

Meta Superintelligence - Leadership Compute, Talent, and Data
AI Datacenter Titanomachy, "The Tent", AI Data and Talent Wars, Zuck Founder Mode, Behemoth 4 Post-Mortem, OBBB Tax Windfall, AI and Reality Labs
Meta’s shocking purchase of 49% of Scale AI at a ~$30B valuation shows that money is of no concern for the $100B annual cashflow ad machine. Despite seemingly unlimited resources, Meta has been falling behind foundation labs in model performance.
The real wake-up call came when Meta lost its lead in open-weight models to DeepSeek. That stirred the sleeping giant. Now in full Founder Mode, Mark Zuckerberg is personally leading Meta’s charge, identifying Meta’s two core shortcomings: Talent and Compute. As one of the last founders still running a tech behemoth, Mark doesn’t need SemiAnalysis to tell him to slow down stock buybacks to fund the future!
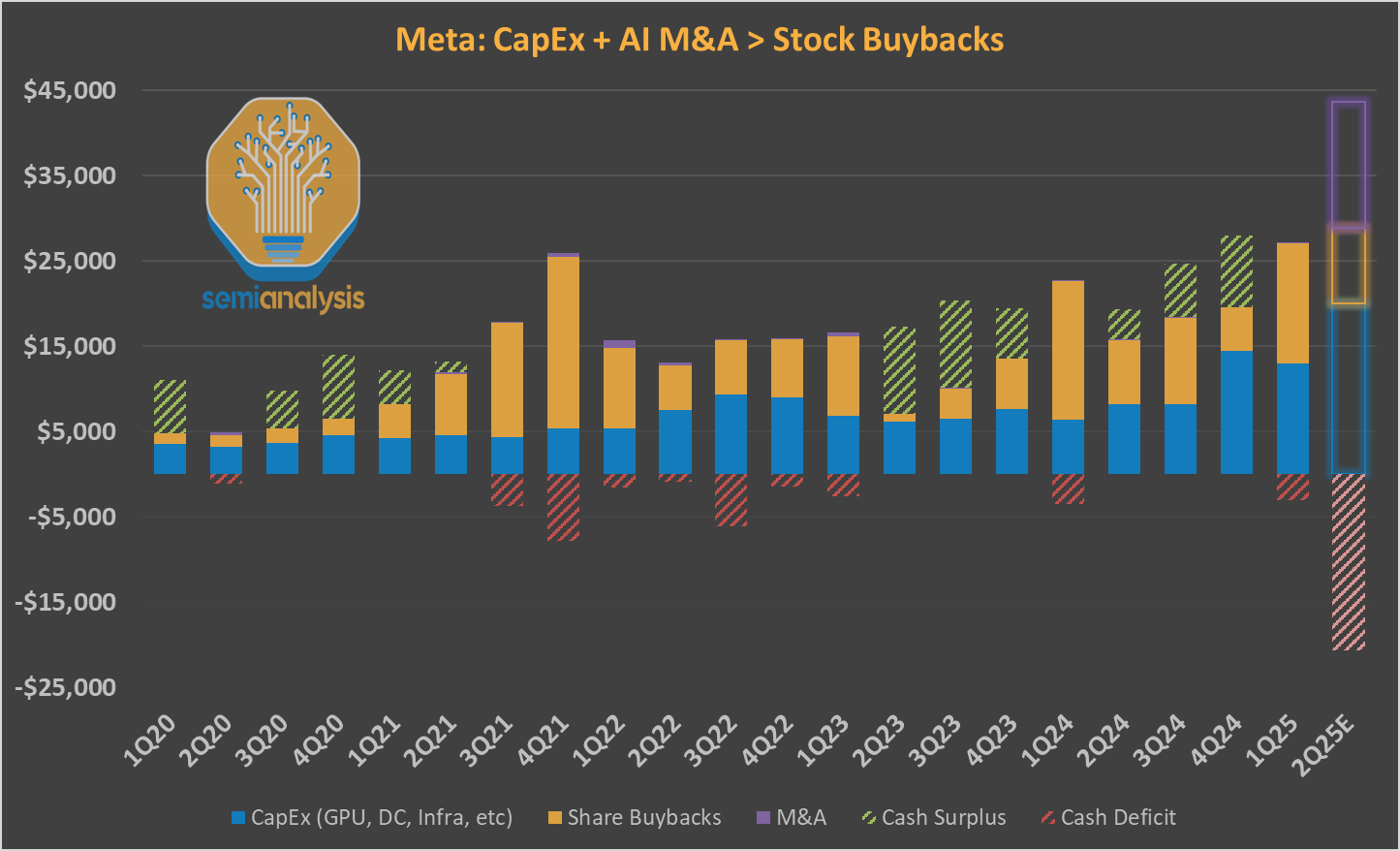
In addition to throwing money at the problem, he’s fundamentally rethinking Meta’s approach to GenAI. He’s starting a new “Superintelligence” team from scratch and personally poaching top AI talent with pay that makes top athlete pay look like chump change. The typical offer for the folks being poached for this team is $200 million over 4 years. That is 100x that of their peers. Furthermore, there have been some billion dollar offers that were not accepted by researcher/engineering leadership at OpenAI. While these offers aren't all successful, Zuck is crushing the competitors by drastically increasing their cost per employee.
Perhaps even more iconic, Zuck threw his entire Datacenter playbook into the trash and is now building multi-billion-dollar GPU clusters in “Tents”!

As this report details, nothing is off the table. We unpack Meta’s unprecedented reinvention from Compute to Talent in the pursuit of Superintelligence as well as the story of how we got here. From Llama 3.0 open-sourced dominance to the epic fail of Llama 4 Behemoth, this Titan of AI is down but not out. In fact, we believe Meta’s ramp in training FLOPS will rival even that of OAI. The company is going from GPU-poor to GPU-filthy-rich on a per researcher basis.
Meta GenAI 1.0: AI Incrementalism
Compared to pure-play AI labs like OpenAI, companies like Meta and Google have followed an “AI Incrementalism” strategy by enhancing existing products with better recommendation systems and GenAI to improve ad targeting, content tagging, and internal tools. This has paid off handsomely in financial results, allowing Meta to shrug off Apple’s attempts at stopping them from tracking users with the release of their App Tracking Transparency (ATT) feature in iOS 14.5 (late 2021, early 2022).
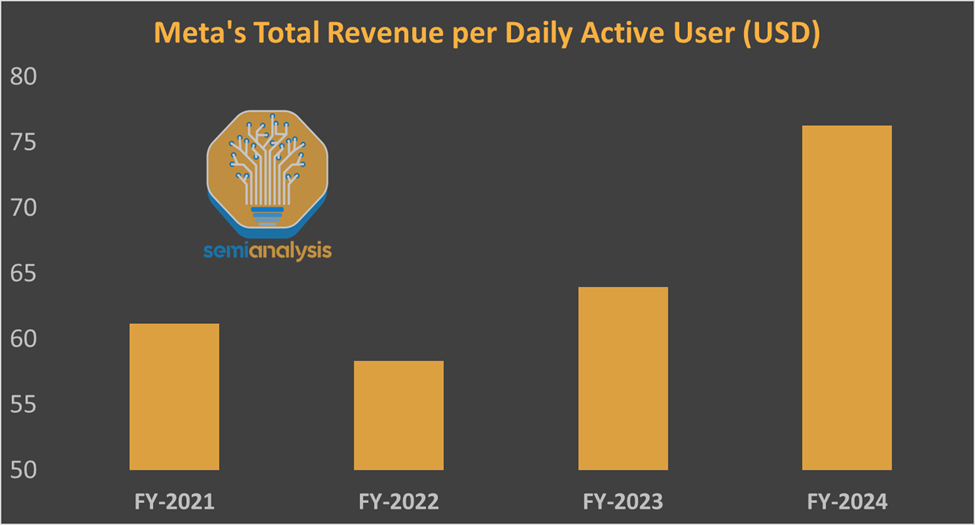
While Meta is arguably more insulated from GenAI disruption than Google, LLM efforts at both companies have been somewhat disappointing. One reason is the allocation of capital primarily for the core business rather than pursuing superintelligence.
