

The Coding Assistant Breakdown: More Tokens Please
Hands On With GPT 5.5, Opus 4.7, DeepSeek V4, Why Benchmarks Are Bad, and Who’s Going To Win
Since we called out the Claude Code inflection point on February 5th, we have seen a flurry of model releases. Opus, Mythos, Codex, Gemini, DeepSeek, Kimi, Qwen, GLM, MiniMax, Composer, Muse Spark, and more. Today we will break down all of these major model releases, explain when you can vs can’t trust the benchmarks, and give our predictions for the future of the agentic coding market.
First we have to highlight GPT-5.5 from OpenAI. In our view, GPT-5.5 is now materially better at some tasks than all other models. We believe that GPT-5.5 has arrived at the frontier. This is a huge change from November when Opus 4.5 was released. At that time, and for the 6 months since, OpenAI’s coding model was not world class in most metrics, leading to Opus being our daily driver. GPT-5.5 is now integrated in our daily work.
Meet the Models
There’s been at least one major lab releasing a new checkpoint purpose-built for coding every week for the past 3 months. GLM-5.1, Qwen3.6-Plus, Kimi K2.6, Composer 2, and Gemini 3.1 Pro all emphasize “agentic coding,” “long-horizon tasks,” or similar capabilities in their headlines. February was a particularly busy month.
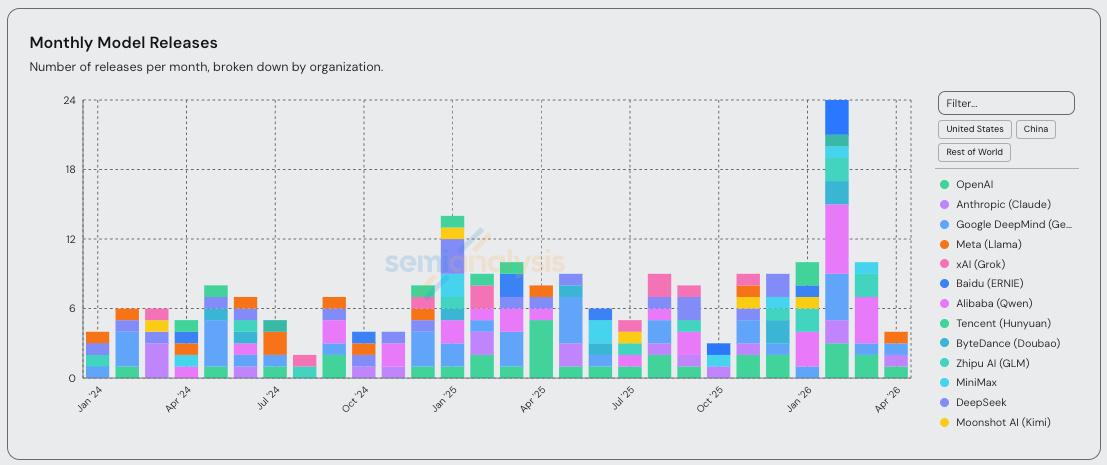
New checkpoints are cool, but entirely new pre-trains are what really get the people going. Heading into April, the San Francisco rumor mill was ablaze with talk about Capybara and Spud. These are codenames for Anthropic and OpenAI’s newest pre-trains. With the release of GPT-5.5 yesterday, we now have something concrete to discuss.
GPT 5.5
GPT-5.5 is the first public release based on “Spud”. As OpenAI’s first new scale up in pre-training since the failed GPT-4.5 (sorry garlic doesn't count), expectations are obviously high. And despite both NVIDIA and OpenAI claiming with precise language that the model was “trained” on a 100k GB200 NVL72 cluster, this “training” is post-training (RL) only. It never achieved that scale.
OpenAI’s flagship model has historically been cheaper than Anthropic’s, but at $5 per million input tokens and $30 per million output tokens, GPT-5.5’s API price will be 2x more expensive than GPT-5.4 and slightly more expensive than Opus 4.7. The API went live this morning after a brief ChatGPT/Codex-only window due to safety concerns. We’ve been testing the model via Codex and API during an alpha testing period and describe that experience later in this article.
Like all their other models, OpenAI will also be offering a priority tier for GPT-5.5 priced at 2.5x the standard rate. Figuring out how to charge users more money for faster tokens is becoming increasingly important, and it’s worth clarifying that priority is totally different from fast mode. Fast mode just makes some vague guarantees like “2.5x faster for 6x the price,” whereas priority makes more conservative, concrete SLAs (e.g. > 50 tokens/sec > 99% of the time). Both Anthropic and OpenAI offer fast mode and priority tiers, but we think Opus 4.6 Fast is the only SKU that’s gained real traction.
Separately, OpenAI also offers GPT-5.3-Codex-Spark, but that’s a totally different model built to run on Cerebras. Specifically, it is a distilled version of GPT-5.3. There’s a big difference between offering faster tokens via running smaller batch sizes, changing the reasoning depth, and routing requests to a priority queue without changing the underlying model (priority and fast mode) vs running a dumber, smaller model (codex spark).
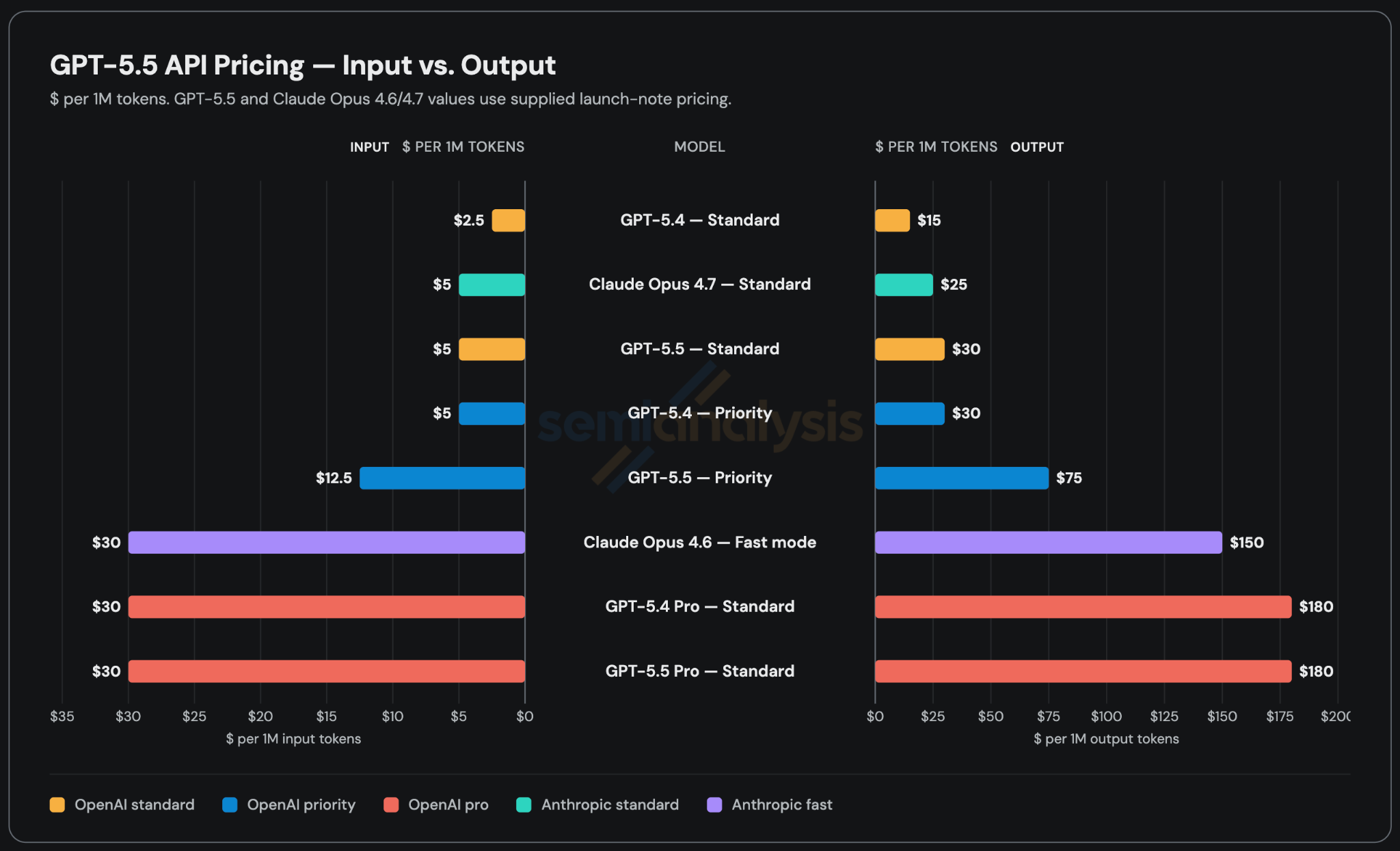
Also released is GPT-5.5 Pro, which is only available via ChatGPT and API. It’s meant for scientific research or long range reasoning tasks instead of everyday agentic work. GPT-5.5 Pro earned SOTA scores on BrowseComp and FrontierMath, and is priced at the same $30/180 as GPT-5.4 Pro. We expect to see more announcements about GPT-5.5 Pro making scientific discoveries soon.
