

The New AI Networks | Ultra Ethernet UEC | UALink vs Broadcom Scale Up Ethernet SUE
LibFabric, Packet Spraying, Rail Optimized, Congestion Control, ECN, ACK, Flow Control, PFC, UEC Challenges
SemiAnalysis Subscribers get access to audio narration of this article.
Standard Ethernet initially lost significant market share to Nvidia's InfiniBand in the early days of the GenAI boom. Since then, Ethernet has started clawing back market share, largely driven by cost, the various deficiencies of InfiniBand, as well as the ability to add more features and customization on top of Ethernet.
Amazon and Google's internal Ethernet implementations have made up a significant portion of the performance deficit (albeit they are still very far behind Nvidia based networking). Furthermore, firms such as Oracle and Meta have invested heavily in building on top of Ethernet, and are not that far behind Nvidia.
Even Nvidia recognizes the dominance of Ethernet and with the Blackwell generation, Spectrum-X Ethernet is out shipping their Quantum InfiniBand by a large amount. In general standard Ethernet is still far behind in performance without significant effort put into a proprietary implementation.
This is where Ultra Ethernet Consortium comes in. Standardizing many improvements for large AI networks and bringing together all the biggest players in a massive alliance.
Ultra Ethernet Consortium Release Candidate 1: An In-Depth Review
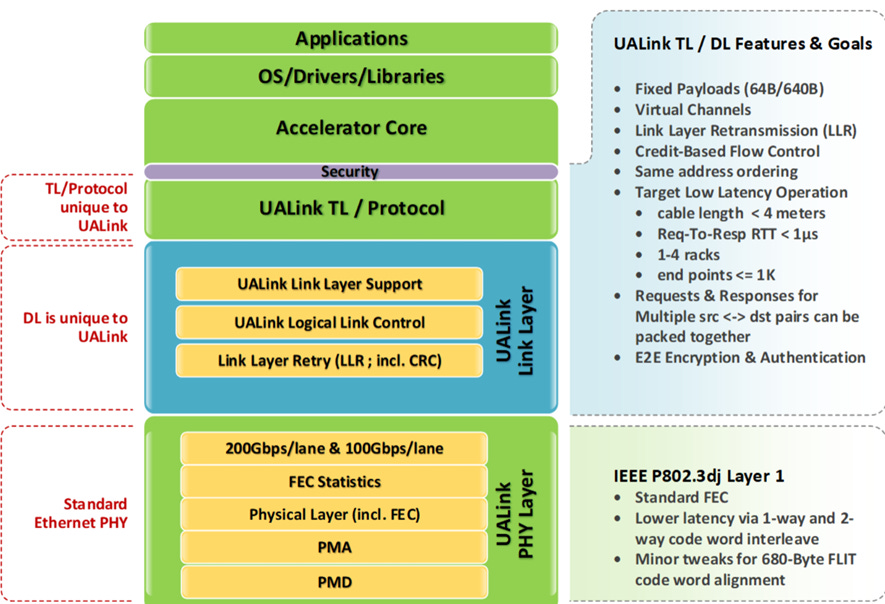
The Ultra Ethernet Consortium (UEC) Release Candidate 1 is a substantial document, spanning 565 pages that was publicly released today. This contrasts sharply with the Ultra Accelerator Link v1 specification, which prioritizes simplicity. UEC, by its very nature, is not simple; a direct read-through is nearly impenetrable. However, a structured approach can reveal its underlying logic.
