

ClusterMAX™ 2.0: The Industry Standard GPU Cloud Rating System
95% Coverage By Volume, 84 Providers Rated, 209 Providers Tracked, 140+ Customers Surveyed, 46,000 Words For Your Enjoyment
Introduction
GPU clouds (also known as “Neoclouds” since October of last year) are at the center of the AI boom. Neoclouds represent some of the most important transactions in AI, the critical juncture where end users rent GPUs to train models, process data, and build inference endpoints.
Our previous research has set the standard for understanding Neoclouds:



Since ClusterMAX 1.0 was released 6 months ago, we have seen significant changes in the industry. H200, B200, MI325X, and MI355X GPUs have arrived at scale. GB200 NVL72 has rolled out to hyperscale customers and GB300 NVL72 systems are being brought up. TPU and Trainium are in the arena. And many buyers are turning to the ClusterMAX rating system as the trusted, independent third party with a comprehensive, technical guide to understanding the market.
An update is needed!
Executive Summary
YouTube summary video available here!
ClusterMAX 2.0 debuts with a comprehensive review of 84 providers, up from 26 in ClusterMAX 1.0. We increase our market view to cover 209 total providers, up from 169 in our previous article and 124 in the original AI Neocloud Playbook and Anatomy. We have interviewed over 140 end users of Neoclouds as part of this research.
We release an itemized list of all criteria we consider during testing, covering 10 primary categories (security, lifecycle, orchestration, storage, networking, reliability, monitoring, pricing, partnerships, availability).
We release five descriptions of our expectations, covering SLURM, Kubernetes, standalone machines, monitoring, and health checks. We encourage providers to use these lists when developing their offerings. We consider the lists as an amalgamation of our interviews with end users, and continue to pursue the quality when developing their offerings.
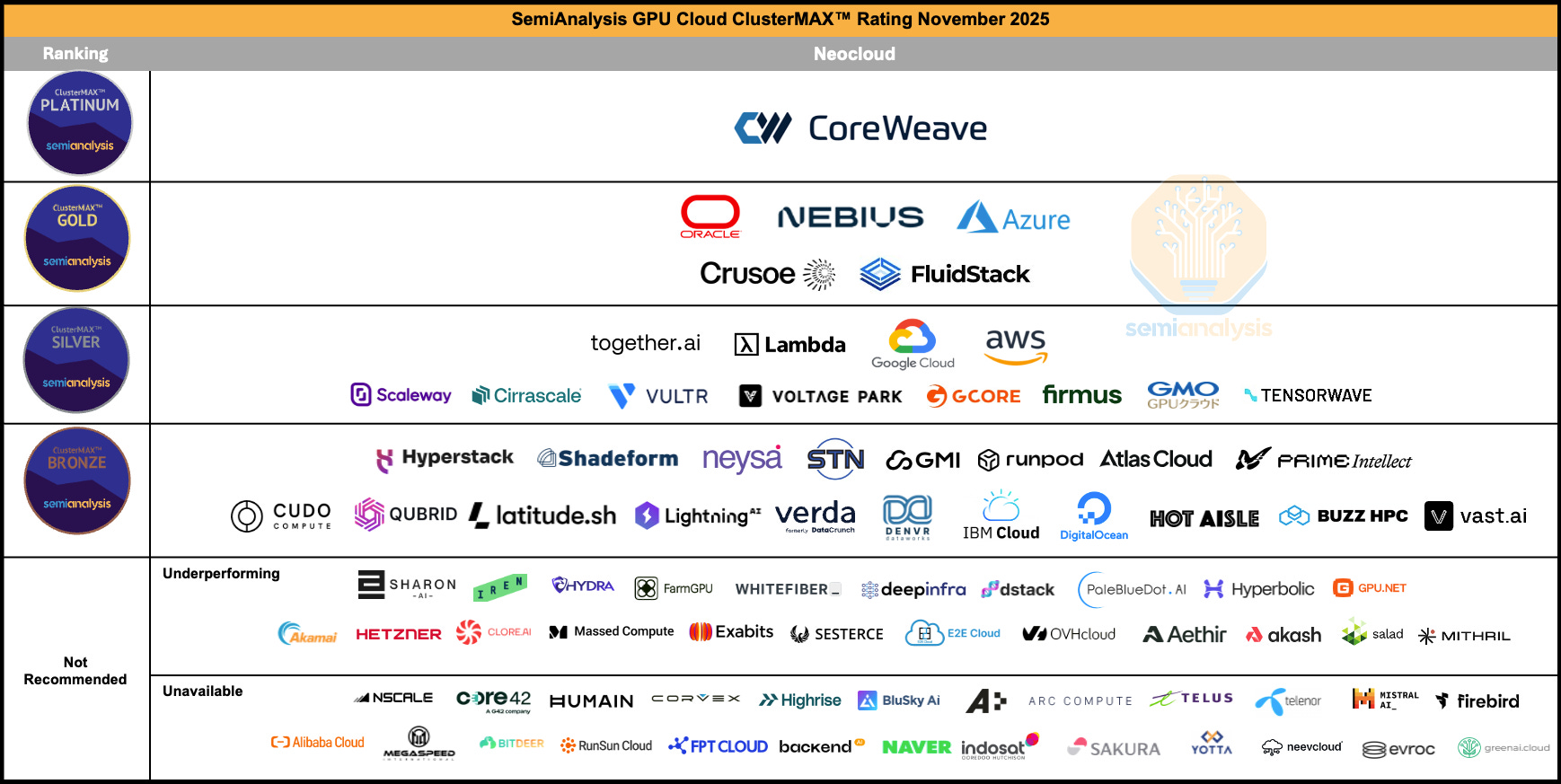
CoreWeave retains top spot as the only member of the Platinum tier. CoreWeave sets the bar for others to follow, and is the only cloud to consistently command premium pricing in our interviews with end users.
Nebius, Oracle and Azure are the top providers within the Gold tier. Crusoe and new entrant Fluidstack also achieve Gold tier.
Google rises to the top of the Silver tier, alongside AWS, together.ai and Lambda. Many more clouds from all around the world debut at the Bronze or Silver tier, for a total of 37 clouds achieving a medallion rating.
We provide analysis of key trends: Slurm-on-Kubernetes, Virtual Machines or Bare-Metal, Kubernetes for Training, Transition to Blackwell, GB200 NVL72 Reliability and SLA’s, Crypto Miners Here To Stay, Custom Storage Solutions, Cluster-level Networking, Container Escapes, Embargo Programs, Pentesting and Auditing
For providers that have deployed both AMD and NVIDIA GPUs, the quality of their AMD cloud offering is much worse than their NVIDIA cloud offering. AMD offerings tend to be missing critical features like detailed monitoring, health checks with automatic remediation, and working SLURM support when compared to NVIDIA.
As a companion to this article, we release https://www.clustermax.ai/, a one-stop shop to review our current criteria, expectations, and results moving forward
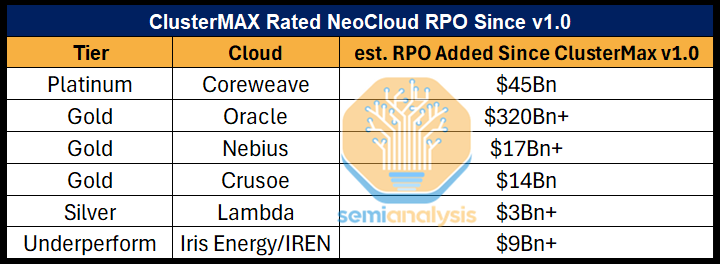
Before we even get to the results, we’d like to point that since releasing v1.0 in late March, our highest rated Neoclouds have collectively booked nearly $400Bn in Remaining Performance Obligations (RPOs). This further reinforces the idea that our rating system translates well across the ecosystem from technical users to key decision makers looking to contract compute.
Results
ClusterMAX 2.0 debuts with an updated ranking list:
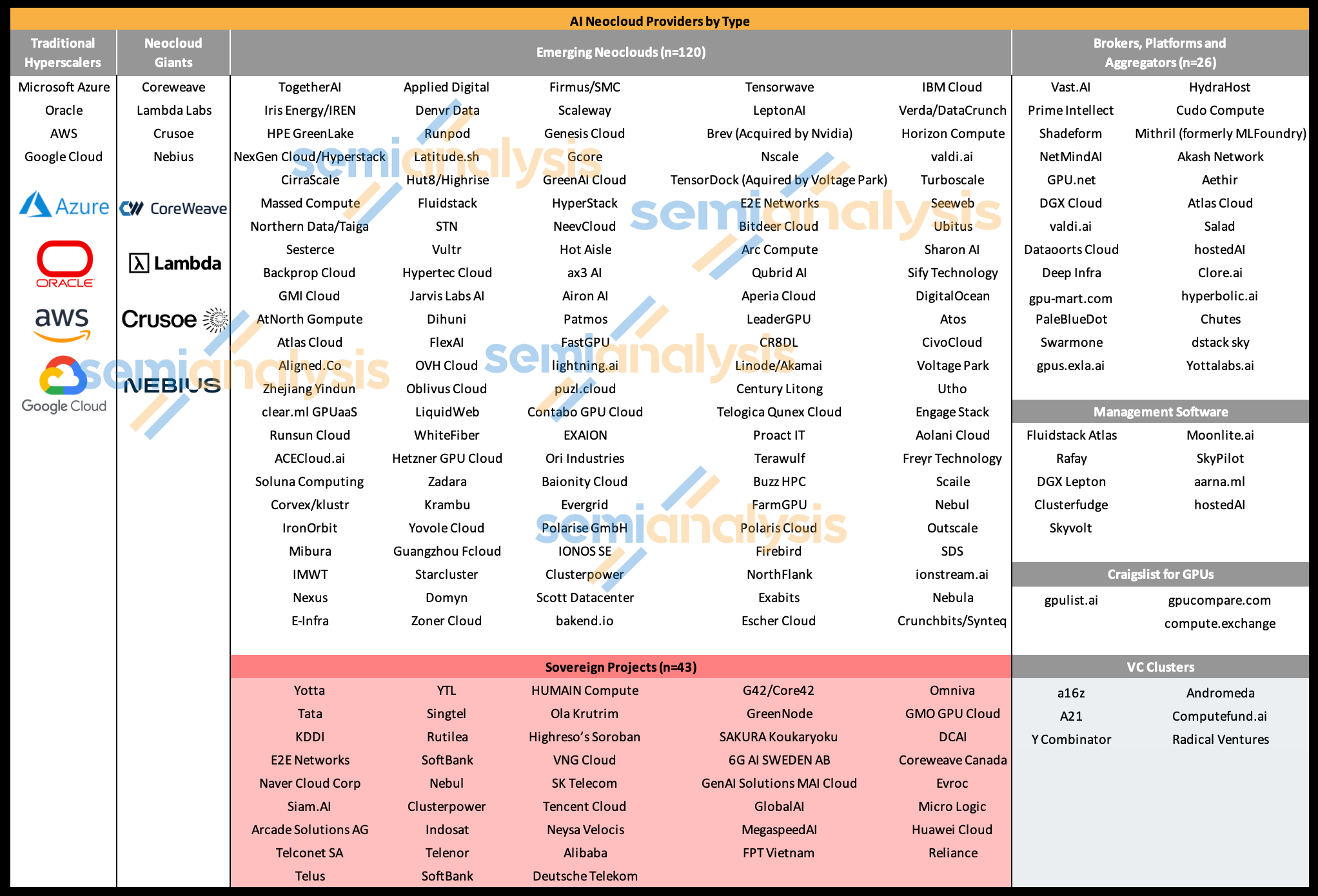
We also release an updated market tracker by type:
Many people have contributed to this research. We thank all ClusterMAX supporters at the leading AI labs, hardware OEMs, investors, startups, industry influencers and more. The impact of ClusterMAX has been immense. For a complete list of quotes from notable members of the community supporting our work, please see https://www.clustermax.ai/quotes
We received two clear pieces of feedback when we released the first version of ClusterMAX:
People who saw only the results table wondered why, exactly, a given cloud had been given a certain rating.
People who read the first article (an estimated 76 minute read with over 20,000 words) wanted even more detailed information on our experience.
For reference, Animal Farm checks in at 29,800 words and the dialogue of the movie “Social Network” about Zuck co-founding Facebook is 34,000 words
This ClusterMAX 2.0 article is over 46,000 words
In this article we attempt to strike the balance between useful summary information and detailed technical information that accurately describes our experience. More information is always available upon request to clustermax@semianalysis.com.
We Are Hiring - ClusterMAX
If you enjoy this article and have a unique technical perspective on Neoclouds, we would love to work with you. Please consider joining us to work on ClusterMAX 2.1, ClusterMAX 3.0 and beyond:
Key Responsibilities
Lead the development of next generation benchmarks and TCO analysis for publication in future versions of ClusterMAX™ and related projects.
Collaborate with executives and engineers from over 203 neoclouds, hyperscalers, marketplaces, and sovereign projects
Establish and maintain partnership with AI Chip manufacturers, startups and OEMs such as NVIDIA, AMD, Intel, etc
Build on existing relationships with leading AI labs, investors, startups, and community members to gauge their experience working with cloud providers and contribute expertise
Author detailed technical research reports analyzing benchmark results, reliability, and ease of use
Stay current on emerging trends and technologies by attending major conferences such as NeurIPS, MLSys, NVIDIA GTC, OCP, SC, HotChips and more. Travel is encouraged but not required
Qualifications
Experience with ML frameworks such as PyTorch or JAX
Experience with GPU or TPU clusters running kubernetes or slurm
Experience with filesystems such as Weka, VAST, Lustre, and GPFS
Experience with interconnects such as InfiniBand and RoCEv2
Experience with ML system benchmarking (GEMMs, nccl-tests, vllm, sglang, mlperf, STAC, HPL, FIO, torchtitan, megatron, etc.)
Experience working at a hyperscaler, neocloud, server OEM, chip manufacturer, or large scale user of these technologies (preferred)
Proactive and capable of working in a global, distributed team
Rating Tiers
Following an evaluation against 10 key criteria (Security, Lifecycle, Orchestration, Storage, Networking, Reliability, Monitoring, Pricing, Partnerships, and Availability) we assign one of five ratings to a given Neocloud (Platinum, Gold, Silver, Bronze, or Underperforming).
It is important to understand that this is a relative rating system. In other words, the quality of the services offered by each Neocloud in each of the ten criteria is assessed relative to their peers. Checking boxes against all of the itemized criteria is a good start, but it is important to note that Gold and Platinum Neoclouds rise to the top by introducing new features and functionality that others do not have, and customers appreciate.
ClusterMAX™ Platinum represents the best GPU cloud providers in the industry. Providers in this category consistently excel across evaluation criteria. Platinum-tier providers are proactive, innovative, and maintain an active feedback loop with their user community to continually raise the bar. In practice, Platinum-tier providers are able to command a pricing premium over their competitors, due to a recognition that the TCO of their offering is better, even if the raw $ per GPU-hr is higher when compared directly to a competitor.
ClusterMAX™ Gold includes strong performance across all evaluation categories, with some opportunities for improvement. Gold-tier providers may have small gaps or inconsistencies in the user experience, but generally demonstrate responsiveness to feedback and a commitment to improvement. Gold-tier providers are a great choice, and generally win deals, especially if they have the best price per GPU-hr and the cluster is available on the customer’s expected timeline.
ClusterMAX™ Silver is an adequate GPU cloud offering but may have noticeable gaps compared to gold or platinum-tier providers. Some users will not consider an offering from a silver tier provider due to these gaps, regardless of an attractive price per GPU-hr and good availability. In general, silver-tier GPU clouds have room for improvement and growth, and we encourage them to adopt industry best practices in order to catch up to their peers.
ClusterMAX™ Bronze includes all GPU cloud providers that fulfill our minimum criteria, and is the last of the providers that we directly recommend to anyone, in any circumstance. Common issues may include inconsistent support, subpar networking performance, unclear SLAs, limited integration with popular tools like Kubernetes or Slurm, or less competitive pricing. Providers in this category need considerable improvements to enhance reliability and customer experience. Some of these providers in this category are already making considerable effort to catch up and we look forward to testing with them again soon.
Not Recommended is our last category, and the name speaks for itself. Providers in this category fail to meet our basic requirements, across one or more criteria. It is important to note that this is a broad category, so in the body of the article we describe what exactly each cloud is missing. The Not Recommended list is further broken down into two categories:
Underperforming – based on our hands-on testing, we believe that providers in this category can quickly rise to bronze or even silver if they fix one or more critical issues. Examples of critical failures include but are not limited to: no modern GPUs available (i.e. only A100, MI250X, or RTX 3090, since we expect at least H100 to be available), not having basic security attestation completed (e.g. SOC 2 Type I/II, or ISO 27001), mistakenly disabling key server features (i.e not disabling ACS, or not enabling GPUDirect RDMA), or conducting offensive business practices such as charging users for GPU hours while a cluster is being created or while servers are down due to hardware failure.
Unavailable – providers in this category have an interesting service that we are excited about, but have no way to verify as it is not available to the public or for us to test. Examples include providers that have not launched their service yet (despite marketing material that would have you thinking otherwise), providers that are completely sold-out with no plans to add new capacity, providers that exclusively serve secure government customers, or other reasons. We are excited about many of the providers in this category but maintain a “trust but verify” approach to our testing and keep them in this category until we can complete hands-on testing.
Rating Criteria
To provide a more detailed description of how we compare Neoclouds across 10 key criteria, we present an itemized list of the testing criteria that we used in ClusterMAX 2.0. Notably, this list was sent to all GPU cloud providers where we have working relations on August 6th. We believe that many clouds delayed cluster handover for weeks following, and rushed to create or modify services to meet our expectations. For example, we had cloud providers that had never installed slurm before try to install it for the first time about a week before handing over a cluster to us. We had others attempt to enable RDMA-capable networks on kubernetes for the first time. And we had even more patching critical security vulnerabilities in their services that they had just learned about from our outreach.
While we appreciate the effort, and believe it is good for the ecosystem to raise the bar, we have penalized clouds that exhibited significant delays during cluster handover. And, via interviews with 140+ cloud users during this effort, we have done our best to assess what is “current state” vs “future state”. In other words, of the services that we are testing, what is public, general availability (GA), and used by customers, vs what is still planned and not rolled out yet.
We conduct this research in an attempt to simplify, for users, an assessment of whether or not the slurm, kubernetes, or standalone machine is properly configured and will meet their expectations. We have heard from many users about the process of “giving back” a cluster, or even playing “Russian Roulette” with certain marketplaces that offer access to a single machine. In these cases, issues with reliability of the GPU drivers, GPU server hardware, backend interconnect network, shared storage mounts, internet connection, and more can cause users to lose faith in a provider, and churn out. While we can’t measure reliability at scale over time, we do assess what we can in a ~5 day long test.
For those curious, a full, live, and regularly updated list of itemized criteria is available on the ClusterMAX website at https://www.clustermax.ai/criteria. For users of Neoclouds, we encourage outreach regarding criteria you would like to see represented in this list. In particular we want to thank Mark Saroufim of GPU MODE for his contribution regarding the Nvidia Nsight Compute profiling available for users to profile GPU kernels, without sudo privilege required on the compute nodes. More detail available here: https://clustermax.ai/monitoring#performance-monitoring
Our itemized list looked like this when it went out on August 6th:
Security
Do you have relevant attestation in place from a third-party auditor that your company processes meet basic standards? (SOC2 Type 1, ISO 27001, etc.)
Do you have more specific compliance in place for global customers (i.e.can you sell services globally?)
Is your backend network setup securely for multi-tenant users (InfiniBand Pkeys, VLANs)
Are drivers and firmware up to date, and what is the process for notification and patching of future vulnerabilities?
Lifecycle
Is it easy to onboard and offboard to the service, are there hidden costs?
How easy is it to create a cluster?
Is it easy to expand a cluster over time?
Is it easy to use the cluster? (i.e. download speed, upload speed)
How good is the support experience?
Orchestration
Is the cluster setup properly with reasonable defaults? (OS version, sudo, ssh, basic packages pre-installed like git, vim, nano, python, docker)
How easy is it to add/remove users, groups and permissions?
Can you enforce RBAC on the cluster’s compute and storage resources
Integration with external IAM provider for SSO
For SLURM: modules, pyxis/enroot, hpcx/mpi, nvcc, nccl, topology.conf set, dcgmi health -c, LBNL node healthcheck or equivalent, prolog/epilog, GPU Direct RDMA all configured correctly
For Kubernetes: easy to download and use kubeconfig, cni configured, arbitrary helm charts, GPUOperator and NetworkOperator able to request resources easily, default ReadWriteMany StorageClass available, metallb or external LoadBalancer, node-problem-detector (or equivalent), all configured correctly
On both slurm and kubernetes: nccl-tests or rccl-tests runs at full expected bandwidth, multinode torchtitan training job runs at expected MFU (via pytorchjob, jobset, volcano batch or other equivalent CRD for k8s training)
For kubernetes only: multi-node p-d disagg serving with llm-d works at expected throughput
Storage
POSIX-compliant filesystem available (e.g.Weka, VAST, DDN)
S3-compatible object storage available (i..easy to use AWS S3, Azure Blob, GCS, R2, CAIOS, Scality)
Mounts available for /home and /data (or equivalent) on slurm, default RWM SC on k8s
Local drives or distributed local fs available for caching on /lvol (or equivalent)
Storage is scalable and performant
Networking
InifiniBand or RoCEv2 available
MPI implementation available (i.e.hpc-x available via default mpirun)
Default NCCL configuration in /etc/nccl.conf is reasonable
nccl-tests or rccl-tests or stas all_reduce_benchmark.py runs at full bandwidth
multinode torchtitan training job runs at expected MFU
SHARP support for improved nccl performance at scale
NCCL monitoring plugin available
NCCL straggler detection available
Reliability
Hardware uptime SLA is available and reasonable (i.e.99.9% on compute nodes, 99% on racks)
24x7 support is available, 15-minute response SLA
No link flapping on the interconnect network
No filesystems unmounting randomly
WAN connection is stable over time, upload/download speed is reasonable
Full suite of Passive Health Checks
https://docs.nvidia.com/datacenter/dcgm/latest/user-guide/feature-overview.html#background-health-checks
Detect and drain when: GPUs fall of the bus, PCIe errors, IB or RoCEv2 events/link flaps, thermals out of range, ECC errros on GPU or CPU memory, XID or SXID’s, NCCL/RCCL stalls
Full suite of Active Health Checks
Lightweight test suites run in prolog/epilog or hourly/daily in a low-priority partition on idle nodes
Aggressive test suite runs weekly on idle nodes
DCGM level 1, 2, 3 with EUD, DtoH and HtoD bandwidth, local NCCL test, local IB test, pairwise GPU and CPU ib_write_bw, ib_write_latency, GPUBurn or GPU Fryer, NVIDIA TinyMeg2, UberGEMM, multinode megatron or torchtitan job matches reference numbers
Monitoring
Grafana or an equivalent dashboard is pre-installed and accessible with high-level and low-level view of cluster information
Easy to configure custom alerting
SLURM integration for job stats, resource usage, summaries (sacct)
Kubernetes integration (kube-state-metrics, node-exporter, dcgm-exporter, cAdvisor)
DCGM information available
SM Active monitoring via DCGM_FI_PROF_SM_ACTIVE
SM Occupancy monitoring via DCGM_FI_PROF_SM_OCCUPANCY
TFLOPs estimation via DCGM_FI_PROF_PIPE_TENSOR_ACTIVE
PCIe AER rates monitoring via DCGM_FI_DEV_PCIE_REPLAY_COUNTER
GPU and CPU memory errors via DCGM_FI_DEV_ECC_SBE_VOL_TOTAL
Node level health status: power draw, fan speed, temperatures (CPU, RAM, NICs, trasceivers, etc.)
PCIe, NVLink or XGMI, InfiniBand/RoCEv2 throughput
dmesg logs (i.e.promtail)
Pricing
Generally, lower prices per GPU-hr are better for end users, assuming the quality does not change
Consumption models (1 month, 3 month, 6 month, 1 year, 2 year, 3 year)
Individual charges for storage, compute nodes, network, etc.or bundled
Expansion and extension of existing contracts
Partnerships
AMD or NVIDIA investment
NVIDIA NCP certification
NVIDIA exemplar cloud performance certification
AMD Cloud Alliance status
Knowledge of security updates (e.g., follow Wiz)
SchedMD partnership (makers of SLURM)
Participation in industry events, ecosystem support
Availability
Total GPU Quantity and Cluster Scale Experience
On-demand availability, utilization, capacity blocks
Latest GPU Models Available (H100, H200, B200, MI300X, MI325X, MI355X)
Roadmap for Future GPUs (B300, GB200 NVL72, GB300 NVL72, VR, MI400, etc.)
Many notable improvements have already been made to this list since our testing window closed on September 15th, 2025. In order to accommodate new additions to the rating system, we will be accepting anyone attempting to move onto the leaderboard and achieve a ClusterMAX medallion status in the coming weeks. To achieve this, we will progressively release minor versions, i.e. ClusterMAX 2.1, without re-testing all providers.
When a notable change in the industry occurs, say when rack-scale systems such as GB200, GB300, VR200 and MI450X gain widespread market adoption we will move to a major version upgrade, i.e.ClusterMAX 3.0. We expect this to be every ~6 months.
Example Tests
Many industry analysts and financial speculators believe that GPU compute has turned into a commodity, easily compared by the price per GPU-hr. We think that price is just one of many criteria that buyers consider when committing to a cluster, or even a virtual machine.
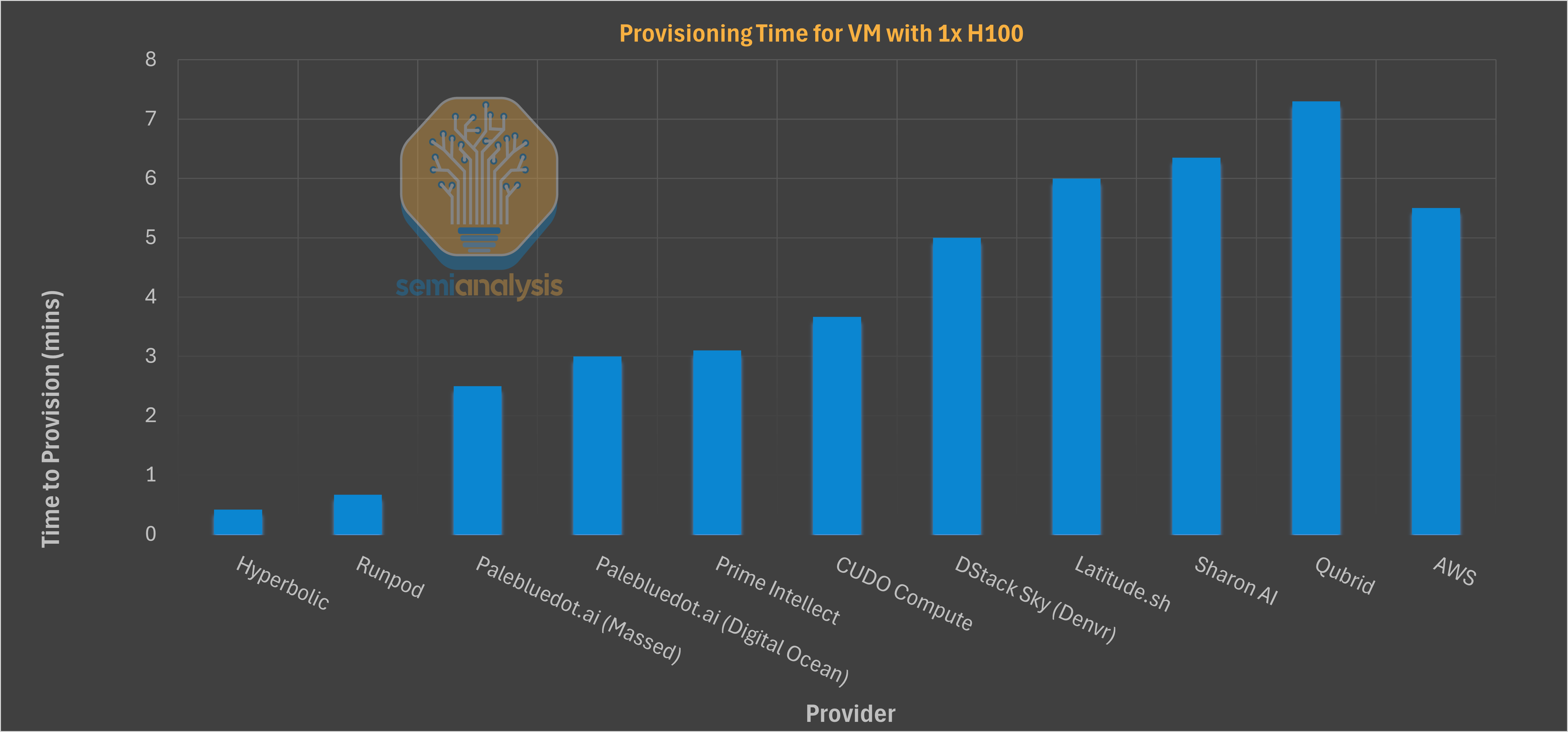
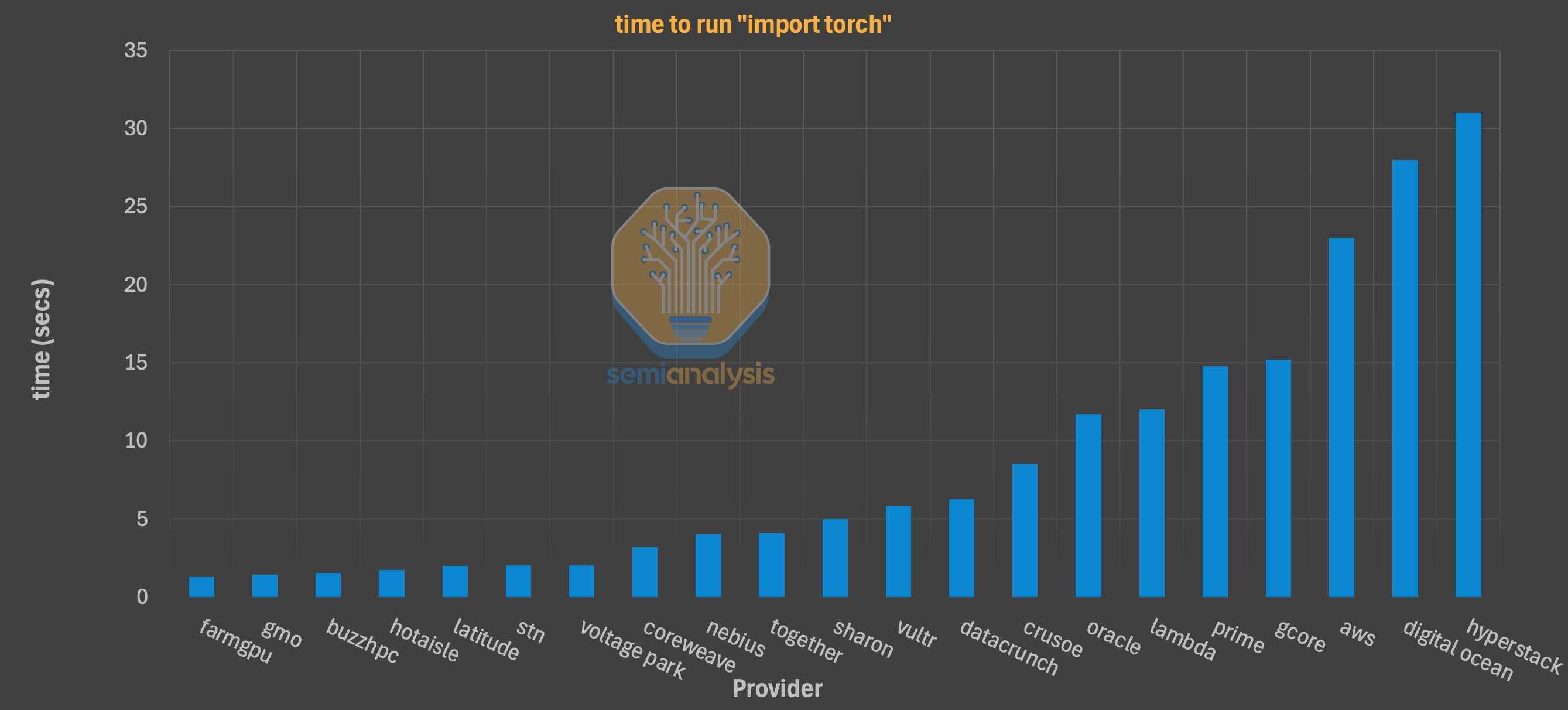
These simple tests generally complete in under one minute. We treat them as a proxy to reveal underlying issues with network configuration, storage performance, peering, and virtualization overhead. A provider that fails these basic setup tasks will almost certainly fail at running a multi-week, multi-node training job. Below are some direct comparisons for useful information that compare GPU clouds directly:
Time to install PyTorch via uv and via pip. This is a proxy for WAN connection quality and local disk I/O for small file operations. Using the modern uv installer, we saw a massive divergence. Best-in-class providers (e.g., CoreWeave, GCP) completed the install in ~3.2 seconds. The median time was ~8.5 seconds, while one Bronze-tier provider took a staggering 41.2 seconds. Using pip was universally slower, with a median of ~28 seconds, highlighting the penalty for not adopting modern tooling.
Time to download pytorch container from NGC. A 22.1GB pull of the standard nvcr.io/nvidia/pytorch:24.05-py3 container is a critical test of a provider’s peering and local caching strategy. Platinum-tier providers like CoreWeave, which maintain local NGC mirrors, completed the pull in under 10 seconds. Gold-tier providers (e.g., Nebius, Oracle) were respectable at 45-60 seconds. Silver-tier providers often took 90-120 seconds, and many Bronze-tier providers exceeded 4 minutes, revealing a lack of basic infrastructure setup.
Time to run “import torch”. This measures the ‘cold start’ time for a developer, including driver initialization and library loading. Anything other than near-instant is a sign of misconfiguration or virtualization overhead. While the median was a tolerable ~1.8 seconds, we found multiple providers, particularly those with complex VM configurations, which have a frustrating 8-10 second delays.
Time to download 15B Microsoft/phi-4 model A real-world test of sustained WAN throughput from Hugging Face’s CDN. The median time was ~35 seconds (roughly 3.4 Gbps). Top-tier providers consistently achieved speeds over 6 Gbps, finishing in ~20 seconds, while others lagged significantly, increasing friction for researchers switching between models.
Time to load 15B Microsoft/phi-4 model into GPU memory A pure test of the local data path, from disk (local NVMe or shared filesystem) to GPU memory over PCIe. The median time here was ~12 seconds. Slower times directly correlate to a poor local storage tier, a bottleneck that will be felt during every checkpoint load.
Location of the machine and IP Ownership match expected provider name A simple whois on the machine’s public IP. This test is critical for exposing aggregators and resellers. In numerous tests of smaller providers, the IP ownership resolved back to Oracle, CoreWeave, or AWS respectively. This challenges some the provider’s marketing and raises questions about pricing and quality of support.
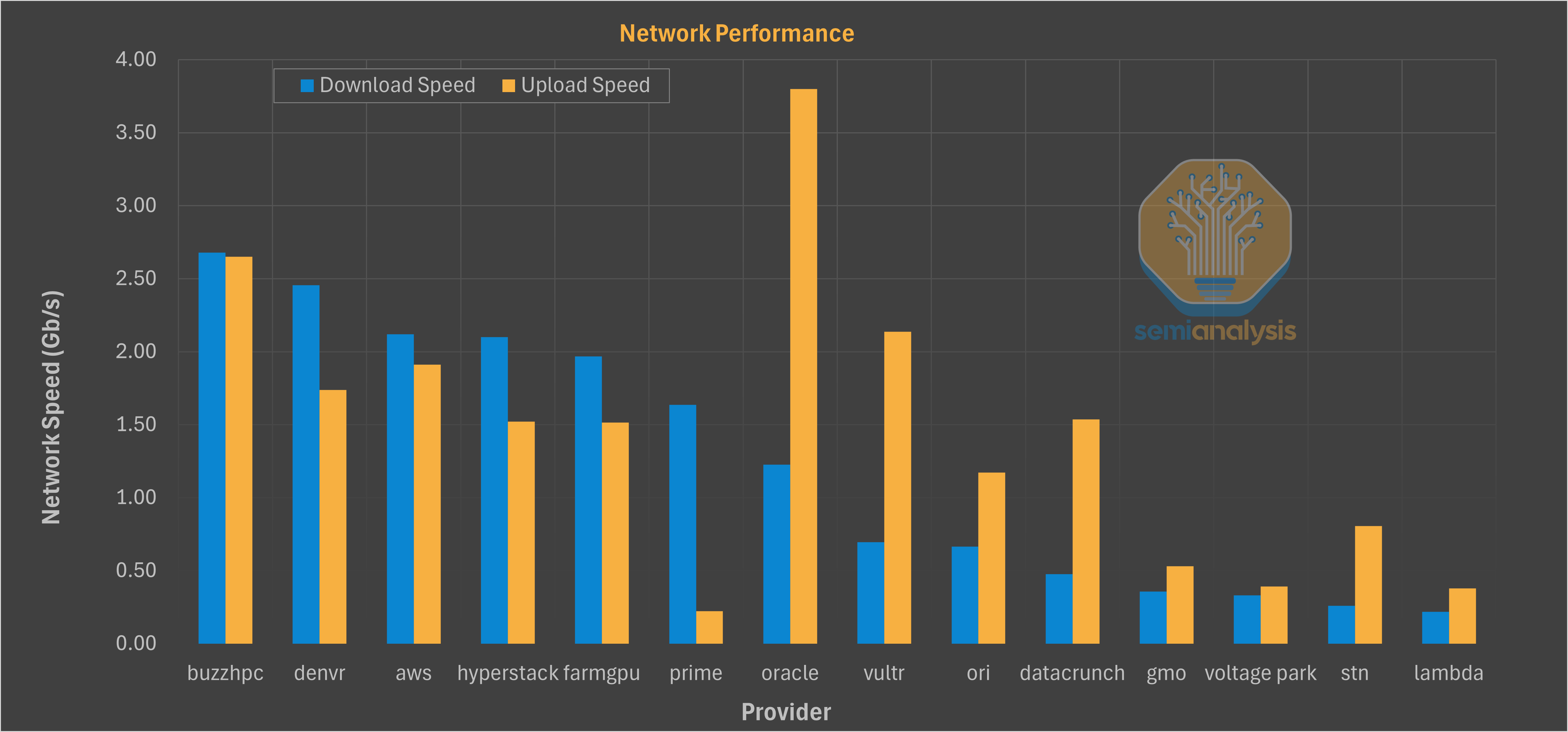
General network speedtest While synthetic, speedtest-cli is useful for spotting WAN saturation or traffic shaping. We saw a median download of ~4.5 Gbps and upload of ~2.8 Gbps. More interestingly, some providers (like STN) would post excellent, symmetrical 10 Gbps speedtest results, but then perform poorly on real-world file (e.g., NGC, Hugging Face) downloads, suggesting traffic management is in place to game these exact synthetic tests.
Interconnect bandwidth test (“nccl-tests” or “rccl-tests”) Using the open source repos, built with mpi or using a torch launch script maintained by Stas Bekman in the Machine Learning Open Book, we test the interconnect on synthetic allreduce, allgather, and alltoall workloads and compare to expected algbw and busbw results. This is a simple way to verify that the network is setup correctly and GPU Direct RDMA is enabled on the compute nodes. We run this test on SLURM via salloc/mpirun, salloc/srun, or sbatch/enroot/pyxis. We run this test on Kubernetes via the MPIOperator or via JobSet.
GEMM benchmark Using a custom script we verify that individual GPUs perform General Matrix Multiplication operations at expected performance (realized TFLOPs). This is a simple way to verify that the GPUs are performing as expected. We run this test directly in a python script.
Single node RL job Using the verifiers library from prime intellect, we run a GRPO training script to train a Qwen model to solve the puzzle game wordle and compare against expected training time per rollout on a given GPU. This is a simple way to verify that the GPUs are performing as expected. We run this test directly in a python script.
Multinode pretraining job Using the torchtitan library, we run a multimode pretraining script to train a Llama model on the C4 datasets, and compare against expected training time per step and MFU. This is an important way to verify that the GPUs and interconnect network are performing as expected. We run this test on SLURM via sbatch, and on Kubernetes via PyTorchJob or JobSet.
Multinode inference benchmark Using llm-d, we run a prefill-decode disaggregated endpoint serving a Qwen model. We verify that inference throughput on the vllm performance suite matches expected performance, and verify that performance improves as more copies of the model are deployed behind the endpoint. We run this test on Kubernetes only.
Some of the results are interesting to view when comparing providers directly:
Notable Trends
There are many notable trends changing how the Neocloud industry operates today and what customers expect from their providers. The following is a description of a few of these trends:
Slurm-on-Kubernetes
Virtual Machines or Bare-Metal?
Kubernetes for Training
Transition to Blackwell
GB200 NVL72 Reliability and SLA’s
Crypto Miners Here To Stay
Custom Storage Solutions
InfiniBand Security
Container Escapes, Embargo Programs, Pentesting and Auditing
Slurm-on-Kubernetes
Currently, there are three ways to run Slurm-on-Kubernetes
SUNK from CoreWeave
Soperator from Nebius
Slinky from SchedMD
There are major differences between the three Slurm-on-Kubernetes offerings. Below we describe the key differences between these projects, and how they are currently used by different providers and users in the Neocloud ecosystem.
CoreWeave’s SUNK was first to market, is proprietary, and continues to be the only viable solution for running both slurm and Kubernetes jobs on the same underlying cluster. For example, a batch queue of slurm training jobs, and an autoscaling inference endpoint on Kubernetes that compete for underlying GPU resources.
Next, Soperator from Nebius, which is open source has also seen widespread adoption amongst Nebius users that prefer slurm. Unlike SUNK, we are not aware of any users that use the kubeconfig/kubectl access to the underlying Kubernetes cluster to schedule workloads on Kubernetes. Instead, Nebius relies on autoscaling and node lifecycles to move GPUs between a slurm batch queue and a kubernetes inference cluster, as an example. However, access to the underlying cluster is open, and some customers do use this access for cluster lifecycle management, observability/logging, debugging via kubectl, and some even customize Soperator itself, setting up user and access management, VPNs, custom prolog/epilog scripts, CSI drivers, etc.
At this point, we are aware of two other cloud providers outside of Nebius (namely, Voltage Park and GCORE) that rely on Soperator to provide their SonK services.
Finally, Slinky from SchedMD, the original creators of slurm, gatekeepers of the slurm roadmap, PR deniers, and sole providers of support: https://github.com/slinkyproject
At this time, Slinky is broken into separate projects, most importantly slurm-operator, which is a set of custom controllers and CRDs capable of running the core slurm services on a Kubernetes cluster, instead of directly on bare metal or VMs. These slurm services are:
slurmctld – the slurm controller which manages what jobs run on what slurm workers in the cluster, and what the health state of these workers are. On kuberenetes this is
slurmd – the slurm worker nodes themselvesslurmrestd – provides an API endpoint for slurmctld
slurmdbd – a database to store job stats, i.e. who ran what