Both the standard and pro models offer different levels of reasoning: xhigh, high, medium, low, and non-reasoning, which is a tradeoff between cost vs capability. As has been clear since the release of strawberry/o1, higher reasoning levels lead to better outputs but require more tokens and users have to wait longer for a response.
Relatedly, OpenAI advertised in their model card that GPT-5.5 scores higher on benchmarks than 5.4 while simultaneously using less tokens. In other words, it’s more “token efficient.” This is an extremely important concept to understand, and we believe it will become a major talking point this year. As we explained and quantified to Tokenomics model subscribers last week, cost per task, not cost per token, is the true north star metric that determines model pricing. Mythos may be 5x more expensive than Opus on a per token basis, but much of that price increase is nullified because Mythos can solve the same problem using fewer tokens. It may also be a faster end to end response.
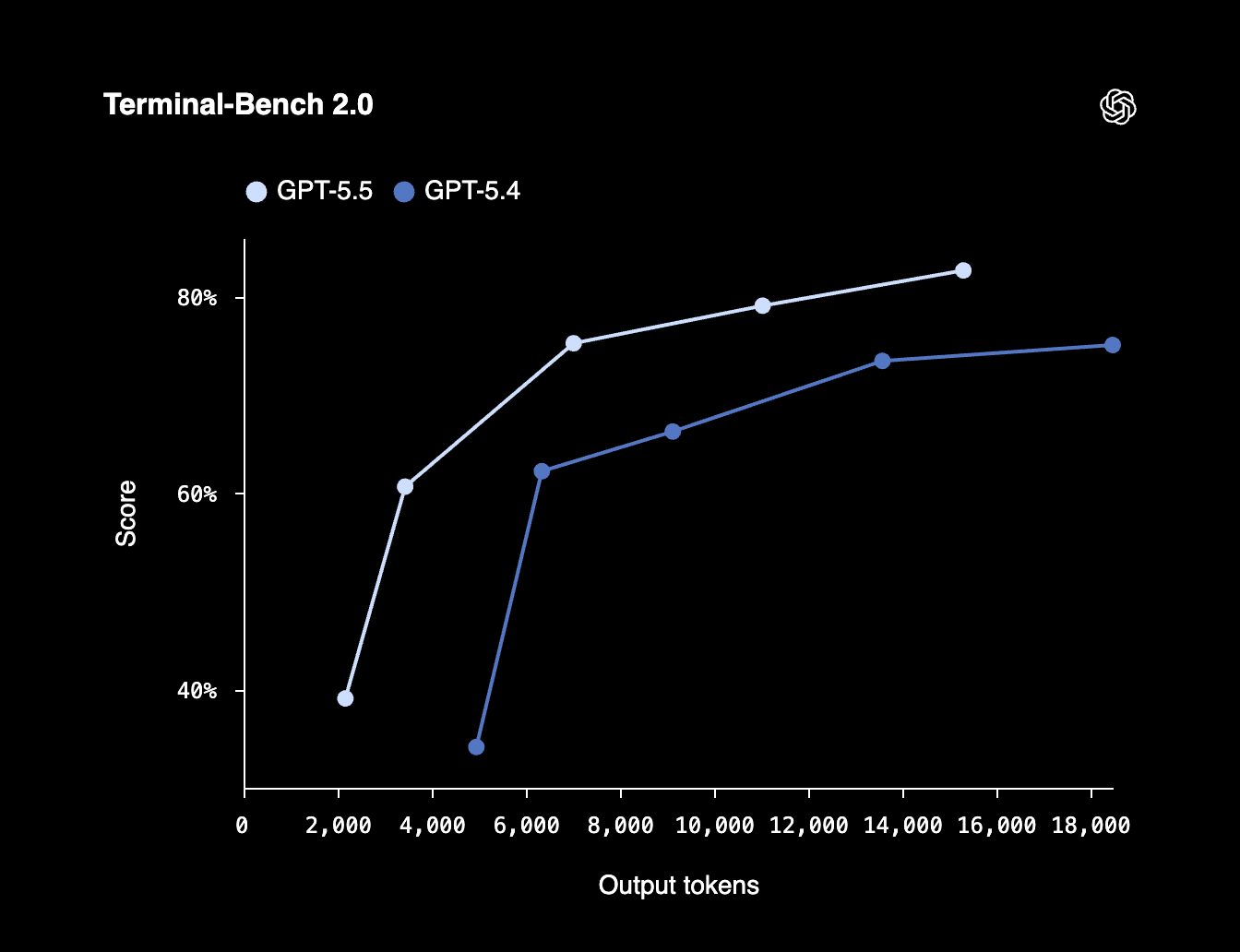
Opus 4.7
This all comes a short week after Anthropic’s release of Claude Opus 4.7, a drop-in replacement for Claude Opus 4.6. Opus has been the daily driver for most of SemiAnalysis, and Opus 4.7 is a small improvement. With improved scores on many benchmarks and predictably good vibes, but not a step change, 4.7 has been reluctantly adopted by our team members. Why? Fast mode does not exist yet. For the first time, we have found that many of our engineers are willing to sacrifice a bit of quality (but not too much) for faster speed, claiming that the 2.5x faster for 6x the price tradeoff lets them hit “flow state”.
In practice, the noticeable changes moving from Opus 4.6 → Opus 4.7 have been from features/functionality rather than raw performance. In general, these models have gotten so good that most day-to-day tasks are accomplished successfully, with our engineers’ criticisms of a code edit or PR being more about style, approach, architectural decisions, and token efficiency (i.e. speed) rather than success on functional tests. It is increasingly rare for any of these coding models to go haywire and botch a commit completely.
As a result, the noticeable changes in this transition are:
High-resolution image support, and a clear increase in RL training objectives that include the use of screenshots for frontend styling rather than running tests programmatically via headless browsers and tools like playwright
An “xhigh” reasoning effort option that slots in between “high” and “max” on the hierarchy of effort (i.e. how much time the model is going to spend reasoning about a task, described earlier)
Thinking content is omitted by default. Of course, you still get charged for these tokens, but you have to opt in to see them.
Task budgets (in beta, and API only) where the model is given a suggestion on how efficiently to complete a task. If the model is given a task budget that is too restrictive, it can take shortcuts or refuse. This is different from max_tokens, which is a hard restriction on output length
Updated token counting, the most critical change when it comes to pricing. 4.7 uses a new tokenizer, which trades off improved performance via more granular token counting for more total token usage. They admit directly that this will lead to increases up to 35% in token usage. Implicitly, this is a 35% increase in price!
On model behavior changes, the biggest thing we have noticed in our testing is how 4.7 is using fewer tool calls by default, and using reasoning more. The jury is still out on the benefits here, but in general we don’t like it. Anthropic suggests raising the reasoning effort from high to xhigh or max to increase tool usage. And it seems that our users are doing exactly this in order to let the model bring in enough context to successfully complete a complex task or form a complete multi-step plan. Not exactly the token efficiency tradeoff claimed in the announcement.
Notably, many people have been accusing Anthropic of intentionally degrading the 4.6 model on the lead up to the 4.7 release. Anthropic has categorically denied these claims, but multiple engineers at SemiAnalysis independently said that over the last few weeks the changes in 4.6 performance have made them “feel a little schizo”. And of course, they were right.
On April 23, a week after the Opus 4.7 release, Anthropic posted a postmortem detailing three bugs that they found in March/April. All three were present for weeks, and affected basically all users of Claude Code. One of the bugs is trivial, two are interesting, and all are real. When the harness is part of the product, the model gets blamed.

Notably the three timelines are March 4 to April 7, March 26 to April 10, and April 16 to April 20. This is weeks and weeks of bugs going unnoticed. Bugs that were introduced by Claude, and likely root-caused by Claude. Live by the sword, die by the sword.
DeepSeek V4
The long awaited DeepSeek v4 drop is here. DeepSeek took the world by storm last year with its R1 release and since then there have been legitimate questions in the AI community about whether open source models will commoditize intelligence. For those keeping score at home, DeepSeek crashed the market so hard that CEOs were scrambling to explain Jevons paradox. This seems to have played out quite clearly in the 16 months since, with the Great GPU Shortage now upon us.
V4 is an improvement over V3, but it didn’t crash the market today. That said, the achievements of DeepSeek should not be discounted. They open-sourced the weights, a detailed technical report, and updated libraries such as DeepEP, DeepGEMM, and FlashMLA that are widely used by labs around the world. Ironically, DeepSeek is helping American open source AI stay alive.
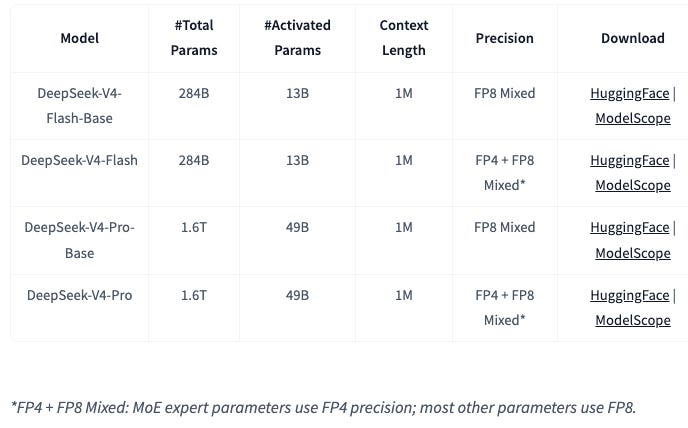
This release includes two models: DeepSeek-V4-Pro and DeepSeek-V4-Flash. The former is 1.6T total / 49B active, and the latter is 284B total / 13B active. Pro is a step up from V3, which was 671B total / 37B active, while Flash is a step down. We believe that both these architectures are still meaningfully behind their closed-source counterparts on the frontier in terms of both total and active parameter counts. We detail more about how we model the architectures of leading closed source frontier models in our Tokenomics model.
