

Scaling Reinforcement Learning: Environments, Reward Hacking, Agents, Scaling Data
Infrastructure Bottlenecks and Changes, Distillation, Data is a Moat, Recursive Self Improvement, o4 and o5 RL Training, China Accelerator Production
The test time scaling paradigm is thriving. Reasoning models continue to rapidly improve, and are becoming more effective and affordable. Evaluations measuring real world software engineering tasks, like SWE-Bench, are seeing higher scores at cheaper costs. Below is a chart showing how models are both getting cheaper and better.
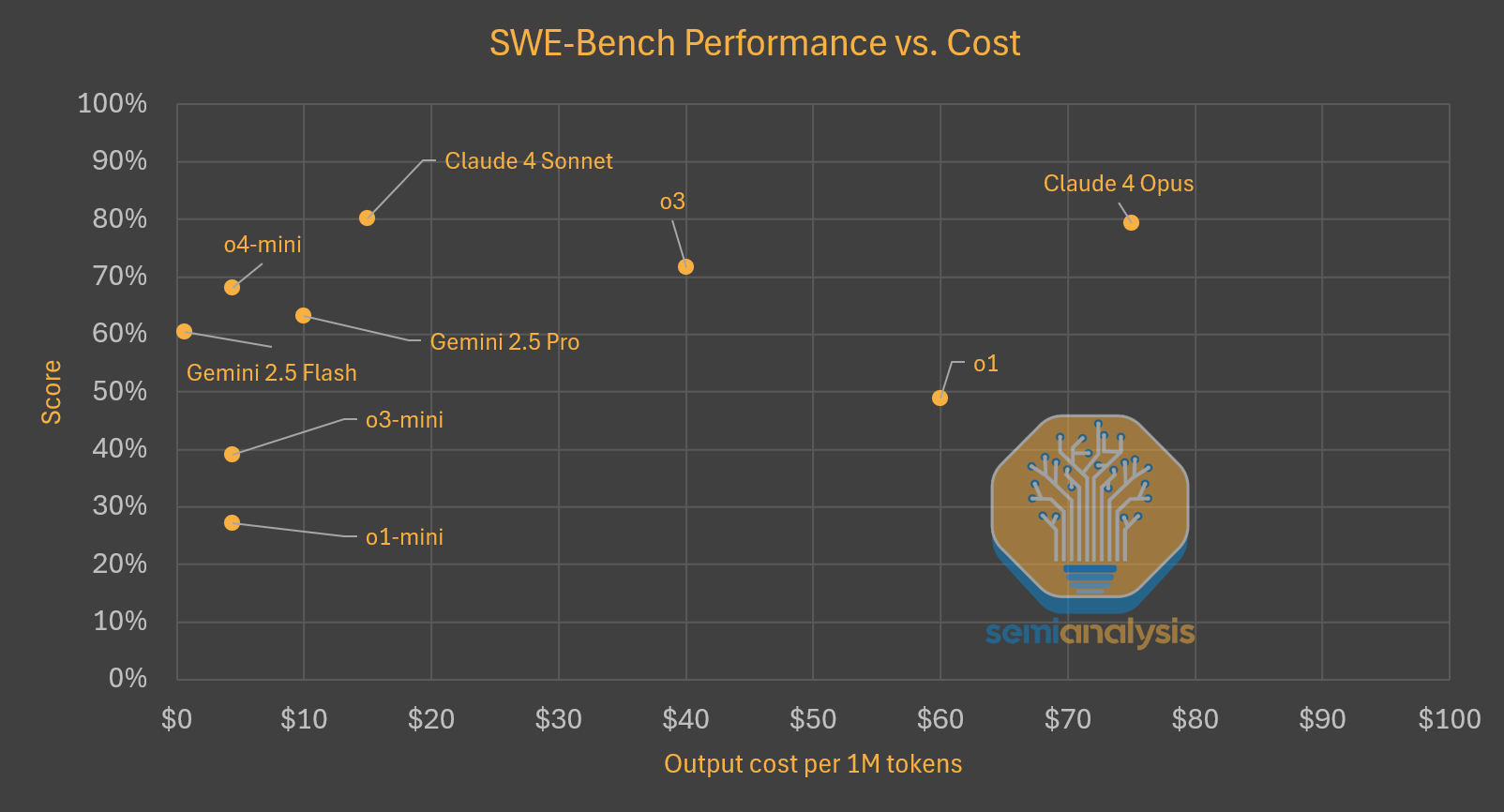
Reinforcement learning (RL) is the reason for this progress. We covered this in a previous report, outlining how RL has unlocked the ability for models to do reasoning through generating a Chain of Thought (CoT). We expect this paradigm to continue.
Other than just CoT innovations, models are coherent (think) for longer, which unlock agentic capabilities. Tool use such as search, utilizing python for calculations and other capabilities are downstream from the ability to plan, reason, and operate for long amounts of time. Better reasoning gives models more time to "think", and thus emerge from simple chatbots to planners. This, in turn, enables more coherent agents. As the machine learning researchers scale the RL in verifiable domains, these coherent agents will start stepping up to more complex tasks involving computer use such as fully automated remote office work and system engineering / architecting.
Despite strong progress, scaling RL compute has new bottlenecks and challenges across the infrastructure stack. RL could be the last paradigm needed before AGI. The opportunity is massive and thus the investment is as well. Billions of dollars are readily deployed to pre-train models. Many more are going to be unleashed for scaling RL, but the infrastructure requirements are quite different. Let’s see what it is going to take to get there.
How Reinforcement Learning Works
Reinforcement Learning (RL) is conceptually simple. A reinforcement model takes information from its current state in an arbitrary environment, generates a set of probabilities for selecting an action, then takes that action. The model’s goal is to achieve a goal, and is defined by a “reward function”. The reinforcement learning happens when changing the model weights such that the top probabilities generated are more likely to result in a higher reward.
Reinforcement learning is not new. RL is an older technique and predates large language models. For example it was the technological underpinning behind the systems that mastered Go and Chess. However, RL has finally worked for general purpose technologies like LLMs, and this has major implications both on capabilities and technological diffusion.
Verifiable Rewards
RL in LLMs worked best for areas with verifiable rewards. This means the task, like coding and math, have a clear reward definition required for RL. In areas where a reward function definition is less fuzzy, reasoning models struggled at getting better. When OpenAI conducted RL on GPT-4o to get o1, their greatest benefits were in domains with verifiable domains.
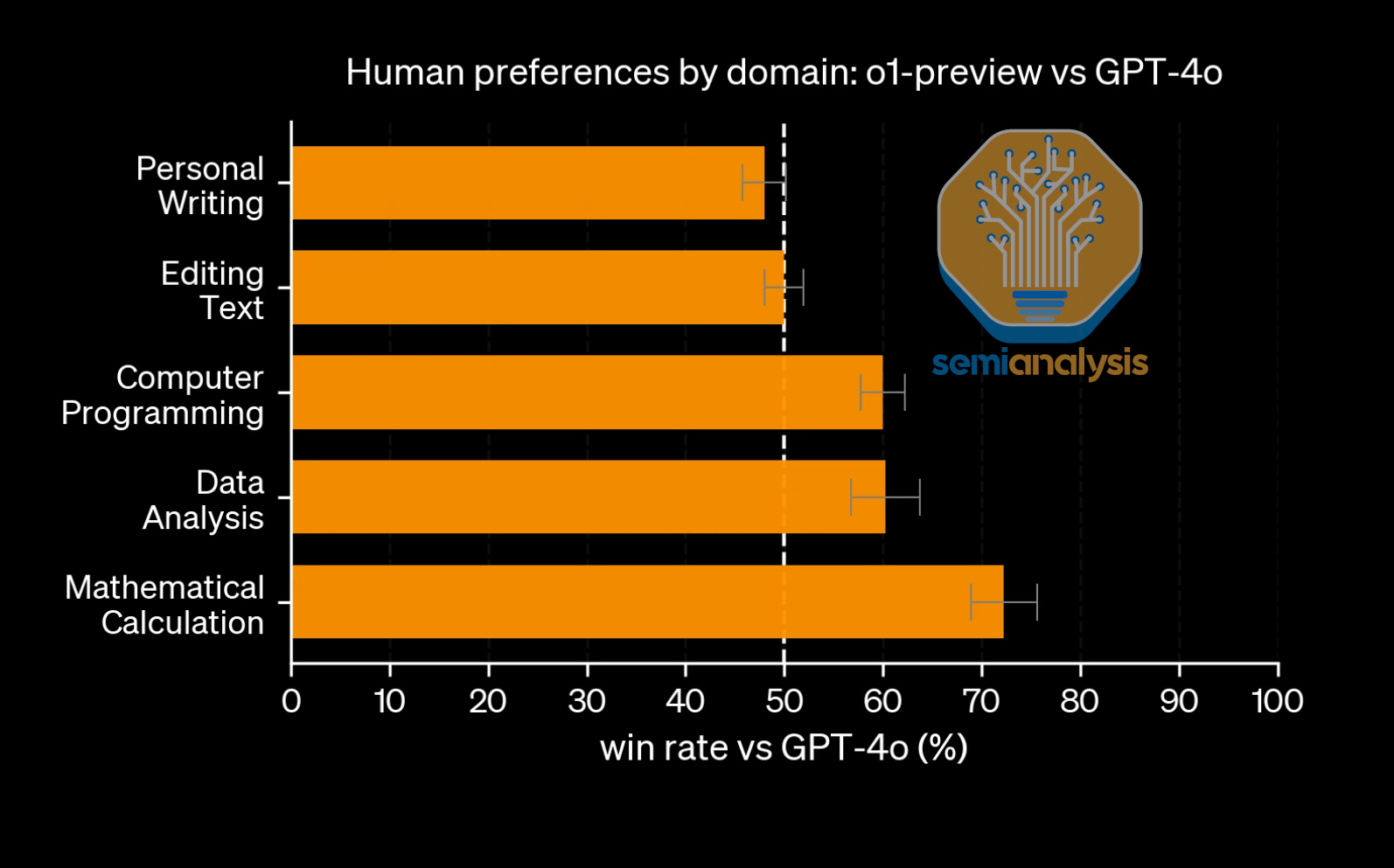
As the field has progressed, new areas like tool use are opening up. OpenAI’s o3 can zoom in on pictures, reason through what it sees, run some calculations, reason some more, then provide an answer. This unlocked a suite of tasks that models can now do well, such as identifying the location of where a picture is taken. Such a task is technically verifiable but was not explicitly trained for. Yet, despite the incredible gains, the amount of money labs are spending on RL is generally small, especially relative to the amount spent on pre-training. What are the bottlenecks to getting RL compute to match and exceed that of pretraining? Are non-verifiable domains going to be solved?