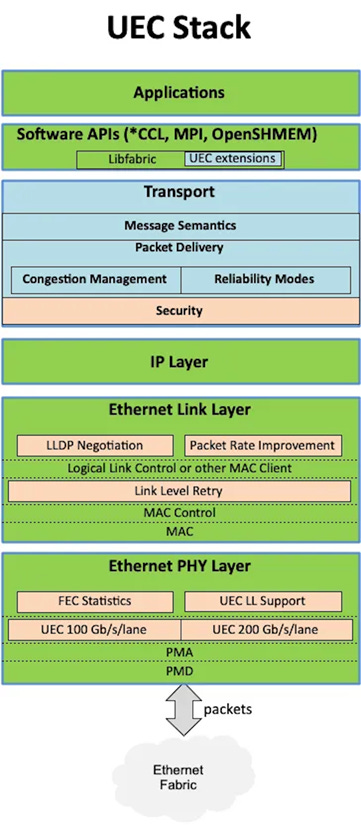
The UEC project aims to provide transport and flow control layers to Ethernet NICs and switches which will improve its operation in large, fast, datacenter networks. Transport is the layer that ensures user content gets from source to destination, and carries all the commands a modern AI or HPC user expects. Flow control ensures that data flows at best possible speed, preventing traffic jams and re-routing around faults or slow links. The network interface cards must implement UEC for this to work. The switches are optional and current Ethernet switches can be used in the network section. The UEC spec is carefully detailed, so that equipment should interoperate between vendors.
UEC Context and Core Blocks
UEC operates under the Linux Joint Development Foundation (JDF) and functions as a Standards Development Organization (SDO). While Ethernet is the base that UEC rests upon, UEC leverages several other specs or industry experiences as building blocks. Designed as a local network, it aims to achieve round-trip times between 1 and 20 microseconds across clusters, specifically targeting data centers. Its primary objective is to optimize scale-out networks for AI training, AI inference, and High-Performance Computing (HPC). The specification mandates the use of the Ethernet standard for the network PHY and requires modern Ethernet features within switches.
A crucial building block is Open Fabric Interfaces, also known as LibFabric. Understanding LibFabric unlocks the first 120 pages of the UEC specification. LibFabric, an already widely adopted API, standardizes NIC usage. Existing bindings or plugins connect LibFabric to high-performance networking libraries such as NCCL (from Nvidia), RCCL (from AMD), MPI (the OG supercomputing parallel communications), SHMEM (shared memory), and UD (unreliable datagram) – styles of networking required in AI or HPC superclusters.
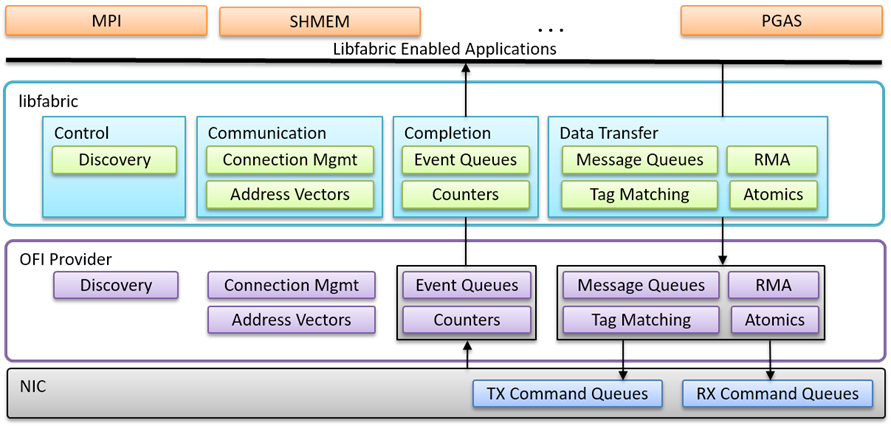
UEC is not an entirely new invention. Instead, it builds upon an established open standard, defining an interoperable framework for its operation. Interoperability is clearly a core concern, as UEC places no constraints on how the API functions with a CPU or GPU. LibFabric revolves around command queues for data transmission, reception, and special values, alongside completions. This queue-based NIC interaction has been standard for over 40 years. UEC does not dictate how these queues are constructed with your GPU or CPU but mandates support for all LibFabric commands: sending, receiving, RDMA, atomics, and special commands. Over 100 pages detail how these commands are encapsulated in message headers, ensuring compatible execution across different vendor NICs. This effectively transitions LibFabric from a software stack on the CPU/GPU to a hardware-accelerated command set on the NICs.