To do this, slinky introduces a new process, slurm-operator, for managing the slurm resources on the cluster. Slinky also introduces a separate login pod, managed as a CRD “LoginSet” that runs the sshd, sackd, and sssd processes needed for users to run commands against the slurm cluster such as srun, sbatch, salloc, scontrol, squeue, sinfo, sacct, and sacctmgr.
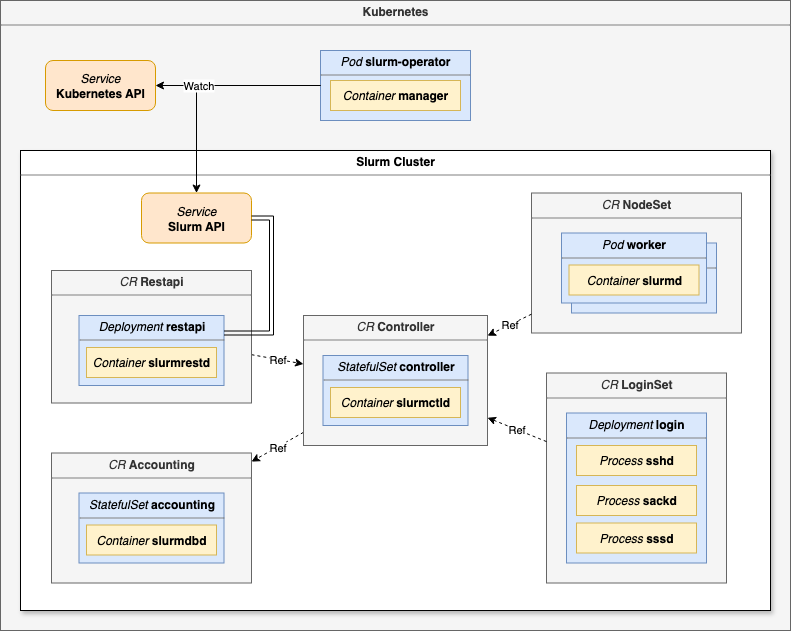
By default, Slinky out-of-the-box is not usable. Unfortunately, this has become a giant footgun for cloud providers that want to run slurm on kubernetes for whatever reason, but unfortunately don’t have the slurm experience to test anything other than the “sinfo” command. The default Slinky LoginSet pod is missing vim, nano, git, python, sudo permissions, and more. This has led to five different cloud providers giving us access to login to a slurm cluster, run sinfo and then… nothing else. How can we download our codebase without git? How can we edit a file without vim/nano? How can we run a script without python? How can we install any software without permissions to run apt?
SSH access between nodes is typically also not an option in these environments. Explaining Slinky is basically the easiest way to start explain SUNK and Soperator. So let’s do that.
Soperator was originally announced in October 2024 during Q3 Financial reporting, with an intro blog and explainer to go with it, but managed Soperator was not released until June 2025.
Architecturally, Soperator is similar to Slinky in that it runs on top of kubernetes, not beside it. In Nebius’s implementation, users are provisioned qemu based VMs on an internal-facing kubernetes cluster, and Soperator manages the Slurm environment within that. Effectively, at Nebius, it’s Slurm-on-Kubernetes-on-VMs-on-Kubernetes. However, that last part is not mandatory, any VMs or bare metal kubernetes cluster will do. Soperator works just fine on other kubernetes clusters, assuming that storage gets setup correctly.
Technically, Soperator is a Kubernetes Operator that automates the deployment and lifecycle of the relevant slurm services. The entire cluster is defined declaratively via a SlurmCluster Custom Resource Definition (CRD):
Provisions KubeVirt VirtualMachine resources for the Slurm control plane (slurmctld, slurmdbd).
Generates the necessary configuration files (e.g., slurm.conf) and distributes them to the VMs.
Manages compute partitions as SlurmNodeSet resources, which in turn create and manage the VM pool for slurmd workers.
Critically for performance, it orchestrates the passthrough of hardware like NVIDIA GPUs and InfiniBand/RoCEv2 NICs directly to the VMs, allowing jobs to achieve bare-metal performance.
It handles elasticity, allowing users to scale partitions up or down by changing a replicas field in the CRD, which Soperator reconciles by creating or deleting the underlying VMs.

However, unlike SUNK or slurm-bridge, Soperator does not provide a hybrid scheduler to co-locate and arbitrate between competing slurm and kubernetes jobs.
Finally, to describe SUNK in detail, it is important to focus on the difference between metadata management and integration with CKS at CoreWeave. SUNK is built with a slurm syncer pod that propagates metadata between slurm services and the Kubernetes scheduler. This is evident when the slurm epilog runs, it sees a failure in node health, and throws an error to the slurm controller, setting the node into a “drain” state. The integration does not stop at the slurm level, it also integrates with kubernetes via a custom scheduler. A slurm job actually creates kubernetes resources with custom scheduler logic for a given pod, which sets a dummy schedule, lets slurm do the scheduling, and then connects that pod to the slurm controller. This means that users can run both kubernetes and slurm jobs on the cluster, but everything is actually being scheduled by slurm. The result is that the slurm controller is aware of all workloads running on the cluster.

In addition, the default behavior of the LoginSet for Slinky and Soperator leaves a lot to be desired. With SUNK, the login pod controller flow includes a hook up with the LDAP/IAM system for user management, and automatically load balances users into an interactive, ephemeral ssh pod that is spun up on-demand and mounted to the standard shared fs for the user’s /home directory. Accessing the pod can be done via ssh, or via the tailscale operator, meaning the cluster doesn’t need a public IP for every login pod. With Slinky, the load balancing is an IP-based layer 3 round robin, which can lead to differences if a user installs some software and then gets disconnected from the cluster.
Overall, it is clear that many providers are looking to adopt the mutual benefits of kubernetes for lifecycle management of the hardware and reliability guarantees, with the ease of use and familiarity that slurm provides users for batch scheduling. We expect Slurm-on-Kubernetes will continue to be a compelling option for providers to use going forward.
Virtual Machines or Bare-Metal?
The classic debate is evolving. Providers like CoreWeave and Oracle champion bare metal for maximum performance. However, this approach necessitates offloading networking, storage, and security functions to DPUs (like Nvidia BlueField), replicating the hyperscaler model that AWS popularized with their Nitro system.
Meanwhile, providers like Nebius (kubevirt) and Crusoe (cloud-hypervisor) utilize lightweight VMs. The claim is that this provides significant operational benefits such as rapid provisioning (seconds vs. minutes/hours), stateful snapshots, shared storage, and cleaner security isolation. In the case of Nebius, they have achieved bare-metal class performance as confirmed by our testing, industry benchmarks, and direct conversations with their users. With Crusoe, this level of performance is an ongoing work in progress.
Overall, the choice is now less about performance and more about architectural philosophy on the side of the provider. It is notable that even amongst the top tier providers in the industry there is not a settled best practice between bare-metal, VMs (cloud-hypervisor), and VMs-on-kubernetes (kubevirt) as the best option for infrastructure lifecycle.
Kubernetes for Training
Without Slinky, Soperator, or SUNK, there are still ways to run training jobs on Kubernetes.
Specifically, tools/CRDs like Kubeflow (MPIOperator, PyTorchJob, TrainingOperator), Jobset, Kueue, Volcano, Trainy, dstack, and SkyPilot all provide methods for scheduling a training job on a kubernetes cluster, and handling a batch queue.
It is useful to understand what each tool does, and where it came from:
Kueue – CRD – Manages job queues and user quotas. Works with the default kubernetes scheduler. Helps teams share underlying cluster resources (i.e. who gets what GPUs).
Volcano – Custom Scheduler – Provides gang scheduling, job dependencies and other advanced features that are missing in the default kubernetes scheduler. Can be used with Kueue.
PyTorchJob – Operator/CRD – Lifecycle management of pytorch jobs. Comes from the KubeFlow community.
MPIOperator – Operator/CRD – Manages the lifecycle of MPI jobs. Comes from the KubeFlow community.
KubeFlow Training – Platform – a collection of multiple different training operators, includes more than just MPI and PyTorch.
Jobset – CRD – General purpose resource definition for gang-scheduled jobs, improving on the Kubernetes batch API. Contributed by Google to the kubernetes community, and growing fast in adoption. Can be used with Volcano and Kueue.
Trainy – Platform – Simplifies job submission to kubernetes, reducing yaml burden for users to contend with. Paid product.
dstack - Platform - Simplifies job submission to kubernetes, reducing yaml burden for users to contend with. Open source with enterprise option (support, SSO).
SkyPilot – Platform – Simplifies job submission to kubernetes, reducing yaml burden for users to contend with. Open source, growing fast in adoption.
We expect the market to consolidate around a few approaches, namely: Jobset + Kueue for those interested in OSS, Volcano for those requiring large batch queues with gang scheduling, and SkyPilot for those running in multi-cloud scenarios.
Transition to Blackwell
We have seen a steep drop in H100 pricing over the last year, and a hesitation for many organizations to move to Blackwell. We believe that performance improvements like this will come in due time, especially for users working on FP8 and FP4 (MXFP4 or NVFP4 datatypes), and especially for inference. During our test period we received a mix of H100, H200, and B200 nodes from different providers.
For our rankings, at the current time, we mainly consider Hopper performance, with H100 and H200 still being the most popular clusters (in terms of quantity of purchases, not total volume) that we have heard about during our discussions with end users.
GB200 NVL72 Reliability and SLA’s
With Hopper, the failure domain was the node. With Blackwell rack-scale systems like the GB200 NVL72, the entire rack including compute, NVLink switches, cable cartridge/backplane and multiple fabrics (scale out, scale up) is the failure domain. This fundamental shift makes reliability and Service Level Agreements (SLAs) a critical piece during pricing negotiations between customer and provider.

As we described in our GB200 NVL72 article in August, a single faulty component can require draining an entire 72-GPU rack. To be clear, this does not literally mean draining the liquid from the cooling loops in the rack, it means the slurm concept of node state = “drain” or kubernetes node health state = “drain” and the node is “cordoned”. In response, top-tier providers are moving beyond node-level uptime and introducing rack-level SLAs. We are seeing top providers like CoreWeave and Oracle begin to offer 99% rack-level uptime guarantees with requisite penalties attached, even when managing hot spares on behalf of the customer.
We believe that achieving this level of uptime on a GB200 NVL72 rack scale system is only possible with a massive investment in proactive, automated health checks (both active and passive), sophisticated monitoring to detect and remediate failures before they interrupt a job, an automated provisioning process for hot spares deployed at scale, and a full, vertically integrated commitment from team members from the technician to the SRE to the end user.
This was particularly potent at GCP and AWS, who went for NVL36x2 instead of a full NVL72, though we have heard about backplane/cable cartridge issues from all providers currently deploying GB200 NVL72 at scale too. Nvidia is saying that the issue was traced to a firmware bug that caused NVLink connections to lose sync over time, not to a hardware fault. So after shipping ES/PS systems as early as November 2024, with volume shipments beginning this past spring, Nvidia finally is releasing this month the all-too-famous firmware version 1.3 that makes the system stable to use. To be clear, this is a delay of 6-7 months after shipping NVL36x2 systems. This also affects a lot of Meta’s racks, where they opted for Ariel NVL36x2 (72 CPU + 72 GPUs) as we described in our GB200 Hardware Architecture - Component Supply Chain and BOM article.

As shown below, NVL36x2 racks experience these intermittent NVLink reliability issues between the cross-rack ACC cables that take two NVL36 racks and connect them together to make a logical NVL72. These ACC cables and the flyover cables have troublesome signal integrity issues due to their additional length.