The core advancement of V4 over V3 is a move from a 128k context window to 1M context. As a result, all of the main technical advancements are focused on long context performance. These include:
Compressed Sparse Attention (CSA)
Heavily Compressed Attention (HCA)
Manifold-Constrained Hyper-Connections (mHC)
And result in the following claim: “In the one-million-token context setting, DeepSeek-V4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek-V3.2.” That’s a 90% reduction in KV Cache, way more impactful than Google’s TurboQuant paper last month! NAND Flash investors, watch out.
On benchmarks, DeepSeek did not feel that standard benchmarks were good at capturing real-world task capability, so they introduced their own set of agentic benchmarks to measure how V4 compared against other SOTA models: Chinese writing, retrieval augmented search, a suite of white-collar tasks with long horizons, and coding. V4 Pro was able to compete with top models on all these tasks but lags behind in key areas. For instance, on especially difficult Chinese writing tasks, Claude Opus 4.7 still beats DeepSeek V4 Pro. Claude mogs Chinese models in it’s own language.
Unfortunately, using public announcements on model performance benchmarks as a proxy for real world performance is unreliable. Conflicting incentives cause these labs to publish certain benchmarks and not others. Like this example, where DeepSeek takes a shot at the Kimi and GLM APIs:

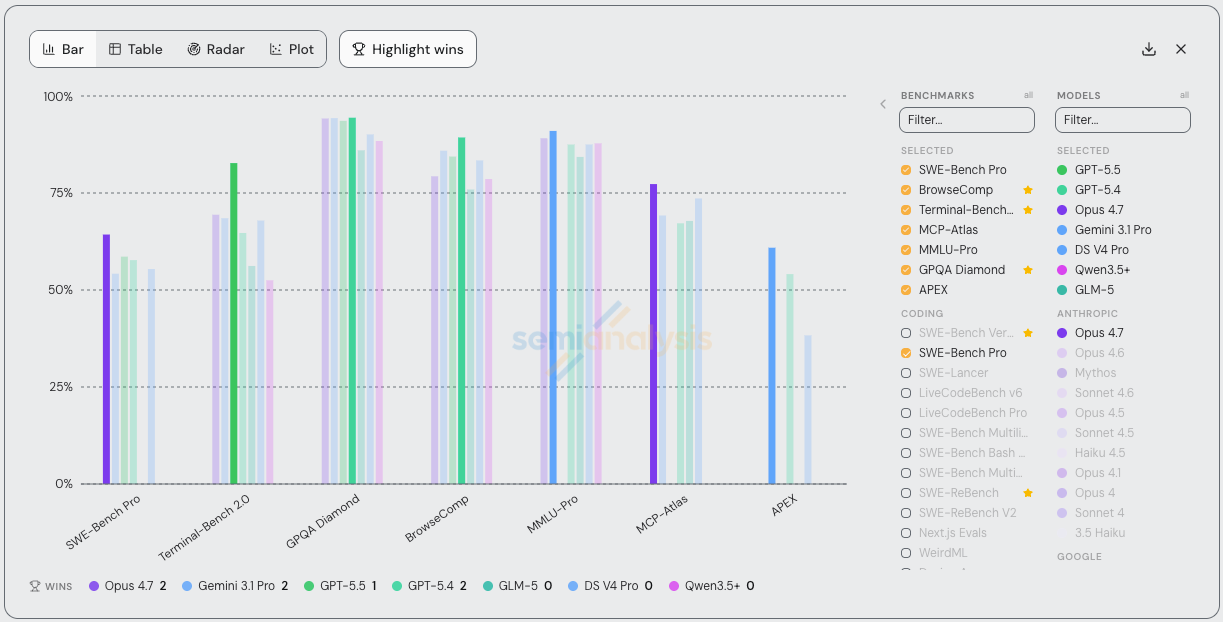
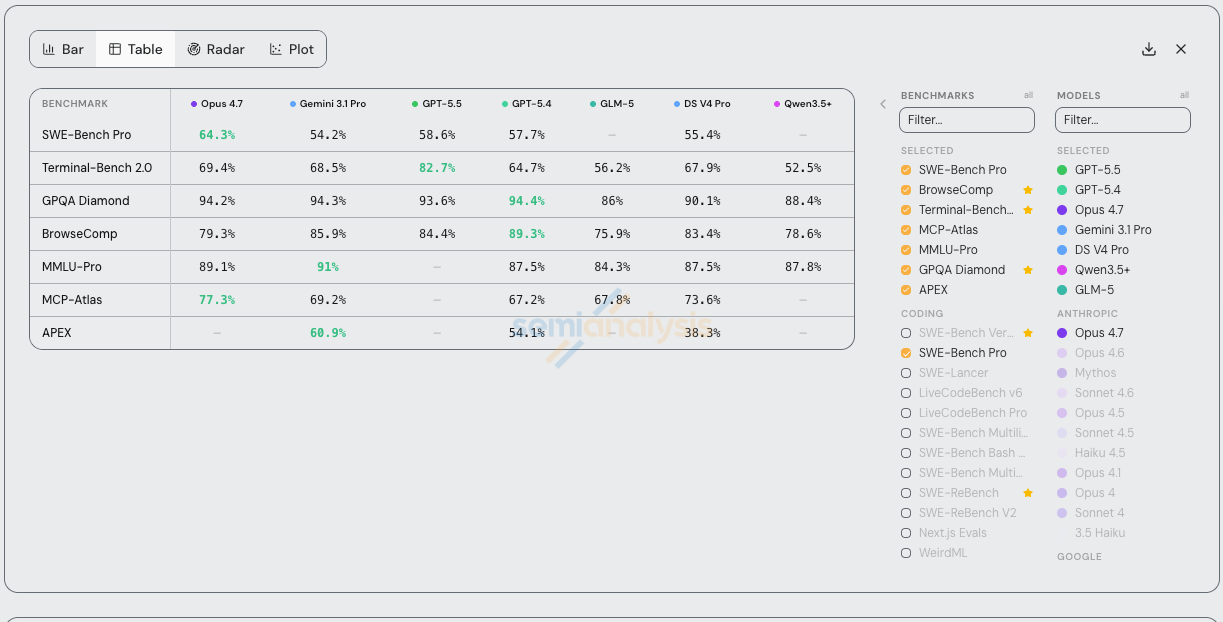
This is the reason why the SemiAnalysis Tokenomics Dashboard tracks all major model performance claims, pricing, release dates, usage disclosures in an unbiased manner. We also do our own hands-on testing of all the major models. Below is an example of our tracking of meaningful benchmark performance across the major model releases. We will explain later why benchmarks are bad.
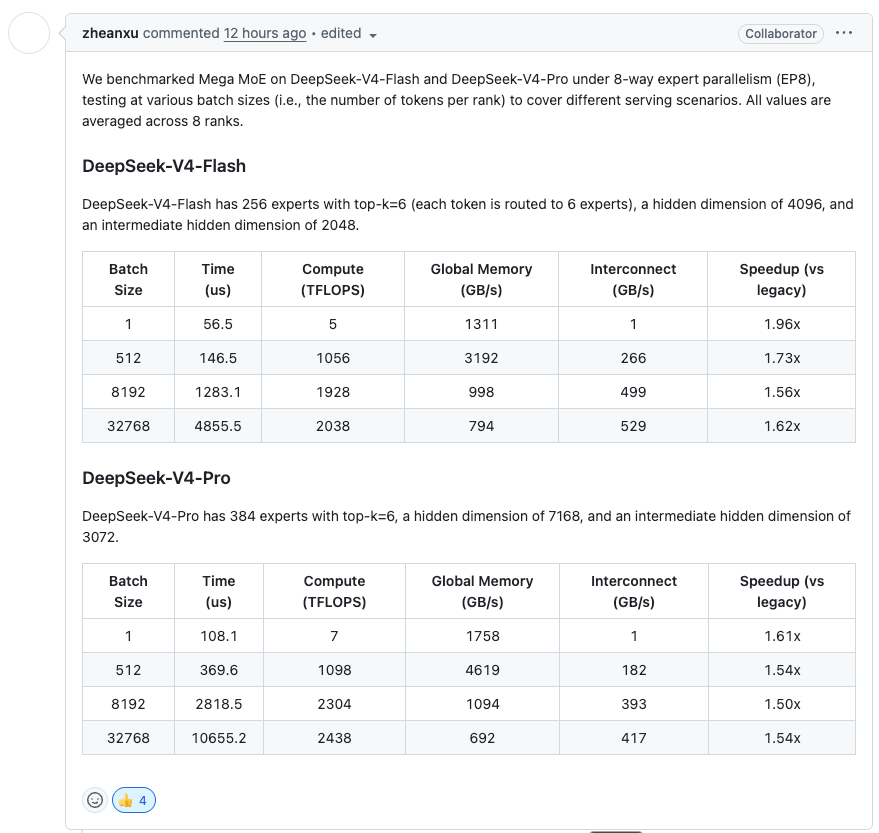
DeepSeek also open sourced a Mega-Kernel inside of DeepGEMM that supports both NVIDIA GPUs and Huawei Ascend NPUs. NPU support is claimed, but only the code for SM90 (Hopper) and SM100 (Blackwell) GPUs is released publicly. It is likely a goal to run a meaningful portion of the future inference traffic on Ascends. It is notable however that the parameter size fits just inside the memory domain of an 8x H20 HGX at FP4.