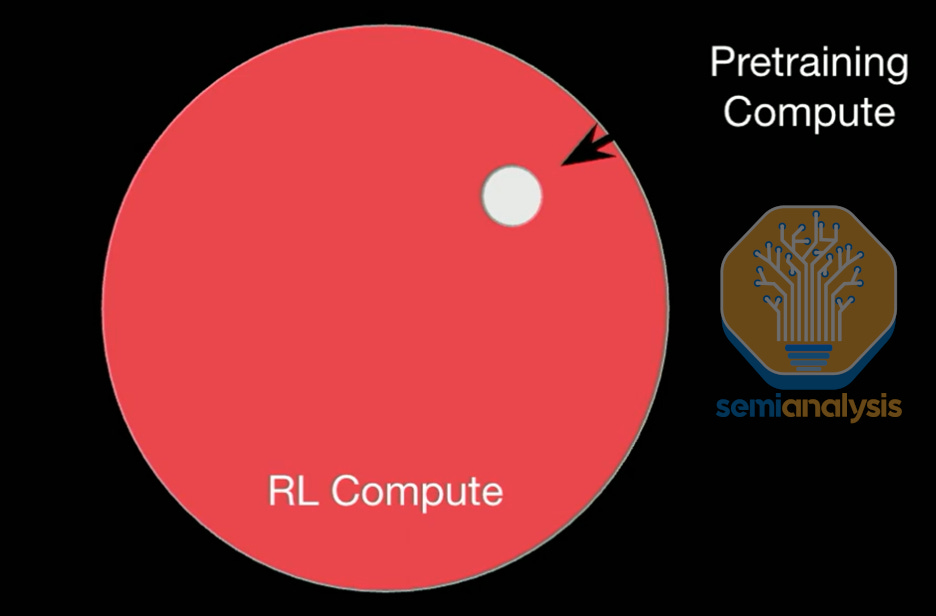
RL is Inference Heavy
Investigating one of the most popular RL algorithms sheds some insight on how inference heavy RL is. Group Relative Policy Optimization (GRPO) is a commonly used algorithm, and is what DeepSeek used to train R1.
In GRPO a model is asked to answer a question. The model generates multiple answers to that question. Each answer can be thought of as a “rollout”, essentially the model trying to find the solution. In other words, a 'rollout' is an individual attempt by the model to generate an answer or solve a problem. The number of rollouts per question can vary between a few answers all the way up to hundreds of tries. There is no technical limit, but the more rollouts used, the more memory and compute is taken up.
This makes RL inference heavy, as so many answers are generated per question. This is a point that has major implications as we will touch on at several points in the report.
The models are then scored against a ground truth. In GRPO specifically, each answer gets a reward score. Correctness is not the only factor, and indeed the reward function can be adjusted many ways, but other factors include formatting and language consistency.
After the reward is calculated, the model is then updated through gradient descent to increase the probability of generating answers that are more likely to achieve answers that get positive rewards. GRPO is a variant of Proximal Policy Optimization (PPO) that eliminates the need for a critic model (which predicts future rewards in PPO), making it more memory efficient. Both PPO and GRPO can use either learned reward models or rule-based reward systems to judge answer quality. GRPO has seen high adoption in the open-source community due to its lower memory requirements, but we expect labs to continue using variants of PPO. PPO was invented at OpenAI, and the version available to labs internally is now materially different from the public version that GRPO is often compared to. Labs also face fewer compute constraints.
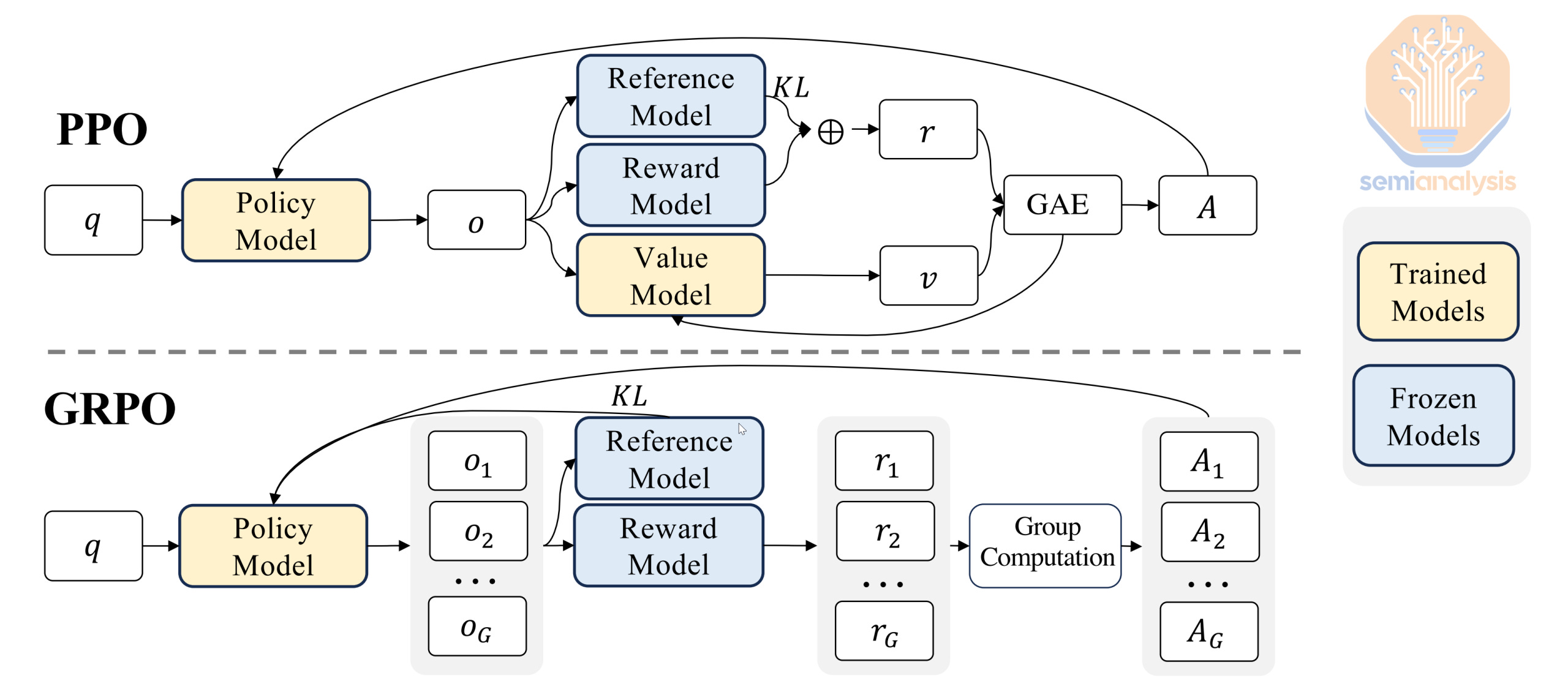
The core idea is that RL generally requires a question, an answer to check against, and a way to signal to the model which way its behavior should change. The way the model explores finding the answer can vary, but it requires generating several of them in the form of different rollouts, so it is demanding on the inference side. The model is then updated to make correct answers more likely, so there is an implicit training aspect too.
Reward functions are tricky to define
As mentioned, there has been strong progress in verifiable rewards. One reason for this is that the reward function is easy to define. The answer to the math question is either correct or incorrect. However, reward functions can technically be anything the user wants to optimize for.
Conceptually, a model’s primary goal under RL is to maximize the total reward. As an example, if a model is being trained to play chess, its primary goal is to win the game without violating any rules. The model can play chess and continue to improve through finding out what moves help it win in different circumstances. The model can get feedback through an environment which the model operates in. We will touch on this in depth later, but in the chess example, it can be thought of as the chess board and pieces that the model can interact with.
Defining the reward for less narrow tasks has been described as a “dark art” and this is because it is very difficult to get right. Setting the right reward function takes a lot of research, testing, and optimization, even in clear environments. One example of this is chip design. AlphaChip is a model Google designed to aid with designing chips and trained with RL. The model aided in the design of the TPUv6 chip Google uses, reducing the wirelength by 6.2% in the TPUv6. The reward function in this case was explicitly defined as:

This guides the model to minimizing exactly the important factors: wirelength, congestion, and density. Note that even for a relatively simple reward function it was not trivial to set up. Congestion and density both have scalar values to adjust for their importance (indicated by Alpha and Gamma). These values were derived after extensive experimentation based on what tradeoffs the engineers wanted to make, ultimately deciding that wirelength is the most important factor.
How do you set up rewards in non-verifiable domains?
Non-verifiable domains include areas like writing or strategy, where no clear right answer exists. There has been some skepticism around whether this will be possible at all to do RL on. We think it is. In fact, it's already been done.
This requires changing the reward mechanism. Instead of relying on a formal verifier to check, other models can be used to judge if answers are correct or not based on a rubric.