One of the issues that this firmware update will address is a firmware bug that causes NVLink connections to lose sync over time. We believe that there continues to be significant hardware issues in these systems, including complete failures, transient interruptions, and also in software stack instabilities from firmware to drivers to software libraries that require upgrades to the latest version in order to achieve an acceptable end user experience. Many end users and hyperscale operators of NVL36x2 and NVL72 are still complaining about the reliability of the backplane, cross-rack ACC cables, and the additional flyover cables.
The challenges that providers describe as the most difficult part of operating GB200 NVL72 rack scale systems is not the total amount of failures, perceived component quality, or even the stability of the software stack. It is the blast radius, and time to recovery. Here we describe the process to provision a GB200 NVL72 rack from scratch in the event of a backplane/cable cartridge failure, assuming that the pre-requisite to begin repairs has been accomplished (i.e. the rack has been drained/cordoned at the cluster level, and no jobs or only pre-emptible jobs are running):
Mechanical validation. Assuming that the NVLink backplane/cable cartridge (effectively, the rack’s “spine”) was replaced, or this is a fresh rack being booted for the first time, ensure strict alignment of all blind-mate connectors from compute/switch trays into the backplane.
Power validation. Energize the PDUs in the rack, but leave compute trays in standby state (POST) and focus on the NVLink fabric.
Connectivity for out of band management. MAC addresses for all BMCs on all 18 compute trays and 9 NVLink switch trays are identified and accessible by the cluster manager (i.e. NVIDIA Base Command Manager, Canonical MaaS). IPs are assigned to these BMCs.
Apply firmware baseline. If there is a mismatch between the compute trays with Grace CPUs, NVLink switches, CX-7 or CX-8 backend NICs, and BlueField-3 frontend NICs, there will be issues. A golden image with correct firmware package must be applied to all rack components simultaneously. Note there is exact compatibility requirements between the NVLink switch firmware and the driver versions coming at the OS level later that must be respected.
Boot NVLink switch trays. Before loading the OS on the compute trays, NVLink switch trays must be booted to a minimal OS/firmware stack, then chassis-level diagnostics are run. In other words, all 72 Blackwell GPUs need to be able to see each other across the new backplane/cable cartridge/“spine”. If re-seating or swapping does not fix the problem, the troubleshooting process begins anew (do not pass go, go straight to mechanical validation with new backplane).
Calibrate NVLink fabric. Fabric training involves forcing the SerDes in the NVLink interfaces to train against the copper backplane, adjusting their electrical signalling parameters to establish a stable connection. This validates that all links are running at full speed. If links fail to train, or negotiate at low speeds, you guessed it: try re-seating, and swapping to establish exactly which component is faulty (compute tray, NVSwitch tray, copper backplane, connectors/interposers). Potentially, begin anew with a new backplane.
Provision the Operating System. Generally, the target OS is deployed to all nodes simultaneously, with a recipe of GPU drivers, MOFED/DOCA drivers, CUDA Toolkit, DCGM, and the Fabric Manager that matches the new firmware baseline.
Start the fabric manager. All compute trays need to be running in order to validate the 72 GPUs still see each other over NVLink at the OS level.
Integrate with the scale-out network. The scale-out fabric (distinct from the scale-up NVLink fabric) is InfiniBand or RoCE. For InfiniBand, UFM must discover the new GUIDs, assign LIDs, and recalculate fabric routing paths. For RoCE (Spectrum-X), the topology location of new nodes is identified with LLDP and the cluster manager (BCM) automatically assigns IPs. Nodes advertise their routes into the fabric with BGP, updating forwarding tables across all switches. A similar process is applied for the frontend/N-S uplink network.
Burn-in validation. The provider’s standard active health check suite is applied to all nodes in the rack, running tests such as dcgmi diag -r 3, nccl-tests, multinode ubergemm, and a sample mutlinode training job to ensure that CPUs, GPUs, scale-up, and scale-out interfaces all experience thermal expansion and contraction at the same time.
We describe this process in detail to shine some light on why providers believe that the provisioning process for a fresh backplane or a brand new NVL72 rack can take anywhere from 9 hours to multiple days. If anyone reading this has personal experience trying to install Nvidia drivers on their gaming PC or workstation, just imagine doing that on 18 PCs and 9 workstations at once, except you’re also installing a new OS on all of them while your kid randomly flips breakers in the garage and the clock on the microwave has to match the one on the stove.
Anyway, an important concern here is diagnosing the correct failure. Experienced NVL72 operators certainly do not want to spend time swapping an expensive component if it is not necessary, and especially when that time can constitute a 1 day rack outage that counts against their uptime SLA with their customer. All sorts of tricks have emerged to localize and identify the exact failure that is occurring. Here is a rough breakdown:
If a single link has failed, it’s a specific pin on a tray connector or a single trace on the backplane
If all links on one GPU fail, it’s the SerDes on that specific GPU or its local routing to the tray connector
If all links on one tray (4x GPUs) fail, it’s a board failure on that tray or that slot
If there are widespread, random failures, it’s the backplane
In the case of first-time failures on a rack, it is also important to consider an A/B swap of trays to pinpoint if failures move with the tray or stay with the slot. To do this in production, we stress the importance of high quality monitoring dashboards, active/passive health checks, and automatic remediation on the side of the provider and promote it throughout our ClusterMAX research effort.
It is also unclear how Nvidia supports customers with tooling. We hear different failure scenarios described by different providers, which seem to currently be solved with a whack-a-mole approach. In other words, Nvidia is coming up with tools and approaches on the fly both for debugging and fixing failures. This leaves providers to differentiate both with their operational processes, and software systems. It seems that the speed which which a provider can onboard a new debugging tool into their automation stack can make all the difference.
The result of all of this is an SLA commitment from the provider to the customer. To booth, we have seen a wide variety of SLAs being applied to these rack-scale systems, involving a range of different uptime guarantees and penalties associated with a breach. We have seen remarkably different approaches:
A provider commits to a node level SLA, and a rack level SLA. In other words, individual nodes must have a 99% uptime, but a rack (defined as 16 of the 18 nodes, or 64 of 72 GPUs) has a lower SLA at 95%. Customers get access to all nodes in the rack.
A provider commits to a node-level SLA only. In other words, individual nodes have a 99% uptime guarantee, and the customer only gets access to 16 of the 18 nodes in the rack. The leftover nodes are used by the provider for other purposes (including as a hot-swap for the customer, for other customer workloads, or for internal workloads)
A provider commits to a rack-level SLA only. In other words, all 18 of 18 nodes must be up 95% of the time, and the customer gets access to all nodes.
The way in which credits or deductions work is also unique. In the event of a breach, some providers insist on providing a credit towards a future monthly bill that the customer spends in the future. Other providers reconcile in realtime, deducting any downtime off the current month’s bill.
At this time, we don’t have a strong preference between approaches to SLAs nor a recommendation to providers or customers. However, after living through the Hopper generation of deployments, we hope that there will be less people suing each other this time around. Less hostility = better outcomes for everyone.
Remember kids, CoreWeave called GB300 “production ready” back in August!
Crypto Miners Here To Stay
The “AI Pivot” for crypto miners is real, and is primarily driven by their head start over pure-play AI Neoclouds. Miners have long been in the business of finding cheap, large-scale power sources. With GenAI taking off and changing traditional datacenter requirements, many Bitcoin miners realized they were sitting on a gold mine. We came to the same conclusion and laid out bullish views on the industry prior to an avalanche of deals in 2025 leading to surging stock prices.
While industry protagonists have mostly been successful at building and leasing AI Datacenters to Neoclouds, some realized that they could increase their realized value per MW by going vertical. Today, many of the top Bitcoin mining companies by hash rate now have a dedicated AI Cloud business. This list includes, but is not limited to, publicly traded American companies such as Terawulf, Cipher Mining, IREN/Iris Energy, Hut 8/Highrise, VCV Digital/Atlas Cloud, BitDeer, Applied Digital, and Core Scientific (acquired by CoreWeave). For a full list of GPU buyers with estimated quarterly GPU count, refer to our industry-leading AI Accelerator & HBM Model.
On the surface, crypto miners are not yet competing at the Platinum or Gold tier for ClusterMAX. However, those who know their Neocloud history will notice that Crusoe started out in bitcoin mining, and that Fluidstack has already partnered with Terawulf and Cipher Mining, backed by Google, to deliver Gold-tier clusters for leading AI labs. We see two ways in which the crypto business model focused on the infrastructure foundation can play out for these companies:
Powered Shell / Colocation: Renting their gigawatt-scale, high-density datacenter space to other Neoclouds or frontier AI labs who prefer to deploy their own hardware, and can effectively lock them out of their own facility if needed.
Wholesale Bare-Metal: Procuring GPUs themselves and offering them as bare-metal clusters, leveraging their low energy costs to compete aggressively on price, putting their people to work, and using their access to capital to purchase tranches of GPUs ahead of demand, resulting in a pricing arbitrage opportunity.
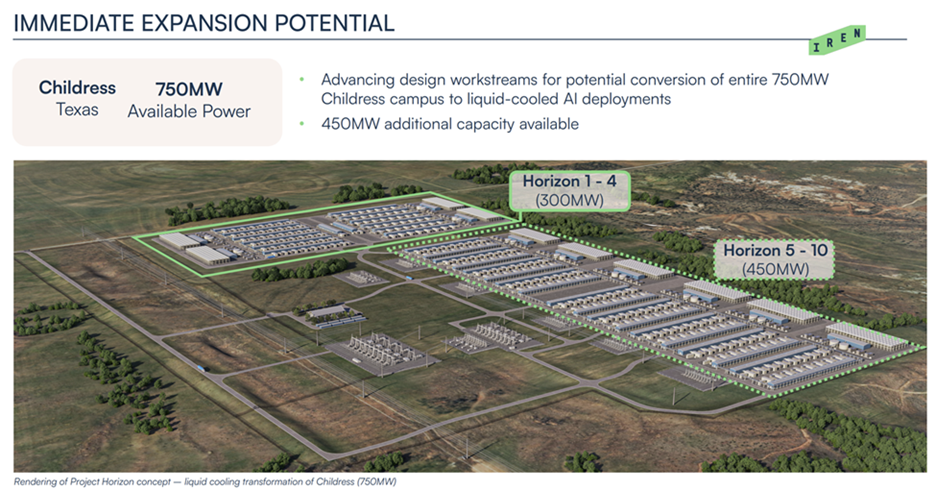
No firm better exemplifies the Bitcoin-to-AI pivot than IREN. It operates one of the world’s largest mines in Childress, TX, shown below.
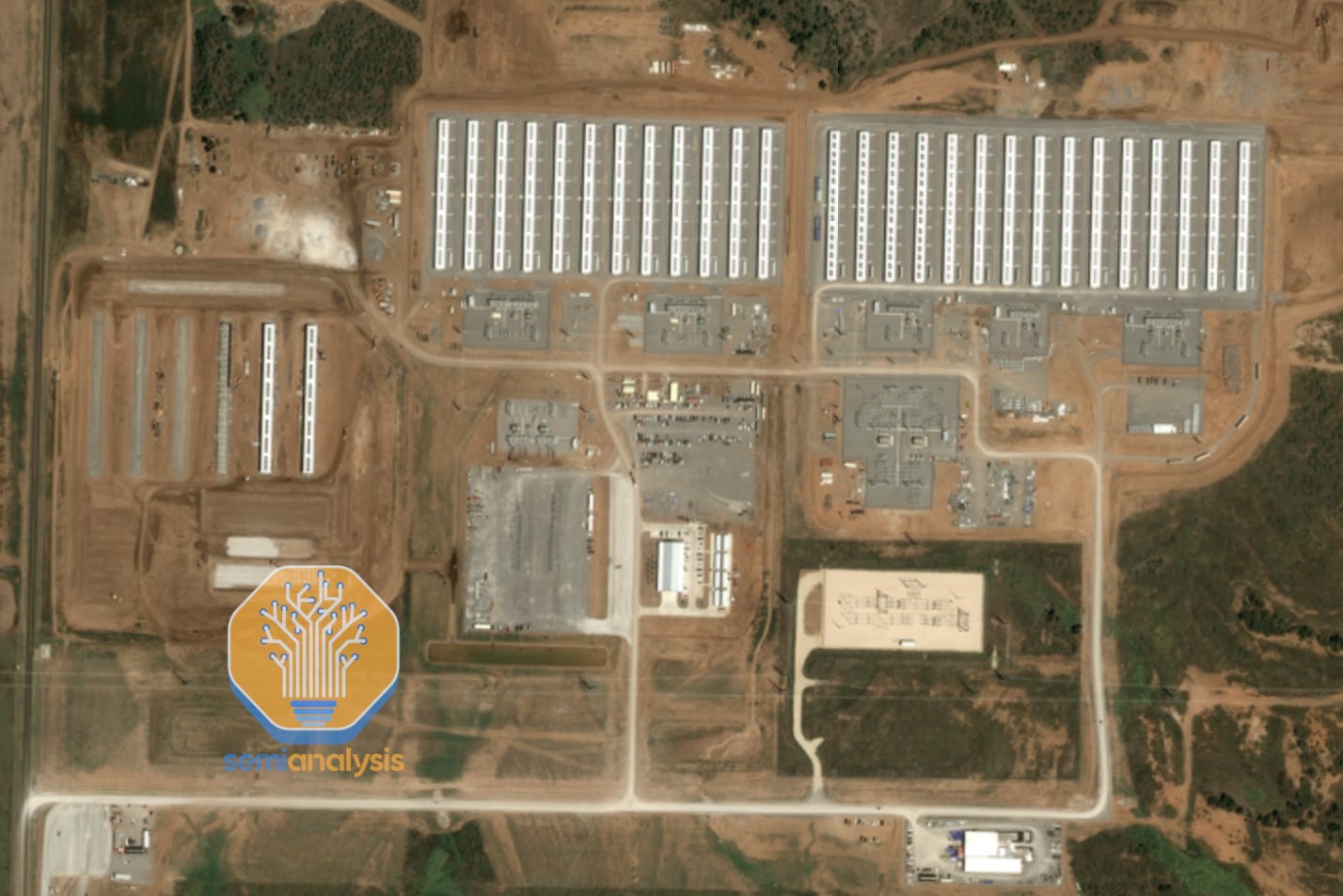
IREN has successfully pivoted to Bare Metal Wholesale Cloud, scoring a 200MW deal with Microsoft to deploy GB300 GPUs in the same Childress, TX campus. IREN already unveiled a vision to retrofit the whole Bitcoin mine into a massive GPU cluster.
While they’ve been very successful at selling GPU Cloud capacity, their economic returns aren’t what has commonly been depicted by market participants. Our AI Cloud TCO Model (trusted by the world’s largest GPU buyers and financial leaders) estimates the precise economics of the IREN/Microsoft deal, allowing users to compare it with other large deals like Nscale, CoreWeave, Nebius, Oracle, and more. Our AI Tokenomics Model further expands on this work by tracking the flow of compute supply and the different sources of demand to the various token factories that ultimately make use off this compute. AI labs like OpenAI and Anthropic feature prominently as the ultimate users of much of this compute capacity!
Custom Storage Solutions
The rise of massive datasets has created a storage bottleneck. While high-performance POSIX filesystems (Weka, VAST, DDN) are still common, a new trend is emerging: S3-compatible object storage (like CoreWeave’s CAIOS or Nebius Enhanced Throughput object storage) sometimes paired with a massive, distributed local NVMe cache. CoreWeave’s LOTA (Local Object Transfer Accelerator) is the prime example, transparently caching data on the local drives of compute nodes.
In our analysis, we have seen that the initial buildout of compute for LLMs trained primarily on text and code considered storage as an afterthought, with storage representing less than 5% of cluster TCO. However, with data-heavy workloads such as image and video generation, weather prediction, drug discovery, real-time voice, robotics, and world models emerging, we have seen specific cluster designs with storage representing over 20% of the cluster TCO (i.e. over 100 PB for less than 2000 GPUs).
We expect to see more providers contend with the “thundering herd” problem of a shared filesystem that provides enormous aggregate bandwidth at 100PB+ scale.
InfiniBand Security
When it comes to securing a multi-tenant cloud, one of the most critical factors is the backend interconnect network. This is the data plane for all “East-West” traffic between GPU nodes, and for large clouds it generally involves a shared three-tier network architecture. Effectively, providers need to be able to create an isolated “VPC” for each tenant (and in many cases, for sub-tenants within each tenant) that extends to the private, backend interconnect.
While multi-tenant network security is well established through the use of layer-2 VLANs or layer-3 VXLANs via the use of datacenter switch and network management software (such as Arista CloudVision/EOS, Cisco NDFC/NX-OS, and Juniper Apstra/Junos), doing this with InfiniBand is relatively new. Nvidia recently released a blog on the topic which highlights that delivering a secure, multi-tenant InfiniBand network to customers involves more than just configuring PKeys.
Specifically, Partition Keys (PKeys) are the standard InfiniBand mechanism for network segmentation, functionally equivalent to VLANs in an Ethernet world. A PKey is a 16-bit value assigned to an InfiniBand port (on both the HCA and the switch). For a packet to be delivered, the PKey in its header must match a valid entry in the partition table of the receiving port, enforcing isolation at the fabric level. On many different providers, we were given a supposedly “isolated” 4-node or 2-node cluster, where we could see far more than just our 16 or 32 endpoints, due to a misconfiguration of PKeys, or a lack of any configuration at all.
However, PKeys alone are an insufficient security boundary for a robust multi-tenant environment. PKeys are managed by a central Subnet Manager (SM). A compromised tenant node could potentially send malicious Subnet Management Packets (SMPs) to query fabric topology or, in a poorly secured fabric, even attempt to reconfigure PKeys and break tenant isolation.
True, hardware-enforced isolation is described in detail by Nvidia in this blog: https://docs.nvidia.com/networking/display/nvidiamlnxgwusermanualfornvidiaskywayappliancev822302lts/configuring+partition+keys+(pkeys) which we encourage all providers deploying InfiniBand to review in detail.
The blog describes a multi-layered approach to InfiniBand security. The result is a one-time setup that includes:
M_Key: Management key that prevents rogue hosts from altering device configurations. If the key doesn’t match, the request is dropped.
P_Key: Partition key analogous to VLANs. These keys define which devices can “see” or talk to each other, creating strict traffic isolation across the fabric.”
SA_Key: For sensitive operations in the Subnet Administrator (adding or removing records, for example)
VS_Key: For vendor tools like ibdiagnet
C_Key and N2N_Key: Secure communication manager traffic and node-to-node messaging
AM_Key (only when SHARP is enabled): Specific to SHARP aggregation, ensuring data is only reduced by authorized switches
Providers who rely solely on basic PKey configuration without these additional layers are offering a demonstrably weaker security posture. We believe that the additional complexity associated with InfiniBand, due primarily to poor documentation from Nvidia, has led to a significant lack of strong skillsets in the industry amongst full time employees and contractors for hire.
Container Escapes, Embargo Programs, Pentesting and Auditing
Security in the Neocloud space has rapidly escalated from a checkbox item to a critical differentiator. The recent discovery of NVIDIAScape (CVE-2025-23266) by security firm Wiz served as a wake-up call for many in the industry. This vulnerability allows a user running inside a container to “escape” their container and escalate to full root access on the underlying host node, a huge security vulnerability in any multi-tenant environment where customer workloads run alongside each other, only isolated via containers on the same underlying host. Most notably, the vulnerability can be exploited with a simple three-line script, easily baked into a docker image in the software supply chain.
As a POC during our testing, we built this exploit into custom containers built on base images from vLLM, and nvidia pytorch. Running it is dead simple, just pull the container and run. Clearly, any provider running an out-of-date container toolkit version and allowing arbitrary containers from public registries to be executed puts their customers at risk of persistent backdoors, data exfiltration, ransomware, cryptojacking, and more. During our testing, we demonstrated this exploit was effective on over a dozen providers who were not up-to-date on their nvidia-container-toolkit (version 1.17.8 or later as described here: https://nvidia.custhelp.com/app/answers/detail/a_id/5659 ).
Most importantly, this is not just an Nvidia-specific problem. The AMD ecosystem has historically lacked a robust, secure container runtime, leaving many deployments insecure by default. The recent development of the ROCm container-toolkit is a direct response. However, these incidents underscore the critical importance of vendor security embargo programs, customer communication, and remediation.
Top-tier providers are included in the Nvidia embargo program, where they receive advanced notice of vulnerabilities like NVIDIAscape. This allows them to develop and deploy patches before the vulnerability and its exploit are made public, protecting their customers. Following our feedback and direct engagement from multiple providers, AMD has now also instituted a formal security embargo program, allowing their Neocloud partners to prepare effectively. We now consider the rocm container toolkit version provided (shown here: https://github.com/ROCm/container-toolkit ) when testing AMD clusters and standalone AI VMs.
This leads to the broader topics of pentesting and auditing. We cannot audit the internal security practices of every provider we track. This is why our criteria demands, as a bare minimum, third-party attestation like SOC 2 Type I or ISO 27001. For a provider handling proprietary models and sensitive corporate data, this is the absolute lowest bar for proving a formal security process exists. However, we encourage all Neoclouds to adopt a hyperscaler mentality: zero-trust, defense-in-depth strategies with continuous auditing and a proactive security posture. Relying on reactive patching or basic pentesting is not viable to serve the world’s leading frontier AI labs effectively.
What AMD and NVIDIA can do better for GPU Clouds and ML Community
Many Neoclouds are not familiar with InfiniBand due to the continued lack of education and documentation around InfiniBand. The situation was not gotten much better in terms of what Neoclouds have actually implemented since ClusterMAXv1 when we made the same recommendation to Nvidia 8 months ago. There has been some public documentation updates recently but not enough and it does not cover commands for how to verify it and we appreciate the Nvidians that are trying to help improve the situation. We recommend that they should rapidly continue provide a lot more good publicly accessible documentation and do lots of education with their NCPs about the different keys (SMKeys, MKeys, PKeys, VSKeys, CCKeys, AMKeys, etc) needed to secure an InfiniBand network properly. We recommend that Nvidia help their GPU clouds properly secure their InfiniBand network and complete an audit of all GPU clouds that use InfiniBand.
Furthermore, 8 months ago, we made the same recommendation to Nvidia that Nvidia should fix ease of use for SHARP for the GPU provider and recommend that Nvidia should enable it by default. Nvidia has not made any significant impact to SHARP usability and the extremely low usage of InfiniBand SHARP is has not changed.
In ClusterMAXv1, we recommended to AMD should support containers as first class in slurm and they have since enabled initial support though it has lots of bugs. We recommend that AMD further QA their container slurm support such that it is bug free and end users aren’t running into new bugs every week.
For providers that both AMD and Nvidia, the quality of their AMD cloud offering is much worse than their Nvidia cloud offering and missing critical features like health checks or working slurm support like on Crusoe and Oracle, etc. OCI’s slurm offering is much worse on AMD compared to Nvidia. Same thing for Crusoe and other hybrid clouds.
Some Final Comments on NVIDIA’s Cloud Confusion: From Ambition to the Grave. Don’t Believe Your Lyin’ Eyes!
When NVIDIA acquired Lepton (a 20-person startup) for a rumored $300-$900M price tag, Neoclouds were scared. Lepton was a gold-tier ClusterMAX provider, with a unique capability to run across multi-cloud infrastructure, a strong resume (Jia Yangqing being a co-creator of PyTorch) and a knack for digging into the technical details. We were Lepton’s biggest fans!
At this point, it seems the Nvidia is intent on destroying the value of Lepton by having the team focus on features that users don’t care about, making the skin of the product dark-themed and Nvidia branded, and breaking things (like the interface for creating storage volumes, notebooks, and batch jobs, as well as the ability to trigger health checks on underlying nodes), instead of adding anything new. In other words, Lepton by Nvidia now reminds us of the old cuDNN download portal, and joins a long list of Nvidia software acquisitions that have been bundled in to die. To list them:
Nvidia acquired run:ai for orchestration and scheduling in May 2024 for $700M
Nvidia acquired deci for inference optimization in May 2024 for $300M
Nvidia acquired shoreline.io for automatic hardware remediation in July 2024 for $100M
Nvidia acquired brev.dev for cloud developer machines in July 2024 for a rumored $100M
NVIDIA acquired Lepton for clusters, orchestration, monitoring and health checks in April 2025 for a rumored $900M
That’s $2.1B in total, if the rumors are true! There have also been some big announcements:
In March 2023 at GTC, Nvidia launched DGX Cloud.
In August 2023 at Google Cloud Next, Nvidia announced DGX Cloud was coming to Google Cloud.
In November 2023 at AWS re:Invent, Nvidia and AWS announced DGX Cloud was coming to AWS, specifically with GH200 Grace Hopper Superchips.
In November 2023 at Microsoft Ignite, Nvidia announced the AI foundry service on Microsoft Azure, and that Nvidia DGX Cloud was now available on the Azure Marketplace.
In March 2024 at GTC, Nvidia announced DGX Cloud was generally available
In January 2025 at CES, Nvidia announced that Uber was using Nvidia’s DGX Cloud to build models for its robotaxi fleet.
In May at COMPUTEX 2025 in Taipei, Nvidia announced the expansion of the DGX Cloud platform under a new name called “DGX Cloud Lepton”. The announcement described Lepton as a compute marketplace connecting developers to tens of thousands of GPUs via global cloud-partners.
In June at GTC Paris, Nvidia announced the expansion of DGX Cloud Lepton to Europe.
Overall, these announcements seem as empty as Nvidia’s promises to open source the whole of run:ai. We have yet to see anything published on GitHub at that level. Same goes for Lepton (outside of gpud). We await this with bated breath.
Following some of our commentary about the state of the Lepton acquisition, we heard directly from Nvidia that they are absolutely offended to be considered a Neocloud. Apparently, all of these acquisitions are not being used for profits or revenue. Instead, the former DGX Cloud is being taken behind the barn, while the new DGX Cloud Lepton is being promoted. This is good for Neoclouds - it seems that after $2B spent, Jensen has recognized that he doesn’t want to compete with his biggest customers. So DGX Cloud, don’t do that!
When we tried to get access to DGX Cloud for testing, we needed to have an intro call and a strategy call with Nvidia team members, scheduled on separate weeks. Without this information we were just left with the DGX Cloud website.

The website leads users to the following:
Try Nvidia DGX Cloud Now - NIMs page on NGC, which is an API for model endpoints
Use Nvidia DGX Cloud Serverless Inference - sign-up page for a 30-day preview of serverless inference powered by Nvidia Cloud Functions, which seems to be an API for model endpoints
Explore Nvidia DGX Cloud Create - a sign-up page to “talk to us”
Deploy Globally with Nvidia DGX Cloud Lepton - a sign-up page to apply for access to DGX Lepton. But if you’re a GPU cloud provider (maybe trying to provide your compute to the marketplace?) you can email the NVIDIA Cloud Partner address: dgxc_lepton_ncp_ea@nvidia.com
Request Nvidia DGX Cloud With NVIDIA GB200 - a circular link back to the DGX Cloud homepage
Get Nvidia Omniverse on DGX Cloud - a link to a DGX Cloud tile on the Azure Marketplace, which requires a sign up link, and probably sends your information to someone in Nvidia sales
So, it seems like most of DGX Cloud is not a Neocloud, rather it is a set of future meetings with Nvidia sales teams with unclear agendas.
The exception is the last link in the portal, which takes you to Azure, where you can double-MFA your way into an opportunity to purchase a DGX Cloud A100 80GB 1 node – 1-month subscription for the low low price of $23,360.00 (with an option to auto-renew).
Note that this works out to $4.05 per A100-hr, the worst price we have seen anywhere, ever.


With that said, Nvidia has also acquired Brev, a useful frontend for Neoclouds such as DataCrunch (now called Verda), which seems to actually come via Shadeform’s orchestration layer. However, the console is nice and simple, and is open to the public: https://brev.nvidia.com/environment/new/public

We very much look forward to testing out Lepton, DGX Cloud, and Brev in the future. Nvidia has hired some incredibly hard working and talented engineers, along with a ton of useful IP that their community could benefit from. We hope to see more in the future.
Eventually, we were also provided the opportunity to test Lepton.
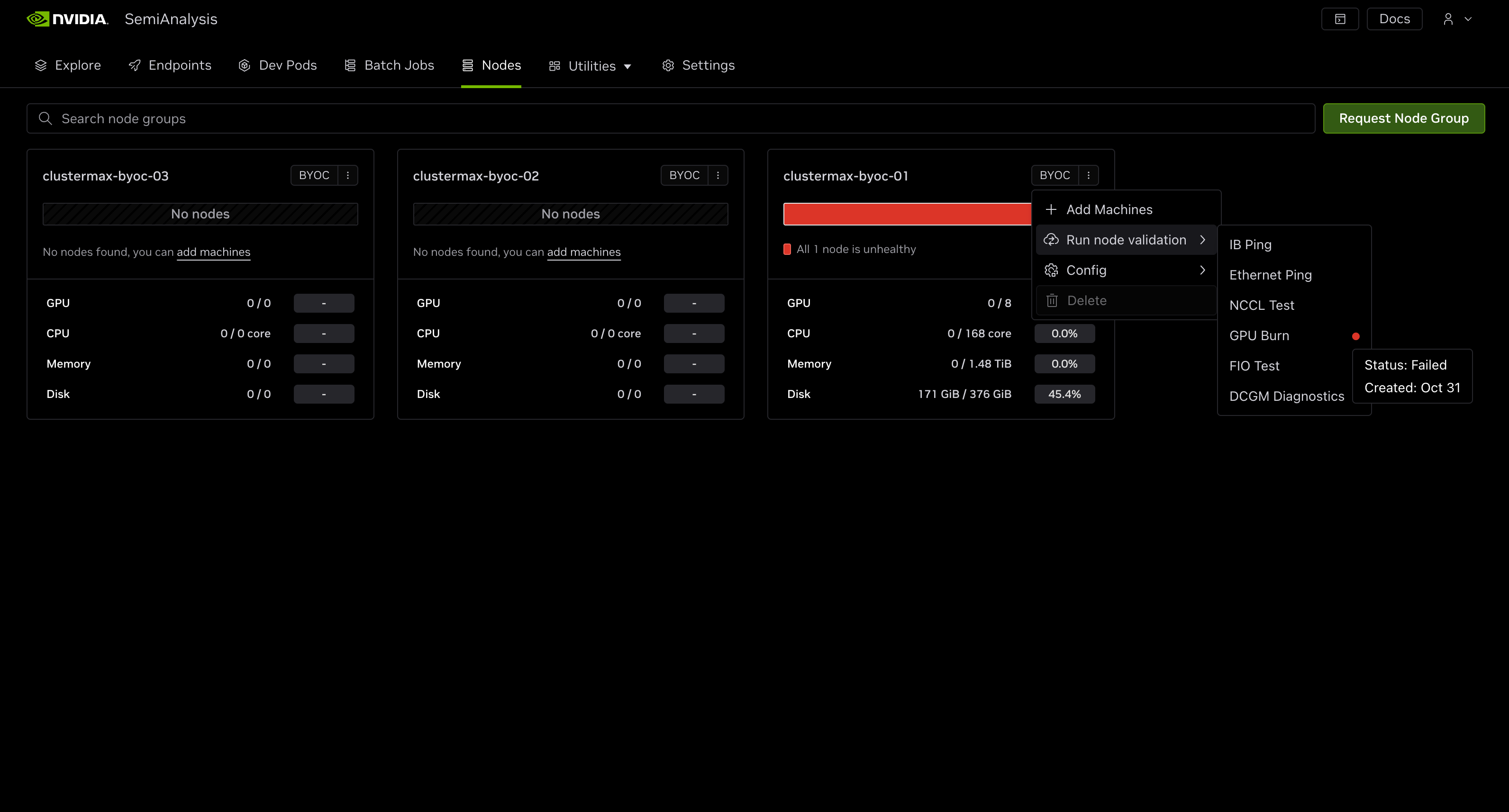
During our testing (which occurred over a month after we closed our testing with all Neoclouds due to delays due to meetings), we were not able to successfully create a dev pod, batch job, or run health checks on a node. Though DGX Cloud Lepton is described as a “compute marketplace connecting developers to tens of thousands of GPUs via global cloud-partners”, we were forced to bring our own GPU machines into the console. These machines are always managed and paid for outside of DGX Cloud Lepton. There seems to be no available clouds pre-registered on the platform, only “BYOC” (Bring Your Own Cloud) functionality.
Overall, our experience with Nvidia as a Neocloud or Neocloud-adjacent provider has been very strange. We encourage Nvidia to open source all of the software from lepton, run:ai, deci, shoreline, and brev so that their community of 200+ Neocloud providers can benefit. We hope that Lepton in particular can follow the path of TRT-LLM, NCCL, etc instead of the path of RIVA, Maxine, Isaac and Drive.
Quotes
The following quotes represent insights from industry experts, researchers, and practitioners who work with GPU cloud infrastructure daily. These perspectives help illuminate the real-world challenges and considerations that inform the ClusterMAX™ rating system.
Industry Leaders
“ClusterMAX has become a valuable tool for making data-driven decisions about where and how we deploy compute. As a leading system for benchmarking GPU clouds across performance, reliability, and support, it provides critical insights to our team as we scale OpenAI’s infrastructure through projects like Stargate — helping ensure the benefits of AI reach everyone.”
— Peter Hoeschele, General Manager of OpenAI Stargate
“Meta’s Super Intelligence efforts relies on both internal on prem clusters and cloud providers to build the largest AI fleet for frontier model training & inference efforts. ClusterMAX is delivering a comprehensive rating system that the industry can rely on to evaluate GPU cloud providers.”
— Santosh Janardhan, Head of Global Infrastructure at Meta
“AI is transforming every industry, and the infrastructure behind it needs to be dependable, scalable, and transparent. SemiAnalysis’s industry standard rating system, ClusterMAX, shines a light on what truly matters—real-world performance, operational excellence, and customer support—helping organizations navigate a complex GPU cloud landscape. It’s a valuable resource for anyone renting from GPU clouds.”
— Michael Dell, Chairman and CEO, Dell Technologies
“In the rapidly evolving AI landscape, choosing the right GPU cloud provider is essential for maximizing efficiency and minimizing risks. Supermicro commends SemiAnalysis’s ClusterMAX rating system, which evaluates providers on security, reliability, and performance to deliver unparalleled value in GPU infrastructure for enterprises and startups alike.”
— Charles Liang, President and CEO, Supermicro
“ClusterMAX has become the go-to benchmark for GPU clouds. By focusing on what users care about like managed Kubernetes, SLURM integration, operational reliability, and enterprise class support, SemiAnalysis helps GPU consumers cut through the GPU cloud marketing noise and select the best platform to run their workloads.”
— Hunter Almgren, Distinguished Technologist, Hewlett Packard Enterprise
“Snowflake’s mission is to empower every enterprise to achieve its full potential with data and AI with the performance and scale they need. As we expand our use of GPUs to accelerate AI workloads, objective and transparent benchmarks like ClusterMAX are invaluable. The system provides the clarity required to evaluate GPU cloud providers across performance, reliability, and cost, helping ensure we make the right infrastructure decisions to support our customers at scale.”
— Dwarak Rajagopal, Vice President of AI Engineering and Research, Snowflake
Financial Leaders and Venture Capitalists
“ClusterMAX is the industry standard for evaluating GPU cloud providers—providing desperately needed transparency to empower all GPU end users, large and small, with a clear understanding of the latest GPU cloud landscape.”
— Gavin Baker, Managing Partner & CIO, Atreides Management
“SemiAnalysis has quickly emerged as a trusted source in our industry through hustle and hard work. ClusterMAX is a prime example, delivering a comprehensive rating system that the industry can rely on to evaluate GPU cloud providers.”
— Brad Gerstner, Founder, Chairman, and CEO of Venture Capital Fund, Altimeter Capital
“By rigorously benchmarking providers across critical dimensions that customers care about like performance, reliability, orchestration, and security, ClusterMAX empowers us to be informed about the state of where AI compute is going.”
— Ricard Boada, Senior Vice President of Global AI Infrastructure, Brookfield Asset Management
“For AI startups, especially in early stages, GPUs are often the single biggest line item. Picking the right cloud provider can literally determine whether you make it or not. SemiAnalysis’s ClusterMAX cuts through the noise by benchmarking cost, performance, and reliability - this gives teams the data they need to make the smartest call when choosing GPU clouds.”
— Sonith Sunku, Venture Capitalist, Z Fellows
AI Companies and Startups
“At Periodic Labs, we’re building an AI Scientist to accelerate scientific discovery. To conduct novel research, we rely on GPU clouds that are stable and performant at scale. SemiAnalysis’ ClusterMAX sets the GPU cloud industry standard and has been extremely helpful in our evaluations of cloud providers. Their evaluations on reliability, performance, networking, and managed Kubernetes orchestration align closely with the demands of our workloads.”
— William Fedus, CEO @ Periodic Labs, Ex-VP of Research @ OpenAI
“At Cursor, we’re advancing the frontier of AI-native software development with tools that help engineers build faster and smarter. To support our research, we depend on GPU clouds that are reliable, performant, and easy to scale. We’re glad SemiAnalysis introduced ClusterMAX as the industry standard GPU cloud ranking system. Its evaluation across reliability, quick node swaps, & performance, and reflects what matters for our workloads.”
— Federico Cassano, Research Scientist @ Cursor
“Jua is a frontier AI lab building a foundational world model of Earth - simulating weather, hurricanes, wildfires, and more. We train on managed Slurm and run inference on managed Kubernetes, and ClusterMAX aligns well with our GPU requirements.”
— Marvin Gabler, CEO of Jua
“AdaptiveML is unified platform for enterprise inference, pretraining, and reinforcement learning. We use FluidStack & deploy on GPUs across all 3 major hyperscalers. Our stack runs on Kubernetes. ClusterMAX’s 9 different categories of criterias aligns well with our requirements”
— Daniel Hesslow, CoFounder & Research Scientist, AdaptiveML
“Extropic is pioneering thermodynamic computing — building AI systems grounded in the physics of information itself. Internally, we use SLURM clusters to manage our experiments. We are glad to see SemiAnalyis’s industry standard ClusterMAX system’s criteria includes evaluating SLURM offering across providers”
— Guillaume Verdon, Founder of Extropic, Ex-Quantum ML Lead at Alphabet
“At Mako, we’re liberating developers from the bottlenecks of GPU performance engineering. Our AI coding agent automatically generates, optimizes, and deploys GPU kernels for NVIDIA, AMD, and custom accelerators. ClusterMAX’s industry-standard GPU cloud rating system, with its multi-criteria evaluation aligned to our hardware-agnostic approach, empowers us to deliver seamless, scalable inference and RL post-training for the AI systems of tomorrow.”
— Waleed Atallah, CEO, Mako
“As an emerging AI lab, Nous Research has developed popular models such as Hermes 4. For us, ClusterMAX is the industry standard for evaluating GPU clouds across the critical dimensions we care about: price, performance, and network stability.”
— Emozilla, CEO of Nous Research
“ClusterMAX has been useful for us even if Dylan Patel is annoying”
— Matthew Leavitt, DatologyAI
“At Cartesia, we’re developing the next generation of interactive, multimodal intelligence, which requires infrastructure that is efficient, low-latency, and resilient. Systems like ClusterMAX provide the clarity and technical detail to help organizations better understand how to scale their compute infrastructure.”
— Arjun Desai, Cofounder at Cartesia
Infrastructure and Platform Providers
“At Modal, we’re the serverless platform for AI and ML engineers. High performance and reliable GPU infrastructure is a key demand of our customers. We are glad SemiAnalysis created their industry standard GPU Cloud ranking system, ClusterMAX. It has guided development of our internal GPU reliability system, gpu-health, and provides insights when selecting our GPU Cloud vendor evaluation.”
— Jonathon Belotti, Engineering @ Modal
“Baseten is a high-performance inference platform operating at the frontier of model performance, serving some of the leading AI companies in the market and early adopting enterprises. Our Inference Stack delivers blazing-fast cold starts, autoscaling, and enterprise-grade reliability. As a provider that operates across over 10 clouds, we are happy SemiAnalysis created their industry standard GPU Cloud ranking system, ClusterMAX. This system evaluates across 9 critical criteria that we value most when it comes to operating at the frontier of AI model performance.”
— Ed Shrager, Head of Special Projects, Baseten
“GPU clouds are propelling the AI revolution by democratizing access to enterprise-grade compute. Unlike traditional clouds, GPU clouds require specialized hardware-software optimization that can make or break AI performance. The SemiAnalysis ClusterMAX GPU cloud ranking system provides a holistic evaluation of the full technology stack combined with world-class analysis that provides WEKA with the vital insights needed to architect powerful AI infrastructure solutions for our GPU cloud partners and their customers.”
— Val Bercovici, Chief AI Officer, WEKA
“ClusterMAX has become the industry standard for GPU cloud rankings, and the results align perfectly with our real-world experience at fal.”
— Batuhan Taskaya, Head of Engineering, Fal.ai
ML Community Leaders and Content Creators
“SemiAnalysis created a in depth study & ranking for the GPU cloud industry covering areas that are important to end users like me such as out of box slurm/kubernetes, NCCL performance and high reliability”
— Stas Bekman, Developer & Author of Machine Learning Engineering Open Book (10k+ github stars)
“The team at SemiAnalysis created the GPU cloud ranking that I think everyone else wishes they could have made. It is as thorough, comprehensive, and neutral. The methodology is aligned with real world applications, and is pretty comprehensive.”
— Jon, Asianometry, 800k+ sub tech YouTuber
Moving Forward
Moving forward, for ClusterMAX 3.0 and interim ratings, we will be communicating direct expectations for slurm, Kubernetes, Standalone Machines, Monitoring, and Health Checks.
To review the following, please visit:
For slurm: http://clustermax.ai/slurm
For kubernetes: http://clustermax.ai/k8s
For standalone machines: http://clustermax.ai/standalone
For monitoring: http://clustermax.ai/monitoring
For health checks: http://clustermax.ai/health-checks
Note that these pages will be updated over time.
Conclusion
Thank you for taking the time to review ClusterMAX 2.0! Going forward, you can see up-to-date rankings and interim news at http://clustermax.ai/, or by reaching out to us at clustermax@semianalysis.com
Reviews For Each Cloud
Platinum
CoreWeave
Since our last article, CoreWeave has made some significant announcements. They raised $1.5B in an IPO on the NASDAQ, trading under $CRWV, and their share price is up over 200% in 6 months.
They have announced three expansions with OpenAI: $11.9B in March, $4B in May, and $6.5B in September, bringing the total commitment to $22.4B. These deals are targeting training. CoreWeave has also landed Meta as a new customer in September, singing a $14.2B deal over 6 years to 2031.
They have also announced an all-stock acquisition of Core Scientific in July for $9B, which represents a 1.3GW expansion of datacenter footprint. They also committed £1.5B to the UK, and $6B in Lancaster, Pennsylvania.
Note: for a blow-by-blow tracker of CoreWeave bringing capacity online, readers can see our datacenter industry model: https://semianalysis.com/datacenter-industry-model/
They acquired Weights & Biases in May, and OpenPipe in September. We will discuss the W&B integration below.
They also launched CoreWeave Ventures, a fund to invest in AI companies: https://investors.coreweave.com/news/news-details/2025/CoreWeave-Launches-Ventures-Group-to-Invest-in-Future-of-AI/default.aspx . We believe this is in direct response to strategic investment practices such as AWS Activate (up to $300k in credits), Microsoft for Startups (up to $150k in credits), Google for Startups Cloud Program (up to $350k in credits), and the NVIDIA Inception + NVentures program.
CoreWeave has announced some of the world’s first GB200 NVL72 and GB300 NVL72 deployments, as well as some RTX 6000 Pro Blackwell instances, setting the stage for future diversification with Rubin CPX.
In terms of our testing, CoreWeave’s clusters meet all criteria, and set the bar for other Neoclouds to follow. It is for this reason that we are aware of multiple examples where CoreWeave is able to command a higher price for managed slurm or Kubernetes clusters (by roughly 10-15%, per GPU-hr) vs their direct competition such as Nebius, Fluidstack, Crusoe, Lambda, and Together.ai. Indeed, CoreWeave’s pricing is closer to the pricing of the big 4 hyperscalers. The main challenge that we perceive for CoreWeave going forward is to continue innovating and differentiating vs their competition, so as to to maintain this pricing power. We believe they will be successful doing so for the GB200 and GB300 NVL72 generation.
In this section we will talk about what is new at CoreWeave, and how they keep setting the bar for others in the industry to follow.
Slurm-on-Kubernetes
Bare Metal Provisioning
Use of DPUs
Security
Monitoring and Health Checks
W&B Integration
Storage
TCO
Services
Customers
Slurm-on-Kubernetes
At this point CoreWeave has consolidated to three offerings:
CoreWeave Managed SUNK (Slurm on Kubernetes)
CoreWeave Managed Kubernetes
CoreWeave Bare Metal without any managed scheduler
Since the original release of SUNK in October of 2023, uptake has been strong for new clusters, which has led to the deprecation of their slurm-on-bare metal service. All new customers that prefer slurm are pushed to SUNK. Earlier in this article, we discussed the slurm-on-Kubernetes trend at large, where SUNK is the most mature option vs Soperator and Slinky. CoreWeave developed SUNK from scratch, controls the roadmap, and has built deep integration with their underlying Kubernetes runtime CKS, as well as their monitoring dashboards (mainly Grafana, branded as CoreWeave Observe™), health check system, and provisioning system (branded as CoreWeave Mission Control).
In addition, CoreWeave has gone beyond open-source slurm to develop their own custom fork of the popular job scheduler. Specifically, in open source Slinky, there are memory leaks in the REST API of the slurm controller which leads to issues if, for example, some user is trying to queue 100,000 jobs.
Specifically, the way that slurm works at scale is through the concept of priorities. In other words, there is no way for a big pretraining job with top priority to be auto-scaled down, and there should always be spare nodes available to be added to this job in the event of an interruption. But while that job is running, users can tag smaller research/experiment slurm jobs as preemptible, and run them on the medium or low-priority partition. Functionally, this means that the slurm scheduler hands off information to kubernetes, which labels the kubernetes job to associate it to the partition. In effect, frontier labs have a giant backlog of low priority sweeps that can always take up extra nodes: trying out the latest learning rate, data mix etc. to see if it improves their research.
As a result, CoreWeave re-wrote the logic in slurm’s REST API in go, and is now using an RPC-based login pod controller for SUNK that is more performant at scale.
Interestingly, we are aware of direct licensing deals that CoreWeave has done with end users who want to run SUNK on managed Kubernetes clusters outside of CoreWeave. While we don’t believe SUNK licensing is a meaningful revenue driver for CoreWeave, it is an indication of the quality of the customer experience when using SUNK and a testament to their engineering effort.
Bare Metal Provisioning
A significant difference between CoreWeave and other cloud providers is their use of bare metal machines for both control plane and worker node services. Since basically all CoreWeave customers use whole 8-way machines in standard HGX (or 4-way machines in NVL72 racks), there is no need to virtualize a machine into multiple 1, 2, or 4-way GPU instances.
However, other providers like Nebius and Crusoe who also don’t split up GPU machines continue to use kubevirt and cloud-hypervisor respectively in order to realize other benefits of VMs: shared block storage (resizing, quick provisioning, PXE boots, backup, clone, restore, etc.) and network isolation.
Since VMs are easier/quicker to spin up and down than bare metal machines (i.e. the underlying OS doesn’t need to change between tenants) CoreWeave has a challenge to address: how to quickly replace and repair a broken machine in a large cluster. To address this, CoreWeave has developed the Fleet Lifecycle Controller and Node Lifecycle Controller which are used by their FleetOps and CloudOps teams to provision machines through their service CoreWeave Mission Control.
This custom stack is actually using a CRD called a NodeSet on kubernetes that defines bare metal nodes as a kubernetes resource before they are even online. Furthermore, CoreWeave has developed custom operators, similar to a mix of a DaemonSet and ReplicaSet, for functions like idle checking and debugging. This customization extends to Protected Rolling Updates, which are aware of the slurm state and wait for nodes to drain before rolling out updated pods. Effectively, nodes that have been repaired after a hardware failure sit in a queue, waiting to be added to a logical cluster on the multi-tenant backend network fabric.
Use of DPUs
Due to the use of bare metal provisioning, CoreWeave must contend with the same challenges as AWS with Nitro or Azure with Boost. In other words, how to implement secure multi-tenant isolation for both the frontend and backend networks. It is important to note that these tenancy challenges exist even in the scenario where a customer has rented an entire datacenter in a wholesale bare metal manner. Tenants still hire and fire interns, consultants, partner companies, academic collaborators, and have general interest in implementing isolation between groups of users on the same underlying hardware.
As a result, CoreWeave uses Nvidia BlueField DPUs on every node to offload functions traditionally handled by a hypervisor on the host CPU (VPCs, encryption, network isolation, NAT gateways, etc.). Using a distributed NAT gateway and distributed storage gateway architecture eliminates a common central performance choke point. AI workloads are “bursty” since individual research jobs or autoscaling inference endpoints can randomly start pulling massive model weight files simultaneously. Switching from centralized to distributed gateway services on DPUs guarantees line-rate performance to WAN or storage.
On Kubernetes, this actually gets implemented via a CRDs and custom controllers, which allows for bare metal nodes to move between tenants while preserving network isolation and policy. The DPU becomes the enforced boundary, not the hypervisor. Effectively, the API for programming this layer is exposed to CoreWeave’s team via `kubectl get dpuconfigurations.nimbus.infra.coreweave.com`
On the backend network, InfiniBand network isolation is implemented by changing PKeys (Partition Keys) per tenant, which is the hardware-enforced mechanism similar to an Ethernet VLAN. CoreWeave is one of the only providers to offer SHARP, which can significantly performance for certain collectives. However, for the highest security customers, CoreWeave does not allow multi-tenant InfiniBand with SHARP enabled.