“Our CapEx growth this year is going toward both generative AI and core business needs with the majority of overall CapEx supporting the core.”
Source: Meta Q1 2025 earnings call, emphasis SemiAnalysis
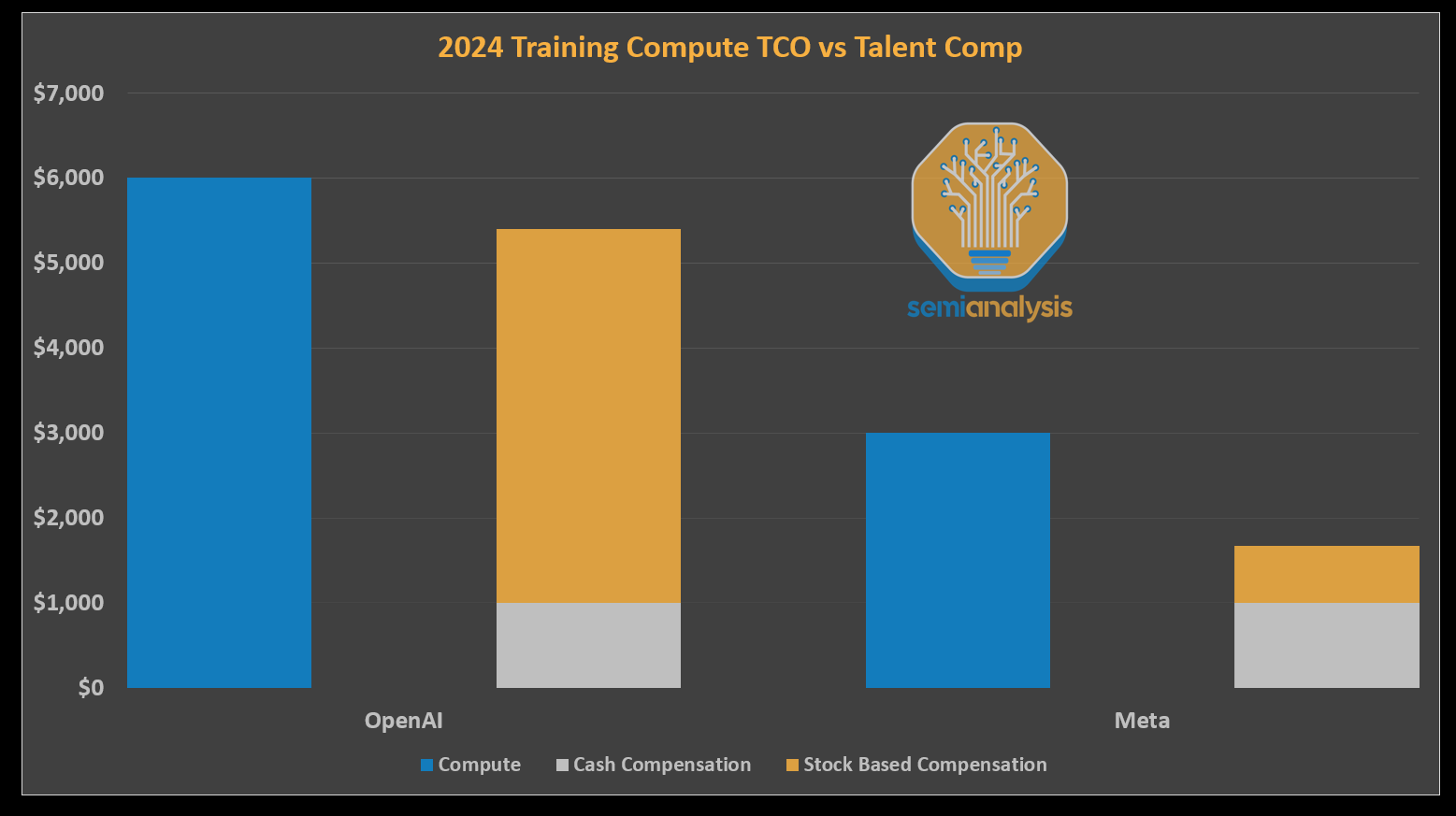
GenAI acts as an extension to these tech giants’ businesses. They don’t have the same existential need to dominate new use cases like OpenAI in chatbots and Anthropic in coding APIs. This is readily apparent in the compute vs human capital allocation of a leading AI foundation lab like OpenAI compared to Meta. Zuck's impact on competing offers and inflation of salary will hurt badly.
As a result, when measuring GenAI consumer app traction, Meta and Google meaningfully lag ChatGPT in its reach and engagement.
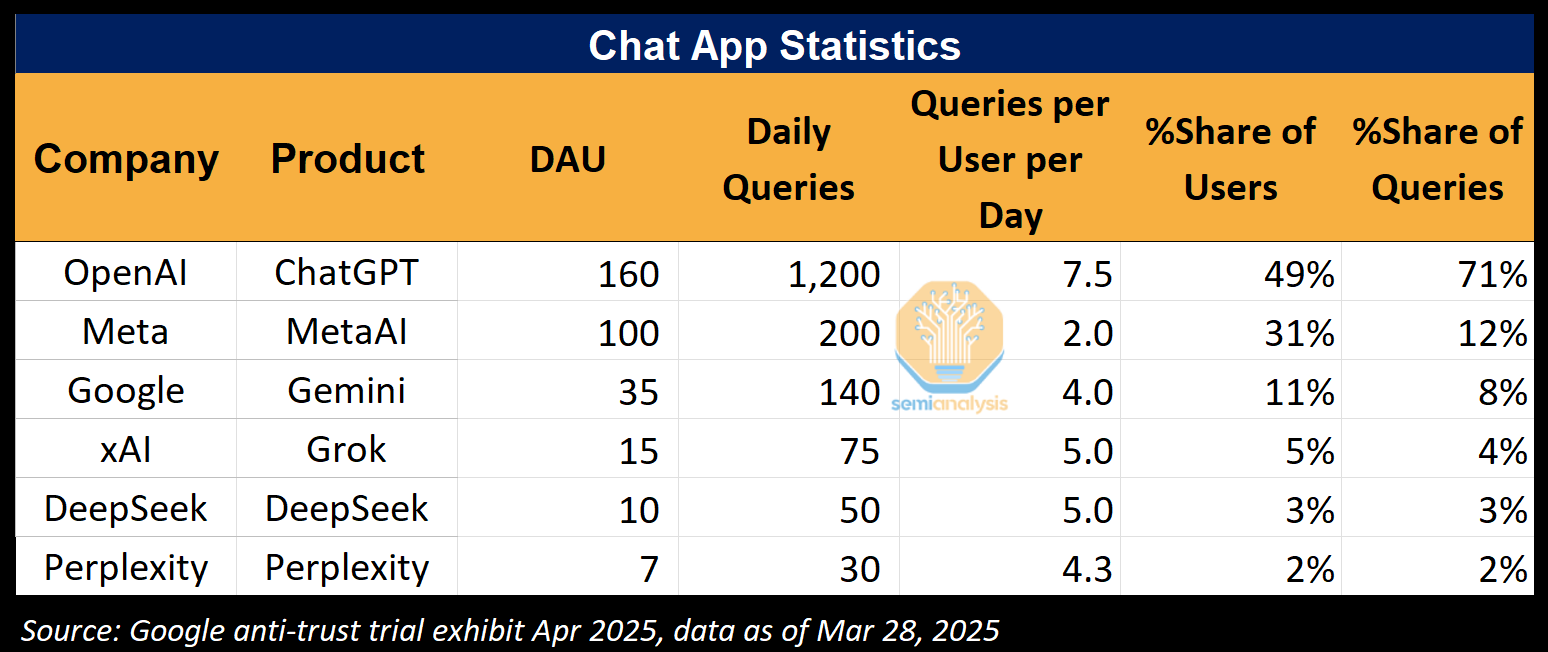
But that’s changing. Leveraging our proprietary Accelerator Industry Model and Datacenter Industry Model, we forecast a meaningful step up in GenAI investment from Meta in the coming years.
