mounted in the middle of the ASIC, rather than at the beachfront, which frees up the shoreline for other use cases.

Zooming out, each PFA module is a 16-radix switch that can support up to 16 XPUs. Rather than have each XPU fan-out to all 16 ports, all-to-all connectivity occurs inside the switch box, where the Fiber Attach Unit (FAU) connected to each Switch ASIC fans out to each of the 16 switch I/Os. As such, every XPU only has one Fiber link to one switch port outside of the box.

By placing memory external to the XPU and within a shared switching interface, data is aggregated and subsequently accessed from the shared memory pool by every XPU in an all-reduce communication collective.
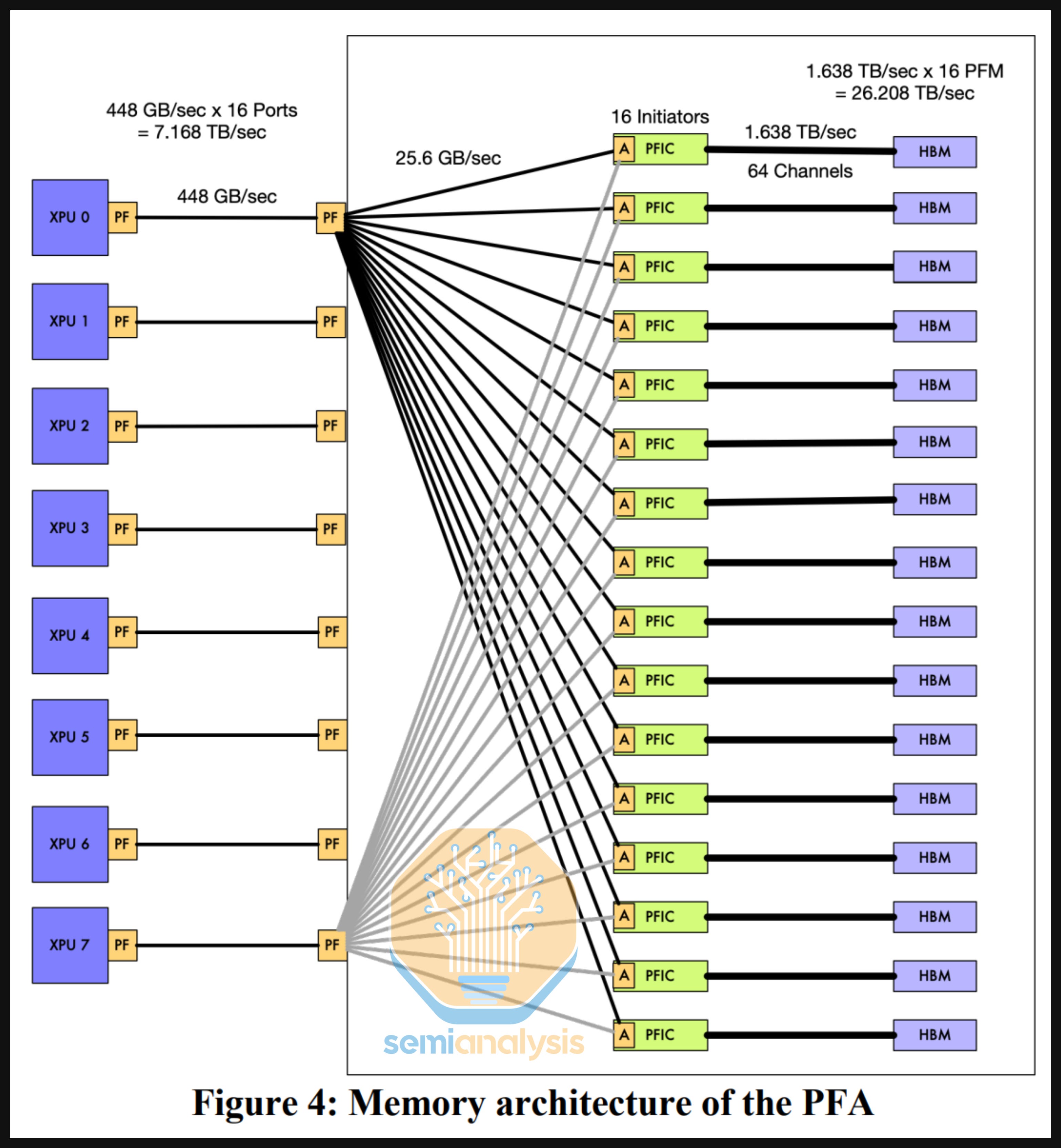
Lightmatter
Lightmatter is well known for its Optical Interposer product, the Passage™ M1000 3D Photonic Superchip, but is also introducing a number of solutions to cater to the various phases of the CPO roadmap, with a number of chiplets being taped out at TSMC.
The first solution to come to market will be optical engines for Near Packaged Optics (NPO) in 2026/2027. In an NPO solution, the Optical Engine would be soldered to the baseboard, with copper connecting LR SerDes on the XPU to the Optical Engine. Lightmatter’s optical engine will support up to 3 FAUs with 40 fiber strands per FAU, for a total of 120 fiber strands. The NPO strategy is premised on the idea that Hyperscalers’ first step in adopting CPO will be to first gain operational experience with NPO, which derisks the product given the Hyperscaler need not “commit” to CPO as it can elect to ultimately use either optical or copper scale-up solutions to interface with LR SerDes on the XPU or switch.
As Lightmatter’s optical engine solution is based on TSMC COUPE and the GF 45nm SPCLO process, many vectors of scaling are on the table. In addition to delivering 200Gbit/s (uni-directional) per lane via 100Gbaud PAM4, it can also support 200Gbit/s on PAM4 with DWDM8 or 100Gbit/s on PAM4 using DWDM16 to achieve 3.2T per fiber.