Security
When it comes to security, CoreWeave is the only Neocloud with a hyperscaler mentality. This means zero-trust policies, strict isolation between tenants, and continuous audits.
For example, while some other Neoclouds provide direct access to server BMCs, CoreWeave treats the BMC, which is a huge attack surface, with extreme caution. Host-to-BMC Access is Disabled: Both the KCS (Keyboard Controller Style) and NIC (RNDIS Ethernet over USB) interfaces from the host OS to the BMC are disabled. Effectively, the BMC management network is isolated to only communicate with the control plane (N/S side), with Layer 2 Isolation enforced to prevent lateral BMC-to-BMC movement (E/W side).
For very large customers, BMC access is via a dynamic jumpbox setup that utilizes the dedicated BMC network. An ACL on the DPU is updated by the Fleet Lifecycle Controller via NIMBUS and ensures they can only access BMC IPs in their specific tenant.
Another critical decision is avoiding scenarios where multiple customers run on the same machine. Effectively, customers can attack their own machine as much as they want, as seen in the container escape scenario, but if a node goes down for repair or is moved between tenants, it gets PXE booted to a clean state before another tenant can run on it. This is handled by the Fleet Lifecycle Controller (FLCC) and Node Lifecycle Controller (NLCC).
In terms of container escapes, future exploits are expected in upstream nightly branches from projects like pytorch, transformers, vllm, sglang, etc. and CoreWeave is in the process of switching to using ChainGuard images as the basis for all customer images. We’ve seen a common trend in this space following Broadcom’s acquisition of VMware, and the subsequent price increase to Bitnami. Notably, CoreWeave’s container images have become a standard for many other neoclouds, from login pods to nccl-test examples, many other providers are building FROM the coreweave image, or just providing scripts that pull the image from CoreWeave’s gcr registry directly: https://github.com/coreweave/nccl-tests/pkgs/container/nccl-tests
More on security:
Defense-in-Depth and Risk Modeling: Security is built on a comprehensive threat model that drives a defense-in-depth strategy, informing a secure-by-default application development lifecycle and deep runtime and infrastructure hardening.
Application and Code Security: The Application Security Maturity Framework mandates that all code changes undergo secret scanning, SAST, SCA, and DAST with strict remediation SLAs. Risk is blocked pre-production via pre-commit hooks, policy-as-code, CI/CD enforcement, Chainguard base images, and golden service templates.
Production Infrastructure and Access: Teleport governs privileged access with customer approvals, RBAC, TPM-backed node joins, and session logging (including keystrokes/syscalls), actively eliminating traditional SSH.
Fleet Integrity and Attestation: SPDM-based firmware attestation, Secure Boot, and Measured Boot validate fleet integrity from power-on, ensuring only cryptographically verified firmware runs and enabling remote attestation prior to workload scheduling.
Data and Workload Encryption/Identity: SecVault PKI infrastructure supports encryption for data (object storage, databases, APIs), while mTLS adoption will bind endpoint identity to trusted firmware. Cross-cluster JWT authentication and SPIFFE integration secure workload-to-workload communication.
Continuous Monitoring and Posture: Eclypsium and Wiz provide continuous security posture management, including firmware vulnerability scanning and cloud workload posture, while telemetry pipelines ensure policy compliance and deviation detection.
Enterprise Identity and Data: Security mandates phishing-resistant MFA and device trust for all users, with Kolide enforcing device posture checks. Policy-as-code Okta rules govern access, and systems like Cyera, Proofpoint, and Netskope manage data governance and DLP controls.
The feedback is here is the security concerns from CoreWeave is way to limiting for a lot of power users. For example as default, systemd is not available, and a lot of CPU and GPU profiling tooling is also not available due to the restrictive security concerns. This has led to an strange design choices from end users such as running background processes inside tmux shells instead of using system.
Monitoring and Health Checks
CoreWeave’s monitoring and health check systems are a key differentiator, and the primary line item being to quantified in TCO discussions with large customers who question the CoreWeave pricing premium. In other words, users running at 10k+ GPU scale understand the impact that interruptions can have on their training jobs.
CoreWeave recognizes that standard Nvidia (DCGM) exporters do not expose all critical metrics, such as certain thermal sensors vital for diagnosing subtle hardware issues like failing thermal paste. CoreWeave developed proprietary exporters using the lower-level NVML library. This provides the necessary granularity for robust node-level health validation.
In addition, they have also built exporters for the interconnect fabric. To identify transient physical-layer problems like signal integrity degradation between compute trays and switches, CoreWeave developed a sophisticated correlation engine. We have noticed that other vendors do not run sustained multi-node jobs during burn-in and during active scheduled health checks, instead running single node jobs, collectives, and GPU stress tests (GPU burn, GPU fryer, or Multi-node ubergemm) individually. The point is that failures are often caused by the simultaneous thermal expansion and contraction of the GPUs and the interconnect. This is especially important for NVL72 rack-scale architectures.
By tracking events like simultaneous XID or SXID errors across the fabric, CoreWeave can automatically root-cause many failure types. For instance, if multiple compute trays connected to a single switch port report errors, the switch is flagged, while if an error follows a specific tray after it has been moved, the tray or its cabling is flagged. Simple intuition like this builds with experience, which CoreWeave has now been building for months with the GB200 and GB300 NVL72 rack-scale systems that have posed so challenging for others to operate. https://semianalysis.com/2025/08/20/h100-vs-gb200-nvl72-training-benchmarks/#gb200-nvl72-unreliability

Meta’s Llama 3 paper is the most clear description of where reliability issues can manifest in a training campaign. Over a 54 day period when training Llama 3 405B, using 8 pods of 3,072 H100s, with 16k of 24k GPUs in use at a given time, there were 466 job interruptions (47 of which were planned upgrades), resulting in 419 GPU server failures, and three instances of heavy manual intervention.
This is an implied MTBF of 2,111 H100-days, and we can assume that “heavy manual intervention” means restarting the job from the last checkpoint.
This example highlights that even small improvements in hardware stability and interconnect performance can shave days or even weeks off of a multi-month training schedule for a large model. Hardware failures also stand out as the #1 source of frustration amongst researchers that we talk to.

This section of this paper has also become infamous for two other reasons: a mention of the “diurnal 1-2% throughput variation based on time-of-day” (i.e. GPUs get hotter in the middle of the day and perform worse) and a comment on how “tens of thousands of GPUs may increase or decrease power consumption at the same time (…) can result in instant fluctuations of power consumption across the data center on the order of tens of megawatts, stretching the limits of the power grid” which resulted in the accidental upstream of the PYTORCH_NO_POWERPLANT_BLOWUP=1 environment variable at some point by a Meta engineer.

In summary, we continue to treat CoreWeave’s monitoring dashboard, passive health check approach, and suite of active health checks as the standard when working with other Neoclouds on their reliability challenges. To read more about these details, see: http://clustermax.ai/expectations/health-checks
W&B Integration
Prior to the acquisition, Weights & Biases (W&B) had become the industry leader in user-facing metrics for job scheduling, but pricing was quite high and the company seemed to be innovating at a loss. Clearly, CoreWeave noticed a big overlap between their customers and W&B’s enterprise customers. Specifically, some of these customers have been called out for having absolutely massive logging infrastructure behind their W&B deployments, effectively abusing the system.
The obvious first step in W&B integration was to integrate infrastructure level metrics, like OOME’s or AER’s into the W&B dashboard so that users can see them. Generally, individual researchers don’t get access to the cluster-level grafana dashboard, but there is still lots of useful information that they can use, specifically from the underlying Nvidia DCGM.
Storage
CoreWeave’s storage offerings have matured over time to include a native Object Storage offering, “CAIOS” (CoreWeave AI Object Storage) and a local cache, “LOTA” (Local Object Transfer Accelerator).
LOTA is a transparent, distributed cache that lives directly on the local NVMe of every GPU node. Public benchmarks show it reaching a sustained throughput of over 7GB/s per GPU on Blackwell.
Effectively, with LOTA, the user doesn’t need to cp or rsync anything. They simply point their S3-compatible application to the cwlota.com endpoint instead of the primary CAIOS endpoint, cwobject.com. LOTA then manages the caching of data onto the local NVMe in a distributed manner across the cluster.
According to list prices, for example, a 1,204 GPU cluster at $3/hr for 1year will cost $26.9M.
However, for storage, 1PB of active data at $0.11/GB per month, costs $1.3M or 4.6% of the total BOM.
In general, we rarely see storage costs exceed 5% of the total cluster cost.
Over time, we expect hyperscalers like AWS, Azure, GCP, and Oracle to follow the current trend of reducing their price per GB per month on their Object Storage offerings (driven by competition from CloudFlare R2 in many cases), reduce or remove punitive egress fees, and reduce or remove costs associated with storage operations like data access.
Support
In our experience, and when talking directly to users of CoreWeave services, we get the impression that team members are empowered, excited to help customers, and proud to work at the company. Notably, all datacenter technicians are CoreWeave employees, go through standard company training, and have equity in the company. CoreWeave is one of the only Neoclouds that has not augmented their capacity with someone else’s GPUs, maintaining vertical integration for all their facilities.
In addition, CoreWeave’s “direct to expert” support model means that all customers get quick responses, at no additional cost. But this isn’t always the case! Recently, CoreWeave actually sent us a ClearFeed notification in slack because their annual company offsite might result in some delayed support responses.

Last time, we recommended that CoreWeave work on a UI console flow for deploying their managed slurm solution, ideally with less than four button clicks. CoreWeave has basically achieved this, though it does seem like the 30+ datacenters on screen are mostly greyed-out.

Total Cost of Ownership (TCO)
In summary, the result of CoreWeave’s execution for Slurm-on-Kubernetes, Bare Metal Provisioning, Use of DPUs, Security, Monitoring and Health Checks, W&B Integration, Storage, and Support provides CoreWeave an ability to argue for lower TCO vs their competition, and command a pricing premium on a per GPU-hr basis.
Our feedback to CoreWeave as they scale is to continue to work on the on-demand, self-serve cluster experience, continue to develop autoscaling features for supporting inference at scale, and to maintain their lead in reliability for the NVL72 rack-scale deployments. From the customer perspective, a downside of CoreWeave continues to be that they do not offer on-demand instances or autoscaling, and rarely accept short-term rentals. This is different from Nebius and Crusoe, and limits the potential upside associated with high margin “spot instance” markets.
Gold
Nebius
Since ClusterMAX 1.0, Nebius has continued to show up as the most direct competitor to CoreWeave in our customer conversations. Nebius counts customers such as Shopify, Recraft, Mirage, Genesis Therapeutics, and most recently landed a 5-year $17.4B deal (with expansion to $19.4B) with Microsoft for their Vineland, New Jersey datacenter. We expect continued pull-ins from Nebius to Microsoft and the healthy deal pipeline sugests more incremental capacity coming online over time.
Nebius differentiates financially due to its low cost of capital, with billions on its balance sheet, no debt, and a strong position as one of two publicly traded GPU-only Neoclouds that we track (the other being CoreWeave). Nebius differentiates technically with a virtualized approach to GPU infrastructure (built on experience from Yandex), and an AI-native approach due to their dogfood approach with their internal AI team, that has resulted in multiple spinoff startups in the AI space.
While we are aware of their struggles in securing colocation deals and establishing a credit rating, their engineering prowess is evident. The Nebius platform prioritizes flexibility, on-demand access, and a robust Kubernetes-native experience. This stands in contrast to CoreWeave’s bare metal, long-term reservation model and makes Nebius a compelling choice for autoscaling and spot instances, specifically used for experimentation and inference. Nebius continues to show up as a low-cost provider on various marketplaces, and as the infrastructure, and is one of the only providers with realistic pricing right on the homepage of their website.

As if that wasn’t enough, Nebius is also foraying into the inference endpoint market!
In this section, we will discuss our hands-on experience with Nebius’ platform:
Slurm-on-Kubernetes
Virtualization and Storage
Monitoring and Health Checks
On-Demand Instances
Slurm-on-Kubernetes
Since ClusterMAX 1.0, Nebius has officially launched their managed Soperator service for a fully self-service Slurm-on-Kubernetes experience.
We were able to test this out, and as expected we got a Slurm cluster that was completely set up and ready for use out of the box. This included pre-installed drivers, Docker, passwordless SSH between nodes, and expected performance on collectives (nccl-tests) and pytorch training jobs (torchtitan pretraining) out-of-the-box.
These requirements may be considered basic, but are not to be taken for granted. Later in the article we will describe how difficult it is for other providers to install Slurm-on-Kubernetes (via Soperator or Slinky) with good defaults. Notably, since Nebius uses its own open-source project, Soperator, they completely control the roadmap and are vertically integrated from customer support issues in an sbatch script, down to the kubernetes orchestration, hardware, and datacenter troubleshooting layers.
The control plane also looks nice:

Virtualization and Storage
Unlike CoreWeave’s bare-metal-first strategy, Nebius has built its platform on layers of Kubernetes clusters managing each other, using KubeVirt all the way down. This means that customer workloads, even for full 8-GPU nodes, run inside virtual machines on a kubernetes cluster that they can access, which itself is managed by a kubernetes cluster that only Nebius can access. This design is similar to how GCP orchestrates compute. The architecture allows Nebius to leverage the benefits of VMs, such as rapid provisioning and advanced storage features. For example, they use virtio-fs to attach a massive shared root filesystem, which presented as 197TB out-of-the box in our cluster, mounted at “/”, but obviously does not require 197TB of drives to be physically installed in the servers themselves.

Nebius’s storage solution is built on YDB https://ydb.tech/docs/en/contributor/distributed-storage , which actually underpins their block, shared filesystem, and storage offerings. This approach to storage has reduced startup times (i.e. pulling a container image or model file) for new machines with some example on-demand autoscaling workloads from over 10 minutes to around 2-3 minutes.
A common perception is that bare metal offers superior performance over VMs. When we raised this, the Nebius team was adamant that users should simply benchmark the platform. Their position is that because there is no virtualization layer for the InfiniBand fabric or the NvidiaGPUs themselves, performance should be identical to bare metal. Our initial testing seems to validate this claim, and third party results do too. For example, in the last round of MLPerf Inference v5.1 benchmarks, Nebius achieved top tier performance on Nvidia GB200 NVL72, HGX B200 and HGX H200 systems, for inference with Llama models.
https://nebius.com/blog/posts/bare-metal-class-performance-mlperf-inference
An additional note that customers have expressed with VMs is the ability to easily enable low-level hardware counters for performance monitoring. The method for enabling hardware counters varies by virtualization platform.
In VMware vSphere, you can enable virtualized CPU performance counters by editing the VM’s settings. This feature, known as vPMC, allows the guest OS to access the host’s Performance Monitoring Unit (PMU). Meanwhile on Windows Server and Windows 10/11 with Hyper-V, you can use PowerShell cmdlets like Set-VMProcessor to enable specific performance monitoring hardware features (e.g., pmu, pebs, lbr) for a stopped virtual machine.
However, on KubeVirt (which Nebius uses) via KVM/QEMU, the VMs inherit the capability to expose hardware counters from the underlying host. The process typically involves configuring the VM’s CRD on the underlying kubernetes cluster to enable virtual PMU from Intel. Hardware-level performance data like CPU cycle counts, cache misses, and branch mis predictions are available through there. You can typically enable this capability by activating a power metrics or PMU plugin, such as a Telegraf plugin, on the Kubernetes cluster. For example, some users perform advanced performance tuning by using features like the Kubernetes CPU manager to pin vCPUs to host pCPUs for predictable latency on CPU-heavy workloads.
Notably, for very large customers who insist on it and are doing a long-term rental, Nebius does have an option to provide bare metal clusters.
Monitoring and Health Checks
Initially, our access to monitoring was a simple Grafana dashboard available via an SSH port forward. These metrics and health checks were basic, but the team later released a series of updates that raised the bar significantly.
Interestingly, since all of this is being integrated into SOperator, and Soperator is open source, we have been able to watch the roadmap come to life on the Soperator GitHub project: https://github.com/orgs/nebius/projects/1

There is no other Neocloud as open and transparent with their development as Nebius.
Around the same time we got notified about the improvements to the dashboard and health checks, Nebius also released a blog post describing what they do for reliability in detail: on-site factory tests, node deployment tests, virtual platform tests, pre-provisioning cluster tests, passive and active health checks. We believe this suite of burn-in tests, checks, and monitoring dashboards will improve cluster reliability and usability, especially as Nebius moves to adopting the GB300 NVL72 rack-scale systems at scale, for customers such as Microsoft.


In the blog, Nebius describes a hypothetical example with 13 failures over 336 hours (14 days) on a 1,024 GPU cluster, resulting in a GPU-level MTBF of 26,446 GPU-hr, or 1,101 GPU-days.
An apt comparison for this is to the data from Meta’s Llama 3 paper, which claims 419 failures over 1,296 hours (55 days) on a 16,000 GPU cluster, resulting in a GPU-level MTBF of 50,677 GPU-hr, or 2,111 GPU-days.
As a further comparison, we have heard from customers that run similar scale clusters (1k to 2k GPUs) from gold and silver tier providers experience as much as 5+ failures per day, for extended periods of time. This translates to a GPU-level MTBF of less than 10,000 GPU-hr, or less than 400 GPU-days.
In our research, the number shared by Meta are very high, demonstrating the quality with which Meta runs their datacenters and Hopper generation GPUs. Meanwhile the hypotheical number from Nebius tracks as a reasonably good customer experience.
Later in the blog, Nebius claims to have had single 3,000 GPU cluster operate uninterrupted for 169,800 GPU hours or 56.6 hours of stable operation. This would translate to an absurdly high GPU-level MTBF of 169,800 GPU-hours or 7,000 days. We are generally frustrated by providers who cherry-pick reliability data in this manner.
We encourage customers to track this reliability data for themselves, especially if DataDog, New Relic, Splunk, or a custom Prometheus Alertmanager is setup and connected to a slack channel for notifications on XID related errors. If you are tracking this data, and are willing to contribute it to anonymized and aggregated research, please get in touch: clustermax@semianalysis.com

It is clear that Nebius is building battle scars when it comes to managed slurm clusters at the 1k+ GPU scale.
On-Demand Instances
A key differentiator for Nebius is their robust support for on-demand and autoscaling workloads. This is a direct result of their software-defined architecture. They offer pre-emptible instances, primarily for inference customers, which function similarly to spot instances on hyperscalers. This allows users to access capacity at a lower cost, with the understanding that the workload can be interrupted.
We’ve seen public examples of this in action, such as Shopify’s work with SkyPilot and dstack sky on the Nebius platform, which highlights their strength in supporting dynamic, research-oriented workloads. This flexibility is a significant advantage for users who cannot commit to long-term contracts, and seems to be a major source of inbound customer qualification for Nebius.
TCO
Nebius presents a compelling and technologically distinct alternative in the GPU cloud market. Their deep investment in a Kubernetes-native, virtualized stack using KubeVirt and Soperator allows them to offer a degree of flexibility and on-demand access that is rare in the high-performance training space. While they may face headwinds in datacenter acquisition, their software stack is mature and performant.
Our feedback to Nebius is to continue improving their monitoring and health-check visibility as they roll these updates out to customers, and to streamline the notification process for all tiers of users. Their ability to deliver bare-metal-equivalent performance through a VM-based architecture is a significant engineering achievement. For users whose needs revolve around research, autoscaling inference, and workloads that can benefit from a spot-like pre-emptible market, Nebius is an excellent choice that challenges the long-term reservation model of its competitors.
Notably, some customers have been fixated on Nebius’ Russian roots, despite the fact that all of their staff are based outside of Russia, as opposed to making purchasing decisions on technical merits. We’re not sure how Nebius can address customers that hold this mindset.
Oracle
Oracle just posted the most incredible quarterly earnings the market has ever seen. We were ahead of estimates, but still didn’t catch this in full. Specifically, Oracle signed four multi-billion-dollar contracts with three different customers in Q1, including a $300Bn+ deal with OpenAI. Recent release from The Information suggested AI server margin concerns from these multi-billion contracts, but we think lower margin during a ramp up period makes sense and expect margins to significantly expand.

Oracle is in a unique position as the only hyperscaler (over 100 AD’s across 45 active regions globally) without an in-house AGI Research program or significant venture capital investment (though Larry did invest $2B in xAI after a few texts from Elon) which has led them to land contracts with OpenAI, Meta, ByteDance, and Nvidia. They currently have over 60% of US Stargate according to public releases. We also track this in detail in our Accelerator & HBM Model.
Oracle also pivoted to wholesale bare metal early, taking advantage of their balance sheet while also maintaining a notable presence in the managed slurm and managed kubernetes market. In many cases, we have found other cloud providers giving us servers with IP addresses, locations, and other configuration information that makes it clear we’re actually running in an Oracle datacenter.
Oracle’s default setup is typically provisioned through the console, using Terraform for automation behind the scenes. A notable point of friction for some users is the almost-mandatory use of Oracle Linux (version 8.10 by default), which is based on Fedora. This operating system choice is contentious, as many AI workloads, particularly those in the open-source community, are first tested on Debian-based operating systems, specifically Ubuntu, for its broad compatibility and ease of use.

We attribute this default to Oracle Linux as a historical beef with Canonical. This is surprising given that certified Ubuntu images have been available on Oracle Bare Metal Cloud Services since 2017 and are current modern to version 24.04.
In order to deploy a slurm or kubernetes cluster through the OCI console, users unfortunately need to use the OCI console. Visually, the console adheres to the Redwood design system, and uses their JavaScript Extension Toolkit (JET), both of which do not spark joy. Oracle remains steadfast in its lifelong commitment to Java, even in the age of AI. After deploying a cluster, users who want to access a Grafana dashboard will need to navigate the maze of UI element options at their disposal. For those interested, the cheat code is: left hand burger menu > Developer Services > Stacks > Stack details > Application Information > (scroll down) > Grafana admin password.