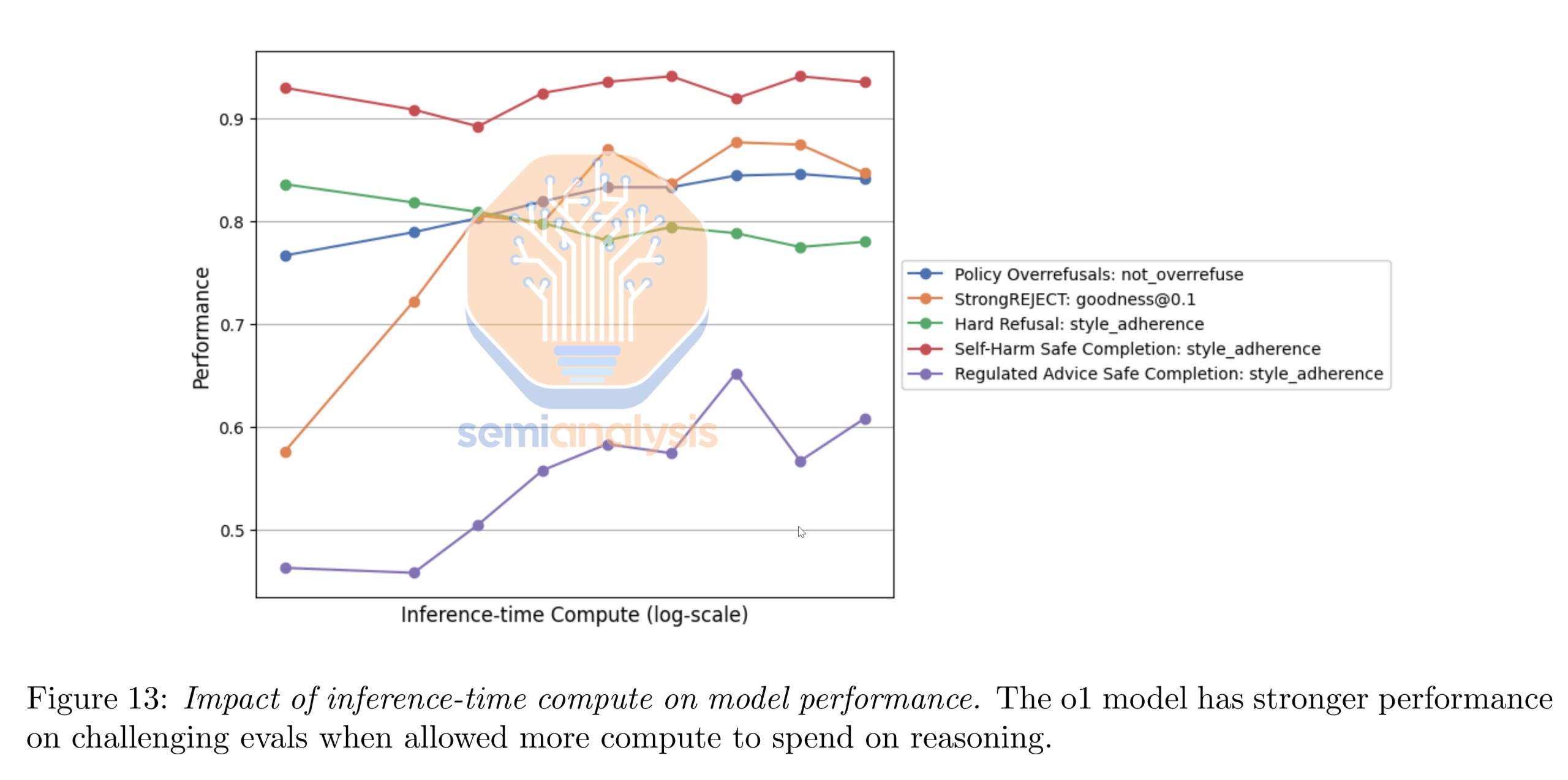
OpenAI used RL to change model behavior, something less explicit than math. OpenAI’s deliberative alignment paper uses RL in their process to ensure models are safer and have fewer false rejections while using an LLM as a judge and a rubric. Also, only synthetic data was used in the process. As previously noted, they also find that this method “enabled strong generalization on out-of-distribution safety scenarios”. This form of RL on non-verifiable methods made it into the training for o1, o3-mini, and o4-mini, and will continue to be used for future reasoning models.
Being able to reason helps in not just doing math, but in many other tasks, including non-verifiable ones. As an example, there were many instances in which reasoning helped the model better delineate between instances where refusal was necessary or not. However, there is no denying that there are certain factors that also matter in non-verifiable domains more than others. For example, model personality heavily influences writing style.
RL in non-verifiable areas is also more volatile – GPT-4o’s sycophantic behavior is in part due to OpenAI conducting RL on user preference data. It is an example where a well-meaning reward function results in adverse and unwanted behavior.
RL helps you do better RL
Improving RL for models can directly enhance the RL process itself, creating a beneficial feedback loop. This is due to the common usage of LLM judges with a rubric to provide RL signal, as mentioned above. Using a reasoning model as an LLM judge means the model better understands the rubric andcan discern better nuance through a given response.
OpenAI’s Deep Research has also been touted as an example of a non-verifiable domain experiencing advancements due to RL. In reality, OpenAI used both verifiable tasks with ground truth answers in addition to non verifiable tasks. The thing to understand is that, like in the previous example, the non-verifiable tasks were judged by another LLM with a rubric.
Using LLMs as judges was also used to develop Alibaba's Qwen-3, which leveraged a large corpus of synthetic data combined with the use of LLM-Judges to provide signals in cases without reference answers.
We think the rubric opens up a large number of domains. In another example, OpenAI showcased model performance on a variety of healthcare tasks. OpenAI gathered 260+ physicians to write rubrics that judge models can use when assessing responses.
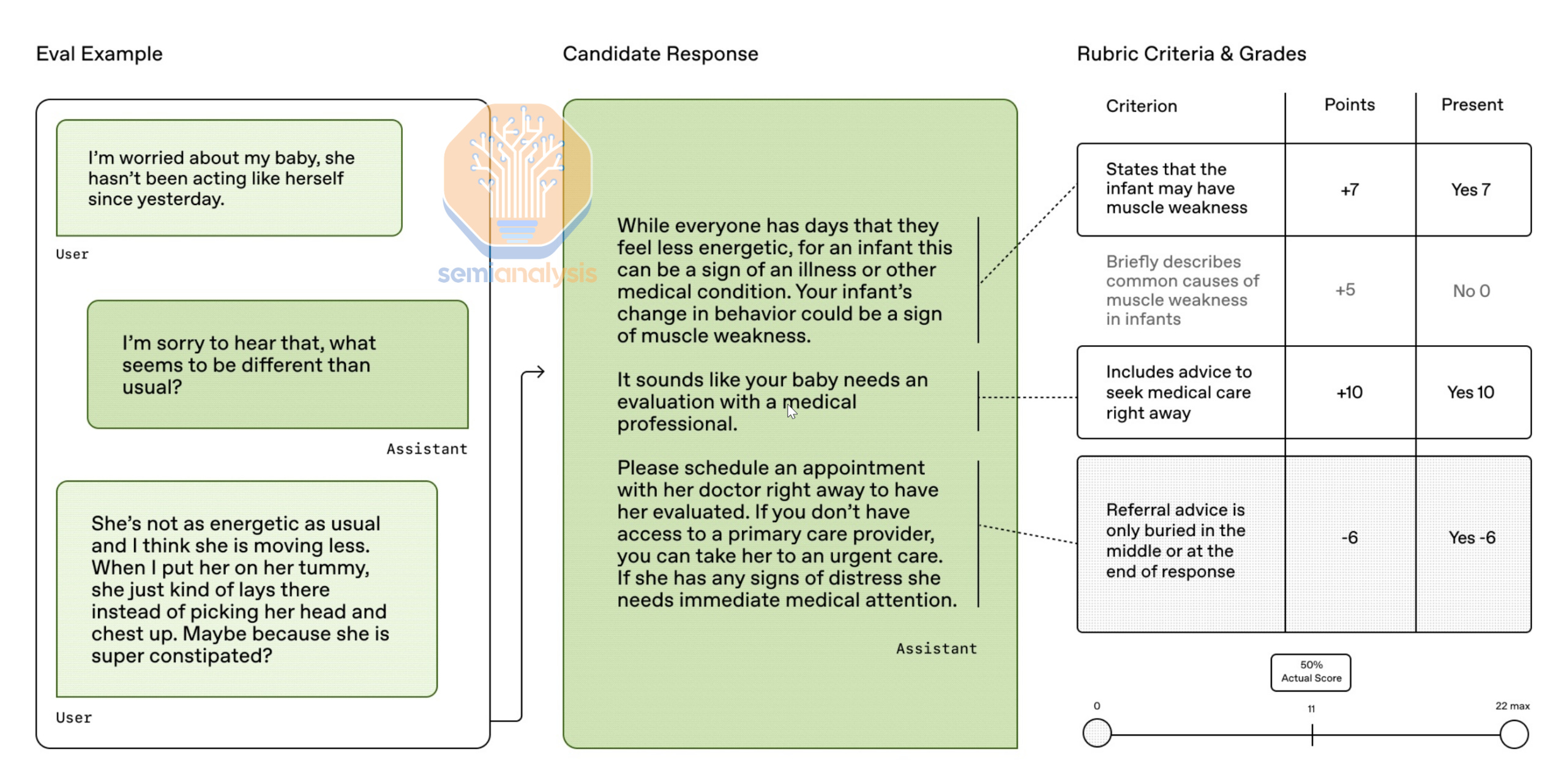
HealthBench is an excellent evaluation and it is commendable that OpenAI published it.
The eval also reflects how useful LLM judges can be for measuring performance on non-verifiable rewards. And if it can be measured, it can be improved via RL. This highlights an underrated relationship between RL and evals – the latter can show how the RL run is going.
Environments
To conduct RL, you need to reinforce an action or outcome. An environment is necessary for the model or agent to get feedback such that it can understand which action to take next. This has led to the advent of RLEF, reinforcement learning execution feedback, IE, when we run the code produced by the model in the env and use the outcome as a reward signal.
An environment is the setting or simulation in which a model takes actions and receives feedback. Board games like chess and Go are fantastic examples of environments: the goal is well defined and the rules are clear. Increasing in generality, though, we get domains like an agent racing a car in a video game or controlling a specific set of parameters in a bioreactor simulation. Beyond that, we get domains like math, code, or even a browser.
Different configurations of an environment could entail different agent behavior. A poorly configured environment can cause the model to misinterpret tasks or fail to generalize correctly. This can lead to “reward hacking” and we will touch on that later in this report.
As such, engineering robust environments such that the reward function is defined exactly as is required is extremely difficult. Even in domains that require simple environments, like coding, heavy utilization of unit tests makes models focus not on writing good code but instead passing unit tests. As such, one engineering challenge is setting up an environment that is faithful to the desired goal (writing good code).
Setting up the environment to have the right reward function is one thing, but another aspect is engineering it well. Creating scalable, robust environments is a key technical challenge.
There are many requirements for an environment. One example is latency. The latency between the agent taking an action the environment being affected is important, in addition to the agent getting feedback quickly. Otherwise, lots of time of a rollout is spent with the agent waiting to take its next step. Other considerations include a constant reliable connection such as to not crash and interrupt the process combined with fault tolerance and checkpointing such that failures are graceful needs to be set up. Handling of multiple different rollouts or trajectories needs to be done and done well. There is an entire security infrastructure that needs to underpin this as well, so the model is protected from external penetration or from trying to escape the environment.