A key concept derived from LibFabric and integrated into UEC is the "Job." A Job represents a cooperative set of processes distributed across multiple endpoints. While functionally similar to VXLAN, it utilizes Fabric End Points (FEPs) within UEC NICs instead of Ethernet VXLAN. A single NIC can host multiple FEPs, but each FEP is assigned to one Job and can only interact with other FEPs sharing the same JobID. A trusted fabric service manages the creation and termination of these Jobs and their associated FEPs. Jobs can also include encrypted domains, providing secure traffic isolation. Provisions exist for Jobs with flexible membership, catering to dynamic service environments. These LibFabric concepts and commands are mandatory components.
Next, the UE Transport Layer is responsible for delivering LibFabric commands and data content to FEPs, potentially over Ethernet, but ideally with support from optional layers.
The Packet Layer: Section 3.2
The specification truly becomes interesting in section 3.2, which details the packet layer. Though not explicitly credited, this layer appears to draw heavily on extensive vendor experience with modular switches. It involves chunking LibFabric messages into smaller packets and routing them flexibly, with explicit consideration for reliability and flow control. A stated UEC goal is to integrate these functions into the transport layer. Datacenters have such low latency that they need hardware-accelerated error recovery and flow control to get the best, smooth traffic. Packets introduce additional headers but facilitate the exchange of network operational information between NICs and switches, independent of message flow. In modular switches, a second, interior layer of switches handles this via packets; UEC, however, relies on NICs generating packets with enhanced flow control, carried by the augmented Ethernet.
UEC is explicitly designed for "fat" networks, characterized by multiple, equidistant, and equally fast paths between FEPs. A common modern implementation is a "rail" configuration. In a UEC network, this might involve a NIC with, for instance, an 800GbE interface comprising 8 lanes of 100 Gbps. At the switch rack, each of these 8 lanes connects to a different switch, perhaps 8 switches, each with 512 x 100G ports. This allows up to 512 FEPs to connect to these 8 ports. The UEC NIC is designed to "spray" messages across all 8 lanes by assigning an "entropy" number which hashes the lane assignment at each choice of output lane in the path. The sender chooses an entropy value to balance use of pathways to fill the full 800 Gbps throughput. Crucially, CPU or GPU applications remain unaware of this complexity; they simply queue messages via LibFabric, and the NIC handles the "magic of rails".
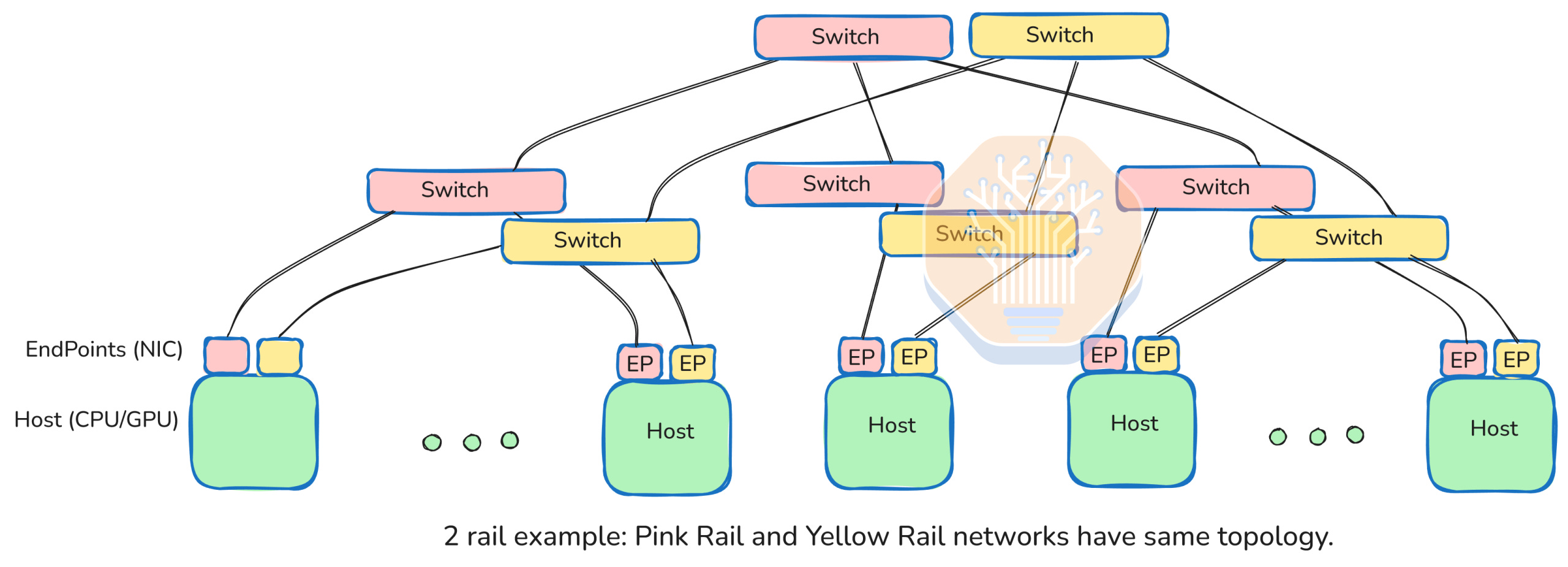
Rail magic enables 512-port switches (currently popular choice) switches to be used in parallel, with same topology, to get the benefits of multiples of throughput. The big step forward is for the endpoints to be coordinated by UEC inside a single NIC so the host sees the large throughput and the NIC distributes the traffic across all paths. The broad switch radix is invaluable for building large clusters while the consistent topology simplifies network build and management. UEC NICs are engineered to handle routing even through multiple switch layers. As a bonus, the packets on multiple paths allow the UEC NICs to provide extremely fast lost packet replacement and super-fast flow control, ensuring smooth traffic flow even under suboptimal application scheduling or occasional network link flaps.