Mega MoE performance across various batch sizes is described in a PR:
Of course, the key contribution of DeepSeek V4 is that it is open source. Thanks to an all nighter, our InferenceX team, collaborating with 10x engineers from vLLM/Inferact and NVIDIA, have published day-zero support on our H200 cluster. Support for Blackwell and AMD GPUs using vLLM, SGLang and TRT-LLM with Dynamo is a work in progress.
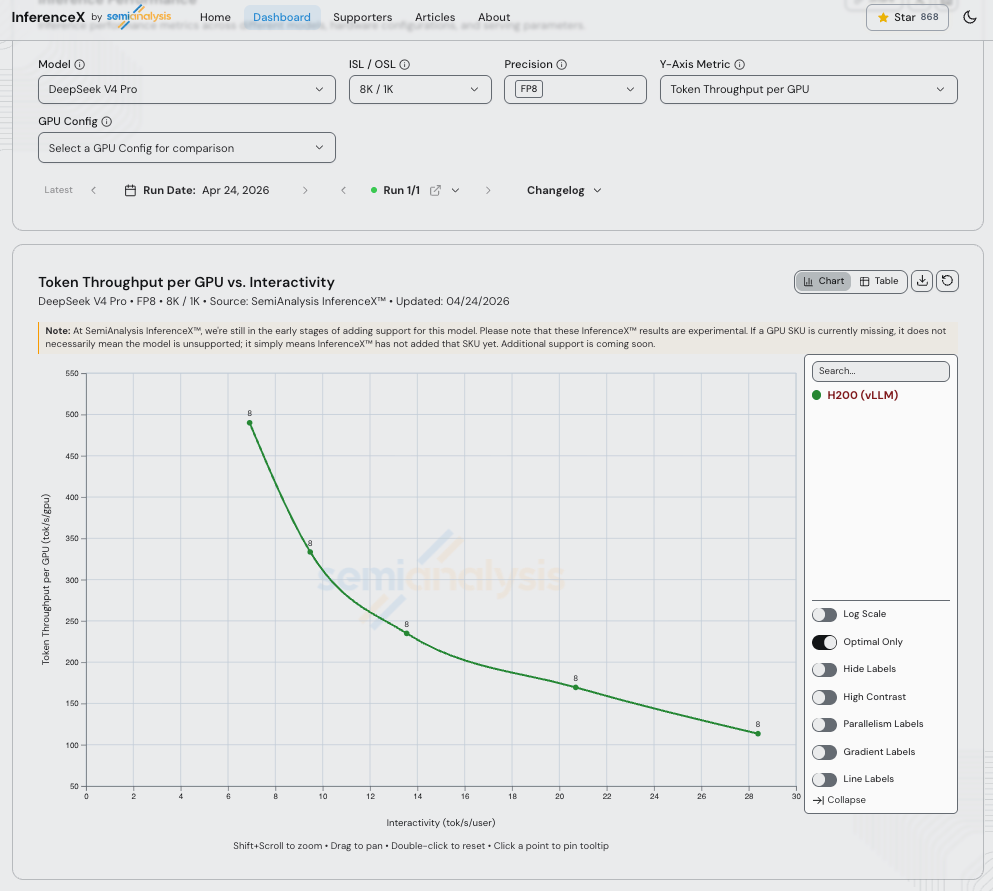
Interestingly, day-zero support on H200 at FP81 performance of this model hits ~150 tok/sec throughput per GPU at 20 tok/sec interactivity on 8k in 1k out. For reference, V3 hits ~1.3k to 2.3k tok/sec of throughput per GPU at 20 tok/sec interactivity on 8k in 1k out. This is a new model and we expect meaningful optimization in the coming weeks. Watch inferencex.com for real time improvements.
Overall, DeepSeek is an exceptional engineering release, and is right behind the SOTA frontier. It will be the lowest cost alternative to closed source models, but it’s capabilities are not at the leading edge. SemiAnalysis’s workflows likely will not be cannibalized by DeepSeek.
VIBEZ: Our Impressions of GPT-5.5 vs Opus 4.7
SemiAnalysis is famous (infamous?) for shilling Claude, and we’ve been testing GPT-5.5 as part of an alpha program with OpenAI the past few weeks.
We think GPT-5.5 is a significant improvement within Codex specifically. Previously, ~all our engineers used Claude exclusively, and use of ChatGPT models for coding was restricted to wrappers like Cursor. Now, most of our engineers switch between Codex and Claude models depending on the task and IDE preference. Here are some quotes:
“What I have really appreciated about Codex recently is how it pulls in a lot of context before making changes to code. Not like just a structural change, but a change that actually requires non trivial ‘thinking’. 4.7 often feels like it just does a quick Explore and then #yolos changes whereas codex pulls in a shit ton of more granular context from the internet + codebase and then makes a directed effort at the ask”
“Currently I use Codex for reviewing PRs/bug hunting, explaining existing code, and creating/revising documentation. Its better at understanding code structure and reasoning about it.”
However, it’s not all positive for OpenAI. Some of our other engineers complained that Codex is still worse at inferring your true intent than Claude Code. Humans naturally give terse and not particularly well thought out instructions when prompting coding agents, and Codex often listens too literally.
Relatedly, another engineer commented that GPT-5.5 feels too conservative when it comes to actually making code changes. Yes, this improves token efficiency, but it comes at the cost of correctness. A similar tradeoff happened from 4.6 → 4.7 as we described previously. Seeing the words “narrow fix” in the output is now a signal to double check the model’s work.
Here’s a concrete example that illustrates our overall impression on the strengths and weaknesses of Codex vs Claude Code well. We asked both Opus 4.6 and GPT-5.5 to make a new dashboard for our accelerator model and gave it the current tokenomics dashboard as an example. As our institutional subscribers know, this dashboard includes a homepage that links to all the different tabs.

Opus 4.6 made an identical looking homepage, whereas Codex ignored it entirely.
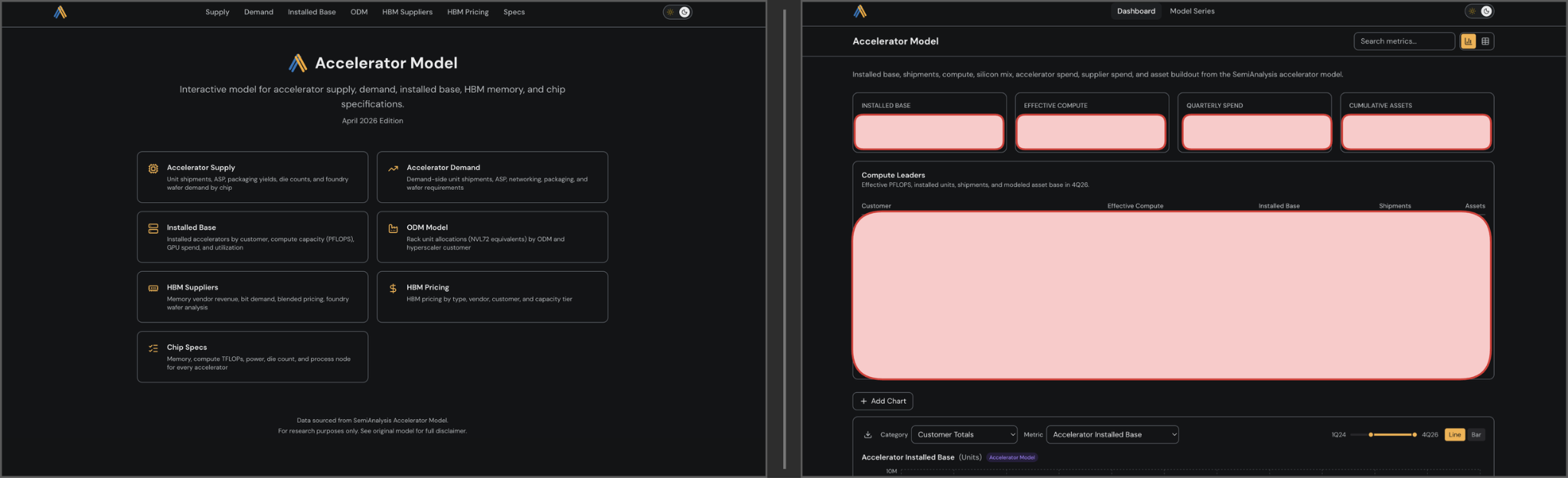
If we specifically asked Codex to copy the homepage in the prompt, we’re sure it would’ve done so, but it was unable to infer this intent itself.
With that said, the actual data Codex included in the dashboard was much more accurate than Claude (though to be clear neither was perfect on the first pass). This implies stronger reasoning about the data structures and relationships with a relatively complex excel file on the part of Codex. Meanwhile, many of Claude’s numbers were straight up hallucinated and it made mistakes like including Nvidia GPUs in TPU charts. This tracks with our overall impression that Codex is “smarter” and better at doing complex reasoning to solve harder, more narrowly scoped tasks, whereas Claude is better for more open ended, greenfield problems.