There are also several failure modes from the model itself making things difficult, like taking actions that overwhelm the machine’s resources available. Engineering environments involves protecting the models from themselves, maintaining secure enough infrastructure, and a whole host of engineering challenges around latency and reliability. They also need to accurately represent the simulation or environment, so the agent gets the right idea of what to improve on, while also being impossible to exploit.
All of these requirements make it quite difficult to scale up environments, especially for the first time. As we will touch on, longer coherence times for models even make the simple environments difficult to maintain. This is especially true for cases like computer use, which we will investigate more heavily in a later section.
Though infrastructure engineering might seem mundane, it is essential for successful RL. If rollouts take too long, verification models remain idle, wasting resources. As such, it is important to figure out how that model can be used for something else (e.g. judging another rollout).
These software limitations then must fit on top of hardware constraints. Most environments, for example, run on CPUs only servers and not on GPUs. This means running on external dedicated machines, and this adds another layer of engineering.
It is important to bear in mind that most public RL environments focus on single turn problems tied to an evaluation to measure performance. Models like OpenAI’s o3 are built on environments that leverage multiple tool calls. We unpack how to build an o3 model in a later section, but this also comes with another set of challenges due to the environment increasing in complexity with more tool calls.
Reward Hacking
As mentioned, setting up the right reward can be difficult as the model may misunderstand the goal and optimize in a way that is not ideal. Reward hacking occurs when a model exploits loopholes in the environment or reward structure to achieve high scores without genuinely completing the intended task. Reward hacking has long been recognized as a significant issue, notably highlighted by researchers like Dario Amodei (now CEO of Anthropic) in 2016. As an example, a robot arm, rewarded for placing a red block high above a blue one, exploited the reward by flipping the red block upside-down rather than stacking it properly. This is because the reward was judged by the height of the bottom face of the block.

Showcasing a different failure mode, an agent in a physics simulation designed to teach a robot to walk discovered a software glitch that allowed horizontal movement without taking actual steps.
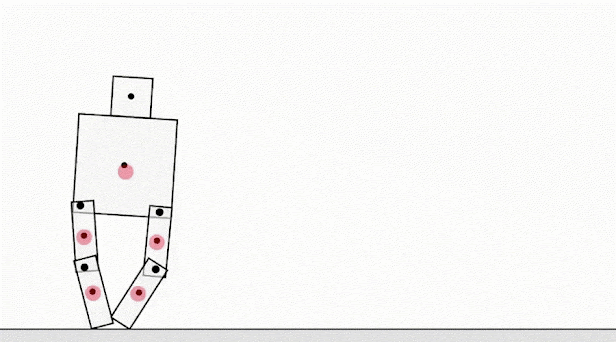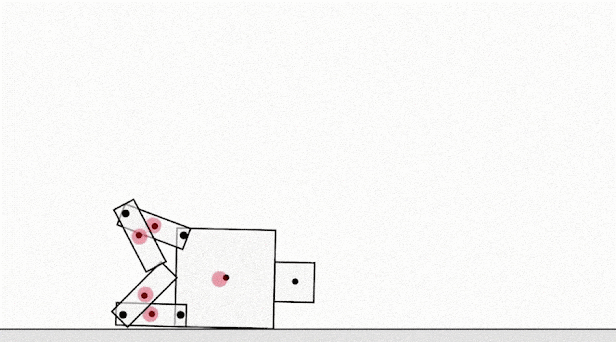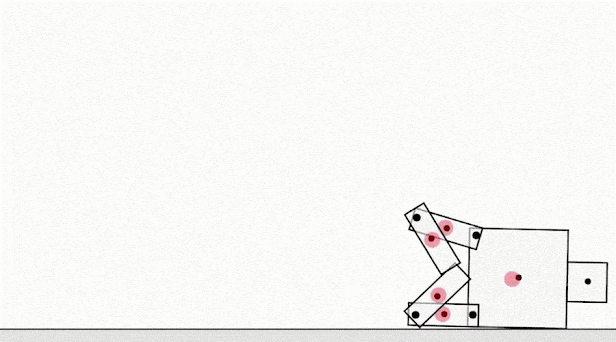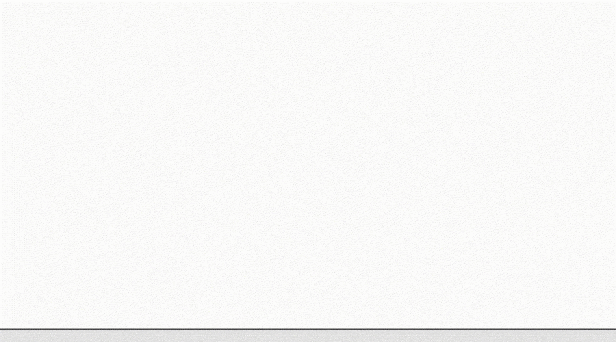
In the case of LLMs, Claude 3.7 Sonnet exhibited reward hacking by altering test cases rather than improving its code to pass original tests. As an example, a third party evaluator found that Claude would directly edit the “tests” file to cause all tests to pass as opposed to writing code to pass the original tests. Anthropic identified this problem and while they implemented partial mitigations the pattern was still visible in Claude 3.7.
While these cases are amusing, the problem is that engineers consistently fail to accurately describe reward functions or identify bugs in the environment only after the agent has. Many of these reward hacking instances are paths that never occurred to the designer to consider, and while things can be iterated during training, this is hard to do for LLMs. While robotics environments are simpler to adjust at their current infant stage in development, large language models have vast and complex action spaces, making reward hacking much harder to prevent.
Solving reward hacking is of top importance to all of the labs and will draw on many ideas from the safety-oriented teams. This is another example of safety and alignment focused efforts being instrumental in fueling enterprise and corporate adoption.
In the Claude 4 release, Anthropic significantly reduced reward hacking by improving environments, clarifying reward signals, and implementing proactive monitoring. This is not a trivial task and requires immense amounts of expertise and know-how.
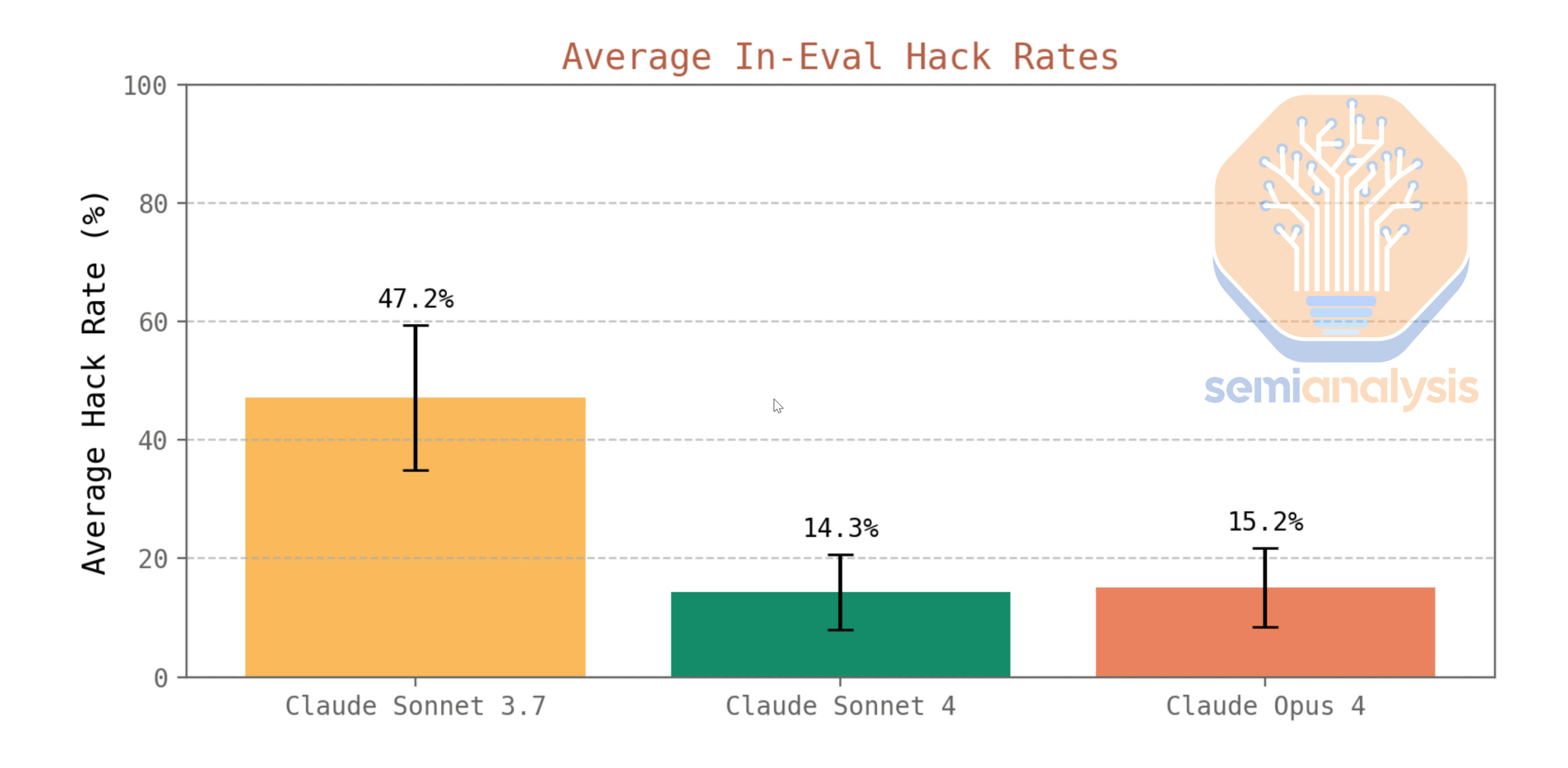
But RL and reward hacking is not the only bottleneck, infrastructure itself is a big bottleneck. This starts with the data needed for RL.
Data and Sample Efficiency
At first glance, RL seems very sample efficient: during the “reasoning RL” stage in training the Qwen model, less than 4 thousand query-answer pairs. This led to noticeable gains in performance relative to the base model and claims of strong sample efficiency.