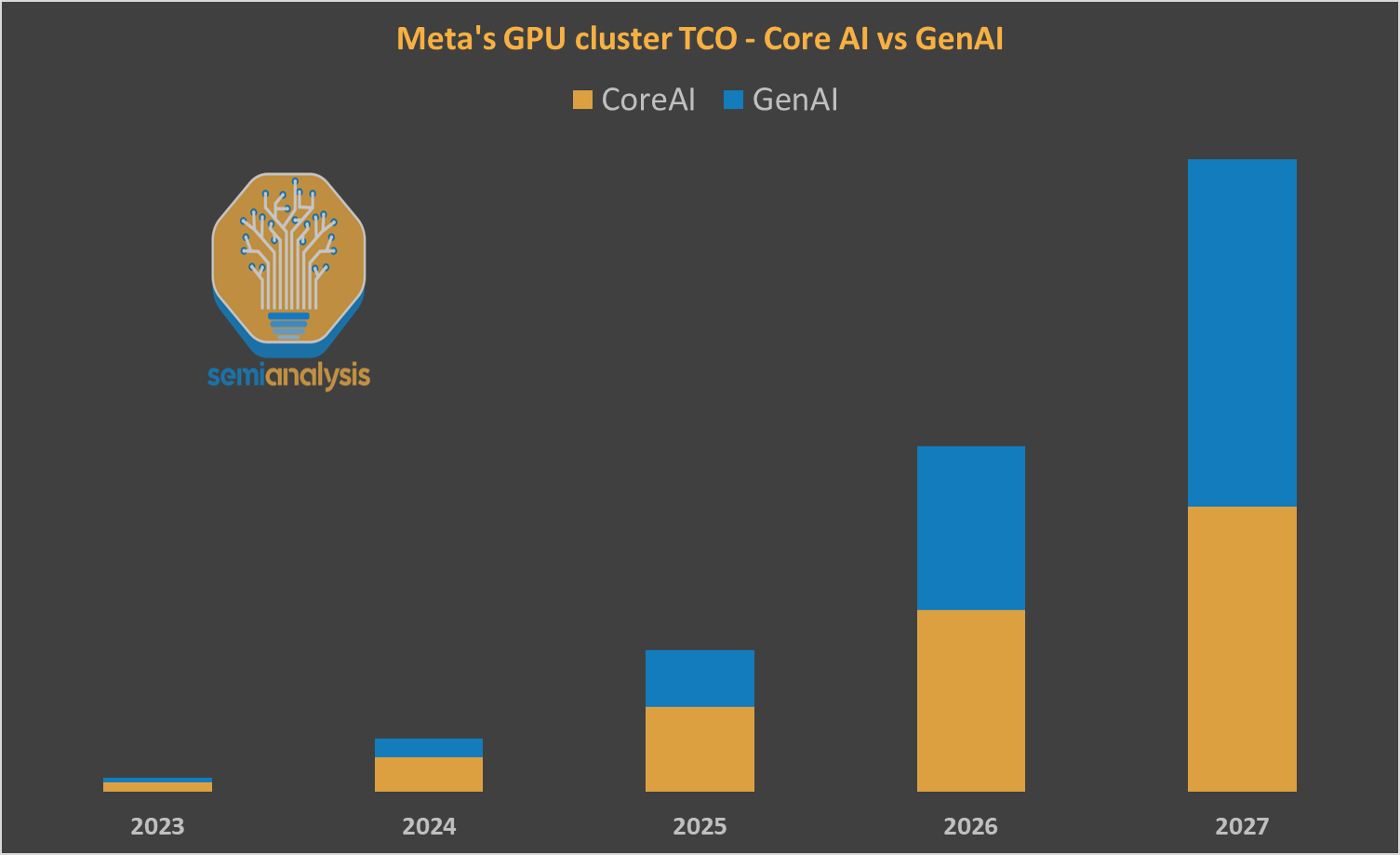
Meta GenAI 2.0 – Part 1, Re-Inventing the Datacenter Strategy (Again)
From Buildings to Tents
Just a year ago, Meta scrapped its decade-old “H”-shaped datacenter blueprint for a new AI-optimized design.

Now in 2025, Zuck decided to re-invent the strategy again. Inspired by xAI’s unprecedented time-to-market, Meta is embracing a datacenter design that prioritizes speed above all else. They’re already building more of them! Traditional datacenter and real estate investors, still somewhat reeling from xAI’s Memphis site and time to market, will be shocked yet again.

This design isn’t about beauty or redundancy. It’s about getting compute online fast! From prefabricated power and cooling modules to ultra-light structures, speed is of the essence as there is no backup generation (ie no diesel generators in sight).
Power currently uses nearby Meta on-site substations. Meta likely uses sophisticated workload management to maximize the utilization of every watt of power it gets from the grid. It might even need to shut down workloads in the hottest summer days.