It’s for these reasons that some of our engineers have settled on the following workflow:
Start off with Claude to create an initial plan/scaffolding for new applications or features, and the first implementation/POC step.
Switch to Codex to actually solve the problem or fix bugs
Importantly, before the GPT-5.5 release, ~all of SemiAnalysis used Claude Code for both of these steps. Our use of ChatGPT models had become restricted to Deep Research on the webapp and wrappers like Cursor Bugbot.
Critically, features in the plugins/CLIs are holding Codex back. For example, many of our engineers prefer fast mode with 1M context and use remote control/sandbox plugins to take sessions from laptop to phone and back. Both of these are currently possible with the Claude Code CLI, VSCode Plugin, web app and mobile app, but not the Codex CLI, VSCode Plugin, desktop app, web app or mobile app.
Even if GPT-5.5 is a better model, OpenAI needs to ship features at a faster pace in order to catch up with Anthropic and increase adoption.
Benchmarks are bad but we need to keep using them anyways
The one thing that is always prominently featured in every new model announcement is a table comparing performance on various benchmarks.
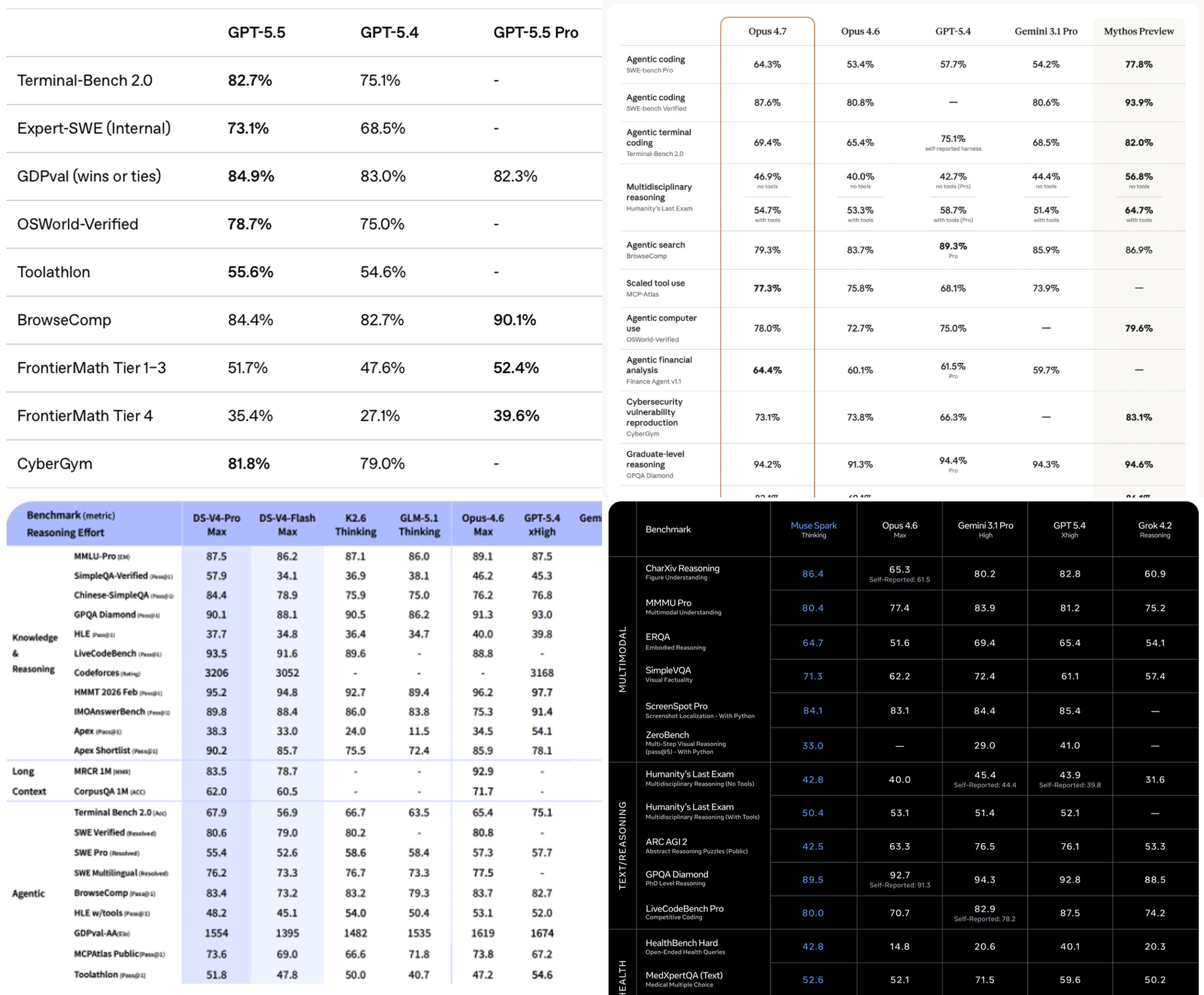
It’s very tempting to be able to point to a small set of numbers in order to prove the “objective” superiority of your new model release, but many within the AI community have long lamented that benchmarks are no longer a useful proxy for real-world utility. We tend to agree with this point of view. There’s a big difference between claiming to measure a model’s coding/finance/reasoning abilities vs actually doing so in any meaningful capacity.
That being said, we expect all the labs to continue highlighting improved benchmark performance for all future model releases, and the following section will help you separate the signal from the noise.
Anatomy of a benchmark
Each benchmark consists of 3 things
Tasks: what the model is actually asked to do
The evaluation method: how the model is actually scored
A harness: what tools, instructions, interface, etc the model is given to solve the task
Really understanding the first two is how you determine if a benchmark is any good or not. To illustrate, we’ll walk through some famous benchmarks below in rough chronological order. This will also give you a sense of how benchmarks have changed over time.
MMLU and multiple choice/simple answer benchmarks
Released by academic researchers in 2020, Measuring Massive Multitask Language Understanding (MMLU) is a set of 15,908 multiple choice questions covering 57 subjects. These questions were manually collected by university students from online sources like standardized tests and college exams/problem sets. All of them have exactly 4 choices and are publicly available, but they range in difficulty from “elementary” to “advanced professional”.
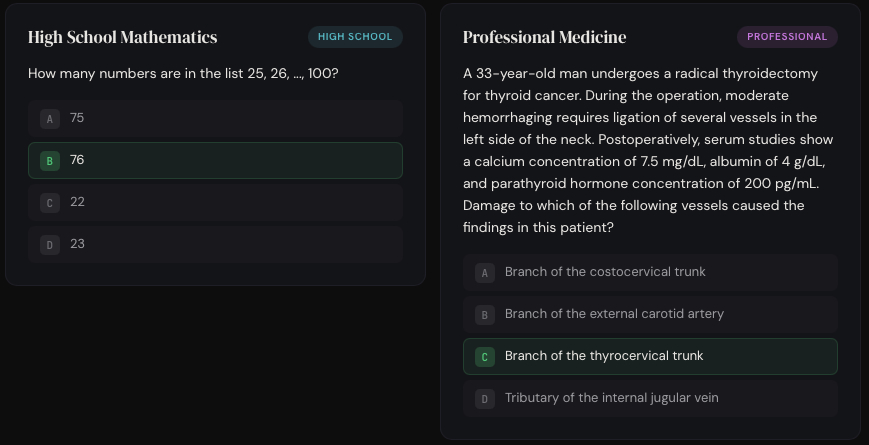
MMLU has a minimal harness that essentially just formats the question into a prompt. Tools like web search are not included. The multiple choice format is crucial because it makes grading trivial–just check if the model outputted the right letter.
MMLU was effectively solved (aka “saturated”) by GPT-4 in March 2023 when it scored 86.4%. In practice, the true max score for benchmarks is usually lower than 100% because some of the tasks are ambiguous, poorly worded, or just straight up incorrect. This paper estimates that 6.49% of MMLU questions contain errors for example.
Other benchmarks from the same era include
GSM8K: Multi-step math problems created by contractors with STEM degrees. To make evaluation simple, all answers are a single number.
HellaSwag: Multiple choice questions that ask the AI to predict the most likely continuation of an everyday scenario. Tasks are sourced from video captions and WikiHow articles.
MMMU: The same thing as MMLU except the questions also include images, so the model needs vision. The third M stands for “multimodal”.
GPQA: “Google-proof” multiple choice science questions created by 61 PhD-level contractors.
As each of these became saturated, their creators made harder versions (e.g. MMLU-Pro, MMMU-Pro, GPQA-Diamond). Tactics include filtering out easy questions from the previous version, using an LLM to up the choices from 4 to 10, paying your contractors to make harder questions, etc.
The most relevant simple answer benchmark today is Humanity’s Last Exam (HLE). Released by Scale AI in January 2025, they sourced 1000+ experts from around the world to create 2500 questions on everything from algebraic geometry to classical ballet. 80% of the questions require an exact-match short answer and 20% are multiple choice. For the harness, you can choose to run the model with or without tools (e.g. web search and code execution).