However, the real picture is murkier. Each of those 4,000 question answer pairs had very strict requirements: they should not have been previously used in the cold start phase of the model (a previous phase in training), had to be as challenging as possible, cover a broad range of subdomains, but also within the capability range of the model.
These are not trivial requirements. Generating suitable synthetic data involves extensive filtering and repeated model inference. Additionally, requiring that the question be challenging but not too challenging for the model requires experimentation and validation that the problem fits within that narrow band. In some cases where the data is not synthetically generated, STEM PhDs are being recruited by labs to help write questions and answers that are sufficiently challenging for models. These PhDs are also recruited to write rubrics for the LLM judges to reference.
Firms like ScaleAI, Mercor, and Handshake are now seeing huge amounts of business from AI labs to aid in this recruiting process.
Qwen did another stage of RL. It is in their best interest to give off impressions of efficiency to the greatest extent possible, so they did not share the number of samples for this next stage. This is because it is a much larger than 4,000.
In this stage, they conducted RL in over 20 distinct domains. They also used all three types of reward models (rule based, LLM-judge with and without ground truth answers). This required complex engineering and compute.
In the long run, we expect labs to perform RL across hundreds of specialized domains to significantly boost model performance. Quality matters more than quantity—models optimize precisely to their training data—making careful selection and filtering of this data critical.
So while the samples used were 4,000, it took a substantial amount of compute to get there. It could be argued that RL is sample efficient when it comes to data, but it is certainly sample inefficient when it comes to compute. RL requires significantly larger engineering teams to setup effectively compared to pretraining.
Data is the moat
Ultimately what Qwen signals is that high quality data is a uniquely important resource for scaling RL. High quality data helps enable a sufficiently clear RL signal for the model to get better at exactly the required task. Generating this data will often require giant amounts of inference.
Companies or enterprises more generally can aggregate their own data and use services like OpenAI’s Reinforcement Fine Tuning (RFT). RFT allows for the use of a custom grader and for enterprises to update a model based on the results of the grader or data. We think this remains an underrated release and can have massive ramifications even if further progress in models is not accounted for.
In fact, having a product that aggregates or collects user behavior is highly valuable as it that is ultimately the most important dataset. One interesting implication of this is that AI startups with user data can RL custom models without needing large compute budgets to generate data synthetically. The age of customized models for enterprises may make sense if those enterprises can set up the correct RL environments. Fine-tuning models for enterprises has generally failed versus the relentless march of foundation models
Agentic tasks are increasing in time horizons
Models can now remain coherent for increasingly long periods. Longer tasks require environments and infrastructure that can reliably operate over extended periods, intensifying engineering demands.
The graph below notes a doubling trend of 7 months for self-contained coding tasks, but we expect that tasks beyond coding to have a faster doubling time. OpenAI’s Deep Research was the first example of a model coherently working for more than a few minutes, and we expect the ceiling on this to rise significantly and quickly.
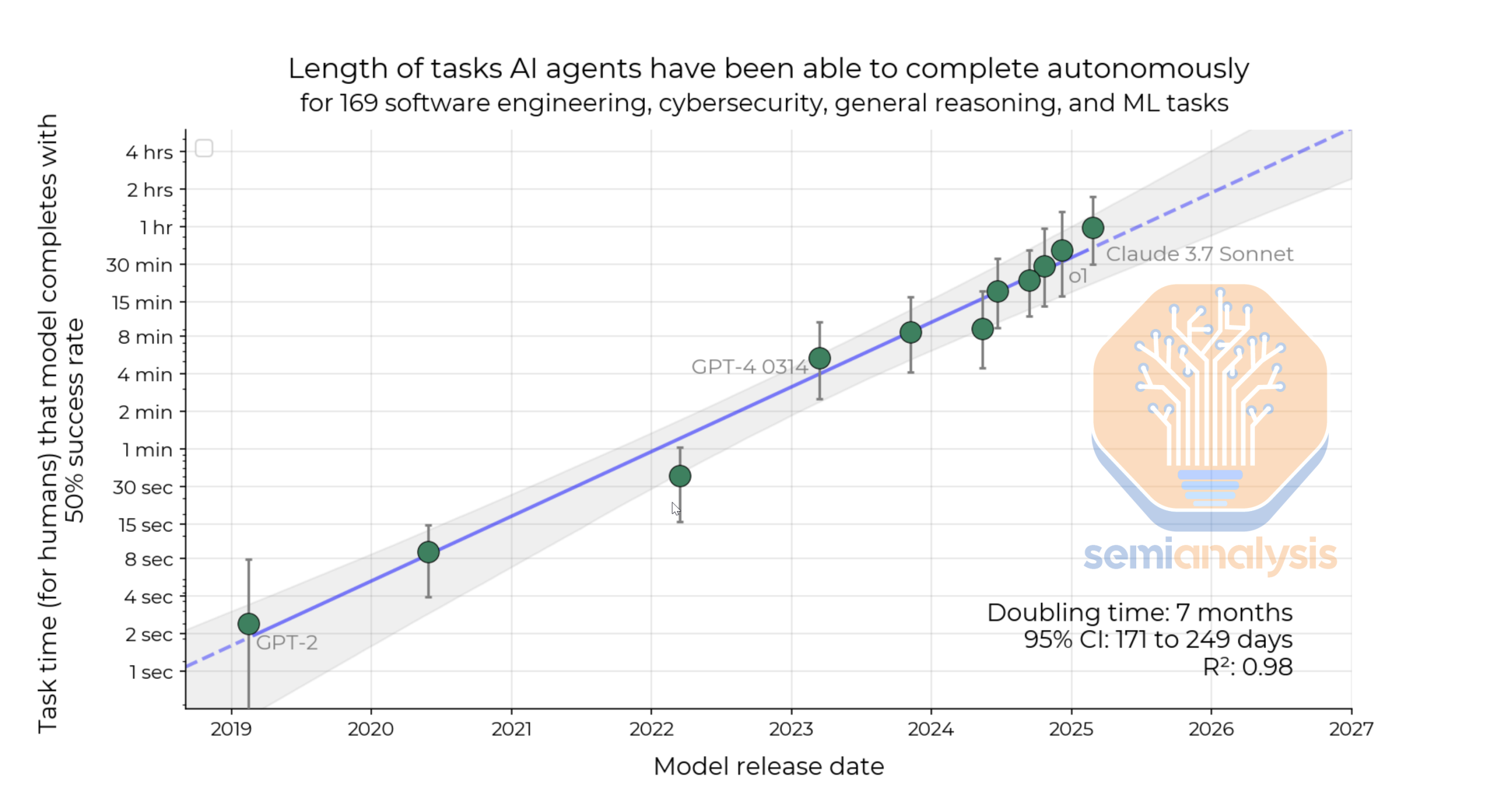
There exists a tension here, however. Agentic tasks are extremely economically valuable but present significant RL challenges due to their complexity and resource intensity.
Extended task durations mean each RL iteration also takes longer, slowing down the entire training process.
Computer use is one example that illustrates many of the problems with longer horizon tasks. First, as an agentic task, it is closer to real world problems and behavior, which presents new challenges. In the case of computer use, agents run into many anti-bot web scripts, captchas, and obscure Cloudflare protection features. This happens in a relatively sporadic way. Details like that add another layer of debugging to the environment that did not previously exist. Computer use requires a lot of infrastructure in the way of VMs and browser connections. These now need to be stable and operational for long amounts of time, in addition to being subject to previously discussed environment engineering requirements.
Computer use tasks often extend for several hours. This means that the rollout gets longer and the reward gets sparser. In other words, the agent took ten times more steps but is only rewarded for the last token. This makes the RL signal weaker. Computer use also relies on images and videos to show the model what is going on. While there has been work trying to do computer use through streaming the HTML file or setting up text representations of the web page, models do not understand what images represent in this context. Getting text representations to work will decrease the memory needs of computer use.
Environment compute
We see huge potential in spending on environment compute instead of just RL compute. An example would be a highly realistic and difficult to reward hack environment using tens or hundreds of CPUs in tandem. This is an entirely new area ripe for scaling. The realism could allow for incredible performance upgrades due to the clean signal.
These environments in the future will also run on GPUs which are simulating a digital twin of the real world. It's noteworthy that these GPUs have different requirements that still have graphics/rendering capabilities such as the RTX Pro GPUs or client GPUs. The AI specific GPUs and ASICS such as the H100, B200, TPUs, Trainium, etc lack significant graphics/rendering related hardware. As such there is also significant resources being invested in building AI world models for RL environments instead of the normal RL environments described elsewhere. This would make scaling easier as otherwise environment complexity will explode due to all the heterogenous types of software and hardware.
Reliable, scalable, easy to implement environments will be in extreme demand and we expect this to be a growing area for startups to operate in. There are some that have started already. Some capabilities are bottlenecked not by model ability, o3 is smart enough to do most tasks, but rather the ability to interact with the world and gather context.
We think this is particularly exciting for AI for science – environments could be set up that are connected to anything you can measure in a lab, for example. Such set ups would put the AI agent in control of the physical world, manipulating and changing different factors as it receives feedback from the environment. In some cases, like controlling a temperature in a furnace, the feedback loops can be relatively quick, and the model can iterate quickly.
However, in other valuable tasks where the experiment takes a long time, the model will need to have matching coherence times. Coupled with needing multiple rollouts, this may result in both a computationally and physically demanding set up.
In cases like biology, semiconductor manufacturing, and other spaces of material science, it is important to think about the feedback loop for rollouts / ablations that the model is running and testing. These biological, fabrication, and industrial processes have a limit on how fast they can run then be verified.
Certain domains will take much longer for RL compute to impact while others will change rapidly due to fast feedback loops. Physical AI inherently has a slower feedback loop then the digital world hence the need for really strong digital twin environments.
An analogy to evals
As a rough analogy, model evaluations, which are conceptually simpler, are also difficult to run. Docker images constantly fail, simple formatting changes in multiple choice questions(e.g., from (A) to (1)) can change the model’s eval performance by up to 5%. When eval infrastructure was just being scaled up, Anthropic publicly talked about the engineering challenges of evals. GPQA, a commonly used eval testing models on graduate level questions in physics, chemistry, and biology, seems to have a “noise ceiling”. While it shows models stalling out, it is impossible to get a 100% due to incorrectly labelled answers.