While some of the other CPO companies have opted to use the merchant laser source ecosystem, Lightmatter has developed its own external laser source known as GUIDE, which is currently sampling. While other laser sources singulate InP wafers to create discrete laser diodes, GUIDE, the industry’s first Very Large Scale Photonics (VLSP) laser, which is a new class of laser that integrates hundreds of InP lasers onto a single silicon chip to support up to 50 Tbit/s of bandwidth. Lightmatter claims to bring a unique control technology to manage these many InP lasers that also has the benefit of increasing overall reliability by overprovisioning the number of InP lasers and allowing “self repair” by swapping in still functioning diodes. The Nvidia Quantum-X CPO Switch featuring 144 ports of 800G requires 18 ELSs, and Lightmatter claims that two GUIDE laser sources could cater to this same overall bandwidth requirements.
Lightmatter aims to align with the COUPE roadmap offering CPO solutions in earnest in 2027 and 2028 then focus on its flagship Passage™ M1000 solution in 2029 and beyond.
Lightmatter’s M1000 3D Photonic Superchip, is a 4,000 mm² optical interposer that is placed below the host compute engine and takes care of signal conversion from electrical to optical. The M1000 was demonstrated in a live rack-scale demonstration at SC25, and Lightmatter has made it available as a reference design. Passage uses TSVs to deliver electrical signals and power between the XPU and the optical engine, and uses SerDes to connect the two. By placing the ASIC directly on the optical interposer, Passage eliminates the need for large, power-hungry SerDes. Instead, it utilizes 1,024 compact, lower-power SerDes (~8x smaller than conventional SerDes) to enable a total I/O bandwidth of 114Tbit/s (each SerDes operating at 112Gbit/s). By placing the ASIC directly on top of the optical interposer, the chip shoreline constraint is also relieved.