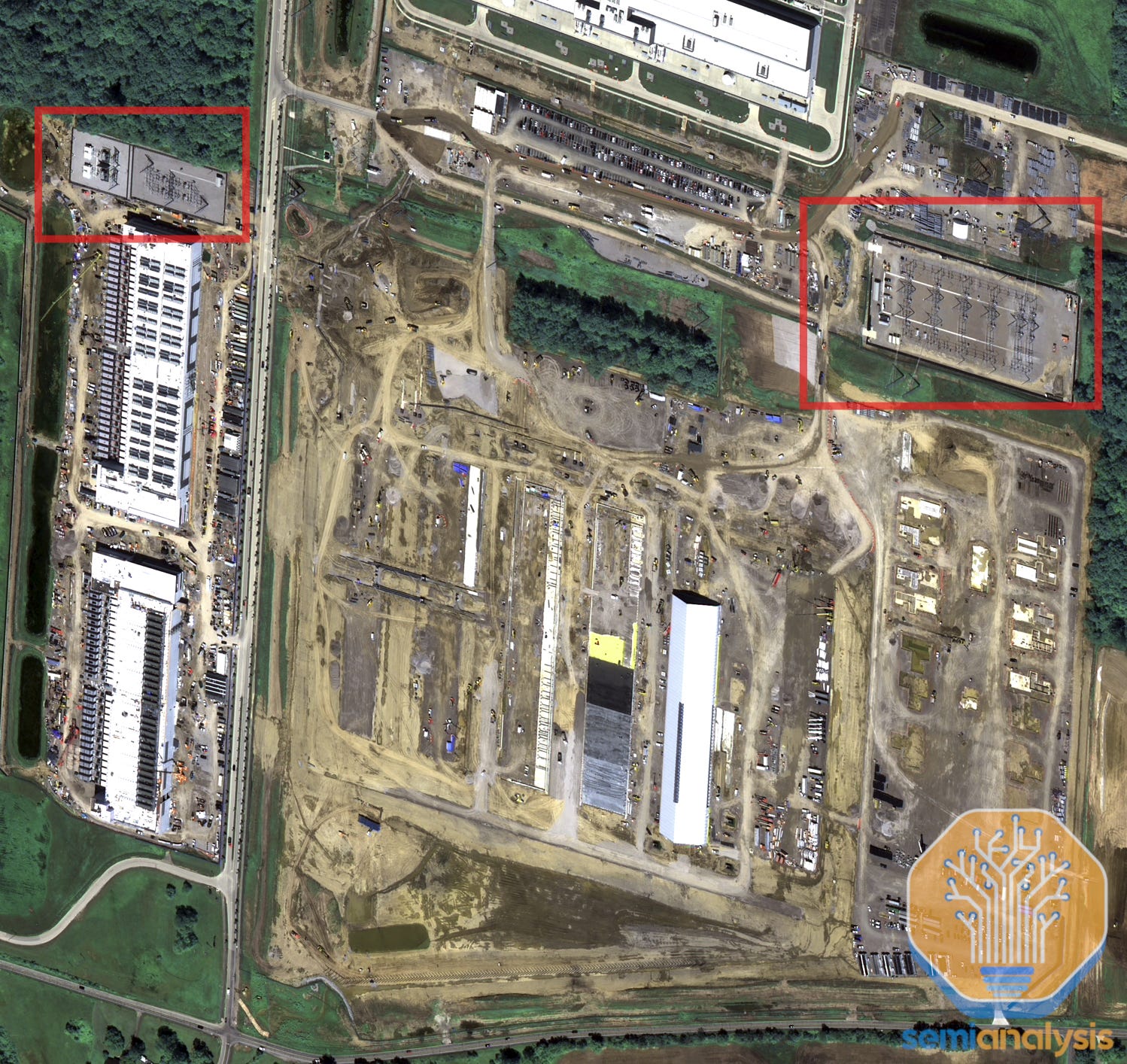
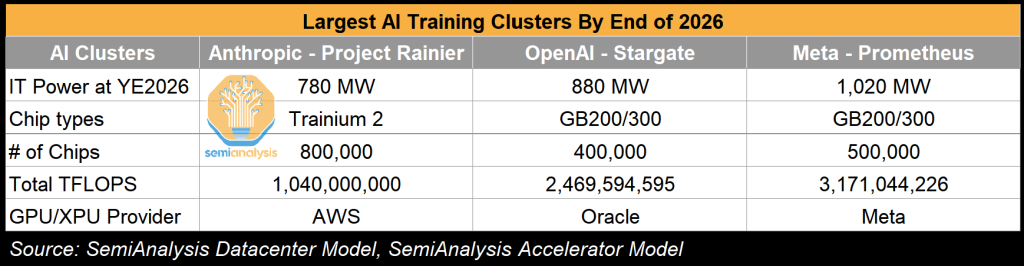
The Prometheus 1GW AI Training Cluster – An “All Of The Above” Infrastructure Strategy
Meta is quietly building one of the world’s largest AI training clusters in Ohio. We have heard from sources within their infrastructure organization they are calling this cluster Prometheus. To beat rival AI labs, Meta has carried out an “all the above” infrastructure strategy:
Self-build campus.
Leasing from third parties.
AI-optimized designs.
On-site, behind-the-meter natural gas generation.
Looking at the Prometheus training cluster below, we believe Meta is connecting all these sites with ultra-high-bandwidth networks all on one backend network powered by Arista 7808 Switches with Broadcom Jericho and Ramon ASICs.
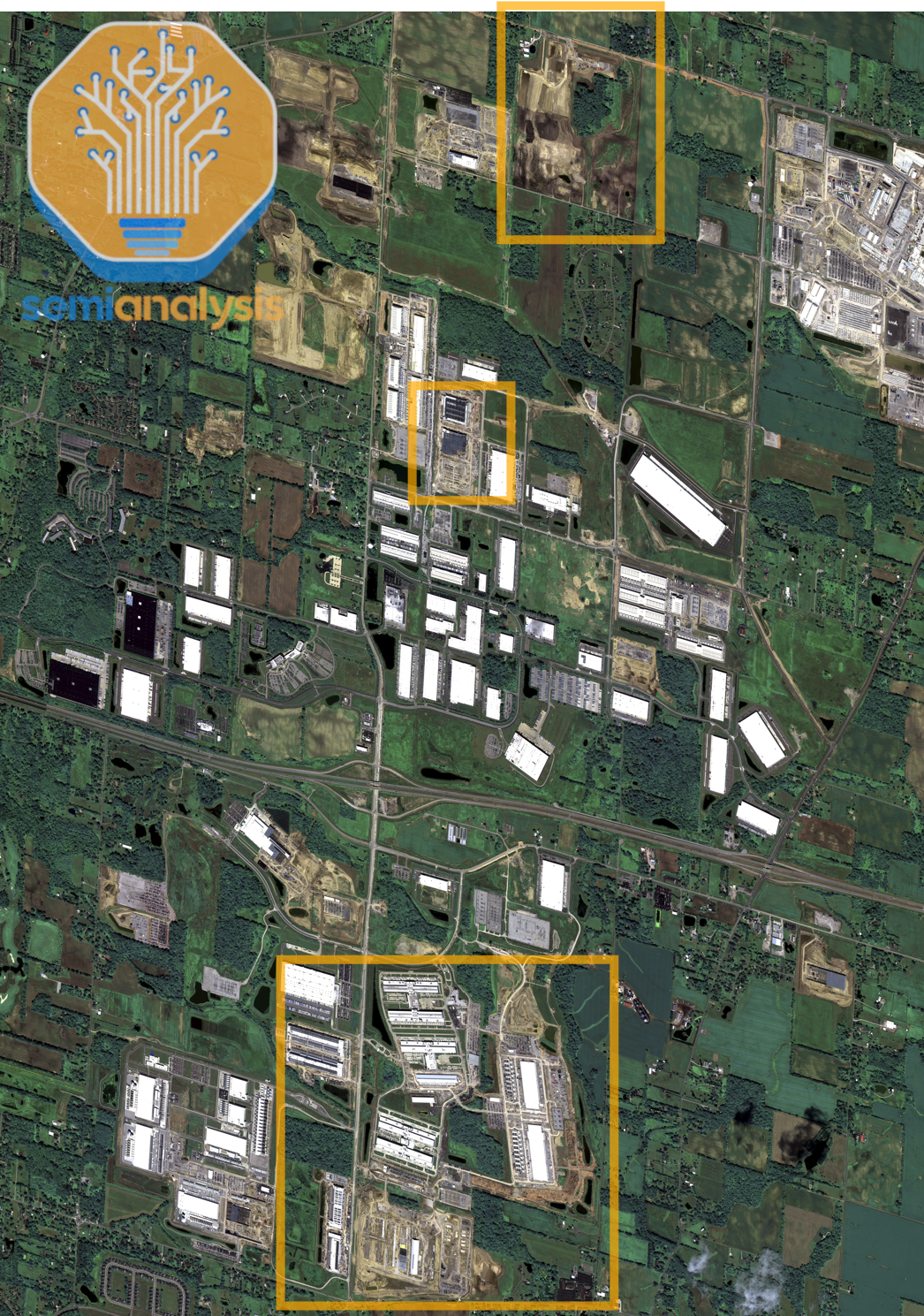
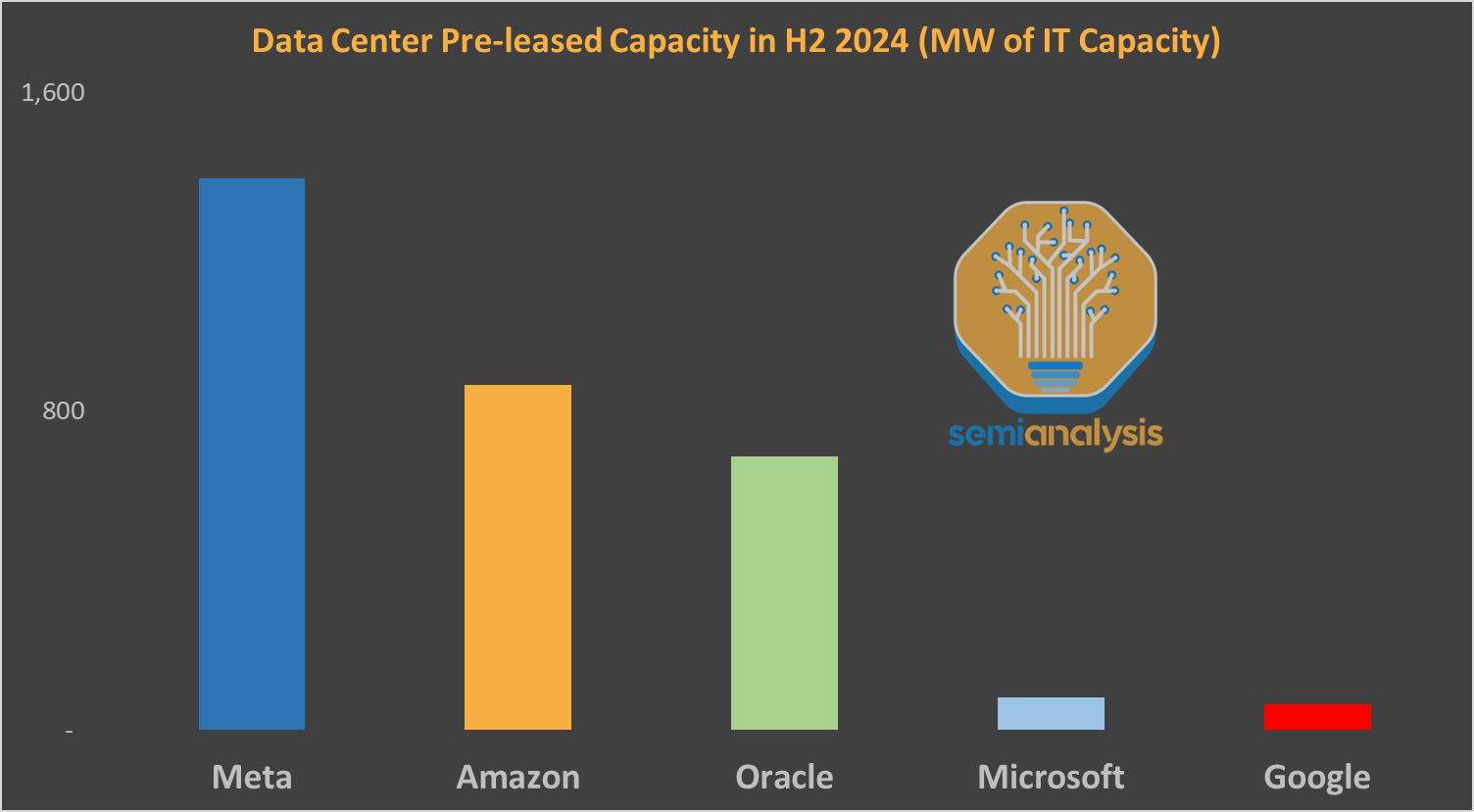