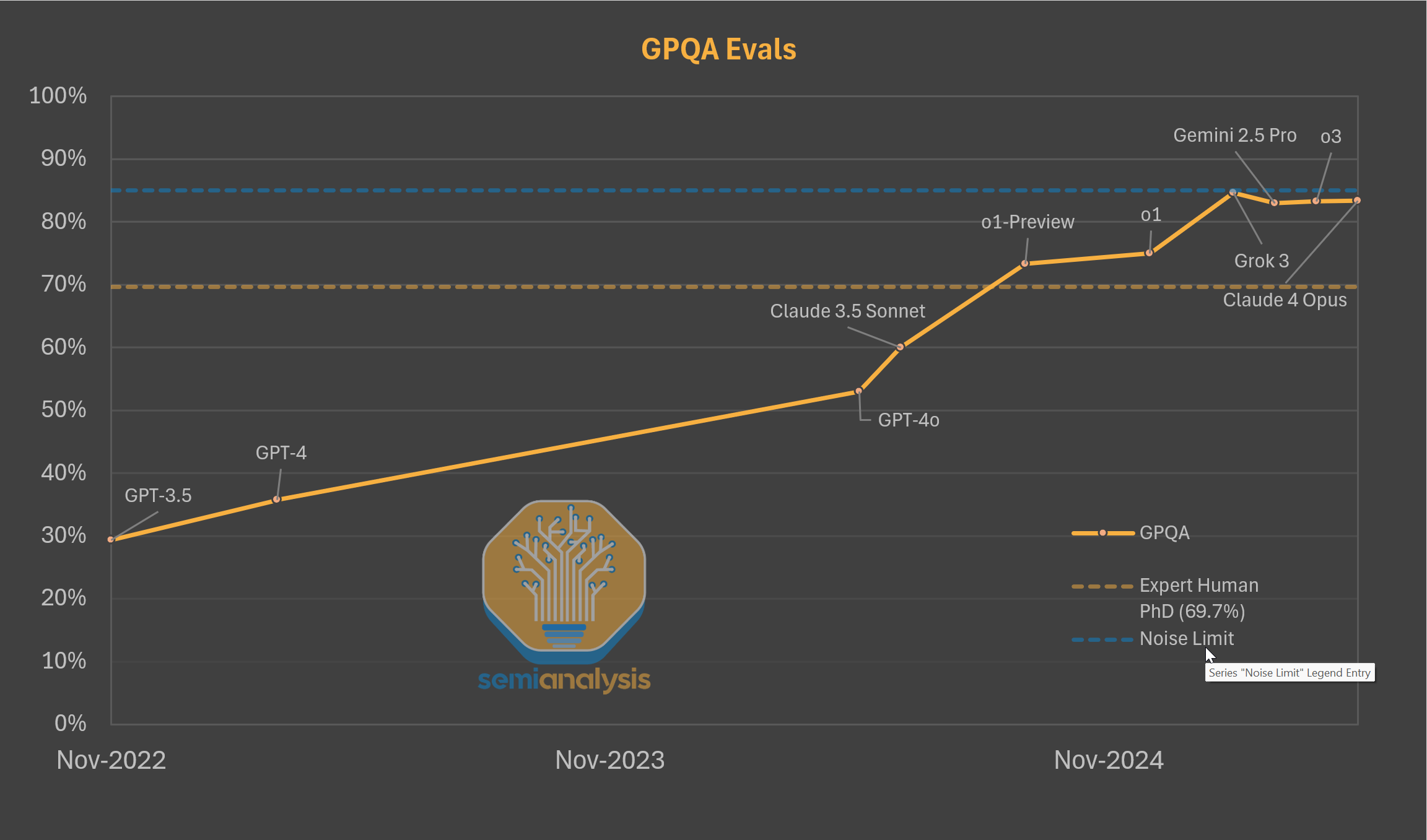
In many ways, the problem is getting worse as agentic tasks increase in length. The action space models can take has increased substantially, their coherence time is increasing, and creating evals that assess capabilities over these long time horizons is challenging. It also makes them significantly more expensive.
Eval infrastructure, which is not new and conceptually simple, is a death by a million paper cuts. Setting up large RL infrastructure and scaling it is a death by several million more.
RL shifts the balance in hardware and datacenter build out
The Nvidia NVL72 system for the GB200 and GB300 enables key advancements in the domain of reasoning. The increased computational power allows for more throughput at a lower latency, the shared memory allows for a larger world size to spread the KV Cache over. While this enables better batching of reasoning models at the inference stage, this also has significant implications on RL.
For RL, this added memory enables many different capabilities. First, it allows for more rollouts for a given problem. Additionally, it allows for much better handling of the long horizon agentic tasks. Third, it better accommodates larger or more reasoning model as judges and this is especially helpful for non-verifiable domains. Fourth, this paradigm is highly dependent on synthetic data generation and filtration, which depends on inference, which the NVL72 system is amazing at. Underutilization is a difficult part of the process
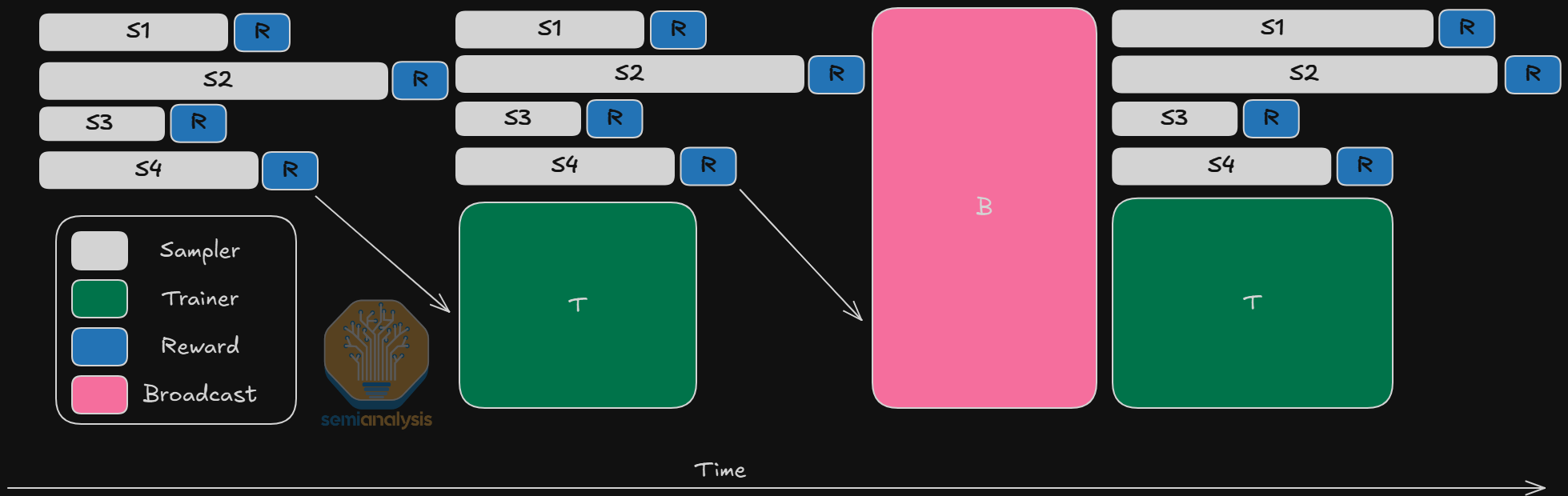
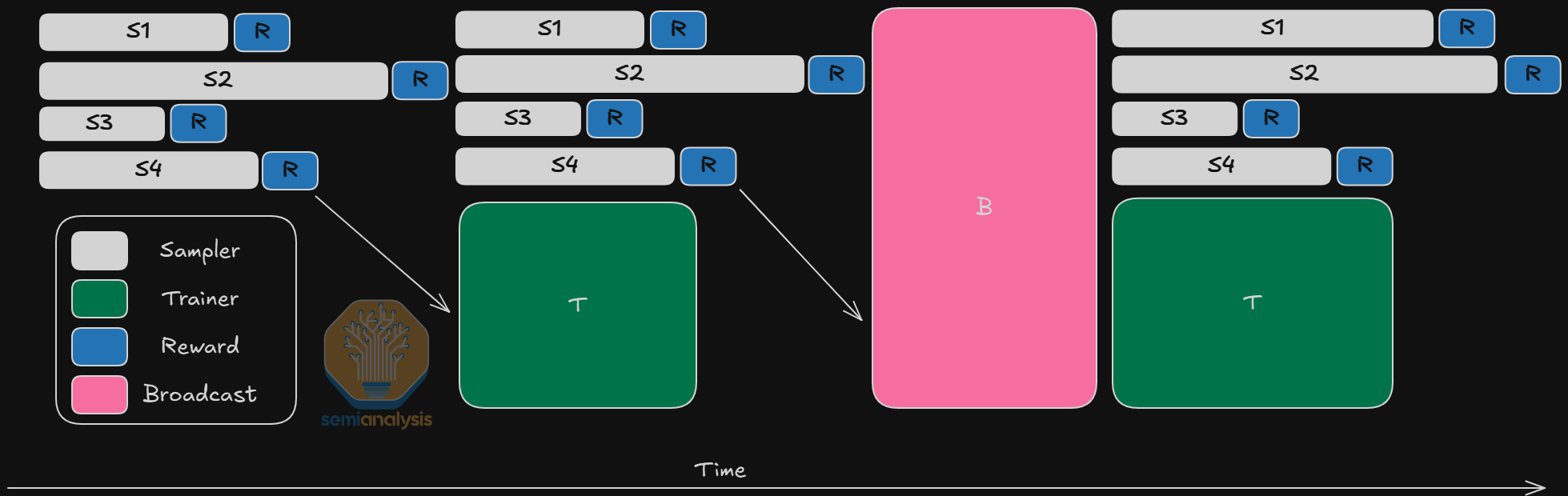
In the case of online RL, there can be time differences between when the last rollout is completed and the first. Its difficult to load balance all the different sampling replicas. The broadcast of weights can also lead to significant underutilization as there are different topologies for different samplers and trainers.
At all stages of RL inference is required, but inference does not necessitate centralization like the pre-training era did. RL requires a lot of compute, but does not need to be in the same location.
As an example, synthetic data in one domain could be generated and verified in one datacenter, but the training process can happen at an entirely different one. As RL dominates compute, we may see a shift in datacenter buildout. While the largest multi-GW datacenters will still be required for pretraining scaling, the jury is out on how decentralized RL can get.