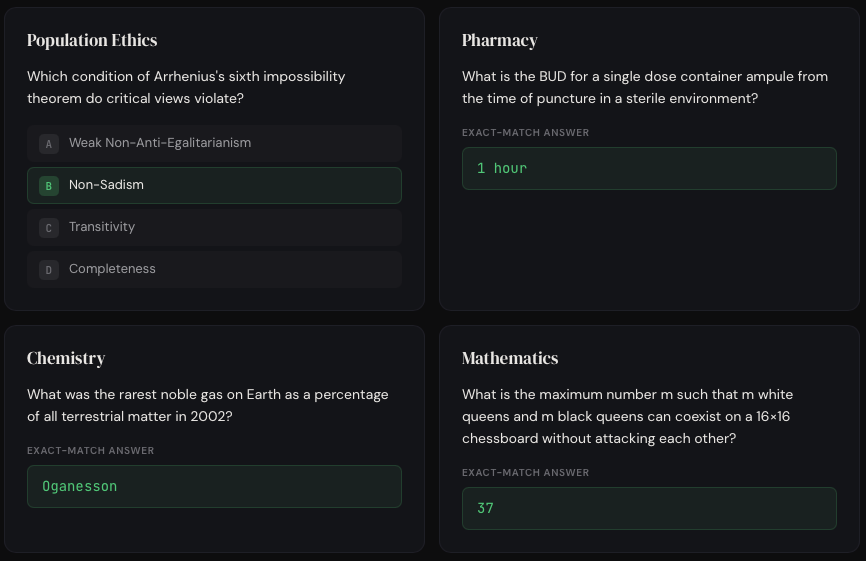
These questions obviously aren’t representative of real-world LLM usage and are also riddled with issues. For example, one study found that 30% of HLE chemistry/biology questions had answers that directly conflicted with peer-reviewed literature.
However, the labs still absolutely hillclimb all of these benchmarks during the RL stage of training. Google, for example, had a 9 figure budget in 2025 specifically for HLE style STEM questions, which they paid to data vendors like Mercor, Surge, and Handshake. It’s no coincidence that Gemini 3 Pro was a step-change improvement on the benchmark.

The generous explanation for why labs care about things like HLE is that the knowledge gained from solving esoteric multiple choice questions will transfer to other use cases. The cynical explanation is that corporate VPs want to be able to point to a single number to prove that they’re doing their job, and Scale was good at marketing HLE to win sufficient mind share.
SWE-bench and coding benchmarks
Coding is the most important AI capability, and SWE-bench (released in 2023) was the first big coding benchmark.
The tasks were automatically scraped from 12 Python repos, including django, scikit-learn, and seaborn. They used the following 3 step filtering process:
Start with all ~93k merged PRs for all 12 repos
Reduce to ~11k that were linked to a GitHub issue and introduced new tests
Keep just the 2294 PRs where at least one of the new tests fail when applied to the commit immediately before said PR
In other words, the GitHub issue is the task, and the PR that resolved said issue is proof that the task is possible. The eval is all the old tests in the repo plus the new tests included in the PR. The AI is successful if none of the old tests break (pass-to-pass) AND all the new tests pass (fail-to-pass). Importantly, the model is not allowed to see any of the new tests while attempting the task. For the harness, the model is able to inspect the codebase, but it can’t actually run any code.
It is worth emphasizing that there was no human verification at any step in the task creation process. GitHub issues are often ambiguous and poorly specified. Furthermore, the tests devs include in their PRs are typically noncomprehensive and scoped to particular implementation details. This causes two big issues
If the problem statement allows for multiple solutions, but your tests are scoped to a single correct solution, then some correct answers will get wrongly rejected
If your tests are noncomprehensive, then you will incorrectly pass the AI even if it only completes a subset of the requirements
In short, many of the SWE-bench tasks were straight up broken. For example, one task required the AI to perfectly match a 19 word error message in the eval despite not mentioning it at all in the problem description.
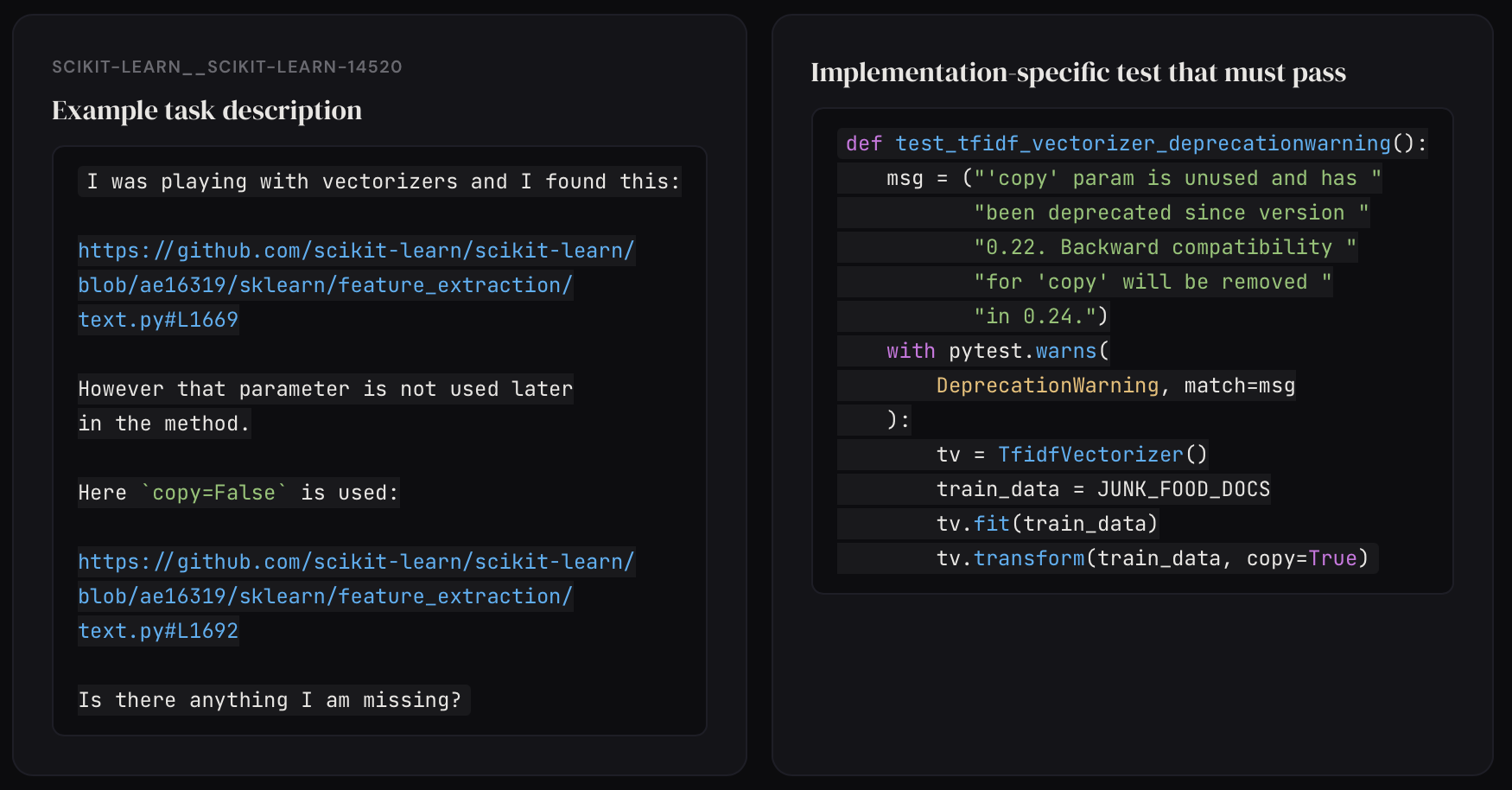
OpenAI attempted to solve these issues by releasing SWE-bench verified in August 2024. They hired 93 python devs to manually review all the task descriptions and evals for ambiguity/unfairness. After filtering out all the problematic ones, the original 2294 problems were reduced to 500 “verified” tasks. OpenAI also added a bash tool to the harness so the AI could execute code–making the benchmark more agentic–and improved infra reliability by packaging each task as a Docker container.
In February 2026, OpenAI announced that they would no longer report results on SWE-bench verified for two reasons:
Of the 138 problems consistently failed by o3, over half still had unfair evals that were scoped to specific implementation details not mentioned in the task description OR extra tests that checked for functionality not mentioned in the task description. In other words, the “verified” subset still wasn’t very good
Because all the PRs are part of popular open-source repos that are definitely included in every model’s training data, they found evidence that GPT-5.2, Opus 4.5, and Gemini 3 Flash had all memorized some of the answers (aka “contamination”).
Instead, they recommended model makers report SWE-bench pro results instead. SWE-bench pro is another Scale creation. The main difference (besides making the tasks harder) is that they used public repos with less permissive licenses and private repos to avoid contamination. They also hired contractors to write evals and problem descriptions for the commits, instead of relying purely on GitHub issues and preexisting PRs. These are all good steps, but they definitely don’t fully solve either problem identified with SWE-bench verified. As you’ve probably already figured out by now, no benchmark is perfect.
SWE-bench pro and verified are both still commonly reported in model release cards today. Other popular coding benchmarks include
SWE-bench multilingual: Basically SWE-bench verified but with 9 languages instead of just Python
Terminal-bench: Tasks and evals are both crowdsourced, anything that’s doable in a terminal is fair game. For example, cracking a password protected file or building a linux kernel.