By combining both self-build and leasing, Meta ramps faster. In fact they pre-leased more capacity second half of 2024 than any hyperscaler, mostly in Ohio.
Furthermore, when the local power grid couldn’t keep up, Meta went full Elon mode. With help from Williams, they’re building two 200MW on-site natural gas plants. The equipment breakdown for the first includes:
3* Solar Turbines’ Titan 250 turbines
9* PGM 130 turbines
3* Siemens Energy SGT400 turbines
15* CAT 3520 Reciprocating Engines

A future SemiAnalysis report will dig much deeper into these systems for the purpose of powering datacenters: cost, advantages & disadvantages, etc. This has signficant negative implications for a certain supplier of onsite natural gas solutions.
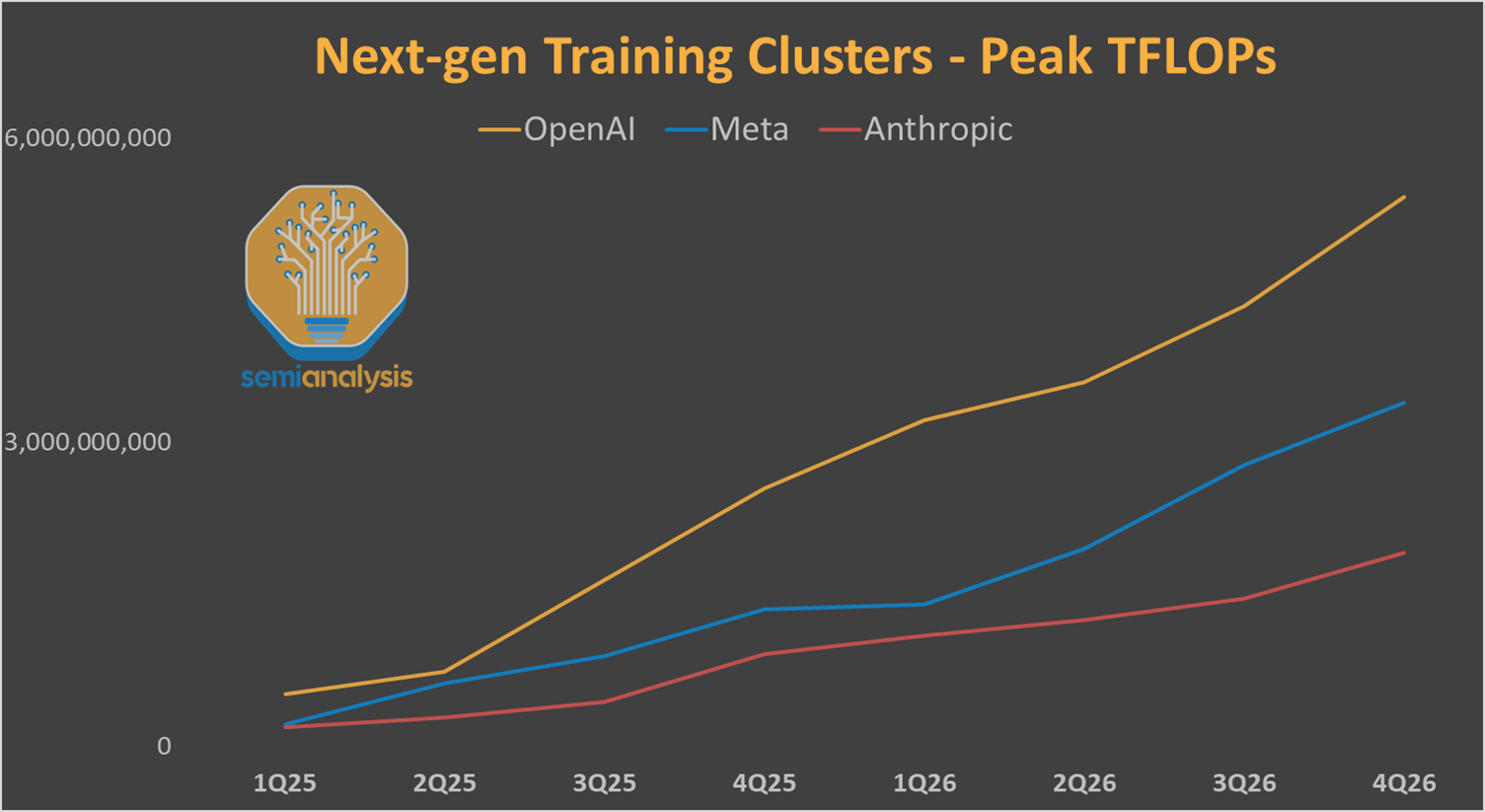
This total compute advantage for OpenAI is important as the advent of reinforcement learning means many large datacenters distributed around the US can be used asynchronously to contribute to improving model intelligence with post-training.