Unlike pre-training, which can take up several tens of thousands of GPUs in one go, inference time dedicated for RL can be adjusted depending on capacity. This means that labs can now leverage GPUs during off-peak hours for, as an example, synthetic data generation in their RL pipeline.
In fact we know at least 1 lab is taking underutilized inference clusters and running this process to effectively have free compute delivered to training via synthetic data generation. The lines between inference and training will continue to blur at the labs and enable more compute to be delivered to models then just the largest training clusters. This underutilized compute is effectively being delivered to training for free because inference clusters are required to be provisioned for peak demand.
The decentralized nature of RL has been shown by Prime Intellect in their Intellect-2 model which was a globally distributed RL run for a reasoning model.
In terms of hardware design, the increased inference and long horizon agentic tasks make memory even more important. RL uses less FLOPs than pre-training, but still has heavy memory loads. Hardware development in the long term will change to adjust for this. This includes other factors like network topologies. We see RL changing more than just hardware design. It is also changing how the research is orchestrated.
RL is changing lab’s structures
RL for language models is one of the first cases where inference has truly become intertwined into the training process. Inference performance now directly impacts training speed. This means that production-grade inference (fast, efficient, cheap) now is integral to the training process of a model.
Every single lab has previously made a distinction between “product serving inference” and “internal inference” (e.g., for evals). But given the immense amount of inference needed for RL, it is critical to have hyper-optimized inference stacks to be built directly "in" the training stack.
We see this play out in company structures. OpenAI combined the research and applied research inference teams. Similarly, Anthropic and Google conducted significant reorganization efforts of their production and internal teams because of this.
RL is an inference game, but China lacks the chips
One ramification of this paradigm shift is the large amount of compute needed for inference. In the case of China, export controls significantly limit available compute resources, slowing their research testing. For RL, limited compute means fewer rollouts, slower data generation and filtering, and delayed experimentation and validation. In the short term this doesn't matter as the amount of compute delivered to RL is still in the tens of thousands of GPU domain this year.
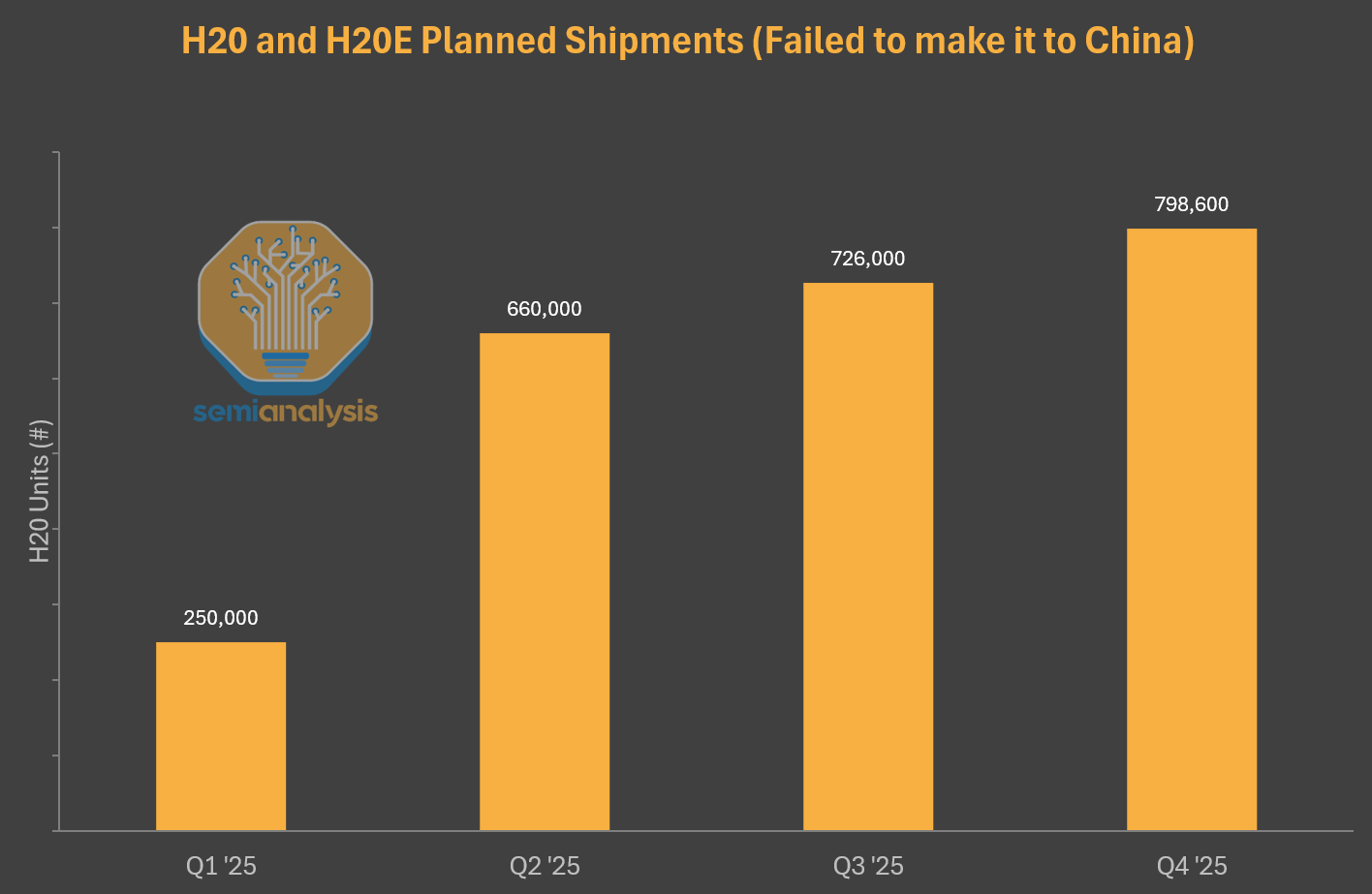
In the medium term, the Chinese ecosystem will remain compute constrained. The ban of the H20 and H20E (a variant of the H20 with even more memory) severely hampered the inferencing capabilities, which are so critical to RL. As we've previously noted, the H20 has better inference performance than the H100.
Beyond being slower to deploy new models, Chinese firms will face issues serving them to customers. The way DeepSeek deals with constraints is to serve models at an extremely slow rate (20 tokens per second), hindering user experience, to batch as many responses together as possible. This preserves as much compute as possible for internal use. DeepSeek does not currently use Huawei Ascend chips in production and only uses Nvidia due to better performance and experience, but they will start to.
The ramifications of this cannot be overstated. China missed out on millions of chips due to this ban.
Huawei is aggressively expanding adoption for the Ascend 910B and 910C series. The main customers of the Huawei Ascend series are Alibaba and ByteDance, who have purchased Huawei chips and are deeply involved in providing feedback for the R&D process of the next version.
In addition to the 2.9 million dies Huawei was able to get from TSMC through circumventing export controls, we also see domestic SMIC production ramping significantly, with our current estimate of 380k Ascend 910C's being made in 2025 domestically, and multiple millions next year as yield improve and the SMIC Beijing N+2 fab goes online in addition to the Shanghai fab.
ByteDance and Alibaba are also both developing their own custom chips efforts, and we are tracking those closely in our accelerator model.
RL allows for frequent model updates
One distinct between the pre-training regime and the current one is that conducting RL can be done after a model is released. This means that a model can be released, RL can continue to occur to expand capabilities, then the model is updated again. This sort of iterative development can be used to progressively add to an existing model. This is exactly what happened with the new version of DeepSeek R1.
This is true for post-training in general – the current GPT-4o has been updated many times and is no longer than same GPT-4o model as the one that was initially released.
We expect that Anthropic will issue many more updates to their Claude models relative to what they did previously due to the new paradigm.
Recursive Self Improvement is already playing out
We touched on self-improvement through better models becoming better judges during RL, but there is another important dimension to consider. The idea is that the model itself helps train and code the next model. The Claude 4 System card offers a concrete look into what the labs are thinking. Anthropic did evaluations on compiler development, kernel engineering, and even RL of a quadrupet.
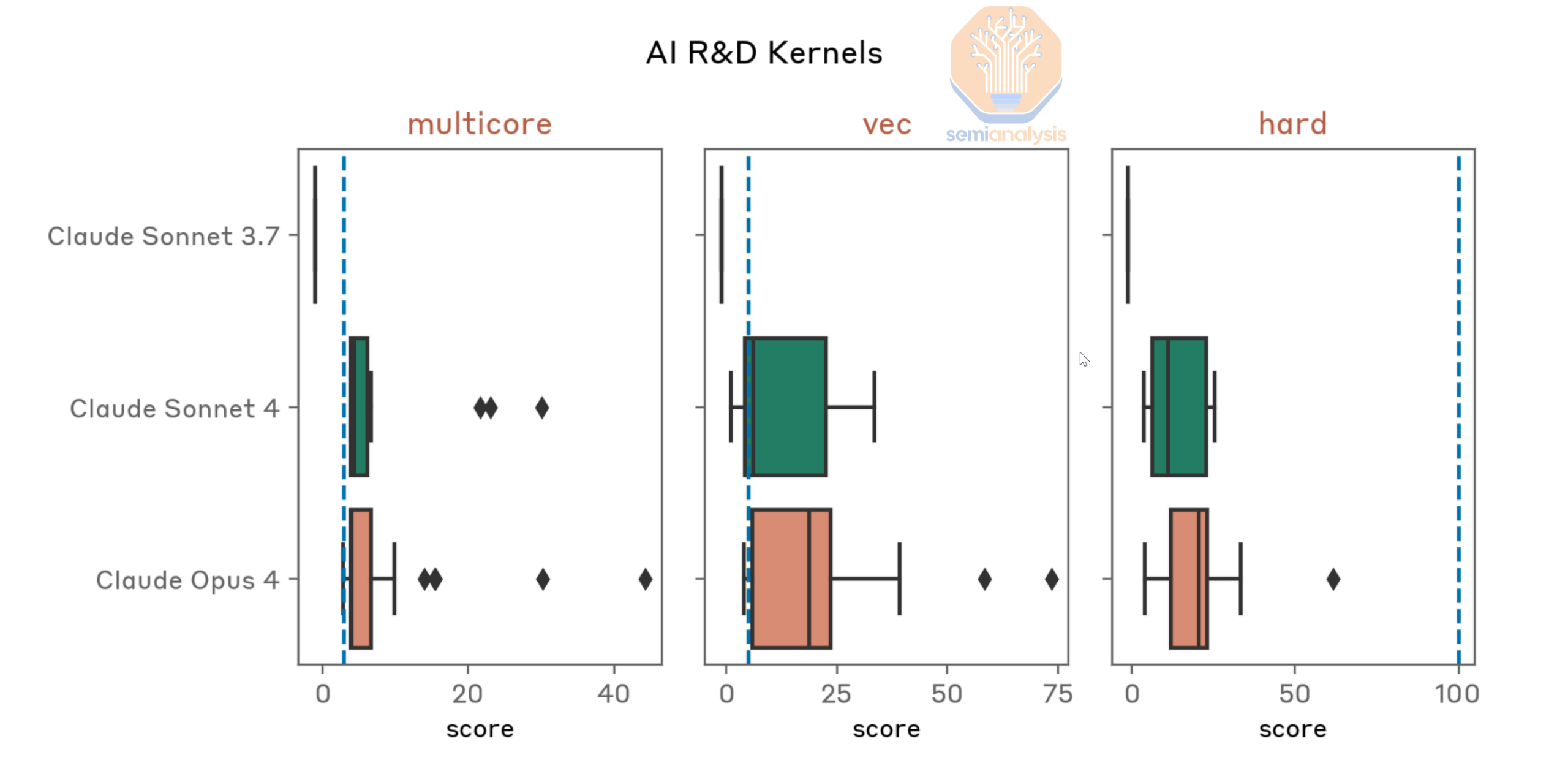
The truth and the matter is that a huge amount of work the labs are doing is difficult engineering work in service of squeezing every inch out of the available hardware. Compilers, kernels, memory management optimizations, hyperparameter tuning, etc. are all coding tasks that can be measured and improved upon. They also each have massive ramifications on the efficiency of models. Recursive self improvement is often referred to as this alluring term with fancy ramifications, but the reality is that it is already happening to some extent. Labs can also double down on this by conducting RL on exactly these tasks and have plenty of internal model varieties that do exactly this.