Sections 3 through 3.4 extensively detail packet and header construction, with some relation to LibFabric semantics. Headers can be significant, up to 44 bytes, though optimized headers for frequent, shorter packets can be as small as 20 bytes. At the slowest expected UEC lane speed of 100Gbps, 20 bytes - 160 bits - translates to roughly 1.6ns. While UEC's maximum throughput will be less than bare Ethernet's theoretical maximum—modular switches typically use a slightly faster backplane to absorb packet overheads—UEC's Ethernet acts as the backplane, resulting in a slightly slower user data rate. This trade-off is made for nearly perfect flow, which should generally improve actual data rates.
Section 3.5 (page 219!) dives into the specifics of packet operation. Unlike the commands and queues, this is unique to UEC. It appears comprehensively specified, clearly leveraging modular switch experience, but no external reference is provided, suggesting a consensus design rather than derivation from any single market solution. This also makes sense given UEC's reliance on Ethernet as a backplane, whereas modern modular switches use proprietary backplanes.
Connections are established on the fly, without ACK (a reply acknowledging receipt) overhead, as messages are fragmented into packets. While all packets for a single message follow the same chosen lanes (facilitating repair and reassembly), messages themselves can and will be sprayed across different lanes. Lane selection is guided by an "entropy" value in the header (unrelated to true entropy), which represents routing choices and has associated flow control.
When encryption is enabled, there will be some overhead (a mandatory round-trip ACK) for establishing packet connections. Real-world performance will necessitate benchmarking with encryption. Hopefully, this cost will not be substantial.
Lost packets are inferred from sequence numbers and replaced via specific requests, a sensible approach in datacenters expected to have extremely low packet loss rates (otherwise, larger systemic issues are present).
Congestion Control: UEC-CC (Section 3.6)
Section 3.6 introduces UEC-CC, the congestion management system—optional, but a core reason for wanting UEC. The design choices here are wise. UEC-CC employs a time-based mechanism with sub-500ns accuracy transit times. Forward and backward paths are measured independently, implying NIC synchronization on absolute time, though this isn't explicit in the spec. Measuring both directions allows for accurate congestion attribution to senders and receivers. Switches are required to use ECN (Explicit Congestion Notification) if UEC-CC is enabled, and are expected to use the modern ECN variant where the congestion flag is set per traffic class and measured immediately before packet transmission. This provides the most current congestion information and differentiated handling per traffic class. In severe congestion, packets can be trimmed, leaving only a tombstone header to explicitly inform the receiving NIC of the bad news - simply dropping a packet slows the corrective action.