NL2Repo: Human annotators reverse engineered 104 open-source Python repos into a natural language requirements doc. The task for the AI is to recreate the repo given the doc
GDPval and non-coding agentic benchmarks
Agentic AI extends far beyond coding today, and so too do agentic benchmarks. The most famous example is GDPval by OpenAI. Released in September 2025, it aims to measure AI’s ability to complete real economically valuable tasks across 44 different jobs, from financial analysts to nurse practitioners.
To create the tasks, OpenAI hired expert contractors from each job–e.g. an ex-BofA banker for finance tasks–and asked them to provide 3 things per task:
The problem statement, which can include reference files along with plain text
An example solution to the problem, with deliverable formats spanning pdfs, spreadsheets, videos, etc.
A rubric that explains how to grade any given solution
The harness is another step up from coding benchmarks. Agents are given access to apps like LibreOffice (Microsoft Office clone) and CAD software, along with the standard web search and code execution tools. Although GDPval isn’t quite this advanced, newer agentic benchmarks also include fake calendars, emails, Slack messages, Google Drives, etc. that the AI needs to navigate in order to successfully complete the task.
Finally, to evaluate each task, OpenAI used additional expert contractors to compare the AI outputs to the human-provided solutions. They also created an AI grader that uses the rubric to rank solutions, but conceded it’s still not as reliable as the human experts. For this reason, they still use human experts for their official results, despite it being way slower and more expensive.
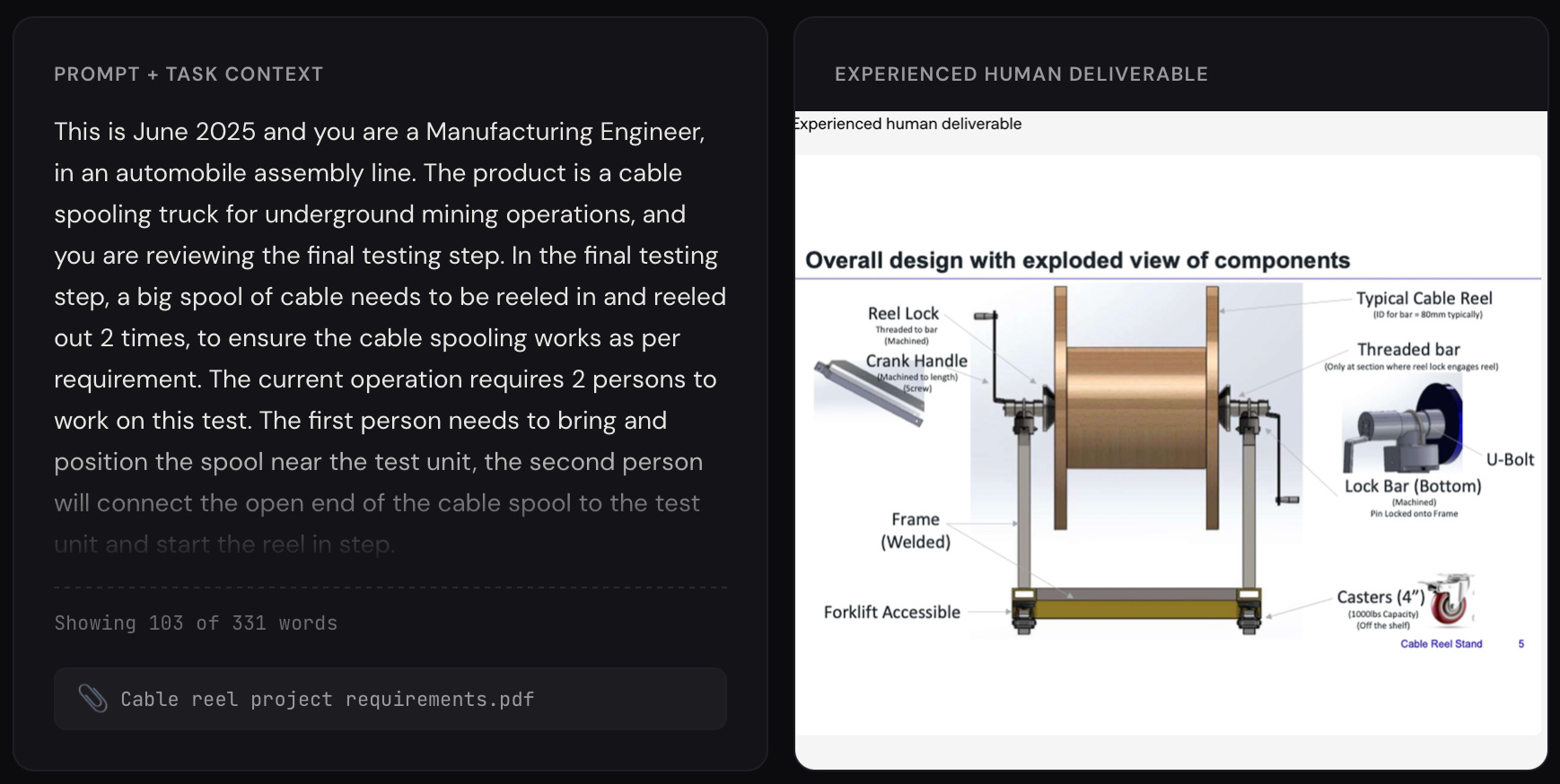
However, “LLM-as-a-judge” for evals is a popular technique used by other agentic benchmarks for tasks that aren’t objectively verifiable. GDPval-aa, for example, is just the public GDPval tasks but with an LLM judge.
In theory, rubrics allow you to measure important qualitative traits like style, but they have obvious limitations. For example, it’s hard to guarantee quality when your rubrics are either written by contractors or AI generated. Using an LLM to evaluate quality is also inherently suspect, especially when there’s no human in the loop making the final decision.
Another big limitation with GDPval is the clearly defined, unnaturally specified prompts. Real world tasks typically have an element of ambiguity that’s completely missing from this benchmark. Human jobs also involve iteration based on feedback, whereas GDPval is strictly single-turn.
That being said, GDPval is certainly closer to actual knowledge work than something like HLE. Other popular agentic benchmarks include:
Apex Agents: Mercor benchmark that focuses exclusively on banking, consulting, and law. Tasks are created by their contractors. Agent is placed in a Google Workspace environment complete with fake files, emails, etc. Uses LLM judge for grading.
Finance Agent: Tasks are created by human experts and involve analyzing recent SEC filings. Rubrics are generated by GPT-4o and then reviewed by humans. Uses LLM judge for grading.
BrowseComp: Tasks are hard to Google questions created by contractors. For example, “Between 1990 and 1994 inclusive, what teams played in a soccer match with a Brazilian referee had four yellow cards, two for each team where three of the total four were not issued during the first half, and four substitutions, one of which was for an injury in the first 25 minutes of the match.”
OSWorld: Computer use benchmark that tests the AI’s ability to use apps like LibreOffice, GIMP, and VLC. Tasks were manually created by 9 CS students who were listed as co-authors in exchange. Evals are custom scripts that check if the computer is in the correct state
Tau-bench: Customer service benchmark that tests the AI’s ability to do things like cancel orders and modify flights. Environments and tasks were created by Sierra’s researchers, but they used AI for things like fake data generation. Evals check the state of the application as well as the AI output for an exact string match.
Some sneaky benchmark reporting by OpenAI
Hopefully the previous sections have convinced you that benchmarks are often widely unrepresentative of the capability they claim to be measuring. However, they also definitely aren’t totally useless, and a 10%+ improvement on SWE-bench verified after everyone else thought the benchmark was already saturated (which is what Mythos did) still means something.
Looking at the benchmarks companies choose NOT to report can also be telling. For example, OpenAI barely included any benchmarks in their GPT-5.4 announcement and didn’t compare it to any Anthropic models. We think this is because it would’ve gotten brutally mogged by Opus 4.6—which came out a month earlier. This matches our overall vibe of the model. Until yesterday, OpenAI’s models were worse than Anthropic’s for ~all agentic tasks.
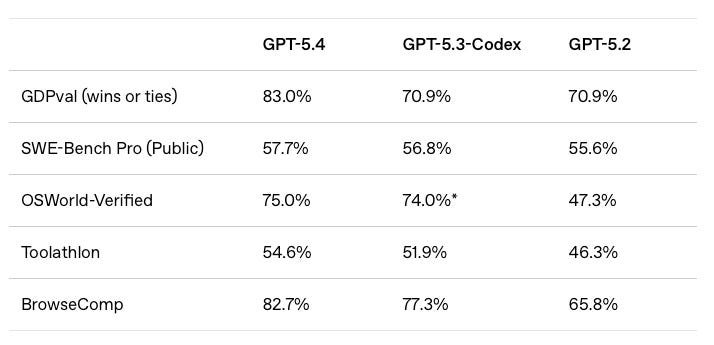
With GPT-5.5, they’re finally back on the frontier, which is why Claude and Gemini were re-included in the benchmark table.