The system incorporates built-in OCS that manages redundancies – if one communication route fails, traffic can be rerouted through an alternate path to ensure uninterrupted operation in such a large-scale system. Additionally, neighboring tiles are electrically stitched together, enabling them to communicate electronically using interfaces such as UCIe.
Passage uses MRMs with diameters of ~15 µm, each integrated with a resistive heater, and achieves 56 Gbit/s NRZ modulation. The module consists of 16 horizontal buses, each capable of carrying up to 16 colors (wavelengths). These colors will be supplied by GUIDE, which delivers 16 wavelengths per fiber on a 200 GHz grid.
Passage utilizes 256 optical fibers, each carrying 16 wavelengths unidirectionally (or 8 wavelengths bi-directionally) via DWDM, delivering between 1 Tbit/s and 1.6 Tbit/s of bandwidth per fiber. To improve yield, they have minimized the number of fibers attached to the chip, reducing complexity and manufacturing challenges. Additionally, they have implemented a fiber attach system that allows faulty fibers to be easily disconnected from the panel and replaced, enhancing reliability and serviceability. The table below reflects the different modes that Passage supports currently.
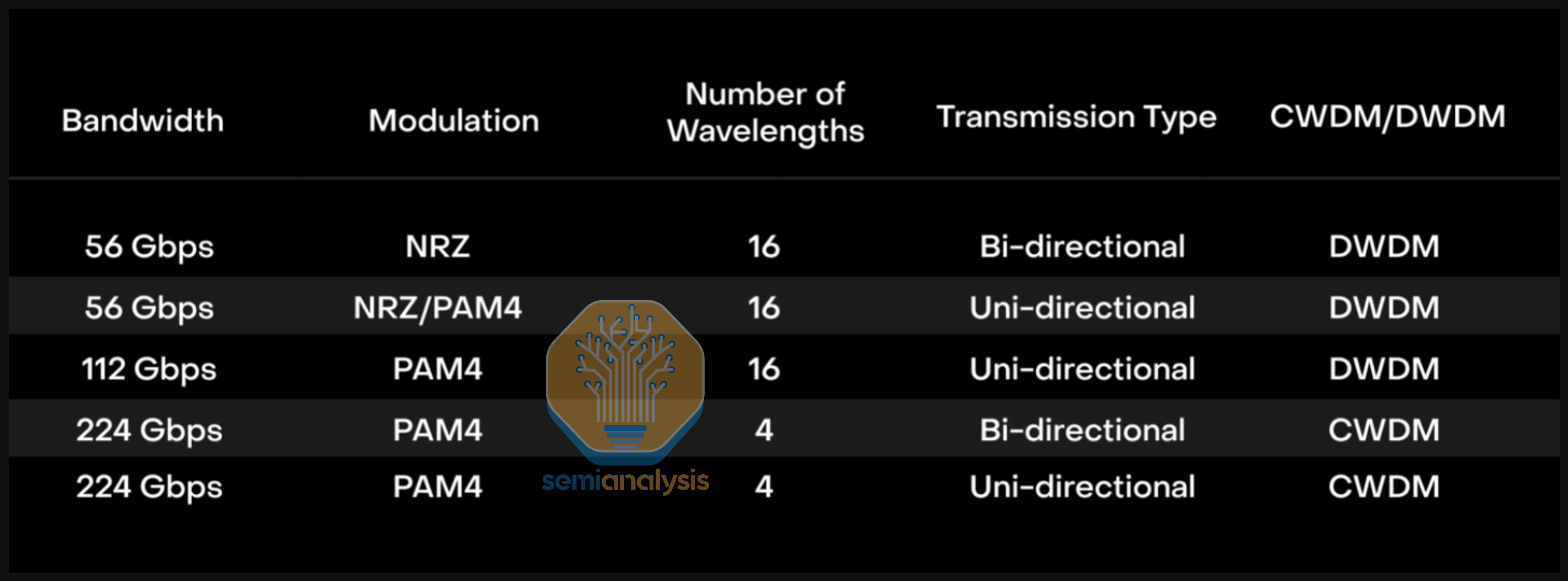
One of the key debates regarding PASSAGE is the thermal stability of the MRMs used given that the optical interposer is located directly beneath a very hot XPU. By comparison, other approaches to CPO do not envision the modulators being placed directly beneath the XPU, and as such are easier to thermally manage. In response to this point, Lightmatter has explained that the control loops used for MRMs in PASSAGE can handle 2,000C per second of excursion and can handle temperatures of between 0 to 105C – that is to say a 60 to 80C temperature transition could occur within 10ms without disrupting the optical links.
The SC25 demonstration video depicted an illustration of temperature variation of between 25C to 105C showing a wide range of operating temperatures, though this particular but with the 80C transition taking around one minute – for a fairly low 1.33C per second excursion, but a separate demonstration also at SC25 using an on-chip thermal aggressor reached the 2,000C/s rate, with the MRM stabilizer heater allowing a far lower range of -2 to +2 C/s at the MRM itself.