During testing of both slurm and Kubernetes, everything went smoothly. We were able to quickly achieve expected collective bandwidth on nccl-tests, and expected MFU on torchtitan. Interestingly, upon first login to the slurm cluster we found a single node in a drain state. This was quickly replaced, but highlighted the difference in approaches to health checks and bare metal node provisioning when compared to CoreWeave.
Oracle is actively working to improve platform reliability and user experience. Node Auto-Repair and Node Problem Detector integration is expected in Q4, with the goal of providing customers with a “doctor HPC” user experience via an official OCI binary. The team is also developing an Active Health Check mechanism called the Sustained Workflow Check, which involves running PyTorch and CUDA matmul linear regressions for 2-5 minutes to ensure sustained performance. This check is currently running on-demand, and in most cases an Oracle engineer works directly with customers to schedule the checks in a low-priority partition. Default behaviour is being developed to integrate this into both slurm and OKE.
For managed Kubernetes, Oracle offers OKE (Oracle Container Engine for Kubernetes), with all resources being public by default. Users have the option to disable this default and utilize the Nvidia GPU Operator, although the default setup uses a custom operator. OKE provides GPU and GPU+RDMA pools as provisioning options, along with integrated storage options via a checkbox. The official instructions for setting up RDMA are publicly available, and nccl-test manifests show good out-of-the-box performance for allreduce and allgather operations.
A key point of frustration in the OKE setup is the lack of a direct kubeconfig file. Users are instead required to SSH into the cluster to perform management functions. This is counter-intuitive for a publicly accessible, load-balanced service and can require a bastion proxy for proper external access to the cluster from a cluster admin or a user. One of the key benefits of kubernetes over slurm for users is the ability to develop code locally, and switch between different cluster contexts quickly, without ssh.
In terms of networking, the default for OKE to use an RDMA network in Kubernetes is to inject two fields, hostNetwork: true and dnsPolicy: ClusterFirstWithHostNet into pod specs. On OKE, Oracle does not deploy the full GPU Operator but rather the device plugin only, with plans to add the full operator later. The Nvidia toolkit is installed and automatically updated on the nodes, ensuring the software stack is current. Performance testing on kubernetes using vllm benchmarks for pd disaggregation with llm-d showed strong results, and was easy to setup and integrate with provided LoadBalancer services via public IP.

The initial testing phase suffered from a lack of integrated health checks. While slurm metrics were added later, the control plane initially lacked the necessary CLI features, which required some rollbacks to prevent customers from inadvertently terminating jobs. The introduction of a new “mgmt” CLI aims to address these operational complexities and we agree.

For Storage, Oracle offers a robust marketplace, with Weka and DDN being the primary partners. Weka is available both on their online on-demand marketplace (i.e. it can be built on-demand with bare-metal instances full of NVMe) and through direct deals. Oracle customers report that the shared support experience is stronger with Weka on Oracle than with either VAST or DDN. For Networking, Oracle is like any other hyperscaler talking their book, trying to convince large customers that InfiniBand is not the only high-performance network solution, and their RoCE works well. They seem to be making progress in this regard.
Overall, Oracle has made significant progress improving their managed cluster offerings, with improved monitoring dashboards and node lifecycle management, but there is still room to improve in terms of proactivity. There is still a chance that customers will discover a bad node before Oracle’s automated systems, and have to report the node for replacement manually.
Oracle continues to be the most cost-effective of the four hyperscalers, and stands out as deploying new infrastructure the quickest, while also providing the best support. We expect Oracle to continue to grow both their wholesale bare metal and managed cluster business going forward, and we encourage Oracle to maintain its commitment to excellent customer support for all customers.
Azure
Azure maintains its ranking as a Gold-tier provider, considering that it will still be providing the bulk of OpenAI’s capacity through the end of 2026.
Unfortunately, if you don’t work for OpenAI, Azure is not a significant player for managed clusters or on-demand VMs. Capacity is constrained across all regions globally for Hopper and Blackwell, and the CycleCloud slurm provisioning process is in need of an update, or at least some simplification. This has been reaffirmed with OpenAI and Microsoft locking in a long-horizon partnership and Microsoft geting a ~27% stake with model/IP rights through 2032.
This gap between wholesale bare metal experience for anchor tenants like OpenAI and the managed experience for the rest of the market becomes clear when we look at reliability and compare slurm (CycleCloud) with kubernetes (AKS).
AKS reliability includes fully managed Node Auto-Repair feature. This system automatically detects unhealthy nodes based on kubelet status conditions and attempts remediation through reboots or re-imaging. This philosophy extends to monitoring, where Azure Monitor for Containers provides, integrated visibility into every layer of the cluster out-of-the-box.
In stark contrast, CycleCloud relies on the traditional HPC model via slurm’s HealthCheckProgram. However, CycleCloud does not provide a good default, like LBNL’s Node Health Check https://github.com/mej/nhc, or anything customized to Azure infrastructure. Instead, the full operational burden of health checks is placed on the user, who must write, test, and maintain custom scripts to monitor GPUs and the InfiniBand fabric. Beyond that, the integrated monitoring is limited to a high-level node status view in the UI, forcing users to implement their own solutions for any meaningful job-level or hardware-specific insights such as DCGM dashboards.
As an example, when deploying a CycleCloud cluster, the current documentation for CycleCloud is split between older guides and a newer GitHub-centric approach. Users are required to configure login and scheduler nodes separately, as well as provision and manage their own MySQL database to handle slurm accounting (sacct).

However, the comprehensive nature of a hyperscaler cloud platforms also has some merits. Networking is straightforward offering access options via NAT Gateway or bastion host. It also provides flexibility through support for custom images, integration with Azure Spot Virtual Machines for cost-effective bursting. Azure has a legacy in HPC that will feel familiar to users coming to a GPU cluster from an academic HPC background.

On networking, Azure continues to lead the hyperscalers in performance, being the only one to deploy with InfiniBand, and implement SHARP at scale. Security is also rock solid, Microsoft in general holds a reputation for robust security and compliance practices, which has made it a trusted partner for federal government agencies and defense contractors.
With that said, the dynamics of Microsoft’s relationship with its key customer, OpenAI are shifting. Since Satya mentioned he’s “good for his $80B”, Stargate has turned into a $600B Behemoth, much of which has been captured by Oracle. Google, xAI and Meta have followed suit, with Zuck committing to the same total spend of $600B over the next 5-7 years.
The reality is that we are forecasting Azure to lose share in the market when considering the frontier labs compute requirements and existing commitments. This leaves Azure with the rest of the market, who generally demand strong managed cluster experiences for slurm or kubernetes and a streamlined support experience.
To address this customer base, we believe that Azure must re-vamp its CycleCloud offering, simplifying the current cluster deployment and monitoring experience. Otherwise, Azure is at risk of being demoted to Silver due to its poor user experience for startups from Series A to AI unicorns. Compared to the fully managed, Kubernetes-native, and vertically integrated offerings from Neoclouds like CoreWeave, Nebius, and Oracle, as well as the aggressive capacity buildout and revised pricing we have seen from AWS and GCP, Azure has stiff competition.
Fluidstack
Fluidstack is the only cloud to debut in our Gold tier this round, and certainly has the most unique business model. Almost all of Fluidstack’s customer deployments involve a third-party datacenter provider. Fluidstack is effectively the hired gun that organizations go to in order to turn bronze-tier datacenter infrastructure into a gold-tier customer experience. Google has also gone into the market to secure colocation demand with Fluidstack as the operator of Terawulf and Cipher sites, potentially for their TPUs. We explore why GCP is willing to “backstop” these deals and why GCP needs Fluidstack here.
This is clear when it comes to customers such as Meta, Poolside, Blackforest Labs, and an unnamed customer running in a TeraWulf datacenter in Buffalo that got a massive financial backstop from Google.



Our hands-on experience with Fluidstack was a live demonstration of their value proposition: a highly collaborative, deeply technical partnership that rapidly improves the platform based on expert feedback. While the initial cluster had rough edges, the speed and precision with which the Fluidstack team addressed every issue was unparalleled.
Our initial slurm cluster came with pyxis and MPI support integrated into srun, and initial two-node nccl-tests showed performance within range for large message sizes. However, we immediately hit a significant usability issue: the prolog.d script was so bloated with health checks that it took over a minute to schedule an interactive run on a single node. The script was running full single-node NCCL tests for NVLink and InfiniBand, plus host-to-device bandwidth checks, every time a job started.
When we pointed this out, the team immediately acknowledged it and committed to their roadmap of moving these active health checks to run on idle nodes in the background, which is the standard practice for other top-tier providers.
This kicked off a rapid-fire feedback loop that defined our testing period:
Performance Tuning: We noted that the Nvidia HPC-X toolkit was missing from the base image, which is necessary for optimal nccl performance at medium message sizes. While it was available within NGC containers, not all users leverage pyxis/enroot. Within 24 hours, the Fluidstack team had deployed HPC-X to the base image on our cluster and added it to their standard deployment pipeline for all customers.
Monitoring Dashboards: The Grafana dashboard was solid, but we identified missing graphs for NVLink Rx/Tx utilization and incorrect DCGM metrics for tensor core pipes (they were capturing SIMT units instead of tensor core-specific pipes like DCGM_FI_PROF_PIPE_TENSOR_HMMA_ACTIVE). The team implemented the correct DCGM metrics the following day.
Security Posture: This was the most critical finding. We discovered the cluster was running a version of the nvidia-container-toolkit vulnerable to NVIDIAScape (CVE-2025-23266). The team patched the vulnerability on our cluster within minutes of us reporting it. While the immediate fix was impressive, our feedback focused on the larger operational need for automated dependency scanning and a proactive security process, such as enrolling in Nvidia’s security embargo program. This prompted a healthy discussion on their software supply chain security strategy.
Passive Health Checks: We found that DCGM’s background health checks were not enabled. By injecting PCIe replay errors (dcgmi test --inject --gpuid 0 -f 202), we confirmed that the node would not automatically drain. Our recommendation was to actively poll dcgmi health -c and configure NVIDIA Health Check (NHC) to drain nodes based on specific thresholds (e.g., >8 PCIe replays per minute or >100 NVLink CRC errors per second). The team immediately added this to their near-term roadmap.
Transitioning to Kubernetes was seamless, with a kubeconfig readily available from the UI. The cluster provided a solid foundation with standard components like Cilium for CNI, a CSI w/ ReadWriteMany support, node-problem-detector, kube-prometheus-stack, draino, a custom controller to turn off ACS, and the Nvidia Network Operator + GPU Operator, all managed via ArgoCD. This high-touch model, typically involves shared Infrastructure-as-Code repos, ensuring customers get the exact tools they need, such as adding cert-manager in our case.
This test, however, resurfaced the most critical theme from our slurm evaluation: software supply chain security. We discovered that the Nvidia GPU Operator chart was a minor version behind, leaving the cluster vulnerable to the same NVIDIAScape exploit. This highlighted a significant gap in their proactive security posture, particularly their absence from vendor embargo programs that provide advance notice of vulnerabilities. Once notified, the team coordinated a maintenance window and patched the vulnerability in under an hour, and motivated them to formalize a security process that includes more frequent proactive updates, subscriptions to vulnerability databases, and taking steps to join Nvidia’s disclosure program.
Overall our experience with Fluidstack was strong. The platform was not perfect out-of-the-box, but both slurm and kubernetes were both in a perfectly usable state within hours of cluster handover, and the engineering team demonstrated an elite level of responsiveness and expertise. Issues that might take weeks or months to get addressed in a hyperscaler’s ticketing system were fixed in hours. If there is anyone that demonstrated the “Forward Deployed Engineering” ethos during our testing, it was Fluidstack.
Crusoe
Since March, Crusoe has been hard at work expanding their datacenter footprint, while trying to keep the Neocloud business alive.
Crusoe has announced:
A partnership with Oracle to develop Abilene, the flagship Stargate project for OpenAI, at over 1.2 GW, worth $15B in joint venture funding.
An order of 29 LM2500XPRESS aeroderivative gas turbine packages from GE Vernova, enough for over 1GW of power.
A deployment of AMD MI355X GPUs, despite counting Nvidia as a key investor in their $600M Series D fundraise.
A 1.8GW datacenter in Wyoming, with a design to scale up to 10GW: https://www.crusoe.ai/resources/newsroom/crusoe-and-tallgrass-announce-ai-data-center-in-wyoming.
Expansion of their Iceland facility with atNorth, and a $175M credit facility for this project.
A smaller, 12MW facility in Norway with Polar, and planned expansion to 52MW.
A $750M credit facility from Brookfield.
A $225 million credit facility from Upper90.
“Prometheus,” a 150MW facility located in the Permian Basin in West Texas.
Interestingly, Prometheus has debuted Crusoe’s Digital Flare Mitigation technology publicly for the first time. During oil extraction, at sites like the Permian Basin, natural gas flaring is a waste product. However with DFM, Crusoe is able to install onsite mobile datacenter units that divert the waste product to generators for the datacenter onsite. These DFM’s have been announced as “Crusoe Spark”, and now include all the requisite infrastructure required to host B200s.

After all these announcements, Crusoe is left with a claimed 3.4GW of datacenter footprint, some of which is already showing up as revenue on their balance sheet.

So yeah, lots going on.
As for the actual, customer experience on Crusoe, around six months ago when we started testing slurm on Crusoe, they had just launched their fully managed slurm solution called “Auto Clusters”. The lifespan of this service offering has come and gone in the interim period, with the focus now being a Slurm-on-Kubernetes experience. Unfortunately, the new Slurm-on-Kubernetes experience is in its early days and is not usable out of the box.
Starting up a cluster is simple, via the Crusoe CLI, avoiding complicated terraform scripts and simplifying some of the complexity of a webUI.

However, when a simple CLI approach is used, we expect reasonable defaults. Crusoe claims to have developed their Slurm-on-Kubernetes offering in-house, while taking inspiration from Slinky. Unfortunately, the login pod was missing vim, nano, git, python, and sudo permissions. We gave some recommendations on how to take less inspiration from open-source Slinky and make the cluster usable out-of-the-box. The SonK offering also doesn’t support partitions, RBAC, and SSO integration, making it basically unusable for a research lab beyond the scale of about 10 researchers.
In addition, when provisioning a kubernetes cluster without slurm for our testing, we had a lot of extras to setup. A Crusoe CMK cluster does not include a default ReadWriteMany StorageClass, making it impossible to deploy any workload with a persistent volume claim. We had to go through many extra configuration steps on the console to figure out how to configure this storage class.
During our testing, we also encountered several performance and reliability issues on slurm, kubernetes, and on a standalone machine. We repeatedly saw NVML driver mismatch errors inside individual Docker containers, indicating potential image or driver management instability. We expect this is due to Crusoe’s use of cloud-hypervisor, and insistence on building all their infrastructure, including GB200 NVL72, with VMs.
On the networking side, while PKeys for InfiniBand partitioning were integrated, using them through the console was not intuitive. We have also had challenges with shared filesystems randomly unmounting, requirements to deploy OS drives and configure RAID settings manually (with the requisite footguns).
In conversations with Crusoe users when discussing reliability at scale, it has been hit-or-miss. Some have had good experiences, but anyone who tested clusters in Crusoe’s Iceland facility prior to March 2025 seem to have all had a common experience: lots of link flaps and random filesystem unmounts. Crusoe ended up having to clean the 20,000 fiber ends using a “clicker” that were full of dust and other debris. Some people have said that the debris was volcanic ash.
We found that in November 2023 the Icelandic Data Center ICE02 from atNorth started publishing status updates regarding increased seismic activity and volcanic uplift near Mt. Þorbjörn in the Reykjanes Peninsula. The datacenter is about 35km away from this volcano.



It is our understanding that this datacenter Crusoe now calls home has continued to experience significant seismic activity and air quality concerns, leading to some more hits on YouTube videos like this one from Iceland.

Overall, Crusoe is clearly executing on an ambitious strategy, securing massive power capacity and datacenter real estate. They have already pivoted once from crypto mining to AI cloud, and seem to be in the process of another pivot from cloud provider to datacenter infrastructure provider.
However, Crusoe is at risk of being downgraded to ClusterMAX Silver due to many of their top individual contributor engineers quitting, leaving the culture in their cloud division beginning to resemble big tech. There are too many middle managers across the organization, especially in engineering. This has caused incredibly slow moving releases, such as their AutoClusters feature, leaving us with concerns about the future of Crusoe’s public cloud offerings. Chase needs to do a rapid course correction if he doesn’t want to lose all of his 10x engineers and eventually lose their Neocloud business with it.
Silver
Together
Together is a strong provider with a robust cluster offering for both slurm and kubernetes, but it is held back from the gold category due to reliability issues. When comparing offers, we hear from users that they generally expect a lower price per GPU-hr from Together to justify the trade-off in reliability. Together is among a few providers for which we tend to hear the most reliability complaints about from users operating clusters of 64 GPUs or more. We expect this is due to their use of a broad mix of datacenter partners, which creates a “roll-of-the-dice” dynamic for performance and stability. Unfortunately, Together also does not offer to do 1-week POCs with most customers, unlike other Silver, Gold, and Platinum tier providers, which makes it difficult for buyers to know what sort of experience they will have on the cluster before making a multi-million dollar commitment.
These are all the reasons why TogetherAI went from an Gold tier provider to Silver tier provider.
Together’s multi-datacenter strategy seems to be driven by necessity. They have significant compute needs due to their serverless inference endpoint business, which is growing steadily. During our research for this article, we spoke with multiple Neoclouds that claim Together is one of their biggest customers. Competing in the serverless inference endpoint business does provide two key benefits: it creates a sales funnel to cross-sell GPU clusters to inference customers, and it allows Together to absorb the cost of idle cluster compute by running inference workloads on it. It also give Together an opportunity to enjoy the fruits of their kernel team’s labour. TKC is an exceptional feature, and the impact of Tri Dao’s FlashAttention cannot be overstated. During the research for this article, we got to hear directly from Dan Fu about the TKC roadmap. We suspect that Dan is the only person in the industry with the title of “VP, Kernels”, and for good reason. TKC is consistently impressive, and it helps both customers and Together’s serverless inference endpoint business achieve improved performance and efficiency. Together’s model of offsetting costs from idle compute by running public and private serverless endpoints is now being copied by the likes of Nebius. Why not make some extra money from idle compute?
During testing, we got access to a classic Together slurm cluster, a TKE kubernetes cluster, and a soon-to-be-released Instant Cluster in preview. For slurm, the onboarding process was smooth. Just create an account on the console, upload ssh keys, and the together engineering team sends you an onboarding document. One ssh command and the cluster works out of the box. Unfortunately, during testing we noticed that the cluster responded very slowly to terminal commands in a VSCode or cursor remote SSH session. The standard terminal application was fine, and we could replicate the slowness from multiple locations, leading us to believe it was a problem with their datacenter provider
The Kubernetes onboarding experience was less polished. Instead of providing a kubeconfig file to download, we were expected to login and access the cluster via ssh. As mentioned previously, this is atypical for kubernetes admins and users who generally prefer to develop code locally and switch contexts on demand. In addition, we found that standard tools like Helm were not installed, and users do not get sudo permissions by default, requiring more manual setup. Together uses rancher k3s to provide these clusters, which is strange considering how much of the serverless endpoint runs on kubernetes. Together has several customers, including Hedra, Cartesia, and Krea, that are successfully running production inference on thousands of GPUs using these managed K8s clusters. However, at this time, together does not have horizontal node autoscaling capabilities in these clusters. Whatever capacity you commit to is what you get. It is interesting to see the dynamic between the cluster business and the endpoint business in action: users can see it as together competing against itself, or providing end users with choice.

“Instant Clusters” is Together’s newest offering, designed to be fully managed via API, CLI, and a Terraform provider. This product allows users to dynamically provision clusters and add or remove nodes on demand, making it suitable for handling burst capacity and autoscaling. The architecture for Instant Clusters provides strong tenant isolation using a multi-layered approach similar to Nebius. First, a base Kubernetes cluster uses KubeVirt to create dedicated Virtual Machines (VMs) for a customer. Second, these VMs are used to form an isolated Kubernetes cluster dedicated to that customer. Third, slurm is then installed into the customer’s dedicated K8s cluster using slurm-operator from Slinky. Overall, this architecture allows Together to offer flexible, on-demand Slurm environments on top of a modern, virtualized stack. Notably, in our testing, Together is the only provider to correctly configure Slinky out-of-the-box with sudo permissions, vim/nano, git, python, and other basic packages pre-installed. They clearly have already rolled out this offering to users, and we are excited for it to launch in full GA.
On these clusters, Together provides 24/7 support from an on-call SRE team that is primarily US-based. For networking, they work directly with customers to configure firewall rules at the datacenter level and provide IP addresses as needed, including 1:1 NAT and public IPs assignable through services like MetalLB.
The final, and most important piece of differentiation from Together and gold tier providers is a proactive and automated approach to monitoring and reliability. This has been a weak point for Together, and is difficult for them to work around given the broad use of datacenter and GPU infrastructure partners they have contracts with.
During our review of the monitoring dashboard, we noted a bug in their Grafana monitoring dashboard that incorrectly reported InfiniBand bandwidth at a physically impossible 1.14 Tbit/s. To their credit, when we pointed this out, their team quickly identified the calculation error in their query and deployed a fix.
For passive health checks, we expect checks run continuously in the background to detect failures on live nodes. This is where the gap between their current implementation and a fully automated system is most clear. Together has implemented detection for many critical issues, including GPUs falling off the bus, PCIe errors, InfiniBand link flaps, high GPU thermals, and high ECC memory error rates. A baseline Kubernetes node health check is also in place. However, the most critical missing piece is automated remediation. While they can detect most of the issues above, the logic to automatically drain a faulty node is still on the roadmap for everything except for GPUs falling off the bus in slurm. Other crucial features on the roadmap include detecting uncorrectable Nvidia XID errors, identifying stalled NCCL jobs, and implementing AI/ML-based predictive failure analysis.
For active health checks, Together has currently implemented a comprehensive suite of tests for single-node validation. It includes Nvidia’s DCGM diagnostics (level 3), PCIe bandwidth tests, single-node NCCL and InfiniBand all-reduce tests to validate local interconnects, and GPU stress tests like GPUBurn. However, key multi-node and application-level tests are still on the roadmap. This includes pairwise ib_write tests to validate the InfiniBand fabric under load, hardware correctness validation with Nvidia’s TinyMeg2, and full-stack performance tests with models like Megatron to ensure TFLOPs and loss convergence match reference numbers. We have previously noted how important these tests are during burn-in and during cluster operation, as they stress both the GPUs and the interconnect at the same time, for an extended period of time, resulting in thermal expansion and contraction of the entire cluster, similar to normal operation. We encourage Together to prioritize implementing these active health checks, as we believe it will help them improve reliability, especially when working with datacenter partners that are not under their direct control.
In summary, Together continues to operate on a solid foundation for managed clusters. They have a large and growing customer base for both their clusters, and serverless inference endpoint products. Their active, single-node health checks are strong. However, the system is not yet complete. We believe that the gap between detecting node failures passively, instead of automatically remediating them proactively is a key reason for the reliability issues users experience today.
Lambda
Lambda is another gold-tier candidate that unfortunately comes in at #1 in the wrong category: customer complaints. Lambda started out in 2012 by building facial recognition software, then pivoted to reselling SuperMicro GPU workstations, servers, and eventually on-premises clusters. Today, they appear to be 100% focused on their “Superintelligence Cloud” and working to shed their legacy on-prem server and workstation business. Their recent announcement with Microsoft suggests they will be providing capacity worth multi-billions across 10s of thousands of Nvidia GPUs.
A recurring theme when we talk to users is that Lambda seems to unfortunately be trying to do everything for everyone. While the company has deep experience in building dedicated HPC clusters, this has not yet translated into a polished, user-friendly cloud console, or cluster monitoring experience. Their product offerings feel conflicted with a new-mslurm, old-mslurm, new-mk8s, old-mk8s, private cloud, 1-Click Cluster, and on-demand Instances.
Notably, 1-Click Clusters aren’t really one click, as you need to wait for approval. It’s more of a 1-Click-if-approved-and-paid-for-then-you-can-have-it-Cluster.

For users that want an on-demand machines instantly, Lambda is generally considered to be the top-tier on-demand provider, with the largest fleet of GPUs available. However, in our recent experience, Lambda is in fact suffering from success in on-demand. We are generally met with greyed-out screens showing that capacity is sold-out:

Also, for a hot minute, Lambda appeared to be getting into the serverless inference API endpoint business, which would put them in direct competition with some of their largest customers. But that is no longer:

Overall, we like the focus. Lambda has pivoted, and is very focused on their 1-Click-Cluster (1CC) business, focusing on “big game hunting”.
During our testing, we evaluated both their new (self-managed) and old (rancher-based) Kubernetes offerings, and their newly available slurm offering. Neither of these is UI or CLI driven, instead requiring a Lambda engineer to set up the cluster for you.
Lambda’s Kubernetes product feels like an early-stage offering, marked by technical debt and a challenging user experience. While the current product does not use Rancher, the public documentation still references it, causing initial confusion. The user experience for inference workloads is particularly lacking. Clusters do not come with a default public IP solution (like MetalLB or an external LoadBalancer). Setting up public-facing inference services is complex and not well-documented, requiring significant manual configuration. This reflects a platform that is developed to target training workloads, not inference. While documentation exists for a simple, single-GPU vLLM deployment, there are no examples for multi-GPU, multi-node, or auto-scaling inference workloads.
For monitoring, Lambda uses a mix of open-source tools, including LeptonAI’s gpud for GPU device management and node-problem-detector for health checks, but the integration is not seamless into their monitoring dashboards for the new or old mk8s products. Dashboards are easy to access, but missing integration to the metrics without an install of an agent that is not documented, and upon further inspection, still in development.
For slurm, Lambda’s offering is a more recent addition, and the onboarding process was fraught with issues. The initial setup process was cumbersome: ssh keys were not correctly provisioned on the cluster, the default home directory was not shared across nodes by default, requiring data to be moved manually. New user account creation is a headache, requiring workarounds like unsetting environment variables (XDG_DATA_HOME) to function correctly.
To their credit, once these initial hurdles were overcome, the cluster’s performance was strong. We observed expected allreduce, allgather and alltoall bandwidth on nccl-tests and were able to achieve full MFU on an example torchtitan training workloads. Lambda also provides some useful, albeit hard to find, tooling. For example, a welcome message (which was invisible in some SSH clients like Cursor or VSCode) contained custom instructions for a grafana-access command to quickly view performance metrics.
Lambda’s approach to reliability on the slurm cluster included a custom dcgm-status script, which can be run on-demand:
The script is also scheduled to run on a regular cadence in a low-priority, “preemptible” partition:


We were impressed by Lambda’s commitment to developing comprehensive active and passive health checks, and believe that they are well on their way to improving reliability challenges, and building the battle scars necessary to run NVL72 rack-scale systems at scale.
With that said, some of the access issues we encountered point to broader operational challenges at Lambda. Their cloud console (though not our cluster) experienced outages during our brief testing window.


Internally, there appears to be a general degree of disorganization. When asked about a true “cloud console” experience, Lambda acknowledged that the team’s background is primarily in traditional HPC cluster deployment, not building scalable, self-service cloud infrastructure. We encourage Lambda to truly focus on the cloud experience going forward as they simplify their portfolio and focus on their mslurm and mk8s offerings.
On the positive side, Lambda is actively working on improving its platform based on our feedback. They have a compliance team addressing SOC 2 Type II requirements for individual sites, and are working to implement both SHARP and InfiniBand security keys for multi-tenant isolation, following recent Nvidia recommendations (and, likely, the onboarding of Nvidia as a customer with a $1.5B contract). Their storage offerings primarily focus on VAST, with future S3-compatible offerings currently in development.
Overall, Lambda is a strong provider with deep hardware expertise, massive capacity, and big plans for the future. However, their public cloud product feels immature, and engaging with the team feels chaotic. We encourage Lambda to continue to work on translating their HPC hardware prowess into a stable, easy-to-use, and reliable cloud service.
Google Cloud (GCP)
You would think Google would set the standard. From jax to the transformer, search to maps, Waymo to YouTube. We use Gmail with Gcal to book a Gmeet to get our work done. We have to pull CoreWeave containers from gcr to run on their kubernetes cluster. Rumors abound about the TPU.
Since the first version of this article, Google has addressed some issues holding them back, specifically making the decision to go with standard CX-7 NICs for their H200 (a3-mega) and B200 (a3-ultra) instances, as well as their GB200 NVL72 instances (a4).
Our testing began by provisioning clusters for both slurm and Kubernetes (GKE). The managed slurm “Cluster Director” offering is still in preview, though at Google “preview” also means that key customers have had it for several months, and things work well. The architecture follows a standard managed service model where the slurmctld is handled by GCP, leaving users with access to the login and worker nodes. We appreciated the default setup, including scripts for testing network performance via nccl-test and storage performance via FIO pre-staged in a GCS bucket for immediate use. For storage, GCP recommends Filestore for home directories, which provides enterprise features like snapshots and backups, while managed Lustre is positioned for large-scale, high-performance scratch space. Provisioning our Lustre filesystem was straightforward but not instant, taking roughly 40 minutes to complete.
Interestingly, the cluster also demonstrated self-healing capabilities; when we intentionally deleted a worker node to clean things up and move from slurm to GKE testing, the Cluster Director service automatically recreated it in a matter of minutes to maintain the desired capacity. We had to delete the whole cluster from the cluster director screen to get it to take. Interesting demo.

However, the GKE-based solution is where GCP truly shines and feels years ahead of all Neocloud competition but CoreWeave. Using the “Cluster Toolkit,” the initial setup was streamlined. Most impressively, the cluster arrived with Kueue and JobSet pre-installed. This immediate, out-of-the-box support for modern, Kubernetes-native scheduling for batch workloads is a significant differentiator. While competitors are still building their own operators or relying on Slurm-on-Kubernetes projects, GCP provides a mature, fully integrated solution.
Out-of-the-box performance was decent. Running nccl-tests with a standard JobSet YAML, we immediately achieved the expected bandwidth for allgather, allreduce, and alltoall operations without any tuning. However, it is worth noting that our experience is not representative of what others are seeing at scale.
Currently with gcp gIB machines which use Nvidia CX-7 NICs (such as the a3-ultra H200, a4 B200, and a4x GB200), to get good performance, users must use the gIB plugin. This means that users need to add additional container mounts and lines into an sbatch script or jobset manifest, such as --container-mounts=”/usr/local/gib”, export NCCL_NET=gIB, source /usr/local/gib/scripts/set_nccl_env.sh, etc. This is a poor UX, leading to even advanced users seeing poor performance when compared directly to other providers. You effectively need to have a GCP engineer to get the expected performance at scale, and it is still an open question for us whether alltoall collectives work as expected on this scale-out network.
Our suggestion to Google to improve this UX is to have Nvidia bake the gIB plugin binaries directly into all NGC container images, and include logic during container init to automatically select the gIB plugin when on compatible GCP machines. This would remove the need for users to manually mount it into their containers. There is a way to detect if running on a GCP machine with gIB, either through vendor and device IDs, or by checking /sys/bus/pci/devices/*. Google and Nvidia have said that they have started to look into this and have plans on how to improve it.
On a more advanced networking front, GCP provides a crucial capability for large-scale training: NCCL straggler detection, powered by their CoMMA (Collective Monitoring and Management Agent). In distributed jobs with hundreds or thousands of GPUs, a single underperforming node or “straggler” can bottleneck the entire collective. Diagnosing where the straggler is presents a significant challenge. CoMMA attempts to addresses this by using a sophisticated eBPF-based agent that non-intrusively traces NCCL operations. By monitoring the progress of collectives like AllReduce, AllGather and AlltoAll, it claims it can identify the specific ranks that are lagging. When a straggler is detected, CoMMA emits a detailed JSON payload to Cloud Logging, identifying not only the slow ranks but also the ranks that are proceeding normally. Customer feedback about CoMMA have been mixed.
Storage performance was robust and capacity was flexible. GCP’s tooling automatically prepared an FIO benchmark job, which we ran to test I/O patterns for scratch writes, training data reads, and checkpointing, all of which delivered solid results for both the home directory and lustre mounts. Google also has a marketplace that includes solutions like Weka, in case customers have preferences to deploy. Of course, GCS is available on-demand too, where many enterprises already have their data stored for long-term retention.
Of course, no cloud experience is without its complexities. The primary hurdle we encountered was a classic cloud IAM footgun. When attempting to run a torchtitan training job, our pods were denied access to the dataset in a GCS bucket. This required diagnosing the node pool’s service account and running a series of gcloud and gsutil commands to grant the necessary permissions. While this is a common workflow for experienced GCP users, it’s a trade-off that working with a hyperscaler presents.
GCP’s focus on production AI workloads is evident the GKE Inference Gateway now being GA. Our evaluation of the GKE Inference Gateway focused on two features: prefill-decode (PD) disaggregation and prefix-aware routing. We found that PD disaggregation, advertised with a potential 60% throughput improvement, is not integrated into the standard GKE Quickstart profiles or documentation. It currently exists as an “advanced optimization” that is a “constant work in progress.”
In contrast, GKE’s implementation of prefix-aware routing is mature and well-documented. Unlike common patterns that require a user-managed proxy to route requests to inference engines like vLLM or SGLang for KV cache reuse, GKE integrates this routing logic directly into its managed L7 load balancer. This design eliminates a user-managed component from the serving stack, reducing operational complexity. GKE provides a robust inference networking layer, but there is a clear distinction between its stable, integrated features like managed routing and its not-quite-documented capabilities like PD disaggregation with llm-d.
For monitoring, google integrates DCGM metrics right into the main cluster dashboard. This is a great UX when compared to a separate grafana instance, with things like authN and authZ being wired up automatically to the same intuitive console where the cluster was deployed. This also allows for some customization We suggested adding a TFLOP estimator via DCGM_FI_PROF_PIPE_TENSOR_ACTIVE * peak_fp8_flops. For example, for H200, it would be 1979 TFLOPS.