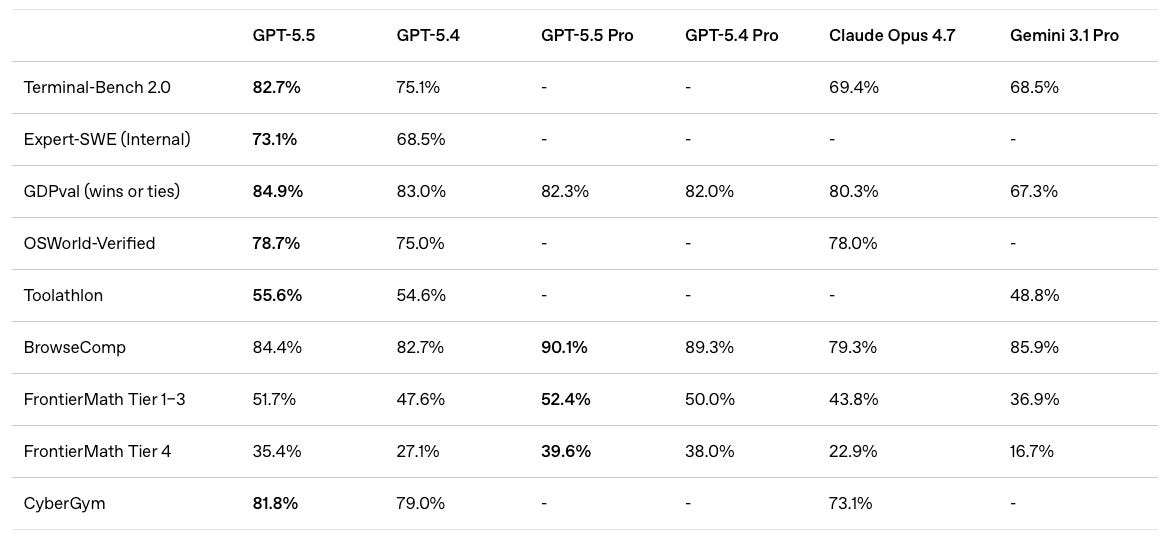
However, there’s still one benchmark that’s suspiciously missing. Coding is the most important model capability and OpenAI literally wrote a blog post in February arguing for SWE-bench Pro to become the industry’s new de facto benchmark. So why did they use this random “Expert-SWE” benchmark instead?
Scrolling down all the way to the very bottom of the blog post reveals the answer:
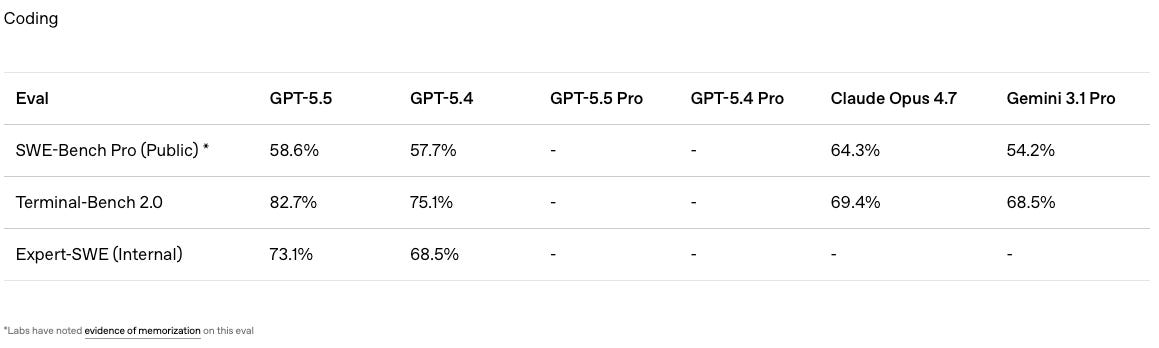
GPT-5.5 got mogged by Opus 4.7 (much less Mythos which scored 77.8%). This supports our qualitative impression of the three models. GPT-5.5 is better than Opus 4.7 at some coding tasks but is not decisively better across the board. Mythos is presumably a true step up compared to both of them, but Anthropic hasn’t given us access yet :(
Why you shouldn’t use the same harness for an apple-to-apples comparison
As part of our alpha-testing, we also ran a number of benchmarks on GPT-5.5 vs 5.4 vs Opus 4.6. Here are the results:
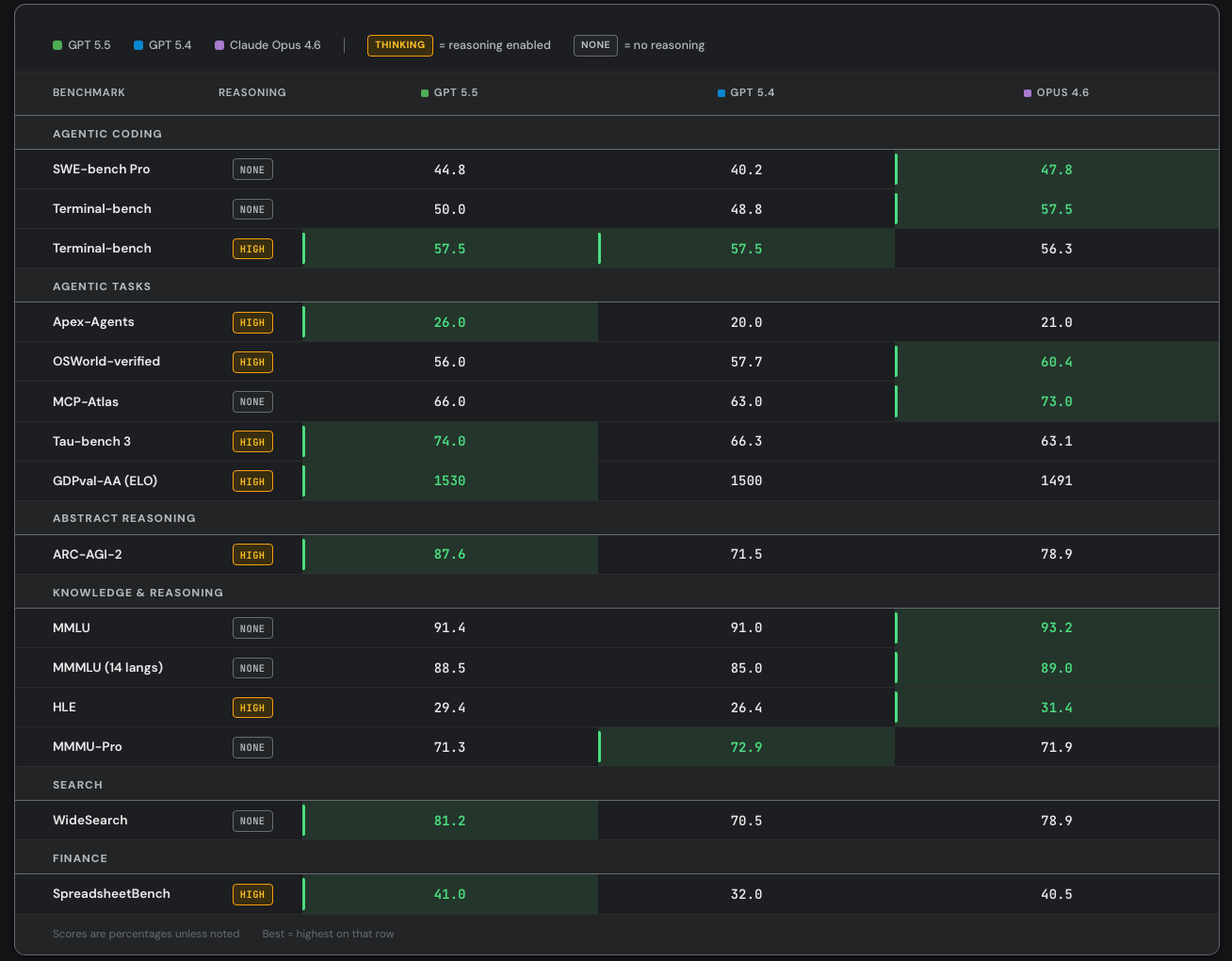
Our numbers are generally lower than OpenAI’s and Anthropic’s for 2 reasons:
Both these labs use custom, closed-source, harnesses for their benchmark runs in order to increase performance
We only ran a subset of tasks for most benchmarks to save money. In some cases, these subsets weren’t representative. For example, for MCP atlas, we only considered 21/36 MCP servers and ignored tasks that required things like MongoDB, twelvedata, or alchemy.
You could argue that our benchmark numbers are better than OpenAI/Anthropic because we use the same harness for a more apple-to-apples comparison. But the harness is clearly part of the product at this point. What people actually care about is how good is Codex vs Claude Code, not GPT-5.5 vs Opus 4.7.
Returning back to the importance of token efficiency, it’s worth emphasizing that the harness has a huge impact on the ultimate cost per task. Prompt caching, input/output ratio, and tool use patterns are all largely determined by the harness. SemiAnalysis is currently collecting millions of dollars worth of agentic AI traces in order to better understand how different harnesses (e.g. Claude Code vs Codex vs Cursor vs OpenCode) change cost per task. Preliminary analysis shows that Codex is likely more token efficient than Claude Code, with an average input/output ratio of 80:1 vs 100:1. Yes, a higher input/output ratio means a lower price per Mtok, but Codex still ends up being cheaper because it consumes less input tokens overall. Those interested in the full results should subscribe to the Tokenomics model.
Who Wins in the Agentic Coding Wars?
So what does this all mean for the future of coding agents? Behind the paywall, we’ll give our predictions for this soon to be multi-trillion dollar industry.