Not to be one-upped, Hyperion—Meta’s second frontier cluster—aims to erase that gap to OpenAI.
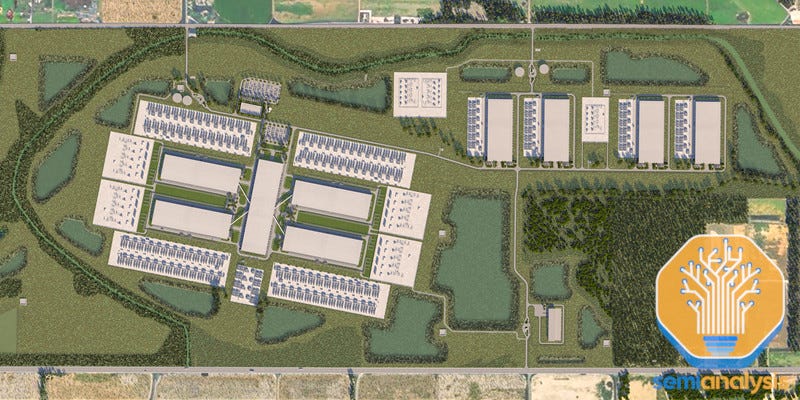
Beating Stargate at Scale: Meta’s Hyperion 2GW Cluster
While all eyes are on the high-profile Stargate datacenter in Abilene, Meta has been planning a response for over a year and making tremendous progress. The Louisiana cluster is set to be the world’s largest individual campus by the end of 2027, with over 1.5GW of IT power in phase 1. Sources tell us this is internally named Hyperion.
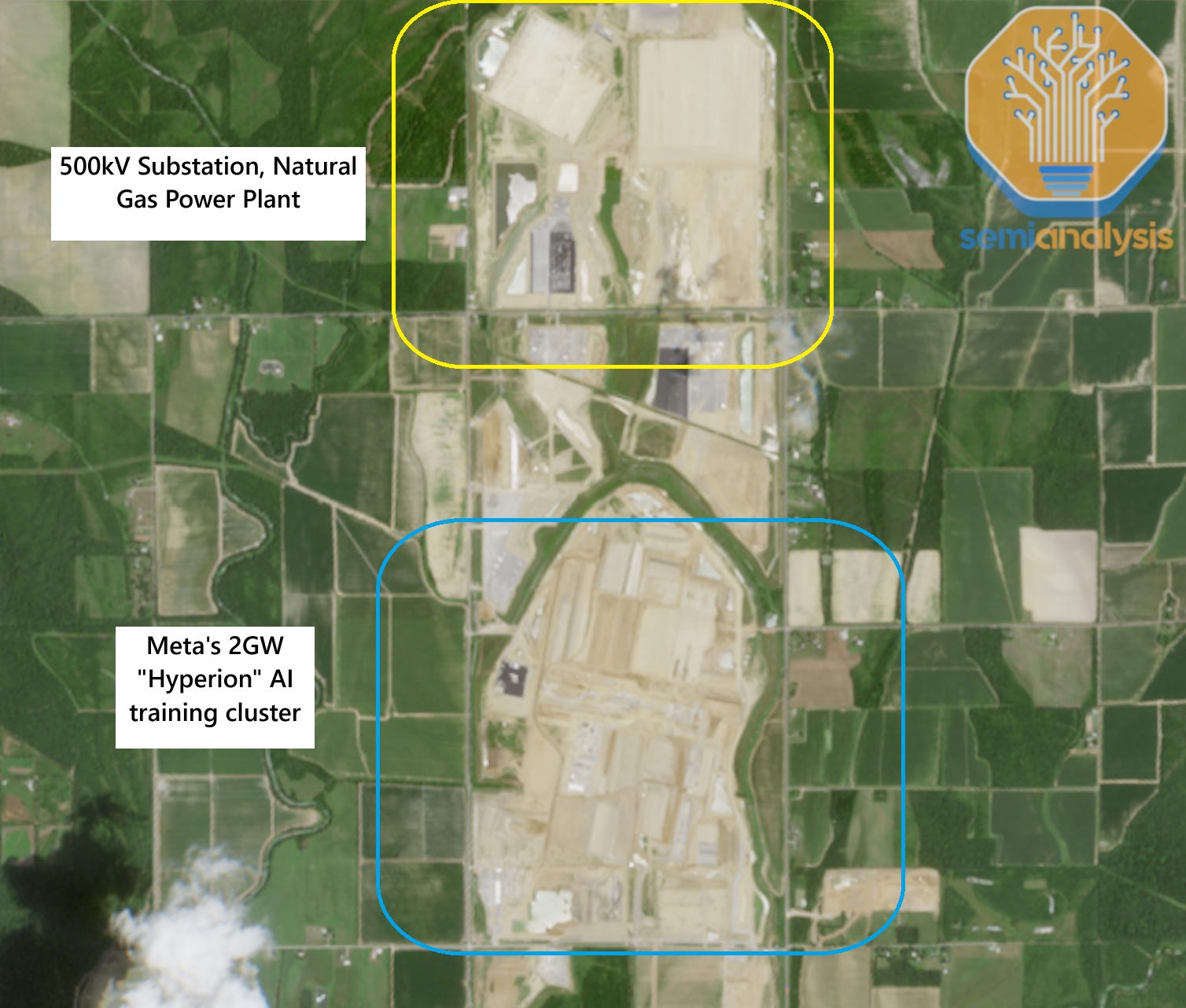
Meta broke ground at the end of 2024 and is currently actively working on both the power infrastructure, and the datacenter campus.
To be clear, Meta has many other datacenters under construction and ramping. A full list of Meta’s AI Datacenters, their expected completion dates, and power per building by quarter can be found in our Datacenter Industry Model.
Llama 4 Failure – From Open-Source Prince to Behemoth Pauper
Before we dive into the Superintelligence Talent race, we should take a look at how Meta found itself in this awkward position. After leading the open-source frontier with Llama 3, Meta now finds itself trailing China’s DeepSeek.