On health checks, Google’s slurm offering is missing a background health check program. Currently, they rely on a prolog health check that runs some dcgm tests but haven’t yet integrated it as a NodeHealthCheck program in slurm for monitoring purposes during a batch job. By contrast, GKE has an option for users to configure AutoRepair, and an API for “repair and replace” functions where users can request a replace. This is a strong reactive offering, but requires manual setup from the customer’s cluster admin, and does not get to the level of proactivity that Gold and Platinum tier Neoclouds exhibit with their health checks. We encourage Google to follow some of their competitors, and treat failures with the perspective that if a customer discovers it first, something is wrong.
The experience we have had working with Google’s engineering team is exceptional, but it comes at a steep price. Access to premium support generally requires a multi-million dollar compute contract and a 3% premium (on purchases that is a minimum of $1M), creating a high barrier to entry and a clear distinction when compared directly to Neoclouds.
Going forward, we have concerns about NVL72 rack-scale architectures in Google datacenters. Google and AWS have both gone with NVL36x2 instead of a true NVL72 rack due to power, cooling, networking, and reliability concerns. The result is supposed to be a similar of NVL72 with the same scale-up domain of 72 GPUs as a standard NVL72 rack, but due to the cross-rack NVLink ACC cables it is a different topology.


but in practice users of GCP or AWS NVL36x2 have been waiting weeks or months longer to get stable firmware, and get the rack to a point of stability where they can run basic collectives.

In conclusion, Google aims to set the bar and command a pricing premium, but wrinkles like the gIB workflow, the lack of a GA managed slurm service, and reported issues with NVL72 rack-scale stability, as well as unclear SLAs + SLOs make the current pricing difficult to justify, especially for the legacy H100 instances that are still so popular amongst users. However, as the industry moves beyond H100s, Google’s roadmap is clearly strong. Once they roll out their B200 and GB200 instances at scale and push some roadmap items to GA, they will be in a powerful position to justify that premium. Google is on the fast track to the Gold-tier or higher.
Amazon Web Services (AWS)
Our experience with the world’s biggest cloud has been full of headache. AWS offers SageMaker Hyperpod Slurm and SageMaker Hyperpod EKS (kubernetes). We started with slurm. Interestingly, AWS and OpenAI signed a multi-year deal for OpenAI to run core AI workloads on AWS EC2 UltraServers with NVIDIA GB200/GB300 worth $38B over 7 years, yet with no mention of EFA or HyperPod/Slurm in the announcement.
Our initial setup process following the primary documentation path for creating a slurm cluster through the SageMaker console. This path proved to be a dead end. The only successful method for provisioning a functional cluster was to abandon the standard documentation and instead use a CloudFormation stack from an official AWS workshop at http://catalog.workshops.aws/sagemaker-hyperpod . This approach pre-provisions the entire required infrastructure stack, including the VPC, IAM roles, S3 bucket, and FSx for Lustre file system, before attempting to create the cluster itself. Effectively, the default console setup does not correctly configure the necessary dependencies.
With that said, the process to get the CloudFormation scripts to work correctly requires navigating multiple documents to correct IAM policies (AmazonSageMakerClusterInstanceRolePolicy), request quotas of all sorts, and upload/run lifecycle scripts.Notably, these scripts are buried five directories deep in an unrelated GitHub repository: https://github.com/aws-samples/awsome-distributed-training/blob/main/1.architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/lifecycle_script.py and are incredibly brittle.


The scripts have to be manually downloaded from the git repo, uploaded to an S3 bucket, and then added at the fourth step of configuring a cluster. When creating a VPC, IAM roles, S3 Bucket, and Lustre FSx, if you miss a step or need to upload a script to a different path, you have to restart the provisioning process.
On our first try, we didn’t define enough controller nodes to handle our 4-node ml.p5en.48xlarge (H200) cluster. On our second try, 1 of the 4 nodes in the cluster didn’t mount the Lustre FSx properly, due to a race condition, and the whole cluster rolled back. On the third try, the size of the instance being requested for the controller node had been exhausted in the region/az, so we needed to rollback and try again. Finally, on the fourth try, with a specific controller VM size (c5.xlarge instead of m5.4xlarge), and adding exactly one node at a time, we were able to provision the cluster properly. The provisioning process for a single cluster can take about two hours, as each node can take upwards of 30 minutes to deploy (if capacity is available).
In total, we worked on provisioning this cluster for 14 straight hours, with intermittent calls from five different AWS engineers across various time zones. Notably, the race condition on Lustre FSx that requires adding one node at a time has been known about by AWS engineers for over a year and not fixed. We spoke to three separate AWS customers during our research that validated they have experienced the exact same issues when setting up a hyperpod slurm cluster.
In addition, the standard, documented path for getting started with a single GPU instance does not actually produce a working GPU instance. Following the console guide results in a GPU instance provisioned without any Nvidia drivers installed, and a default root volume size of 8GB, which is insufficient to even install the required drivers manually. We believe this is a primary reason why various marketplaces reselling GPU compute in AWS datacenters such as lightning.ai and Qubrid have able to maintain a business: the AWS UI is just so hard to use.
On the HyperPod cluster, AWS (like other hyperscalers) removes public IPs in favor of a proprietary SSH wrapper script easy_ssh.sh https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-hyperpod-run-jobs-slurm-access-nodes.html. Unfortunately, this easy_ssh.sh is not easy, instead requiring an Access Token to be retrieved from the AWS console as they are cycled every 24 hours by default, and use the AWS SSM approach for access. This wastes time and is annoying, let alone the process to manage users with add_users.sh or plugging the cluster into an IAM provider.
Uniquely, AWS is the only cloud where account managers pestered one of our team members relentlessly for payment on a capacity block that they had provided us directly for our testing. While this did get rectified, the experience speaks to the fact that the AWS organization is a behemoth, and customers need to push hard to get the left hand to speak to the right.
Beyond our direct testing, independent feedback from multiple AWS users deploying hundreds of GPUs highlight additional issues: the need for a /16 CIDR to avoid IPv4 exhaustion (since 81 IPs are consumed per GPU instance), and a lack of IPv6 support on EKS. Regular footguns also show that HyperPod does not use existing reservations automatically, another source of potential cluster recreation, and a different (but similarly frustrating) need to add nodes incrementally, in this case to avoid EFA errors.
On health checks, AWS does have a relatively comprehensive approach to health checks compared to other hyperscalers. However, deep health checks can be excessively long (60-120 minutes) and are best disabled for faster scaling. Unfortunately, monitoring dashboards for slurm or Kubernetes cluster health, performance, and job stats are basically non-existent beyond standard, manual, open source tooling.

Finally, on networking, not much has changed since our previous article. AWS remains steadfast in its commitment to EFA for all H200, B200, B300, GB200 NVL72, GB300 NVL72, and even future VR300 rack-scale architectures. Customers that see superior performance from InfiniBand and high-end RoCEv2 deployments generally dislike EFA performance and debugging. However, AWS is steadfast in their commitment to EFA, going so far as to design future architectures where they will run PCIe connections between their compute trays and a separate “JBOK” (Just a Bunch of NICs) rack full of custom K2V6 EFA NICs.
On GB200, their p6e platform uses NVL36x2 and runs into the same NVLink unreliability troubles as GCP where the cross rack NVLink ACC cable causing major issues.

AWS markets this disaggregated design as a strategic choice for resiliency, claiming it enables N+1 NIC redundancy and improves the mean time before failure (MTBF) of sensitive optics by moving them to a cooler, dedicated tray. However, the engineering reality suggests this move is less a choice and more a necessity driven by the thermal and spatial constraints of fitting multiple power-hungry K2V6 NICs inside a dense 1U compute sled. This architecture introduces non-trivial latency from PCIe Active Electrical Cable (AEC) retimers and feels like a complex workaround to us.
However, this JBOK design also enables a long-overdue shift to a rail-optimized network topology, which is critical for the performance of MoE models heavy on All-to-All collectives. But this obsession with reliability at the component level leads to a shockingly inefficient operational model at the system level. An entire GB200 rack (or logical rack, as AWS is going for NVL36x2, just like Google) is treated as a single failure domain called an “Ultraserver.” This means a single faulty compute sled requires draining workloads from all 18 nodes in the rack before any repair can be attempted. This is a stark contrast to the hot-swappable serviceability customers expect and receive from other GB200 NVL72 rack-scale providers. In the worst case, this policy has brutal TCO implications as it demands entire “spare” racks to maintain capacity SLAs, a cost inevitably passed on to the customer via poor SLA penalties, or higher prices.
For users of EFA, debugging is also incredibly challenging. First, in a traditional HPC environment using InfiniBand or RoCEv2 (Converged Ethernet), engineers have a standard toolkit: ib_write_bw, ib_ping, ibv_devinfo, and ibdiagnet for direct testing of the physical layer. However with EFA, your access ends at the EFA driver on the host. Second, since NCCL does not communicate with EFA directly there are multiple layers of abstraction to contend with. The communication path is a complex chain of software shims:
NCCL → aws-ofi-nccl Plugin → Libfabric API → EFA Libfabric Provider → Custom ibverbs provider in RDMA Core Library → EFA Kernel Driver → AWS Hardware
When a NCCL collective (like an AllReduce) hangs or performs poorly, the error message is often generic, like a timeout or a provider error. Pinpointing the source of the problem is a nightmare: is it a bug in NCCL itself? Is it an incompatibility or bug in the aws-ofi-nccl plugin? Is Libfabric misconfigured or hitting a corner case? Is the EFA provider encountering an issue with the SRD protocol (e.g., congestion, retransmissions)? Is there a physical hardware problem on the NICs, switches or cables? Without deep introspection tools for each of these layers, debugging becomes a process of managing support tickets with AWS.
Third, is the case of “gray failures”, where job performance degrades for inexplicable reasons. Is it congestion from other jobs on our cluster? Sub-optimal routing policies? A noisy neighbor tenant on the same global fabric? Multi-tenancy is always difficult to handle in networking, and a backend interconnect for GPU clusters is no different.
Finally, the same usability issues with cluster setup can impact networking experience too. Security Groups, IAM Permissions, and Cluster Placement Groups all need to be handled correctly to ensure a given user is getting proper performance. Many small things added together results in a big challenge for administrators.
In general, we try to represent the customer experience, which repeatedly tells us that EFA does not perform well at scale. But AWS doesn’t care, they are not cow-towing to Nvidia and adopting CX-7 or CX-8 NICs. They have already sunk enough time and energy into this EFA NIC, and they’re going to make it work and save that 0.8% of TCO, dammit.
Overall, Amazon SageMaker HyperPod is surprisingly difficult to use, especially considering that AWS is the leader in the cloud industry and brands itself on customer obsession. Official AWS documentation is hard to follow or incorrect, and the underlying platform suffers from issues of usability and performance at scale. For teams considering HyperPod, we recommend budgeting for significant engineering effort focused on cluster maintenance, including time to build custom automation that can work around AWS’s unique limitations.
Scaleway
Scaleway continues to carve out a niche as a premium, sovereign European cloud provider with a focus on large-scale, AI training particularly for startups and non-profits.
The company’s primary offering for high-end AI is centered entirely on slurm for training. Inference, and Kubernetes in general is not a significant part of their go-forward strategy. A significant recent improvement is the deployment of a “copilot” Grafana instance, which includes essential DCGM and slurm exporters. This directly addresses a criticism we made in the first version of this article, regarding a lack of monitoring in their offering. Furthermore, Scaleway has enhanced reliability by implementing health checks through slurm prolog and epilog scripts, with monitoring data being actively managed to ensure cluster stability.

On the networking front, Scaleway continues to mainly offer H100 nodes with Nvidia’s Spectrum-X networking. They generally provide customers an opportunity to reserve clusters for days or weeks to compare its performance against traditional InfiniBand, and have seen good results. Interestingly, during testing, Scaleway worked with a customer to develop a synthetic benchmark better than nccl-tests, which indicated a 20% performance improvement over InfiniBand. However, in a crucial real-world test case, that performance advantage was not realized.
Looking ahead, Scaleway is still in the planning phase for Blackwell, and is targeting HGX B200/B300 baseboards only, rather than the fully integrated GB200 NVL systems. The company is also exploring AMD GPUs, but have yet to see significant customer traction in Europe.
Overall, Scaleway’s business model has begun to reflect a “European premium” for sovereign, GDPR-compliant infrastructure. This is evident in their resource allocation, which requires customers to contract for an entire cluster for large-scale jobs, rather than allowing on-demand access to single 8-way GPU machines. This model targets well-funded, serious AI projects, including an ecosystem built around the Scaleway Startup Program. This program offers credits and support, aiming to onboard the next generation of European tech companies.
We expect Scaleway to continue to operate in a solid niche, prioritizing dedicated, high-performance clusters for, the European market with an associated premium.
Cirrascale
Cirrascale occupies a unique, and somewhat confusing, position in the market, landing them in our Silver tier. The company operates on a build-to-order basis for its cloud services, a model that feels more like a high-touch colocation or system integration service than a conventional cloud offering. Their offerings include rent-to-own plans and a service where they help customers procure servers (e.g., from Supermicro), which the customer then owns, while Cirrascale provides hosting, setup, and RMA coordination for a fee. This is a fundamentally different approach from most other providers, possibly comparable to Lambda’s Private Cloud business, some of Fluidstack’s agreements, and STN’s managed services.
Our interactions with the Cirrascale team have been challenging. The Cirrascale team feels that our criteria, particularly around software orchestration like Kubernetes, are not relevant to their customers. Their philosophy is to avoid any responsibility at the platform layer, meaning they provide bare-metal access and expect customers to bring and manage their own software stacks. In conversations with customers that use Cirrascale, however, we have heard that they don’t actually like this approach. Integration of a simple DCGM background health check into a Slurm environment that plugs into datacenter operations systems would allow for quicker diagnosis of problems, and more goodput during training runs. It may also save Cirrascale time and money when performing RMAs.
While Cirrascale has thousands of GPUs deployed and a large backlog of customers for new B200 and AMD MI355X systems, their market position has also seen significant shifts. Notably, OpenAI, which once hosted all its owned servers with Cirrascale, migrated its entire infrastructure to Microsoft Azure. This move by a flagship AI lab away from the customer-owned/managed-hosting model to a hyperscaler is a telling indicator of the industry’s direction.
In summary, Cirrascale serves a specific niche: organizations that want to own their hardware assets but outsource the complexities of datacenter operations. However, their hands-off approach to the software stack make it difficult to recommend them for teams that expect a reliable, hands-off cluster. This model places a heavy operational burden on the customer, solidifying Cirrascale’s position in the Silver tier.
GCORE
GCORE is a Luxembourg-based provider that was founded in 2014, originally focusing on gaming, CDN, and general purpose cloud. But now, AI. GCORE offers GPUs across Europe, including datacenters in Luxembourg, Portugal, Germany, the Netherlands, the UK, and the US (Virginia and California). They also have plans to go into the Nordics, partially via self-build, but also via an established partnership with Northern Data Group (also known as Taiga Cloud). It’s unclear where this partnership will go, as Northern Data apparently just had their offices raided over tax fraud allegations related to crypto mining operations in 2023.
The GCORE platform is feature rich, with a nice balance of usability and strong underlying hardware performance. Unfortunately, only Kubernetes was available to test for us. We learned after the fact that their Slurm-on-Kubernetes offering, based on SOperator, is buried in API documentation. We look forward to testing this in the future.

The onboarding process began with a series of manual hurdles where we quickly realized we were dealing with an enterprise-ready console modeled after the hyperscalers. After creating an account, we were required to request a quota increase to spin up a cluster. Interestingly, while at the hyperscalers we can approve these quote increases ourselves, with GCORE there was a nameless faceless support team member making the decision for us. This actually resulted in us needing to make three separate attempts (over the course of two working days) to get quota approved for 2TiB of VAST Storage to go with our 2-node kubernetes cluster.

Forging ahead, we followed the required steps: creating a three virtual networks, a VPC, provisioning our Kubernetes cluster, which promptly became stuck in a “provisioning” state for over two hours before ultimately failing. Notably, GCORE takes networking seriously: routers, configurable networks, floating IPs, firewalls, and reserved IPs. It can just make things confusing on setup for non-cloud native users.

Our second attempt was more successful, at least on the surface. The cluster spun-up correctly, including a default ReadWriteMany StorageClass using the VAST quota we fought so hard for. Unfortunately, the cluster was delivered without the Nvidia GPU Operator or the Network Operator. This is a critical point for many general-purpose clouds that have kubernetes experience but miss some of the basics when they turn to serving the AI market. Some opinions (like having the GPU and Network Operator pre-installed) are worth enforcing in customer clusters.
After confirming that performance on nccl-tests, a torchtitan pretraining job, and disaggregated prefill/decode inference endpoints via llm-d was working as expected we turned to focus on monitoring. Unfortunately, this seems to be left completely up to the user. While gold and platinum tier providers handle the CNI, CSI, active/passive health checks (e.g. via node-problem-detector or custom controllers and CRDs), kube-prometheus-stack (i.e. on a Grafana dashboard), and Slurm-on-Kubernetes, GCORE leaves that all that stuff up to the user.
Overall, GCORE’s platform is strong, and one of the best purely self-service offerings we tried for kubernetes. The console includes all the enterprise goodies one would expect, and it makes sense why this enable them to sell into large enterprise with PCI DSS compliance and a global datacenter footprint. We encourage GCORE to develop an advanced cluster monitoring dashboard, implement active/passive health checks on the kubernetes layer, and consider developing a first-class Slurm-on-Kubernetes experience over time.
Firmus / Sustainable Metal Cloud (SMC)
Firmus is an Australian company that was recently backed by a strategic investment from Nvidia at a $1.9B valuation: https://www.afr.com/technology/nvidia-backs-australian-ai-factory-firmus-with-1-9b-valuation-20250915-p5mv0v. Their current ambition is to build a “Stargate for the southern hemisphere,” with a specific focus on next-generation rack-scale systems like the GB300 NVL72 and VR. Though we believe that the bulk of Firmus’s experience with immersion cooling is misguided, and now wasted, we also believe that this team is one of the few in the industry that has the engineering chops to monitor and maintain the physical layer of these DLC systems effectively. Our review of their current telemetry and failure prediction system for their immersion deployments demonstrates significant attention to detail, and a deep understanding of the physical stack, down to the signal quality and light levels in custom transceivers and optical cables. However, this experience at the lowest physical level can be undermined by a higher UX level that feels out-of-touch with customer requirements.
Our testing began with a difficult wrinkle: cluster access is gated behind a mandatory VPN. This is a significant operational bottleneck for teams accustomed to standard cloud workflows with public IPs or streamlined SSH wrappers. While some security-conscious customers (such as international federal agencies for defense, intelligence, and research) may find this acceptable and even prefer isolation at Layer 2,3, 5 or 7, the general public does not operate this way. The fact that Firmus had no alternative access method prepared was telling for us.
Once connected, our slurm environment also had some configuration issues. The standard topology.conf file was not set for topology-aware scheduling, and a simple “srun -N1 –gpus-per-node=8 –pty bash” command took over a minute to execute due to an exceptionally long prolog. It seems that the Firmus team took some of our previous feedback around health checks to an extreme, filling up the prolog with unnecessary dcgm level 3 checks when level 1, 2, or just an epilog with HealthCheckProgram configured would suffice. To their credit, a pre-staged nccl-test script was provided and ran at expected bandwidth.
As mentioned previously, the Firmus monitoring stack is unique, going beyond standard DCGM metrics and feeding ML models to predict component failures before they occur. A “link flap” is formally defined as five events in one hour, triggering automated diagnostics. Their internal validation suite is exhaustive, running regression tests on spare nodes that include P2P bandwidth tests, GDR copies, small-scale llama training runs, and NCCL tests to proactively identify GPUs, NVLink, or InfiniBand interconnects that are approaching failure.


This level of investment in monitoring at the physical layer is how Firmus plans to back up an aggressive “99.94% SLA”, aiming to differentiate itself from competitors by ensuring maximum goodput – something that we have also heard from top-tier providers like CoreWeave and Nebius. Their business model mirrors other major Nvidia clouds, with attractive prospective pricing for their upcoming rack-scale deployments, much of which is made possible by a low power cost in their massive expansion into Tasmania. We encourage Firmus to double-down on their focus on operational excellence from the physical layer to the orchestration layer (i.e. properly configured slurm and kubernetes clusters) without getting distracted by fancy PaaS and SaaS applications that the vendor-du-jour is pitching.
GMO Cloud
GMO Cloud, part of the sprawling Japanese conglomerate GMO Internet Group, presents a highly opinionated approach targeting their domestic market. The offering is built on a foundation of security that for us is so stringent it alters the user experience, while still providing solid performance.
We focused on slurm as kubernetes is not available, and quickly found that sinfo and scontrol are completely disabled for end-users. This decision, presumably made in the name of security, caused us issues with pre-baked scripts that depend on scontrol show hostnames $SLURM_JOB_NODELIST and other basic convenience functions. It also resulted in us having to modify some of our standard debugging practices, since users are unable to inspect the cluster state or topology. Thankfully, GMO provides a convenience command “snodes”, and a custom script, “get_master_addr.sh” which got us running jobs at expected performance.

In addition to these convenience scripts, a few other usability issues arose. GMO did not configure topology.conf, relying on a rationale that since they manually allocate customer clusters to servers that do not span across different Spectrum-X leaf switches, and organize everything by known hostnames, they are able to make topology awareness at the slurm level redundant. We think this points to a lack of experience running large customer clusters, and handling hardware failures in large multi-tenant environments.
The theme of forcing non-standard workflows due to a focus on security continued with their containerization strategy. The environment lacks support for Pyxis and Enroot, effectively blocking teams that have standardized on Docker-based containers. Users are required to rebuild their entire workflow around Singularity, a relatively significant undertaking that creates another barrier to entry for new users.
Unfortunately, this focus on security can also fall short at a basic level, creating a strange paradox. On one hand, simple command-line tools with no known exploits are locked down. On the other, we found outdated packages, such as nvidia-container-toolkit versions 1.16.2 and 1.17.4 on login and compute nodes respectively. While GMO acknowledges these are flagged by their internal vulnerability scanners and slated for an update, the presence of old software vulnerable to 9.0 Critical CVE’s running on our brand-new cluster contrasts sharply with the user-facing restrictions. Overall, GMO’s approach feels like security theater to us.
On the positive side, the base environment is well-configured for HPC tasks. The nodes come pre-installed and configured with HPC-X, NCCL, and nvcc making it dead simple to build nccl-tests from source and run it at full expected bandwidth. We were also able to run torchtitan jobs at expected MFU. In addition, the standard dcgmi health -c program is configured properly as a Slurm HealthCheckProgram, addressing our background health check expectations.
Finally, the platform lacks key observability and reliability features. There is no monitoring dashboard, though GMO states a Grafana-based solution is planned for a future release. For now, users must rely on basic Slurm email notifications for job status, and we could not identify any proactive health check system, placing the burden of failure detection largely on the user.
Overall, GMO has established a clear advantage within Japan, especially with the region’s dependence on Slurm and other traditional HPC technologies. Support is strong, and we expect that example customers like Turing: https://group.gmo/news/article/9501/ and AI Robot Association (AIRoA) https://internet.gmo/en/news/article/45/ trust the offering as GMO Cloud is a leader domestically. We recommend that GMO focus on usability over security theatre, improve monitoring options for users via custom Grafana dashboard, improve passive and active health checks, and consider developing a kubernetes offering in the future.
Vultr
To kick things off, Vultr set the record for this round of ClusterMAX by bringing 12 people onto our kickoff call. Vultr raised money last year at a $3.5B valuation, including an investment from AMD Ventures, and this past summer also got $329M of debt financing. As a result, Vultr now offers AMD MI355X GPUs (backstopped by AMD) and an expanding fleet of NVIDIA GPUs (including HGX B200), across some of their 32 global regions.

When we started our testing, the Vultr SLURM service seemed brand new, like a second class citizen in the console. This was clear when we logged in too. The cluster was missing pyxis, hpcx, topology.conf, the default login user was “root” (with no default workdir). Most importantly, there was no shared home filesystem. We recommended some basic fixes, and quickly got going with an “ubuntu” user, with a default workdir switched to a shared /mnt/vfs.


Eventually, we were able to get nccl-tests at expected bandwidth, and some basic torchtitan training runs going at expected MFU.
When we were handed our kuberenetes cluster, we unfortunately got versions of the NVIDIA GPU Operator and Network Operator that were over 1 year old, meaning they were subject to three separate “critical” level CVEs, such as NVIDIAscape from Wiz: https://www.wiz.io/blog/nvidia-ai-vulnerability-cve-2025-23266-nvidiascape. We recommended an upgrade, and the team mentioned they were “writing the jira for it”.
During testing, we had some intermittent link flaps that eventually went away on their own. Unfortunately, there was no proactive notification or remediation of this, due to a lack of a monitoring dashboard and any active or passive health checks on the cluster’s interconnect.

After eventually getting nccl-tests to run at full bandwidth on the kubernetes cluster, we engaged with the support team to troubleshoot a training job on the cluster. One of the team members, Enis, was familiar enough with KubeFlow to get it installed and configure an example torchtitan training job to work on their network. We were impressed!

After shifting to inference, we saw a strong showing from VKE. The Vultr Cloud Controller Manager runs as part of Vultr’s managed control plane (not visible in the cluster), and handles automatic provisioning of resources like a LoadBalancer public IP. Reasonable default helm charts were installed, and it was easy to configure new ones, thanks to a default ReadWriteMany StorageClass being configured.
Following our feedback, Vultr has joined the NVIDIA embargo program to ensure they are notified ahead of time for future security vulnerabilities. Vultr’s outreach to AMD’s Product Security Office seems to have motivated AMD to develop a similar security embargo program on their own.
We appreciate Vultr’s commitment to improvement and the direct engagement from their engineers. We recommend that they work on developing a monitoring dashboard, active and passive health checks, and continue building experience operating large GPU clusters.
Voltage Park
Voltage Park is a story of turnaround and redemption. If we were to have done this review in 2023 or 2024, the story would have been much different. The current Voltage Park is who we are rating, and the current Voltage Park is a reasonably less weak provider focused exclusively on H100 GPUs. As of our testing, their on-demand capacity appears to be regularly sold out. The company is shipping features at a rapid pace, including a recently launched SLURM service and OIDC integration for Kubernetes. Voltage park offers the one of the lowest price in the industry.
Our initial experience with slurm included a lot of provisioning challenges, with multiple attempts being required to spin up our test cluster. Once provisioned, we would be load balanced to different login nodes, with the now-classic SonK issue of not being able to run code. Not git, vim, nano, or sudo permissions. However, Voltage Park is the only provider with these SonK issues that seemed to be aware of them, suggesting a kubectl exec command to access the login pod, instead of the original ssh via public IP. While this container-first approach got us to workaround the initial root permission issue, it still takes time to install software, and if your connection gets reset, all software installs go away. In other words, login pods are stateless. The Voltage Park engineering team committed to building a new container image for login pods that included necessary software to run slurm jobs and edit code, and they delivered just that in under 24 hours. We were impressed by the commitment to customer support.

Inside the intended container environment, the setup is more robust. We found a correctly configured topology.conf for network-aware scheduling, SLURM prolog and epilog scripts in place, and a modern container toolkit with pyxis and enroot installed. Interconnect performance was strong, running collectives at expected bandwidth. We also saw good download speeds, and a reasonably fast shared filesystem.
Operationally, we encountered two major points of concern. First, Voltage Park’s dashboard has a “Shutdown” function that is distinct from “Terminate”. “Shutdown” halts the instances but continues to bill for the reserved capacity, a nuance that is not made sufficiently clear in the UI, and we expect is a disaster waiting to happen. Notably, not a single other provider offers these distinct “Shutdown” and “Terminate” options, and even after discussing the purpose of the “Shutdown” button with the Voltage Park team, it is still very confusing to us what the intended use case is. We recommend
Second, their process for handling hardware failures in on-demand clusters is manual, requiring operator intervention to cycle nodes out of a user’s cluster. This is a far cry from the automated, resilient systems offered by top-tier providers. This is also demonstrated by a lack of up-to-date security patches. The cluster was also pre-installed with an nvidia container toolkit version (1.17.4) that was out-of-date by 9 months, and as discussed previously in this article, victim to CVE-2025-23266 (NVIDIAScape) and CVE-2025-23267, with CVSS scores of 9.0 and 8.5 out of 10 respectively (“Critical”).
In conclusion, we believe that Voltage Park now has a solid technical foundation to carry forward and recover from reputational issues. We are encouraged by the execution of the technical team, and look forward to seeing more improvements in the future.
Tensorwave
Tensorwave is a provider that recently raised a $100M Series A from AMD Ventures. As a result, they have an exclusive focus on AMD hardware, including 8,192 MI325X GPUs in their Tucson, Arizona datacenter. Since we love all GPUs and love AMD, we have been working with Tensorwave for a long time as they graciously provide us access to GPUs for benchmarking that is well beyond the scope of ClusterMAX. We are grateful for this support.
Our testing on Tensorwave’s SonK platform has shown it to be largely unstable. The onboarding process is confusing, relying on Rancher’s RKE2 open-source kubernetes distribution (formerly RKE government), Longhorn for storage, and a modified version of Slinky for SonK (to get it to support AMD GPUs properly). To login to the cluster we initially had to escalate to sudo just to run basic kubectl commands and get a “slurm-login” convenience script working. It took a significant amount of back and forth with the Tensorwave team to get a working kubeconfig (notably, this is now easy to download from the console). We also ran into issues with permissions and user groups, which did not seem to be properly synchronized between the jump box and the Slurm login nodes. This issue has also been fixed since our testing period, but it is clear that there is limited experience getting an RBAC-scoped cluster working with an external IAM provider. In addition, the Slurm login node was missing the (now classic) tools we expect: vim, nano, git and sudo permissions to run apt install. However, in Tensorwave’s case, it only took a few hours for the team to modify the base container image to include these tools. We were impressed by this turnaround time.