Xscape Photonics
Xscape Photonics is an innovative company that is working on ChromX, a programmable laser that offers 4 to 16 wavelengths, with plans to provide up to 128 wavelengths in the future. By offering up to 128 different colors, ChromX will be able achieve significantly higher bandwidth as compared to existing lasers that only offer 4 to 8 wavelengths. ChromX relies on an external III-V laser alongside an on-chip multicolor generator that helps to generate multiple wavelengths for WDM.

The fact that the laser is programmable offers flexibility to provide wavelengths for different types of workloads to meet different bandwidth and distance requirements. Interestingly, their solution requires only one laser whereas existing CPO solutions require multiple lasers that have extremely high power and electricity consumption. Moreover, all wavelengths are carried over a single fiber which avoids the complexity that plagues most CPO systems that require multiple fibers significantly reducing fiber coupling issues.
Xscape recently announced the availability of its EagleX, which is a plug and play technology evaluation kit targeting Scale Up CPO applications and is positioning itself for product announcements in 2026.

Ranovus
Ranovus is focused on both optical chiplet technology as well as laser design and manufacturing. They have taped out products across a few different paths, a monolithic CPO product at GlobalFoundries and a TSMC PIC tape out.
Unlike other CPO vendors that focus on bookended solutions, Ranovus focuses on developing interoperable systems and focuses on Ethernet standard interoperability as their key differentiator. They demonstrated their 8x100G DR8 optical interoperability at OCP 2024 in partnership with MediaTek - showing interoperability with standard 8x100G pluggable module from various third party suppliers.
Ranovus’s Odin Optical Engine uses Microring Resonator modulators and can deliver up to 64 lanes of 100Gbit/s using PAM4 modulation.

Ranovus’ go to market is centered around providing the interoperable solutions that customers want. For now, this means 100G PAM4 DR optics, but the use of Microring Resonators for modulation enables a pivot to other schemes such as 56 Gbaud NRZ but using WDM combining 4 lambdas to deliver 400G per fiber pair.
Ranovus has demonstrated interoperability with AMD on its 800G chiplet and has partnered with MediaTek to offer the Odin direct-drive CPO 3.0 as a chiplet solution for future custom silicon XPUs from Hyperscalers.
Scintil
Scintil’s main product is LEAF Light, a Photonic System-on-Chip (PSoC) that can be delivered in die format (KGD) or assembled in modules, integrating 8 or 16 lasers of different colors spaced at 200 GHz or 100 GHz intervals, enabling multiple wavelengths to be carried on a single fiber through DWDM. They have developed electronic controls that would allow them to accurately maintain 100 GHz or 200 GHz spacing between wavelengths, even under temperature variation. There is a package reference design for an ELSFP module – similar to an OSFP – defined by the OIF, making it easier for customers to integrate this external laser source. Scintil’s solution works well with co-packaged optics based on ring modulators.
Scintil’s process is called SHIP (Scintil Heterogeneous Integrated Photonics). The essence of the technology is to integrate III-V lasers onto standard silicon photonics in a wafer-level process. The process begins with a standard silicon photonics wafer – complete with waveguides, detectors, and mux/demux – fabricated using a conventional foundry flow. The wafer is then flipped and bonded to a new handle, allowing the original substrate to be removed and revealing the buried oxide layer. Unpatterned III–V material is subsequently bonded onto this newly exposed surface. The III-V is then patterned with lithography and etched to fabricate lasers, resulting in a monolithically integrated silicon photonics chip with on-board lasers. This contrasts with traditional InP-based lasers patterned using E-beam writers, where achieving precise wavelength control for DWDM can be more challenging, making it difficult to support tightly spaced channels.

Developing a DWDM DFB laser array is challenging because each wavelength’s frequency must be precisely generated. To achieve a 100 GHz channel separation, the advanced capabilities of silicon photonics foundries and photolithographic processes shall be leveraged to accurately and repeatedly pattern the grating in silicon. Moreover, because the lasers are produced at the wafer level, hundreds of devices can be fabricated on each wafer, enabling high-volume and scalable production.
One key advantage of Scintil’s solution is power efficiency. The Scintil solution can generate and multiplex multiple colours (8 or 16) on single chip, unlike solutions using multiple discrete lasers along a combiner splitter, which require very high-power lasers to achieve the target power per multiplexed color. The Scintil solution offers superior power efficiency and increased bandwidth density, while halving the energy required for each transmitted bit. This is in comparison to existing co-packaged solutions, (including what Nvidia is currently adopting for Q3450 CPO switches), which use a single wavelength with high modulation speed rather than multiple wavelengths with low modulation speed.
Part 5: Nvidia’s CPO Supply Chain
We have discussed the role key components play in CPO systems, in this section we will discuss specific companies in the supply chain and component BOM cost with a focus on Nvidia’s suppliers, naming key suppliers for Laser Sources, ELS Modules, FAU, FAU Alight Tools, FAU Assembly, Shuffle Box, MPO Connectors, MT Ferrules, Fibers, and E/O Testing.
 | A guest post by
|