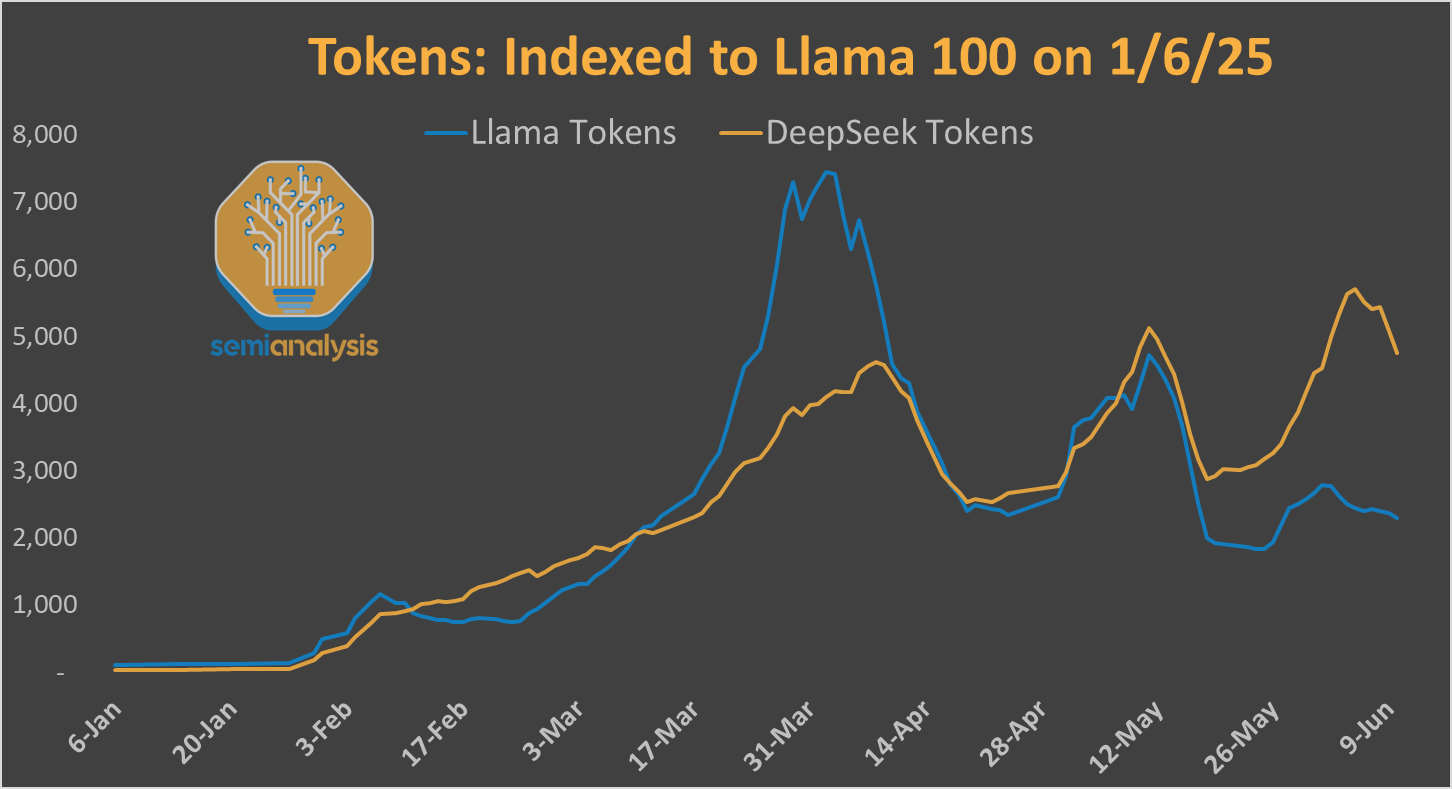
On a technical level, we believe the major contributors to the failed run were as follows:
Chunked attention
Expert choice routing
Pretraining data quality
Scaling strategy and coordination
Chunked Attention
Naively implemented, attention in large language models scales quadratically with token count. To address this, researchers introduced memory-efficient mechanisms. Meta chose chunked attention for Behemoth, and that may have been a mistake.
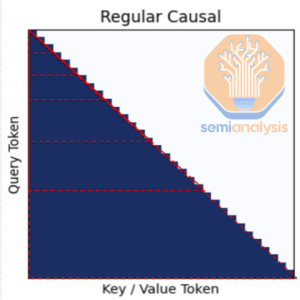
Standard Causal Attention: Imagine a series of expanding triangles fanning out from the top left corner, representing the attention size for every subsequent token. Double the tokens and the area of the triangle quadruples.
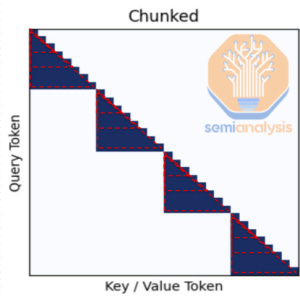
Chunked Attention breaks this triangle into fixed-size blocks. Each block resets attention to a new “first” token. With the efficiency of reduced memory, it enables even longer context. Meta felt they needed this to achieve long context, but the tradeoffs aren’t worth it. The first token in each block lacks access to prior context. While there are some global attention layers, that’s not enough as we expand on below.

Sliding Window Attention, used in other models, provides a smoother alternative: the attention window slides forward token-by-token. This maintains local continuity, even if long-range reasoning still requires multiple layers to propagate context.
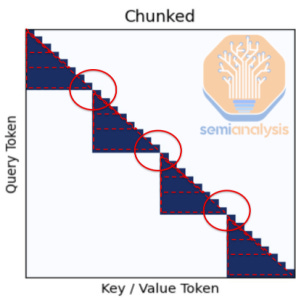
Behemoth’s implementation of chunked attention chasing efficiency created blind spots, especially at block boundaries. This impacts the model’s ability to develop reasoning abilities as chain of thought exceeds one chunk in length. The model struggles to reason across longer ranges. While this may seem obvious in hindsight, we believe part of the problem was that Meta didn’t even have the proper long context evaluations or testing infrastructure set up to determine that chunked attention would not work for developing a reasoning model. Meta is very far behind on RL and internal evals, but the new poached employees will help close the reasoning gap massively.
Expert Choice Routing
Most modern LLMs use a Mixture of Experts architecture in which, between each model layer, a the token is routed to different experts based on a router. In modern MoE models, most are trained with token choice routing, i.e. the router provides a tensor of shape T x E (T being total tokens, E being number of experts in the MoE model) and a topK softmax is run on the E dimension producing a T by K tensor. This effectively means that the router is asked to choose K most probable experts for each of the tokens T, where K can be one or more experts. K is a hyperparameter that can be tuned by the researcher.

The advantage of this approach is that each token is guaranteed to be attended to by K experts, making sure the information value of each token is absorbed by the same number experts. The disadvantage is that certain experts can be disproportionately ‘popular’ with tokens while other experts are under-trained, resulting in an imbalance in the ‘intelligence’ of each expert. A known problem, many of the top labs have developed a fix with auxiliary-loss (or loss-less) load balancing. When training with EP (Expert Parallelism), this can lead to lower training MFU, as the model is spread across different GPU nodes, resulting in many more collectives (NCCL) running across the scale-out network (InfiniBand or RoCE) instead of the scale-up network (NVLink). This is a major motivation for NVIDIA’s NVL72 design, where the scale-up network expands beyond standard 8-way servers.
Expert choice routing, introduced by Google in 2022, flips the logic: experts choose the top-N tokens. Taking the same T x E tensor produced by the router, in expert choice routing a topN softmax is run on the T dimension which produces a E by N tensor. This effectively means each of the E experts has chosen the N highest probability tokens to be routed. The N hyperparameter can be tuned by the researcher but to compare it to a token choice routing approach, N = K * T / E.