This mechanism is critical because the receiving FEP (one or more per NIC) is responsible for pacing senders. With datacenter round trip times (RTTs) of only a few microseconds, senders have a very short window of data they can transmit without receiving an ACK. The receiver decides how many new packets are granted, allowing senders to be paused within microseconds, generally preventing losses. The receiver gathers rich traffic condition information from ECN flags, distributed across multiple lanes and traffic classes, giving it both individual credit counts and an overview of all arrivals. It communicates its decisions to senders via ACKs and a special Credit CP command.
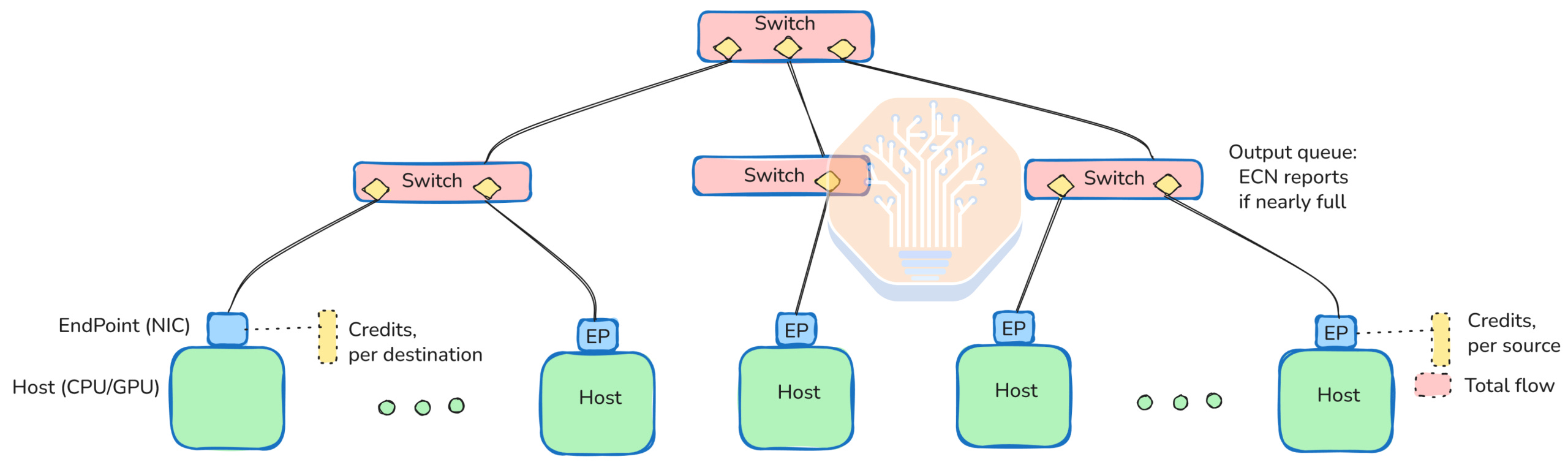
These decisions can also rebalance routes by adjusting specific "entropy capacities," thereby altering the balance used for message spraying. UEC standardizes some level of reporting on (forward) error correction rates and packet drops, enabling detection of specific entropies using a weak link and rerouting traffic to avoid it. Entropies hash hop choices at each switch, and there are expected to be an order of magnitude more entropies than lanes, allowing a weak link to be isolated with minimal impact on overall route capacity.
Crucially, UEC-CC deprecates some flow control methods. The widely used older methods RoCE and DCQCN will degrade UEC-CC performance because, unlike UEC-CC, they do not directly update flow control to match the actual location of a flow problem. PFC (Priority Flow Control) is unnecessary and must be disabled between switches, where it can block valid flows. It is also deprecated where NICs connect to switches, as it lacks UEC-CC's precision and may over-reduce flows. Credit Based Flow Control is similarly deprecated due to interference with UEC-CC.