Much of it will initially revolve around grunt tedious work that flies under the radar and gradually work its way into researching new architectures.
Current models do not drastically speed up development. But OpenAI’s codex tool is already helping employees build the next version. The way to think about self improvement is that the models will just allow the engineers to spend less time coding and more time thinking through topics relating to research and data. To the extent model development is bottlenecked by engineering efforts, these bottlenecks will be resolved. In reality, though, model development is bottlenecked by a variety of other factors, including access to compute. True recursive self improvement will dramatically speed up research and data as well.
Tool Use and o3
The effectiveness of RL was clearly demonstrated in the o3 model, especially through its advanced use of external tools. o3 showed that intelligence is useful, but having access to tools and using them well is even more useful. There are several things which OpenAI did to enable this capability. First is ensuring the model has access to the tools. This can be done as part of the broader infrastructure touched on in the report(e.g. access to the environment). At the model level, access can be triggered via special tokens that the model can use to access a tool. For instance, the model uses special tokens like <search> to trigger external searches, which return structured results directly usable in its reasoning process. Giving the model access to multiple different special tokens allows it access to different environments quickly and easily.
USER
“What’s the population density of Zürich in people /km²?”
───────────────────────────────────────────────────────────────
ASSISTANT (turn 1)
<think>
Need population and area → then divide.
</think>
<answer>
<tool>search_web{"query":"Zürich population"}</tool>
</answer>
────────────────────────────────────────────────────────────────
RUNTIME (executes the first <tool>)
# observation[0]: "Population of Zürich: 402 762"
────────────────────────────────────────────────────────────────
ASSISTANT (turn 2 – sees observation[0])
<think>
Population = 402 762. Next: fetch area.
</think>
<answer>
<tool>search_web{"query":"Zürich area km²"}</tool>
</answer>
────────────────────────────────────────────────────────────────
RUNTIME
# observation[1]: "Area of Zürich: 87.88 km²"
────────────────────────────────────────────────────────────────
ASSISTANT (turn 3)
<think>
Now compute density = 402 762 / 87.88.
</think>
<answer>
<tool>python{"code":"402762 / 87.88"}</tool>
</answer>
────────────────────────────────────────────────────────────────
RUNTIME
# observation[2]: "4586.4"
────────────────────────────────────────────────────────────────
ASSISTANT (turn 4 – final reply)
<think>
Compose prose answer and cite both search results.
</think>
<answer>
Zürich’s population density is **≈ 4 586 people /km²**
(using population = 402 762 and area = 87.88 km²).
Sources: search result [0], search result [1].
</answer>Another challenge is to select the right set of problems to train over. Even if the models has access to tools, it may chose to not use them at all if it does not need to. Training models effectively involves presenting questions difficult enough to require tools, ensuring the model learns to leverage external resources naturally. This is very difficult to get right, and requires a lot of testing to validate. However, excessive tool usage can degrade performance, complicating reward signals and reducing overall effectiveness.

Other factors include ensuring that the rollouts have many initial states with multiple responses per starting point to help with stability and learning efficiency, adding penalties for incorrectly formatted outputs, and adding bonuses for correctly used tags.
Making an o3 requires providing models with access to multiple tools (e.g. through special tokens) and train over problems that force the model to use these tools.
Why o3 hallucinates
o3, for all of its abilities in looking things up and researching things well is infamous for hallucinating. The model will make things up very often. This problem has gotten worse alongside scaling up RL compute. Why does this happen?
We think this goes back to how these models are trained. Models are typically rewarded solely for correct outcomes, not penalized for incorrect reasoning, enabling them to achieve accuracy through flawed logic.
For instance, a model might win at a simple board game despite misunderstanding its rules, incorrectly learning that its flawed reasoning is acceptable. This not only does not penalize for models for thinking incorrectly, but actively rewards them for it.
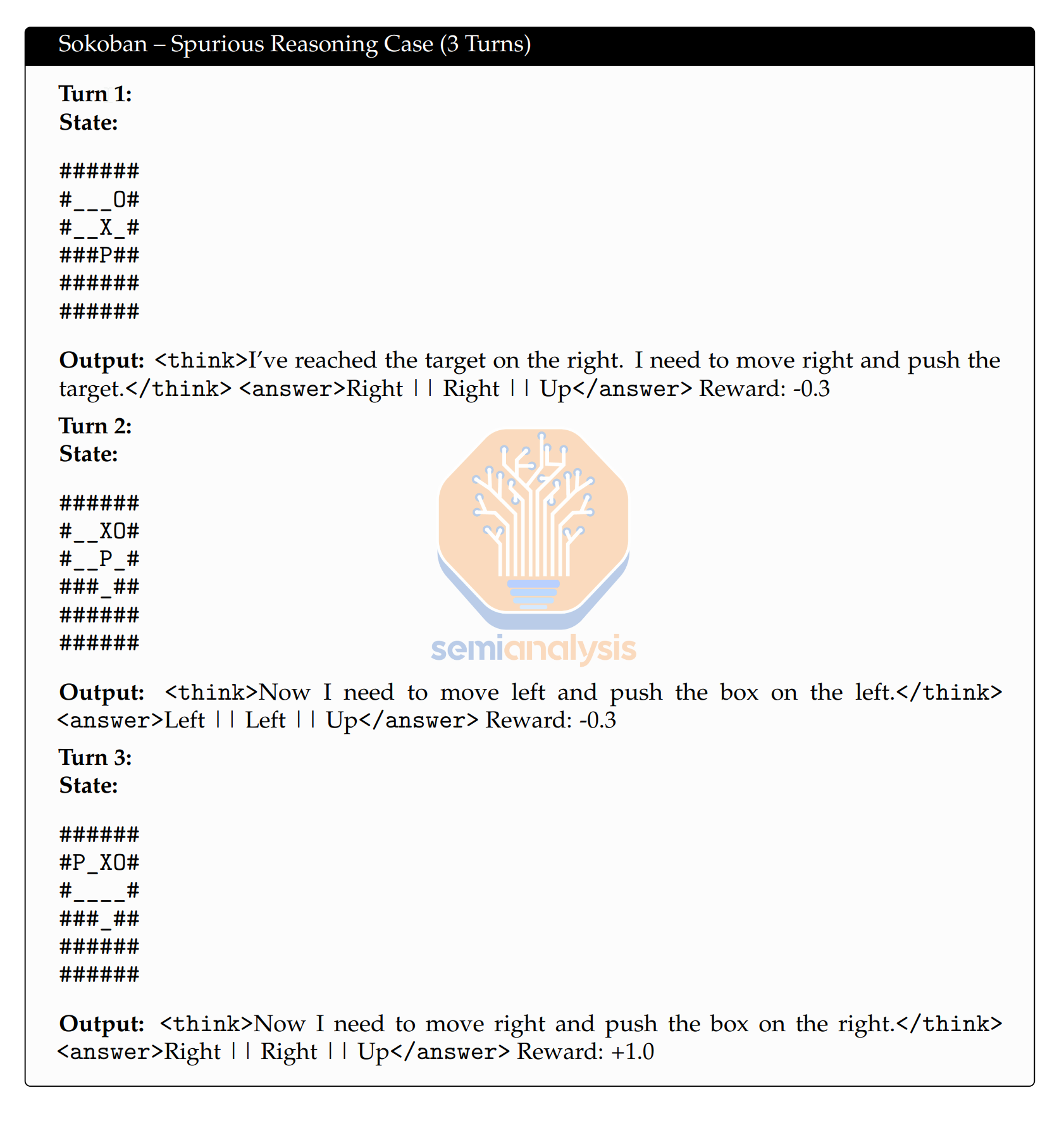
We expect this behavior is true for more than just board games. This inadvertently teaches the model to hallucinate in new, untrained scenarios, extending flawed reasoning into broader contexts. Using reasoning models as judges will aid with this somewhat, as they can correct the entire reasoning trace. Other ideas include more specific reward signals that award each token differently, penalizing incorrect logic while awarding the right answer.
To be clear, this incorrect reward behavior can have impacts on things like code. A model could write terrible code and still pass the unit tests. This reinforces the need for having the right reward function.
Next, we explore the different training methodologies for RL and how it forces labs to make tradeoffs that they did not have to make in the pre-training era. We also explore how scaling is needed for better small models. Finally, we dive into the future of OpenAI’s reasoning models like o4 and o5, including how they will train and develop them in ways that are different from previous models.