In addition to access, there was no topology-aware scheduling in place, health checks were not integrated with Slurm for auto-draining nodes that fail a health check, and the monitoring dashboard was missing critical information about GPU and system health that is unique to AMD’s RDC package. While NVIDIA providers get a simpler foundation building on DCGM, Tensorwave has had to build a lot of this from scratch, since they are AMD exclusive. Most importantly, however, is reliability. During our testing, we have experienced a number of reliability issues, including some outages that stretch over multiple hours or days. In a two-month period, we have experienced 7 distinct interruptions: hardware and firmware issues on GPU nodes, a redeployment of Kubernetes, SonK/slurm-login connection issues, maintenance on Weka storage, maintenance on switches and routers, and even a power outage. Notably, none of these issues are directly related to AMD GPUs, it is the rest of the cluster and the facilities around the GPU.
To their credit, the Tensorwave team is always very responsive to our feedback and quick to address issues we raise. We have also seen a general trend of reliability improving over time. Overall, the fact that we have to provide guidance on proper Slurm setup, monitoring, and health checks points to a general lack of experience running multi-tenant clusters at the scale of 8,192 MI325X GPUs or larger. We look forward to collaborating more with Tensorwave over time as they build out more AMD GPU capacity.
Bronze
GMI
GMI is our top Bronze neocloud that is just not quite there yet. The company shows promise, with recent developments like achieving security compliance and implementing confidential computing capabilities for H100 and H200 nodes. However, in our testing the slurm cluster was frankly unusable.
We did not get access to a self-service console or monitoring dashboard of any kind, and it took over a month from our initial request, and multiple follow ups to finally login.
On the cluster, slurmctld was running directly on a compute node, and the environment was missing basic tools like docker the modules utility. More critically, the cluster was provisioned without a shared home directory across nodes despite having VAST with POSIX/NFS and S3 options in the environment. After negotiating to get a shared fs configured on the cluster, we found that the performance was terrible. Basic file-saving operations and carriage returns in the terminal would take multiple seconds to complete or respond.

One of our GMI nodes, with 1.9TB of shared storage, and 27.9TB of local storage, matching NVIDIA’s DGX specification perfectly
On the positive side, the underlying hardware appears to be configured correctly for high-performance workloads. A check for nvidia_peermem confirmed that GPUDirect RDMA is enabled, and the team confirmed that their interconnect network is built on InfiniBand with PKeys for network segmentation.
We also found no evidence of active or passive health checks, and no monitoring dashboards were provided to give visibility into cluster state or job performance.
In the future, when we can confirm that the Slurm offering is working well, development of monitoring dashboards is complete, active and passive health checks are in place, and a comprehensive Kubernetes offering is available, we expect GMI to be an obvious candidate to move into the silver tier.
STN
STN is second in our list of providers that should be in the silver tier if our testing went better. By comparison, STN is similar to Cirrascale, which is to say STN offers dedicated managed services for clusters that are built-to-order for individual customers. There is no “public” cloud experience, and frankly not much about this is “cloud”. But customers who want a high-touch experience can get it here. In our testing, the STN platform is undermined by significant configuration errors and reliability problems, landing STN in our Bronze tier.
Onboarding is entirely manual, requiring phone calls to review PDFs and set up accounts. We were given a 4-node B200 cluster with impressive hardware, including four network fabrics (RoCEv2 for interconnect and storage) and 25TB of VAST. However, this high-end hardware was let down by basic configuration mistakes. For example, we found seven local NVMe drives unmounted on each node. The Slurm environment was also missing key components for performance: no topology.conf, GPUDirect RDMA was disabled (nvidia_peermem not loaded), and MPI was not installed.
Unfortunately, STN’s biggest weakness was reliability. During testing, we saw two different nodes go into a “down” state, one of which stayed “down” for over two days. Since the STN repair process is entirely manual, it requires customers to spot and report failures themselves. Notably, dcgm health -c is enabled on the nodes, but it is not plugged into Slurm as a HealthCheckProgram.


We suggest that in the future, STN focus on actual cluster reliability instead of reporting fake “Uptime SLA” metrics to Grafana.

Finally, getting jobs to run was a struggle. It took weeks for STN engineers to modify the cluster to include hpcx, nccl, and nvcc, enable GPUDirectRDMA and turn off ACS so that we could a basic nccl-test and torchtitan training job to run on four nodes. We also ran into what looked like network traffic shaping over the WAN that slowed down our downloads, but made speedtest-cli look great.
With all this said, in our conversations with customers, STN has demonstrated that they have the capability to do deep, custom work for their customers. Going forward we suggest that STN work to automate a lot of its Slurm provisioning, health checks, and develop a comprehensive monitoring dashboard to improve reliability. Until then, we feel that STN remains a high-risk choice and a Bronze-tier provider.
Prime Intellect
Prime Intellect is our favourite non-neocloud startup that happens to be a neocloud too. Prime is most well known for their decentralized training runs (INTELLECT) and synthetic dataset generation (SYNTHETIC). They have also debuted an environments hub, quickly becoming the go-to place for researchers interested in open source RL environments. We absolutely love Prime’s open source contributions: Verifiers (a library for creating RL environments), PCCL (a library for running collectives over TCP/IP, i.e. on the WAN), and PRIME-RL (a framework for asynchronous RL at scale).
For our testing, we were provided with a 4-node SLURM cluster, a feature that was still in beta at the time. We gave initial feedback on some configuration issues: no shared home directory, no passwordless ssh, preinstalled MPI, lmod, container toolkit, pyxis or enroot. Initial attempts to launch batch jobs failed due to InvalidAccount errors, and distributed PyTorch runs via torchrun hung on hostname resolution, suggesting some networking issues. We also saw a lack of health checks or dcgmi integration, and no monitoring dashboard available.

After these findings, the prime team was all over it and completely overhauled the configuration. In less than a day, they added passwordless ssh, docker with nct, enroot, pyxis, the nvidia hpc sdk (nvcc, mpirun, hpcx), aliasing for python3, preinstalled uv, and a custom controller-hosted nfs mount for /home directories.
Prime Intellect’s responsiveness was among the biggest thing we took away from the engagement. We were able to go from sending feedback in slack to a working cluster in a matter of hours. In the future, we look forward to further validation of their slurm offering for topology-aware scheduling, automated health checks, monitoring dashboards, and large-scale I/O performance. We are aware of some large customers have have taken the plunge, running clusters at the 1k GPU scale with Prime outside of their public console and marketplace. We are also very excited for the launch of a kubernetes offering, coming soon. Overall, if the team at Prime keeps up their relentless pace of shipping new features, we expect them to quickly move higher in the ClusterMAX rankings.
Neysa
Neysa is an emerging provider operating in the Indian market. They have recently signed an MoU with NTT Data and the Telangana government to build a 400MW, 25k GPU facility in Hyderabad, and currently operate a fleet of H100, H200, and soon MI300X AMD GPUs. However, our testing revealed that their current platform has gaps in security and usability when compared to international competitors.
The onboarding process raised concerns on security for us. Access is managed via username and password-based SSH, with manual IP address filtering and a fragmented user account system. We had no way to create new users for others on the team to test, implying that it would be difficult to support RBAC with an external IAM provider.
The SLURM environment itself also suffered from basic configuration errors. Jobs fail to run initially as no default partition is configured, requiring manual specification for every submission. In addition there was no topology.conf configured. If Neya is going to run a 25k GPU cluster in the future, topology aware scheduling is going to be critical. Also, monitoring and health checks are effectively non-existent. The provided Grafana dashboard was non-functional during our testing and appeared to be missing some expected exporters for health checks or performance monitoring to work. On a more positive note, the software stack for containerized workloads is modern. We found an up-to-date NVIDIA container toolkit, and both pyxis and enroot were installed.
At the time of testing, Neysa did not have a Kubernetes offering available for us to test. We look forward to testing it in the future. We expect Neysa to benefit from compliance with Indian regulations such as the DPDP, but we find it unlikely that they are able expand beyond their domestic market at this time. We encourage Neysa to improve their default experience: a better security posture, user management, proactive support experience, default monitoring systems, and health checks.

Hyperstack/NexGen
Hyperstack has a snappy, easy-to-use web portal, where we can quickly and easily spin up and spin down GPU VMs across three regions: Norway, Canada, and the US. They also plug in to external marketplaces such as PaleBlueDot.AI, where we were able to test them again.

However, in our direct testing we also found that either their flagship Kubernetes service is broken, or we got them on a bad capacity day. After waiting for three hours, we got a vague “reconcile failed” error. The system gave us no logs or details. Luckily, our account was not charged for GPU time during this attempt (unlike some other providers on our list, more on that later).

On our second attempt, with different GPUs, more progress was made. After 4 hours stuck in the “Creating” stage, it did look like some machines were created and public IPs were allocated to the cluster.

We encourage Hyperstack to fix this core problem with their kubernetes deployment workflow so that customers can reliably use its H100 and H200 GPUs in clusters.
Atlas Cloud
Atlas Cloud presents a somewhat confusing picture. While their website points users towards a model playground and serverless endpoint environment, the core business is a typical bare metal wholesale provider. Atlas operates under the umbrella of a holding company called VCV Digital, with a sister company in Tiger DC, which is currently building a new datacenter in South Carolina. VCV Digital also owns the crypto company One Blockchain.
The company acknowledges that the focus of Atlas is in transition, having shifted focus from the US to Asia and now back again. In our testing, we were unable to spin up/down a GPU Pod for testing.

With that said, we expect Atlas to continue to operate in the baremetal wholesale market going forward. We encourage Atlas to review our criteria and inform the development of core security, user management, networking, and storage services. Eventually, we would also encourage them to consider developing advanced monitoring, health checks, orchestration software and support to expand upon the bare metal wholesale business in their TigerDC sites and beyond.
BuzzHPC
BuzzHPC is the AI division of HIVE Digital Technologies (fka HIVE Blockchain), a crypto mining focused on cool climates with green energy (Canada, Iceland, Sweden). HIVE pivoted into the AI cloud market in 2022 when they acquired a 50MW facility in New Brunswick, Canada from GPU Atlantic, aka gpu.one.

In our testing, the Slurm cluster we got had almost everything wrong with it that we’ve seen in this testing, all at once. It was almost impressive. Here is a list:
initially, no control plane machine
initially, no NFS mount, and then user’s default workdir was not on the shared filesystem
initially, no passwordless ssh between nodes
docker and the nvidia container toolkit not installed on the worker nodes
modules not installed, also no hpcx, nccl, nvcc
no pyxis or enroot
dcgmi background health checks not installed, or enabled
no prolog or epilog configured, no active health checks
no montoring dashboard
To get around all of this, we ran a 2-node nccl test with the pytorch-bundled libnccl. Unfortunately, we did not see expected bandwidth (we about 10x lower than expected). This was weird, because ibstat showed 8x 400Gb CX-7 in the nodes.
So, we quickly confirmed that both GPUDirect RDMA was not installed, and ACS was not turned off.

To their credit, the BuzzHPC team was responsive and worked with us over several days to resolve some of the issues we identified. They’ve also committed to building our feedback into their default slurm offering going forward.
However, even after these fixes, the cluster does not meet the standards we expect for usability, monitoring and health checks. It seems that BuzzHPC’s platform is still actively in development. We look forward to seeing more from BuzzHPC in the future.
Shadeform
Shadeform operates as a marketplace for GPU compute rather than a direct provider, owning no GPUs for themselves. Unlike other marketplaces, Shadeform has a lean team and only $2 million in funding, and focuses strictly on their software and brokering deals. Their platform offers a transparent view of available GPU instances, uniquely identifying the underlying provider for each machine, such as Verda (formerly Datacrunch), Lambda, Voltage Park, Hydra Host, Digital Ocean and Nebius. This transparency extends to surfacing compliance information like SOC2 Type II and HIPAA certifications.

In fact, as of our testing, Shadeform is providing access to GPUs from 23 different providers, the most we have seen on any marketplace.
Interestingly, Shadeform’s primary business has transformed, with them now entering into the wholesale bare-metal market as a broker. This means that a significant portion of their revenue comes via the negotiation and structuring of large-scale cluster deployments for their clients, particularly in the Asia-Pacific region (Taiwan, Japan, India). The Shadeform website has become a valuable discovery tool for this purpose, and is often the first place neoclouds have their GPUs appear publicly. Shadeform also appears to be the only partner currently in place for NVIDIA’s Brev offering, which we describe later in this article.
With all that said, without a comprehensive Slurm or Kubernetes offering that we can test, no monitoring dashboards, and no way to do active/passive health checks on the underlying provider’s machines, we think it will be difficult for Shadeform to move beyond the bronze category. We look forward to testing cluster products and finding ways to evaluate the brokering services in the future.
Runpod
Runpod manages a significant fleet of over 20,000 GPUs, with users all over the world. However, their fundamental architectural choice to put every user inside a “pod” (container) severely limits their ability to service large scale training, inference, and any enterprise workloads.
In our testing, the container-centric design prevents the use of standard HPC and MLOps tools, such as running Slurm with Pyxis or Enroot for containerized MPI jobs, performing active health checks on the underlying bare-metal infrastructure, or using Kubernetes.
In our testing of Runpod’s Slurm offering (still in Beta), we initially used a cluster directly from another provider, FarmGPU, and gave feedback on a number of issues we found. The Runpod technical team was responsive, took the feedback, and committed to actively incorporate this feedback in their next development cycle. A few weeks later, different Runpod team members insisted that we re-test with a different bare metal provider, directly from their console. While we appreciate their engagement, all the core issues we found on the first round of testing remained.
The default user is root, with no way to add additional users, enforce RBAC, or use an external IAM provider. The default home directory (~) is not on a shared filesystem, forcing users to navigate to a separate /workspace directory. More critically, the environment lacks essential tooling. We found no pre-installed MPI, and initial attempts to run MPI-based jobs using srun failed due to a required hostfile modification, specifying external container hostnames and routes, since these are not updated in DNS or standard IPs. Specifically, we had to export NCCL_SOCKET_IFNAME=”ens1” because it was not pre-populated in /etc/nccl.conf, export HF_HOME=/workspace/.cache/huggingface because /root is the default workdir, not /workspace, run head_node_ip=$(srun --nodes=1 --ntasks=1 -w “$head_node” ip addr show ens1 | grep “inet “ | awk ‘{print $2}’ | cut -d’/’ -f1) and include --hostfile hostfile in mpirun commands, instead of much simpler options on standard clusters. Even with knowledge of these custom approaches going into the second round of testing, it is currently still poorly documented and clearly a beta feature.
On monitoring and health checks, we expect it will continue to be difficult for Runpod to ensure the reliability and performance required for large scale training. We have heard from multiple Runpod customers that since Runpod does not explicitly state which underlying hardware provider you’re going to land on (aside from specifying a “region”, and a binary “secure” or “community” cloud) that they effectively feel like they’re spinning a roulette wheel to try and “get a good pod”. In other words, users waste a bunch of time spinning up/down pods based on their perception of quality, because price-per-value information is not available to them in the console.

Overall, we expect Runpod will continue to serve a niche market that values its simplified, container-first approach, but it will struggle to make progress against our criteria without a fundamental change to their architecture.
Verda/DataCrunch
Verda (formerly DataCrunch) is based in Finland, with datacenters in both Finland and Iceland. When logging in, Verda provides a nice clean console, making provisioning quite straightforward. Their “Instant Clusters” feature was easy to use and spun up a slurm cluster in minutes. We were also impressed by the completeness of their Slurm implementation, which stands in stark contrast to many other providers on the bronze or even silver tier of this list. From this experience, it seems like they have battle-tested the offering with customers, despite it still being labelled as “Beta”.

Specifically, the B200 cluster we got had everything we expected: pyxis, enroot, hpcx, nccl, nvcc, topology.conf, dcgmi health -c plugged into Slurm’s HealthCheckProgram.
On monitoring, the Grafana dashboard included an interesting SSH command to retrieve the password, and was relatively well configured. Missing pieces related to job performance were minor, and we gave feedback how to make some improvements beyond standard DCGM metrics, and display them in a meaningful way to users. The platform also still lacks any way to add users with RBAC enforced at the storage or slurm level.
Overall, with working B200 instances available, and comprehensive slurm install, our initial impression was that Verda had made significant improvements from our last round of testing. However, this solid software foundation is still undermined by significant issues on the business and operations side.
We have heard about reliability issues from various Verda customers, both at the hardware level and with respect to their WAN connectivity. Specifically, Verda customers have told us that entire sites can go dark with no explanation. While things like this happen, the more serious issue is in response. Unfortunately, we have seen Verda charge their customers for GPU time even when instances are down or entire sites are inaccessible. To us, this is an offensive business practice. Our basic expectation for all cloud providers is to commit to their SLAs in written form, with penalties in the form of credits or deductions off a customer’s monthly bill in the event of a breach. Not upholding a written SLA undermines many of the technical benefits and attractive pricing that we have seen from Verda during our testing.
Note: since publishing this article we’ve discussed this issue in detail with Verda. Verda is committed to compensate any customers who experience downtime with at least 2x the cost of running any instances in the form of a credit. Customers contacting technical support via chat get an automatic message stating that all downtime will be compensated. Verda typically issues refunds within 24 hours of the downtime occurrence during weekdays, and on the following Monday for downtimes occurring during weekends. For customers billed monthly, any downtime or defects are compensated by subtracting the corresponding amount from the monthly invoice.
Frankly, we think this is an excellent response.
In general, SemiAnalysis recommends that customers be sure to keep server logs, screenshots, and other information readily available if they are pursuing downtime claims from their provider. At this time we have only seen gold or platinum tier providers proactively issue credits without customers asking for them.
Overall we recommend that Verda shore up their reliability challenges, finalize their slurm offering currently in beta, improve the monitoring dashboard, and continue development of their kubernetes offering. We look forward to seeing more from Verda in the future.
Digital Ocean
Digital Ocean is another case of a traditional cloud provider attempting to get into the GPU game. However, with standard pricing of $3.44 per H200-hr, no slurm and no kubernetes, we expect it will be difficult for them to compete for business where the customers is not already locked into their ecosystem.
While we were unfortunately unable to create a GPU instance directly on the Digital Ocean console directly, we were able to access a machine via PaleBlueDot, a marketplace discussed later in this article. The single machine showed reasonable performance, but without the ability to create clusters, no shared storage or high performance networking, monitoring, or health checks in place, it is difficult for us to recommend using Digital Ocean GPUs for anything more than a bare minimum developer machine.
IBM Cloud
IBM Cloud is our last general-purpose cloud getting into the GPU game. IBM falls victim to the traditional enterprise hubris that leads companies to be opinionated about things that the market has already decided on.
Instead of Slurm, IBM pushes you to use LSF. Instead of Weka or VAST, IBM pushes you to use Spectrum Scale (their GPFS). Instead of kubernetes, IBM pushes you to use OpenShift. This is all supposed to be to your benefit, Mr. Customer, because IBM knows better than you. Except for the fact that it is not, and they don’t. Even the IBM AI Research division uses SLURM over LSF.
Unfortunately, when we tried to line up testing with IBM, they went so far as to deactivate our account and block us from making new sign-ups


Even when trying to circumvent this verification process, IBM’s Account Verification team (a different team than the Analyst Relations and Product Management team we were originally working with) called the cell phone number included in the account sign up process and pestered us with questions about what we were doing on the platform. “Research” was not good enough, we needed to explain exactly what we were trying to do with the new account.


Though there are lots of promotions available via coupon code, in the default region of Frankfurt it is hard to justify $12.25 per H100 GPU, per hour…

With all that said, it did take us only 45 seconds to spin up a new machine, a little bit longer to assign a floating IP, and access it. NVIDIA drivers, docker, and the nvidia container toolkit are not pre-installed in the base image, causing a bit more headache before we could get started with testing. But it worked.
We were about halfway through a simple download speed test using docker when IBM once again found our account and shut us down. We maintain IBM’s rating as a bronze tier provider until we are able to test their services in the future.
Hot Aisle
Hot Aisle is an AMD-exclusive neo cloud offering MI300X GPUs in 1-way VMs or 8-way bare metal nodes, on-demand, at a competitive price. Recently, they completed a SOC 2 Type I attestation and achieved HIPAA compliance. Interestingly, they have also released 2-way and 4-way VMs, with the AMD xGMI interconnect passed through and available. This is a unique and competitive offering for developer machines. We know of a few users in the open-source ecosystem that test on Hot Aisle due to flexibility and representative, real-world performance.

At this time, Hot Aisle does not have shared storage, monitoring dashboards, health checks, modern security practices, RBAC, vertically integrated support, or the ability to run at scale (i.e. anything more than 2 or 4 machines at a time). They claim to have slurm or kubernetes on their website, but when we reached out for help it was not setup. The first time we tried to test, Hot Aisle was unavailable and did not have any bare metal servers or virtual machines available for us to use, though we were able to grab some later on.


It is difficult to understand how Hot Aisle will make progress beyond providing cheap MI300X while the market moves to MI325X and MI355X. While other providers already full set up and offering access to paying customers for MI355X since September, Hot Aisle’s MI355X may not come until the end of this year, or even into early next year. Focusing on individual developer machines instead of clusters is a niche, focusing on AMD GPUs instead of NVIDIA GPUs is a niche, and focusing on the MI300X instead of the MI325X or MI355X is a niche. So, a niche of a niche of a niche market.
Vast.ai
Vast.ai (not to be confused with Vast Data, the storage provider) operates as a GPU marketplace, not a direct provider. The platform claims SOC2 compliance is in place directly, and some other notable security information: https://vast.ai/compliance. They also state that many underlying datacenter providers are ISO27001 compliant, a notable step up from an aggregator, but still less introspection on who the underlying provider is than we would like since generally only the location is described. Vast does provide ways for users to track datacenters by IDs, and toggle for a “secure cloud”, but does not expose who the underlying provider actually is outside of the country. Clusters are available on a per-request basis and we have not been able to try one out. Users can pay for their GPUs with stripe (credit card), coinbase, or crypto.com.
Our testing experience confirms the platform’s architectural focus: it is almost exclusively designed for containerized workloads, heavily pushing users toward Jupyter notebook environments. Gaining basic SSH access required manual configuration steps, and once connected, it was clear we were operating inside a container, not a VM or bare-metal host. This container-only model immediately precludes standard multi-node orchestration like Slurm or native Kubernetes, though cluster-on-demand requests are available.

Reliability and performance are unpredictable, which is characteristic of the aggregator model. Our first test instance was provisioned in Czechia, hosted by an unknown underlying provider (though an IP lookup suggests E-Infra or Zoner Cloud). While this instance was functional, the marketplace model means users are rolling the dice on many qualities with every deployment. Without the ability to test managed Slurm/Kubernetes, multi-node clusters, or review monitoring and health checks, Vast.ai remains a platform primarily built for individual developers and hobbyists.
CUDO Compute
CUDO Compute was founded in 2017 and like many others on our list began its journey as a crypto miner, albeit at a modest scale. CUDO now operates a global partner network of data centers, including a recently announced a partnership with CanopyCloud.io to expand their datacenter network globally.
Our hands-on experience started with their web console, which offers a highly configurable and project-based approach to organizing resources across global datacenters. Today, interconnected nodes are only available in Dallas, while 8-way bare metal servers are available in Paris, Stockholm, or Kristiansand Norway. In total, GPU VMs are available in 6 of 10 global datacenters, with the other 4 providing CPU-only VMs. We decided to grab our first ever African GPU VM, via CUDO’s datacenter in Centurion, South Africa.

Spinning up a virtual machine was straightforward, with the provisioning process taking under 4 minutes and the console providing easy ssh key management. Usefully, we could configure a shared disk in the datacenter location we were using, meaning local data can be re-used in between cycles for a VM to spin up/down. However, the 200GB disk we deployed is not a filesystem volume, and is not mounted and visible to the OS image by default. We would prefer a shared filesystem volume that could be mounted to multiple machines, and requires similar underlying functionality on the server side to deliver. We also found it unfortunate that we were logging into the VM as a shared root user, instead of passing RBAC-enforced auth credentials from the console to the underlying VMs.
Furthermore, the base Ubuntu image was not AI-ready out of the box. The driver version and nvidia container toolkit version provided were significantly out of date (meaning insecure). The OS image was also missing pip/pip3, and the python3 binary was not aliased to python, requiring extra steps to set up a basic virtual environment for development. Crucially, CUDO Compute does maintain ISO 27001 compliance with underlying datacenters, a key security attestation that many similar providers lack.
Overall, CUDO Compute has a promising foundation with a flexible, easy-to-use console and global reach. However, the platform is not ready for large scale training and inference due to a lack of managed slurm or kubernetes services, shared file storage, monitoring dashboards, health checks, and any sort of proactive, enterprise support options. We recommend that CUDO focus on refining their base machine images for ease-of-use, consider deploying shared file storage, and continue building experience at the orchestration layer for slurm and kubernetes clusters in the future.
Lightning.ai
Lightning.ai (aka Lightning Cloud) is a broker for GPU machines in neoclouds and hyperscalers that provides useful MLOps features on top. The founding story of Lightning Cloud begins with the development of PyTorch Lightning, an open-source framework that organizes and simplifies boilerplate PyTorch code such as the training loop, logging, checkpointing, and distributed training. The lightning git repo seems to be the #1 way top-of-funnel sales start for Lightning Cloud.
Fast forward to today, with LLMs on the rise, there is a split in the market. Older frameworks like NVIDIA NeMo use Lightning under the hood, while new frameworks that we use in our testing such as torchtitan, verifiers and Megatron-LM do not. The open source pytorch-lightning and lightning packages are still growing rapidly:
Functionally, the Lightning Cloud product offers a simple way to track who’s using what across multiple clouds. We had a chance to test the Lightning Studio, which provides access to GPUs in a browser (VSCode, Jupyter notebook) or remote SSH (VSCode, Cursor, Windsurf, etc). Users can also submit batch jobs and “mmt” (multi-machine training) jobs to individual machines or clusters that they get access to on demand. Our testing of clusters is coming soon.

Notably, these multi-GPU studios, batch jobs, and mmt training jobs are restricted to users on a Pro, Teams or Enterprise Custom payment tier. Lightning is the only neocloud we have seen charging a per-seat price, and translating that into GPU-hrs behind the scenes on clusters that they manage for the customer.
Interestingly, there is an easy way to attach/detach GPUs to existing “studios” (i.e. notebooks or remote shells) and auto-sleep them if unused. This means that users only paying for what they use. Lightning also forecasts the wait times associated with spinning up a GPU from a given provider, such as AWS, Google, Lambda, Voltage Park, or Nebius. The worst wait time is for an 8x H200 machine in AWS, estimated at 3hrs. Unfortunately, despite what the website says, there are no GPUs available from NScale.

Another piece that jumped out during testing is that notebooks have full CLI access including docker, meaning the notebook is running directly on a VM under the hood. This leaves users with full flexibility in the environment.
Overall we have our doubts about the utility of remote developer environments where cluster access is abstracted away from users, especially at the high-end of the market. The largest buyers of GPU compute do not have a problem spinning up a notebook on kubernetes with a simple manifest.yaml, or accessing a single machine via srun -N1 —gpus-per-node=8 —pty bash in a slurm cluster.
We find it hard to see a path forward for Lightning Cloud if the industry moves beyond the lightning framework and the GPU marketplace business continues to focus on taking a margin on top of expensive hyperscalers, with no third party compute. As for the ClusterMAX rating system, we look forward to testing Lightning Cloud’s mmt training, and kubernetes in the future. We encourage Lightning to consider building a slurm offering, adding monitoring dashboards for underlying cluster health that integrates with job logs and performance profiling, adding integration with active/passive health checks on clusters, and customization options for high performance storage and networking.
Qubrid
Qubrid enters our ratings in the Bronze tier. The provider offers individual GPU instances (VMs) and bare-metal server rentals through a clean web console, with hardware ranging from H100s to the latest B200s.
Our hands-on testing of their individual VM offering was a mixed bag. On the positive side, the user experience for provisioning a single machine is straightforward. SSH and Jupyter access are easy to configure, and our B200 instance was provisioned and accessible in around 8 minutes.

However, this basic usability is undermined by the fact that Qubrid charges users while the machine is stuck spinning up. We can only speculate that the reason for this is that Qubrid is running on AWS hardware in Ashburn, VA (us-east) as confirmed by a basic IP test when we logged in, though they do not make this clear to their customers. Readers can see in the screenshot above that our B200 instance was provisioned with the CUDA 12.4 toolkit by default. While the driver was newer (12.6), this older toolkit just obviously doesn’t work with Blackwell hardware (i.e. SM100) which requires CUDA 12.8 or above.
Finally, Qubrid’s business model feels more like a traditional server host than a flexible neocloud. Their pricing requires strict minimum commitments (e.g., 1-week for H100, 1-month for H200, and 3-months for B200) and they openly advertise yearly server rentals, despite not owning the hardware. We encourage Qubrid to fix its billing practices, address usability issues, and be more upfront about who’s hardware they’re selling to customers.
Latitude.sh
Latitude.sh presents itself as a straightforward provider with bare metal or virtual L40S and H100 machines mostly located in Dallas, Texas. Upon logging in, the console is clean and well-organized. We appreciate the ability to organize resources by project and apply tags for environments like ‘dev’ or ‘pre-prod’. Provisioning options are clear, and spun up a machine in seconds.
An interesting and somewhat unique feature is the ‘Cloud Gateway’ service, which leverages Megaport to establish private connections to major public clouds. This could be a compelling offering for customers pursuing hybrid or multi-cloud strategies.
Unfortunately, we had a couple issues during testing, where an L40S VM reported an NVML driver/library mismatch error, and an H100 VM’s driver provisioning just didn’t work properly.

This sort of instability is part of the danger of using virtual machines in general. However, once we provisioned some new VMs, an L40S and H100 instance performed as expected, with the GPU immediately recognized by nvidia-smi out of the box.
With that said the only base OS image available is “Ubuntu 24 ML-in-a-Box”, except it includes an out-of-date pytorch version, python3 without the python3-venv package, no alias for python, and no docker or nvidia-container-toolkit pre-installed.
Beyond the individual instance issues, Latitude has no Slurm or Kubernetes offerings, no integrated monitoring dashboards, no shared storage options, and no health checks.
For individual developers or small teams, Latitude.sh might offer a compelling price point. But for organizations seeking a production-ready cluster, the platform falls short.
Denvr Dataworks
During previous rounds of testing, Denvr Dataworks was a strong cloud provider with a promising future despite a part-time obsession with immersion cooling. To set aside the claims around the viability of immersion cooling on the technical side, it is also clear that claims regarding the usage of fresh water for cooling in datacenters are way overblown. This is described in detail in this report and this article, which estimate that datacenters in the US used less than 0.15% of the nation’s freshwater last year, depending on how you count it.
50M gallons per day if counting only cooling
200-275M gallons per day if counting power but not dam reservoir evaporation
628M gallons per day if counting evaporation from reservoirs used for hydro power
Compared to the roughly 2 billion gallons of water per day used for golf course irrigation, the 50 million gallons per day on liquid cooling is about 2.4% of the total.
Unfortunately, it seems that much of the original Denvr team has now left the company and GPUs are inaccessible to us when using their website directly.