Transport Security Sublayer (Section 3.7)
Section 3.7, the Transport Security Sublayer, is deeply technical and appears highly competent. It borrows heavily from proven approaches while incorporating useful updates. The recommended encryption is a post-quantum DES cipher. Significant attention is paid to defensive operation, with rules for regular nonce changes. Encryption is assigned per domain, a subset of FEPs within a Job, including a variant for adaptive domains supporting dynamic services with clients joining and leaving. A clever key derivation scheme allows a single key to be used throughout a domain, with every flow employing a distinct key and nonce, yet requiring minimal table space (Jobs can have tens of thousands of endpoints).
The datacenter fabric must include trusted components: a Secure Domain Management Entity, which sets up domains, and NICs that contain trusted hardware for their port into the domain. While verifying and attesting to the version of these components is outside the UEC spec's scope, open standards exist that vendors could be asked to support.
Section 3.8 provides a useful list of references for section 3.7.
Other Layers
Section 4, the UE Network Layer, primarily discusses packet trimming, an optional feature for congestion control.
Section 5, the UE Link Layer, aims to improve overall performance through link-level packet replacement and flow control between switches. This strikes me as unwarranted complexity, particularly given the deprecation of CBFC (which this layer implements) in the UEC-CC section. In a datacenter with microsecond round-trip times, where receiver FEPs make quality flow control decisions with global traffic information, and packet losses are rare and UEC can already flow around them while repairs are schedule (Section 6 helps!). This part of the spec appears to add complexity without commensurate value. Fortunately, it's optional, and I would wager it will never see widespread use. It will certainly complicate testing and plugfests (multi-vendor interoperability meetups).
Section 6, the UE Physical Layer, mainly recommends multiple lanes of 100Gb Ethernet, adhering to 802.3/db/ck/df specifications. A brief apology notes the inability to cite 200Gb due to its unofficial status. UALink spec has no problem referencing 200Gb, and that is where the wind is blowing. UEC should aim to start there, not just get there.
Subsection 6.3 explores using FEC (Forward Error Correction) telemetry to monitor and estimate link-level reliability. While fascinating to any network enthusiast, the gist is simple: FEC is incredibly effective, making lost packets on a properly initialized datacenter link an exceedingly rare occurrence. Good to see it in the spec.
UEC: Key Advantages
In summary, the compelling reasons to adopt UEC include:
Hardware-accelerated LibFabric.
A well-designed Job structure integrated with modern encryption.
Datacenter Congestion Control, implemented correctly.
Elimination of the problematic RoCE and DCQCN.
Existing open-source plugins for CCL, MPI, SHMEM, and UD.
UEC: Cautions
It's worth noting that plugin support for Amazon EFA networking, which uses LibFabric, hasn't been straightforward. While the plug-in configuration is provided, Nvidia's stance is often unsupportive, preferring their proprietary solutions despite supporting the underlying interface. While the plugin reportedly yields good performance from EFA NICs, the performance with newer UEC NICs remains to be seen.
General interoperability must be checked, including not just “it works” but also to see that performance holds up when endpoints are from different vendors. It will also be useful to see how well UEC NICs work when the network in the middle is not UEC – so long as you ensure the switches do support features like best practice ECN generation that UEC does use and require.
Comparison to UALink and SUE
Ultra-Accelerator Link's spec is less than half the length of UEC's, even though written with similar care. The Broadcom Scale-Up Ethernet description is careful but informal, a mere 20 pages, and assumes what it describes is simple and obvious.