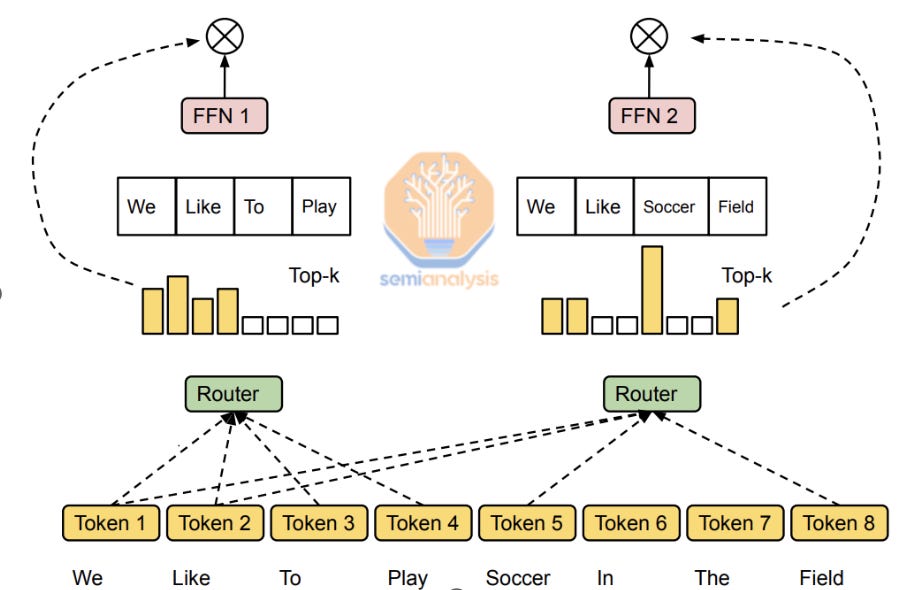
When compared directly to token choice routing, expert choice routing guarantees that experts are being activated in a balanced manner, avoiding the performance degradations associated with imbalanced experts. To be clear: the router makes the choice in both cases. In token choice, the input to the router is the tokens, and it picks the experts. In expert choice, the input to the router is the experts, and it picks the tokens.
This equalizes the load for expert training and improves MFU across distributed hardware. Hyperscaler networks are purpose-built for this kind of parallelism, and we cover them extensively in our Networking model.
The disadvantages of this approach is inverse of the token choice architecture. Expert choice routing can result in certain ‘popular’ tokens being attended to by multiple experts. While this doesn’t produce the same training bottleneck that is present in token choice routing, it can result in degraded model generalization as the LLM now does not pay attention to all tokens equally. Furthermore, most EC models need to be finished with TC training to produce an effective LLM.
Inference is also another issue for EC. Inference is split in two steps: Prefill and Decode. In the Prefill stage, the user prompt is encoded and loaded into the KVCache. This step is Flop-bound. In the Decode step, the model calculates the attention and runs through the feed forward network of the model one token at a time one layer at a time.
Here, expert choice routing struggles as the experts can only choose from to 1 token x batch size per layer initially, resulting in each expert only given a very small set of tokens compared to when it was trained (an example training run would have 8k seqlen x 16 batch size = 128k tokens per pass). Being able to see the entire sequence as in training would break causality of modern autoregressive models hence the mix of EC and TC even for EC models.
Meta switched from expert choice to token choice routing partway through the run which is not unusual for EC models. However the performance drop from the switch resulted in a model that was meaningfully worse than a model fully trained on TC.
Data Quality: A Self-Inflicted Wound
Llama 3 405B was trained on 15T tokens and we believe Llama 4 Behemoth required substantially more tokens, 3-4x order of magnitude larger. Getting sufficiently high-quality data is a major bottleneck that Western hyperscalers cannot shortcut by copying the homework of other models’ outputs.
Prior to Llama 4 Behemoth, Meta had been using public data (like Common Crawl), but switched mid-run to an internal web crawler they built. While this is generally superior, it also backfired. The team struggled to clean and deduplicate the new data stream. The processes hadn’t been stress-tested at scale.
Furthermore, unlike all other leading AI labs including OpenAI and Deepseek, Meta does not utilize YouTube data. YouTube lecture transcripts and other videos are an incredible source for data and the company may have struggled to produce a multimodal model without the data.
Scaling Experiments
Beyond the above technical issues, the Llama 4 team also struggled to scale research experiments into a full-fledged training run. There were competing research directions and a lack of leadership to decide which direction was the most productive path forward. Certain model architecture choices did not have proper ablations but were thrown into the model. This led to poorly managed scaling ladders.
As an example of how hard scaling experiments can be, let’s look at OpenAI’s training of GPT 4.5. OAI’s internal code monorepo is very important for training their model as they need a validation dataset to measure perplexity against when doing training ablations that is known to be uncontaminated. While scaling GPT 4.5 training experiments, they were seeing promising developments in the model’s ability to generalize only to realize mid-run that parts of the monorepo were copied-pasted directly from publicly available data. The model was not generalizing but rather regurgitating memorized code from its training dataset! Large pretraining runs requires enormous amounts of diligence and preparation to effectively execute.
Despite all of these technical issues, not all was lost. Meta was still able to distill the logits into the smaller and more efficient pretrained Maverick and Scout models, bypassing some of the flawed architectural choices of the larger model. Distillation is far more efficient than reinforcement learning for smaller models. That said, these models are still bound by the limitations of their source: they aren’t best-in-class for their size.
Meta GenAI 2.0 Pt 2: Bridging the Talent Gap
With infrastructure revamp underway and the technical lessons absorbed, Meta’s GenAI 2.0 strategy now pivots to the next ingredient of superintelligence: talent.
Mark Zuckerberg understands the talent gap relative to leading AI labs and has taken over recruiting. He’s on a mission to build a small but extremely talent-dense team, casually offering signing bonuses in the tens of millions of dollars. The goal is to create a “flywheel effect”: top tier researchers join the adventure, bringing credibility and momentum to the project. It’s already working with recent high-profile hires including:
Nat Friedman, former GitHub CEO
Alex Wang, former Scale AI CEO
Daniel Gross, who was the CEO and co-founder of SSI, Ilya Sustkever’s startup.
The recruiting pitch is powerful: unrivaled compute per researcher, a shot at building the best open-source model family, and access to over 2 billion Daily Active Users. The offers that generally range from $200M to $300M per researcher for 4 years also strengthens this pitch. As such Meta has acquired awesome talent from OpenAI, Anthropic, and many other firms.
M&A, Scale AI, etc
Zuckerberg reportedly made acquisition offers to both Thinking Machines and SSI, but was turned down. While some have noted that Zuckerberg “settled” for Scale AI, we do not think this is the case. As we discussed, core to many of the Llama 4 issues were data problems and the Scale acquisition is a direct move to address that.
Alex will bring many of the top engineers from Scale, especially the SEAL lab which specializes in evals that Meta so desperately needs. SEAL has developed one of the top benchmarks for Reasoning model evaluations, HLE (Humanity’s Last Exam). With Nat Friedman and Daniel Gross joining the team, Meta gains not just elite operators but tow of the most prolific and respected investors in the AI community. Meta has very strong product people at the top.
The More You Buy The More You Save: OBBB Edition
Zuck could not have picked a better time start this spending splurge. The One Big Beautfiul Bill has some tax goodies specific to hyperscalers that could massively accelerate the tax incentives to build now and go big. Superintelligence funded by the federal government is the modern Manhattan Project.