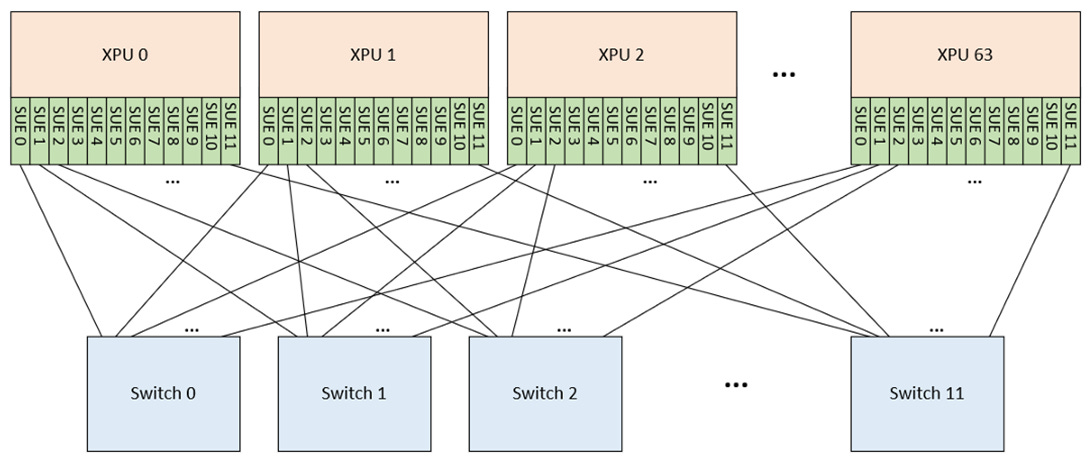
Both UALink and SUE focus exclusively on ScaleUp, akin to Nvidia NVLink. They support only a single switch layer and up to 1024 ports (i.e., GPUs or xPUs). This is significantly more limited than UEC's goal of scale-out networks with multiple switch layers and tens of thousands of endpoints. All three specifications assume an AI or HPC cluster with rail networks that maximize switch radix.
SUE and UALink confidently refer to 200GbE links within their specifications, making UEC seem somewhat behind the curve.
UALink, like UEC, sprays traffic across rails. UALink explicitly details a credit-based flow control. SUE, conversely, defers this by recommending its implementation within Ethernet with help from client software - a simpler spec, with much the same practical result. UALink binds 4 lanes together (e.g., 4x200) for faster message transmission, while both SUE and UEC appear to assume 200G lanes are already sufficiently fast. This is one area of extra complexity in UALink that appears of marginal value.
SUE recommends that Ethernet handle flow control via PFC or, preferably, Credit Based Flow Control. This approach should certainly work, given the single switch level where PFC is mostly effective, while CBFC would offer smoother operation.
UALink implements encryption for connections. SUE, more simply, states that reliability, data integrity, and encryption should be provided by Ethernet.
SUE delegates message spraying and load balancing across rails to the software layer within the endpoints. This is a clear win for companies specializing in such software.
Both SUE and UALink offer memory-mapped interfaces. Neither spec dictates the memory-map's implementation, but they expect message transmission/reception via reading or writing to a memory address corresponding to another endpoint in a large virtual system. These should be as efficient as NVLink but will require a plugin or new low-level code, as they do not copy NVLink's packet formats.
Memory Mapping and Host Fabric
Memory-mapped is often cited as “memory semantics”. Mapping - using a large virtual address space to assign every host its own identifiable range - allows the host processors to use read and write instructions, memory operations. They do not include memory semantics such as ordering and coherency. No memory snooping is occurring, no clever updating of caches around the cluster happens.
For all of these systems including UEC the speed of operation and low latency in the datacenter is causing the endpoints to move to be coprocessors on the host chip fabric, not held at a distance over an increasingly archaic “IO bus”. It is more like the endpoint (NIC) is just another core in a multicore system. This simplifies efficient interop from the compute cores (streaming GPU or classic CPU) to send commands and for the endpoint to interact with memory on the host.
We can expect SUE and UALink to show up as IP blocks integrated into host chips rather than looking to find them as separate chips. NVlink has been like that for a while, and chips like Intel Gaudi 3 or Microsoft Maia 100 also do that with ethernet links. This simplifies the IP blocks but also requires them to be simple to reduce their footprint in the host chips. UEC's complexity is likely to show up in separate NICs but integration into the host fabric should be expected soon. Maybe as chiplets?