However, Denvr’s hardware has not disappeared entirely. Instead, it appears Denvr has pivoted to wholesale-only, surfacing its capacity through aggregators and marketplaces. During our testing of the Dstack Sky platform, our job was provisioned on a Denvr Dataworks machine in Houston, Texas via vast.ai. After getting through the turducken of ssh tunnels and into the dstack orchestrated, vast.ai deployed, container running on the Denvr server, we were able to successfully run a multi-GPU (2x H100) RL training job on this hardware. When it works, it works.
In the future we look forward to revisiting the Denvr platform and testing out slurm or kubernetes offerings.
Not Recommended
Not Recommended is our last category, and the name speaks for itself. Providers in this category fail to meet our basic requirements, across one or more criteria. It is important to note that this is a broad category, so in the body of the article we describe what exactly each cloud is missing.
Underperforming – based on our hands-on testing, we believe that providers in this category can quickly rise to bronze or even silver if they fix one or more critical issues. Examples of critical failures include but are not limited to: no modern GPUs available (i.e. only A100, MI250X, or RTX 3090, since we expect at least H100 to be available), not having basic security attestation completed (e.g. SOC 2 Type 1, or ISO 27001), mistakenly disabling key server features (i.e not disabling ACS, or not enabling GPUDirect RDMA), or conducting offensive business practices such as charging users for GPU hours while a cluster is being created or while servers are down due to hardware failure.
Unavailable – providers in this category have an interesting service that we are excited about, but have no way to verify as it is not available to the public or for us to test. Examples include providers that have not launched their service yet (despite marketing material that would have you thinking otherwise), providers that are completely sold-out with no plans to add new capacity, providers that exclusively serve secure government customers, or other reasons. We are excited about many of the providers in this category but maintain a “trust but verify” approach to our testing and keep them in this category until we can complete hands-on testing.
Underperforming
Sharon AI
Sharon AI is an Australian-based company making a significant push into the US market. Their ambitions include a joint venture, Texas Critical Data Centers, which aims to build a 250MW data center with a path to 1GW. They advertise a fleet of the latest hardware, including NVIDIA H200s, H100s, and AMD MI300X GPUs, all deployed with InfiniBand.
However, upon signing up for an account and logging in to their “Client Area”, we couldn’t actually find a way to spin up an instance. We could configure a GPU machine for a reasonable on-demand price per hour.

Despite the console showing “ready” for this VM for quite a while, it took 6:21 to spin up and access the Virtual Machine and start running some tests. We also got a NVML Driver/library version mismatch error on the machine:

And then a minute later… it just went away


We think there were some provisioning script running in the background, despite our ssh access being enabled from the console. Notably, we did select a “docker, portainer, nvidia container toolkit” related image during the setup process, and that stuff did start randomly running.
But, then it came back. And this time it didn’t go away.

After waiting for 22 minutes more, we cut our losses and shut down the instance. Interestingly, you can spin up instances on demand, but you need to submit a manual Cancellation Request to shut down your instances. There is also no credit system, so you won’t know how much you spent until you see your monthly bill. We hope our Cancellation Request was accepted!

Most critically, Sharon AI positions itself as an enterprise-grade provider, yet fails to meet the basic table stakes for this category. We could find no public documentation or evidence of a SOC 2 or ISO27001 security attestation. For a company handling potentially sensitive training data and proprietary models, this is a non-starter.
IREN/Iris Energy
IREN is one of the most aggressive crypto mining companies trying to convert their facilities into a neocloud. Unlike their competitors such as TeraWulf, Core Scientific, and Cipher Mining, which have all realized significant value from their existing investments by pursuing the powered shell datacenter infrastructure business (aka colocation), IREN is intent on doing things the hard way and building a neocloud all by themselves, with no relevant experience on their team, now with nearly 100K GPUs committed for current and future customers.
We have tested IREN in March 2025 and found the service to be severely lacking, with multiple basic configuration errors on the hardware such as ACS not being disabled and GPU Direct RDMA not being enabled. In March 2025, our two node NCCL test on the AllReduce collective showed that IREN machines had around 129.27GB/s at 128MiB msg size when the Nvidia reference numbers and our testing for top tier neoclouds is well above >= 300GB/s busBW. It was later confirmed to us by IREN engineers that the root cause was due to their team not disabling the ACS setting on the system’s PCIe switch, which meant the GPU couldn’t talk directly to the NIC but instead had to go through the root complex of the CPU. While this should be a simple fix and checks or remediation is easy to automate with software, we have not been able to verify that IREN has made any changes. For this round of testing, IREN has claimed they have no capacity available to test for over 3 months straight.
Recently, IREN has had some success, signing a $9.7 billion offtake deal with Microsoft targeting a portion of their 750MW site in Childress, Texas. It is known within the industry that IREN offers below market rate prices compared to providers in the ClusterMAX Silver, Gold, or Platinum tiers. We think the reason is twofold:
Cheaper-than-average cost structure, through ownership of the datacenter and site selection centered on areas with cheap power costs (typical in the Bitcoin mining business)
Inferior service quality, relative to the market average
For a deeper analysis of the economics or IREN’s publicly announced AI cloud contracts, our AI Cloud TCO Model is the best tool. It is trusted by many major GPU buyers, as well as their financial sponsors.
Hydra Host
Hydra Host is another marketplace/broker that operates without any security compliance attestation and as a result has lost some opportunities with Fortune 500 customers. Their Brokkr platform has been recently redesigned which makes it easy to access GPUs from a wide variety of datacenters, though there is lots of information missing if you want to know exactly which provider you are renting GPUs from. During our test, lots of GPUs listed on the Brokkr platform were currently “at capacity”, even including the A100 GPU:

In total, when we tested, Hydra was “at capacity” for the A4000, 3090, 5090, A10, A6000, GH200, A100, and B200. Available on demand were 8x 4090, 8/7/5/4x L40S, 16x V100, 8x H100 in Vietnam, and 8x H200 India, Washington, or Japan.

Unfortunately, in order to actually get access to one of these servers, Hydra forces users to pre-pay for a weekly bill, and promises to “refund for the unused portion” rather than running a truly on-demand experience.
We look forward to testing Hydra’s white glove cluster product during ClusterMAX 2.1 following their pending SOC2 Type II compliance attestation.
FarmGPU
We tested FarmGPU via Runpod only, as they currently do not have a way to access their cloud services directly. We described our experience in detail in that section, where after some back and forth with the team we were eventually able to see expected performance on NCCL tests on their network using a Runpod-orchestrated slurm cluster with modifications. We have not been able to test kubernetes, or verify any monitoring and health checks in place.
In general, we appreciate FarmGPU’s commitment to improvement over time, strong knowledge of storage drive performance, and contributions to OCP’s Neocloud workstream describing their experience working with the SONiC NOS on Celestica whitebox switches with Kubernetes.
At this time FarmGPU does not have basic security attestation in place. We look forward to testing their services again in the future.
Whitefiber
Whitefiber is a wholly-owned subsidiary of Bit Digital, another company which has recently pivoted from crypto mining to Ethereum staking and AI. Whitefiber went public on the NASDAQ in August 2025, raising approximately $150M. The combined company ($WYFI and $BTBT) has a market cap approaching $1B. Bit Digital recently announced a North Carolina datacenter that can expand from 24MW to 99MW, a large augmentation to their existing footprint in Montreal, with the intention to host more AI customers. In the past the company has mentioned LOI’s for 288MW, and they have publicly announced contracts for 4,096 H100, 1,040 H200, and 464 B200. You can read more about companies like this, and their expansion plans in our datacenter model.
In our testing, Whitefiber’s networking was within the reference numbers if not slightly better for some message sizes.
In terms of other aspects, we were sadly disappointed and did not match the same quality as their networking. we were given a Slinky cluster, with access to both the slurm and kubernetes layer. Unfortunately, neither of them worked. Initially, slurm was inaccessible from a remote machine, with lots of negotiation required to make it work. Meanwhile, at the kubernetes layer, nothing could be scheduled since slurm-bridge was not configured, and all GPU resources were taken by slinky. Eventually, we got a jump box working to get into the slurm cluster, and found the typical slinky footguns: no git, vim, nano, python, or sudo permissions to install software.
Cluster dashboards were long and detailed but missing important metrics about jobs. No active or passive health checks could be found. We were given access to dashboards for clockwork and trainy, neither of which were explained or documented, and were therefore not useful in our testing.
Whitefiber has clearly made investments in their AI cloud offering by hiring a large team of consultants, integrating a custom interconnect to replace NVIDIA, and buying every piece of software pitched to them. Unfortunately, they are held back even from the bronze category for lacking a basic security attestation from a third party auditor, such as SOC 2 Type I/II or ISO27001. We believe that by ClusterMAX 2.1 or ClusterMAX 3 if Whitefiber gets a basic SOC2 Type I compliance in place and fixes their SLURM/Kubernetes orchestration, they would find themselves in at least the bronze tier.
DeepInfra
DeepInfra is a recent entrant into the GPU cloud game, starting as an inference provider and now renting out some of the cheapest B200’s on the market. We expect that with a relatively lumpy business like inference growing faster than can be forecasted on the compute side, DeepInfra is looking for customers to soak up some of their unused capacity. In other words, they are taking the opposite approach when compared to Nebius or GMI’s inference endpoint business that is expanding on an existing cloud business.
Unfortunately, DeepInfra’s only current offering in the neocloud market, an 8xB200 instance, was out of capacity whenever we tried to test it out, and there is no security compliance attestation in place.

With attractive pricing and a talented engineering team, we hope to see more from DeepInfra in the neocloud market in the future.
Dstack Sky
Dstack the company has a really interesting orchestrator and scheduler that replaces the need for slurm or kubernetes. We love the idea of moving beyond slurm and kubernetes, and have been hearing great reviews from dstack users about their experience. On the flipside, the dstack sky marketplace offering is not at the same level. Dstack sky is a cloud broker that works similarly to their GPU orchestration product by focusing on a CLI-driven approach to provisioning GPU resources. The offering allows users to create three types of resources: a dev environment (a GPU instance accessible via an IDE), a task (a batch job), or a service (a deployed model or web app).
Under the hood, everything is powered by docker containers. As we have mentioned previously when reviewing other marketplaces and brokers, this creates an initial restriction for building developer environments that users must comply with to use the product. However, it is nice to see that dstack does not require users to build from their base image, instead allowing users to bring their own image of choice while dstack adds orchestration on top. We particularly enjoyed the convenience script that automatically edits a users local .ssh/config file to provide quick access to newly created systems.
However, the abstraction comes with a significant lack of transparency. It’s unclear how the underlying GPU provider, or “Backend,” is chosen, and there is no apparent way to view the full list of providers or filter by price when you get “Offers” from the CLI. When requesting an H100, we had no way to distinguish between PCIe and SXM models. During testing he happened to receive 2x SXM GPUs, but this seems to be a matter of chance.

Once connected, we found ourselves logged in as root, implying there is no RBAC or shared storage options on the cluster side. The machine we connected to provided a small 100GB root partition, and our connection speed was extremely slow, with seconds of lag for a carriage return to register on our CLI. This was likely due to our instance being provisioned from a provider in Thailand (“Internet Thailand Company Ltd.”). Storage performance, however, was good, taking only 6s to import torch.
This experience highlights the multiple layers of indirection in the Dstack model. We pay Dstack for credits; Dstack then pays a provider like Vast.ai for an instance; Vast.ai in turn pays the end provider to run the container (possibly the provider in Thailand uses a datacenter operator under the hood, too). It’s unclear how many layers exist and who is ultimately responsible for hardware maintenance and security, a significant concern for any serious workload.

With all this said, we are still able to use dstack to connect to a remote machine with 2x H100 inside VSCode in under 5 minutes, install required software in under 5 minutes, and run an RL rollout for a sample model eval. All in less than 30 minutes, paid for by the minute with existing credits. A nice experience for on-demand development that motivates us to reconsider the use of CLI’s to spin up machines. When it works, it works.
We look forward to testing dstack again in the future, and the company is planning on completing a basic security compliance attestation such as SOC 2 Type 1 soon.
PaleBlueDot
PaleBlueDot is one of the many marketplaces covered in the underperforming tier that is missing a basic security attestation. We had a good experience testing some of the five different clouds that are aggregated on the PaleBlueDot marketplace. It was easy to spin up and connect to virtual machines, and we were only charged by the minute. We encourage PaleBlueDot to consider onboarding more providers in order to increase GPU availability and provide a true cluster experience via slurm or kubernetes orchestration and shared storage.
Hyperbolic
Hyperbolic positions itself as a low cost GPU aggregator, however it’s “high-end” H100 and H200 offerings, are explicitly listed as “beta” on the website. Users can pay for their GPUs with cryptocurrency, bank transfers, or credit card payments.
Our hands-on testing began with exceptionally fast provisioning time, with a new H100 instance spinning up and becoming accessible in under 25 seconds, the fastest we saw in all our research. Unfortunately this was immediately undermined by the state of the software on the node. The instance was pre-provisioned with an out-of-date PyTorch version (2.5.1). Also, essential tools like Docker were not pre-installed.

Platform reliability emerged as the most critical failure. Our testing was plagued by persistent connection drops, instances inexplicably falling into an “Unknown status,” and ultimately, a complete failure of the provisioning system that prevented us from creating or accessing any instances.


Overall hyperbolic has a promising business but is lacking basic security attestation, and had among the worst user experience for an on-demand VM from all the marketplaces that we tested. It is unclear if that is on the side of hyperbolic, or the underlying datacenter provider, but we think it illustrates the point about reliability challenges that prospective users of GPU brokers/platforms/marketplaces/aggregators will have to contend with.
Aethir
Aethir functions as an underlying infrastructure partner by creating a decentralized GPU compute infrastructure (DePIN). It aggregates globally distributed, idle GPU capacity and rents it out for both AI and cloud gaming. Its model is built on its own cryptocurrency token (ATH), which is used by investors to “stake” GPUs and provide liquidity, effectively trading on the volatility of spot instance pricing.
Unfortunately, Aethir is not truly a self service experience, requiring prospective buyers to fill out a form in order to purchase GPU time on their platform.

It seems that this decentralized network concept, while particularly useful for cloud gaming, has not taken off yet for AI. Aethir does not have any security compliance attestation in place for users to assess if the company taking payments and managing the GPU access has access controls in place.
Akash Network
Akash is a decentralized marketplace with a supposed 64 active providers on “Mainnet”. When we logged it in it seemed like there were many different consumer-grade GPUs available. We decided to give it a go an request 1x H200.

Unfortunately, we weren’t able to access any H100 or H200 on the platform. Interestingly, there is an option to request AMD MI100 GPUs, but when we tried to request them or different NVIDIA consumer GPUs (3080, 4090) we couldn’t get anything more than an apologetic loading screen:

After a few hours waiting for a bid for a 4090, and none being found, we moved on. Overall our experience with Akash lends us to thinking that it is basically not ready for any workloads.
Salad Cloud
Salad Cloud is another decentralized marketplace that focuses primarily on consumer-grade gaming GPUs at reduced prices in their “Community Cloud” offering. In their “Secure Cloud” offering, there is no option for high-end GPUs such as the SXM H100, H200, or B200. Since ClusterMAX 1.0, we do appreciate that Salad Cloud is now SOC 2 Type 1 certified, and does not charge their customers for cold-boot startup times.

Clore
Clore operates as a decentralized GPU marketplace, similar to Aethir and Akash. It connects individual hardware ‘hosts’ (hobbyists or small-scale crypto miners) with users seeking on-demand compute. Since the platform is built around its crypto token, users are encouraged to use crypto for payments and staking GPUs.
During testing we had basic issues signing up for an account. We have general concerns about the validity of a platform like this with a lack of basic security, reliability, orchestration, storage, and networking features that users expect from their GPU clusters.
Mithril/ML Foundry
Mithril (formerly ML Foundry, formerly Foundry) operates as a GPU aggregator, or what they term an “AI omnicloud.” Their core philosophy is that the primary problem in the GPU market is one of price discovery and market inefficiency. Their solution is to create a “fluid market” through aggregation and abstraction, allowing costs to adjust dynamically to reflect increased supply. We completely disagree with both the premise and solution.
The premise that the GPU market lacks price discover is flawed and represents a fundamental misunderstanding of the market. In our experience, over 90% of the GPU cloud rental volume is done on long-term contract between enterprises with a standard 25% down and monthly payments through the end of the term. In other words, a typical B2B transaction.
The reason for this, which has been detailed throughout this report, is that not all GPUs are deployed equally. GPU compute is not a commodity. Mithril, and other companies trying to aggressively financialize the GPU market as though it is crude oil or lumber, is solving for price per GPU-hr as the only variable. This is an important criteria, but it is just one the 129 criteria that we use to assess a provider’s quality, and is often a poor proxy for the realized TCO of a cluster.
By building abstractions on top of an aggregated and abstracted “roll-of-the-dice” marketplace of underlying providers, Mithril places the entire operational burden on the end user. As a provider, Mithril has no control over their customer’s support experience, orchestration software preferences, networking and storage performance, monitoring experience, or, most critically, the reliability and security posture of the cluster.
With that said, even if GPU compute was a liquid, commoditized market, we would expect the winner to have open access to many GPU providers, real-time data feeds on availability, forecasts for upcoming supply, proxy information for realized quality from end users… but unfortunately we are left with this instead:

GPU.net
GPU.net is yet another marketplace, and one of the biggest by the numbers. The homepage proudly displays access to 42 providers, with 121k total GPUs available.

Pricing is reasonable for on-demand, at $2.15/hr per H100. Unfortunately, all H100 and H200 SXM appeared to be unavailable, showing a “Booking Error” when we tried to purchase them. Eventually, we got a 1x H100 80GB PCIe, and a 2x L40S machine to spin up in about 2 minutes each.

Logging into our H100 machine in North America, and our 2x L40S machine in Australia. One has GPU drivers, and one doesn’t. Interestingly, the machine without drivers had docker installed, and the machine with drivers did not.
We saw that the H100 PCIe machine (dubbed “North America” on the console) was created in Hypertsack/NexGen Cloud’s Montreal datacenter, and the 2x L40S machine (dubbed “Australia” on the console) was created in Sharon AI’s Melbourne, Australia datacenter.
Overall, GPU.net is another crypto-focused decentralized marketplace that may provide users the optionality to access to multiple cloud providers. However, they struggle with reliability, a consistent user experience, and many of the basic expectations that we have for a neocloud such as security compliance and attestation.
Massed Compute
In the previous version of ClusterMAX, we commented on how Massed Compute, a reasonably well run bare metal compute provider, is unfortunately inundating the internet with AI-generated SEO junk articles with incorrect information. This is harmful to the community and simple to fix with <meta name=”robots” content=”noindex, nofollow”> in the <head> section of the HTML for their chatbot webpage.

Exabits
Exabits operates as a bare-metal provider, primarily surfacing its capacity through marketplaces rather than a direct-access cloud. The provider is associated with a cryptocurrency project which seems to provide funding for GPUs through staking.
We attempted to provision Exabits instances via the PaleBlueDot.ai marketplace, where it is listed alongside other providers such as Digital Ocean, Massed, and Nebius. During our testing window, unfortunately no Exabits capacity was available to provision from this platform.
Lacking an accessible self-service platform or available marketplace instances, we were unable to evaluate Exabits against any core criteria, including orchestration (Slurm/Kubernetes), multi-node networking, security, or monitoring.
Sesterce
Sesterce is a French cloud headquartered in Marseille, currently claiming access to 1GW of compute, 100k GPUs under management, and €750 million of investment. They started as a crypto miner, but have recently announced a Europe-sovereign €52 billion investment plan across multiple datacenters. This plan involves an initial site in Valence Romans Agglo, which will have 40k GPUs, totaling €1.8 billion. They then plan to add two additional sites in Grand Est, totalling 600 MW of capacity and 500,000 GPUs by 2028, with additional scaling to 1.2 GW and over 1 million GPUs by 2030. Big plans.
Back to the present day, Sesterce seems to have reasonable availability of NVIDIA GPUs across their “regions” in Helsinki, Kansas City, Des Moines, Salt Lake City, Dulles, New York, Calgary, Toronto, Mumbai, Osaka, Australia, Frankfurt, Amsterdam, Warsaw, Iceland, Norway, and Sweden. From this size and scale, it seems clear that individual VMs are being deployed in datacenters run by other providers. Pricing also reflects a scenario where this is some middleman getting paid.

Users can easily create volumes in the Region where they are planning to launch a GPU machine, and re-use these volumes on additional machines in the future. Nice feature.

Users can also configure a specific docker image to pre-load in the machines cache.

Our 1x B200 VM spun up in the Helsinki Datacenter, and upon login we found that the machine belongs to DataCrunch (now called Verda, another ClusterMAX bronze provider)
Clusters can be requested (but not spun up on-demand) 16 nodes at a time in Helsinki for B200, or 1-4 nodes at a time in Marseille for H100 or H200.
Unfortunately, these clusters are just bare metal machines with a shared storage option. Sesterce does not offer Slurm or Kubernetes orchestration, monitoring dashboards for the clusters, or health checks. It also seems that RBAC with authentication from external IAM providers is not available.

The machine also had nvidia drivers docker pre-installed, with the nvidia container toolkit configured and on the latest version. Download speeds were solid from this Helsinki location, posting some of the fastest times to install pytorch, download an ngc pytorch container, and download a model from huggingface.
Overall, our experience from Sesterce was solid. We expect that for certain users, paying the Sesterce premium for availability and a proper setup of an individual development machine offsets some of the headache that is experienced with other clouds. We encourage Sesterce to get into the game with on-demand slurm and kubernetes clusters given the solid foundation that exists from their public cloud services.
Most importantly, we encourage Sesterce to make it clear which provider is actually running the machine on their underlying platform, and to publicly communicate a third-party attestation of simple security audits and compliance, such as SOC2 Type I or ISO 27001 in order to move into the ClusterMAX ratings.
E2E Networks
E2E Networks is a publicly listed Indian cloud infrastructure provider. The company is undergoing an ambitious expansion fueled by significant fundraising and its integral partnership in the government’s IndiaAI Mission. The company operates datacenters in Delhi, Mumbai, and Chennai, though their AI platform “TIR” only runs in Delhi. However, this is our final review in the article and our worst overall experience.
The testing process began with an aggressive KYC (Know Your Customer) procedure required before we could even log in. Our attempt to provision a training cluster, following their documentation, quickly ran into problems. The platform did offer an interesting selection of pre-configured software images, including NVIDIA NeMo, and options to create a shared file system for our slurm cluster. However, we ran into a complete lack of resource availability.


The most serious issue occurred while we were stuck in this queue, waiting for our slurm cluster to be deployed. We watched as our credit balance was drained, and then went into the negatives. The entire time, we were unable to click delete on the cluster and remove our account from the queue.

Eventually, the E2E support team solved the issue by suspending our account completely. We view this business decision to charge customers for time while a cluster is spinning up but not usable as the most offensive business practice we have seen throughout all of our ClusterMAX testing.
OVHcloud
As one of Europe’s largest cloud providers, OVHcloud has a massive footprint and lots of experience. They should be well positioned to capture the sovereign AI market in the EEA. However, OVH is still defined by a legacy IaaS/VPS model that lacks modern GPUs and, oh I don’t know, that one time their Strasbourg datacenter burnt down. Come on its still the first thing anyone things of…

Dihuni
Dihuni is a Virginia-based provider with a solid list of customers. Dihuni also has a long-standing collaboration with NEC, a major electronics company in Tokyo. To run their GPU Cloud, Dihuni has established a key partnership with Qubrid (covered previously in this article). We think this is an obvious trend: neoclouds like Qubrid beginning to sell their software to other providers like Dihuni that have existing datacenters and want an easy button to get started.
Akamai/Linode
Akamai is a CDN giant that made a $900M acquisition of Linode in March 2022 to build a cloud from a foundation of datacenters, networking, and free cash flow. The scene was set for ChatGPT to launch later that year. Unfortunately, Akamai’s entry into the GPU cloud market has been a case study in missed opportunities. Akamai has completely ignored all high end GPUs and instead focuses on the RTX 6000 Blackwell.
Unsurprisingly, the platform has no managed Slurm cluster, and its Kubernetes engine is not optimized for GPU servers.
Akamai’s strategy seems focused on single-node, small-scale inference or developer VMs, which is a crowded, low-margin market. For a company with their resources, this lack of ambition is a significant disappointment to us.
HETZNER
Hetzner is popular low cost provider based in Germany, operating facilities in Nuremberg, Falkenstein, Tuusula, and colos in Ashburn, Hillsboro, and Singapore. At this time the only GPUs available are the RTX 4000 and RTX 6000, likely due to some environmental limitations in their datacenters. Until Hetzner adds high end datacenter GPUs for users to build clusters they will remain in the underperforming category for our criteria.
Unavailable
NScale
NScale is an NVIDIA-backed partner with a huge presence in Stargate Norway, which we have covered extensively in our Datacenter Model: https://semianalysis.com/datacenter-industry-model/. They have announced multi-billion contracts with Microsoft, with the first one in September and follow up with a subsequent announcement in October. These deployments are for Nvidia’s GB300 rack scale solutions.
Unfortunately we have been unable to gain access to any GPUs on the NScale platform, either directly or through publicly advertised partners like Lightning.ai. We regret the difficulties and look forward to testing NScale services in the future.
Core42/G42
Core42 is the neocloud division of G42. G42 also operates MGX (an investment fund) and Khazna (a datacenter development company). All are based in the UAE.
We have covered these companies extensively in our Datacenter Model, and public articles such as: https://newsletter.semianalysis.com/p/ai-arrives-in-the-middle-east-us-strikes-a-deal-with-uae-and-ksa with recent updates showing that a tit-for-tat deal of a measly 10T USD has resulted in an export license being granted and NVIDIA resuming shipments of GPUs to the UAE.
At this time we have not been able to access and test a cluster provided by Core42. We regret the difficulties and look forward to testing Core42 services in the future.
HUMAIN Compute
HUMAIN Compute is the neocloud division of Saudi Arabia’s Public Investment Fund (PIF). The KSA PIF is also involved in other major technology and infrastructure projects as part of the nation’s “Vision 2030” plan. While there have been significant announcements regarding their intent to build large-scale AI infrastructure, a publicly accessible, self-service platform for testing and review is not yet available.
Corvex
Corvex (formerly Klustr) currently operates H200 and B200, with expansion plans for GB200 NVL72 systems coming soon. During our testing period, Corvex was unfortunately sold out.
We appreciate that in order to serve their customers, notably secure federal government agencies in the US, Corvex maintains strict compliance with SOC 2 Type II, ISO 27001/27017/27018, PCI-DSS, and FedRAMP certifications, along with InfiniBand and RoCEv2 isolation, SR-IOV safety controls, and automatic customer notification and CVE patch management. The platform advertises automated Slurm and Kubernetes provisioning, out-of-the-box topology configuration, and integrated Grafana monitoring tied into DCGM and job telemetry.
We look forward to testing Corvex in the future.
Highrise
This is the AI brand for the crypto-mining company Hut 8. Despite massive announcements for over 10GW of power capacity, we have been unable to access any GPUs for review at Highrise. We look forward to testing their offerings in the future.
BluSky
BluSky is a small scale startup with access to massive amounts of power through a relationship with RIOT, one of the largest crypto miners in the US. We look forward to testing their offerings in the future.
Andromeda
Andromeda was created to serve as a VC-backed cluster for companies within the Nat Friedman and Daniel Gross (NFDG) portfolio, specifically recipients of their AI Grant (or AI Grant). The company also operates the popular website gpulist.ai. Their model now involves procuring capacity from a range of neoclouds on our list, on behalf of the startups. Effectively they are a “fractional SRE” or “fractional procurement team” that the startups can lean on. User described to us that Andromeda can take these clusters and deploy their own orchestration layer, primarily via Slurm on Kubernetes, with light namespace isolation between tenants. It seems that the NFDG portfolio companies trust each other.
With Nat and Daniel first going to SSI, and now joining Meta, it is uncertain what the future holds for Andromeda. We are excited by the concept of strategic VCs backing startups with compute capacity in addition to cash, allowing them to compete with startup programs from strategics like the hyperscalers, CoreWeave, and NVIDIA’s NVentures. We look forward to seeing more from Andromeda in the future.
Mistral
Mistral started as one of the leading AI companies in the world, with an affinity for open source models, magnet links, and le chat (apps, not cats). Now that they have procured compute, they have pivoted or added the capability of building a neocloud to their public offering, with a particular focus on sovereign AI projects in Europe. This summer, Mistral even had President Macron advertising their services on stage alongside Jensen. As Jensen said during this session “a country can outsource a lot of things, but outsourcing all of your intelligence makes no sense”. With all of this work well underway, we look forward to testing public offerings from Mistral in the future.
Firebird
Firebird is another provider that debuted this summer at GTC Paris, backed by $500M from the Aermenian government with intention to buy GB300 NVL72 rack scale systems and a focus on sovereign AI. They have support from Telecom Armenia and Ireland’s Imagine Broadband. Though a public offering is not yet launched, we are excited to test it in the future.
TELUS
TELUS is a major Canadian telco that has deployed GPUs in datacenters but is still “launching soon” with its own Sovereign play. The platform is currently unavailable for testing, though we expect to include it in ClusterMAX 2.1, coming soon. We are encouraged that from day one TELUS will offer both slurm and kubernetes clusters to their users.
Telenor
A major Norwegian telco that has announced Norway’s first “AI Factory” in partnership with NVIDIA. The platform is not yet launched and is unavailable for testing, despite initial announcements being made back in February 2025. Norway has one of the largest sovereign wealth funds in the world, a cool climate, and cheap green energy. We are excited to see what Telenor comes to market with in the future.
Alibaba Cloud
While a major hyperscaler in Asia, its high-performance, modern GPU offerings (H100/B200) are not readily available for testing in most public regions, with a primary focus on the Chinese domestic market.
Alibaba Cloud’s managed Kubernetes service is called Container Service for Kubernetes (ACK). ACK provides a fully managed solution where Alibaba Cloud handles the control plane (master nodes), which are critical for the cluster’s operation. You only need to create and manage the worker nodes. This simplifies the deployment and maintenance of Kubernetes clusters. ACK supports various node types, including those with heterogeneous computing resources like GPUs, making it suitable for a wide range of workloads, especially for AI and machine learning.
Alibaba Cloud also provides a managed Slurm solution as part of its Elastic High Performance Computing (E-HPC) service. E-HPC is a platform that simplifies the deployment and management of high-performance computing clusters. It also includes a Slurm on Kubernetes solution, which uses a dedicated operator to deploy and manage Slurm clusters within ACK.

In our datacenter model, we have covered Alibaba’s expansion globally across Thailand, Mexico, SK, Malaysia, and Philippines. There is also a new datacenter in Brazil being built, as ByteDance is looking to add $10B there, Huawei Cloud is looking to build a 4th datacenter there, and Tencent also plans expansion into South America. Notably, Didi, AliExpress, Shein and many Chinese automakers are expanding to Brazil too. Alibaba Cloud is getting in at the ground floor, helping build Brazil’s AI industry from the ground up.
In the future we are very interested in testing the Alibaba Cloud experience. It seems clear that the software console is sophisticated, and proven at scale by some of the world’s largest AI companies. We will be tracking this neocloud’s posture with respect to geopolitics closely over time.
ARC Compute
ARC Compute has a track record of deploying HGX GPU servers to customers in Canada for H100, H200, B200 and B300 generations. Unfortunately ARC has had its fair share of legal troubles, from prosecuting two former employees caught stealing source code and soliciting clients, to allegedly violating US export controls on their server sales. On the website, ARC advertises H100 clusters with InfiniBand starting at $1.45/hr, an attractive price for anyone who can access them for testing. Unfortunately we have not been able to gain access to conduct our testing.
MegaSpeed
The New York times did some reporting on Megaspeed recently, but somehow did not make the connection to Alibaba as the primary customer. Megaspeed is headquartered in Singapore, and we have been tracking their massive buildout across Malaysia for a while in our Datacenter Model.
We have been unable to access any Megaspeed cloud services for our testing.
Bitdeer
Bitdeer is Singaporean-based company that spun out of Bitmain, the largest Chinese crypto mining company that also sells custom ASICs for mining. Bitdeer runs a lot of these ASICs, and is now also a neocloud. Their platform includes sites around the world: Singapore, Malaysia, Indonesia, Iceland, the Netherlands, Canada and the US.

When we logged in to test, there was supposed availability of H100 in Malaysia, US, Iceland and the Netherlands. There is also B200 and H100 in Singapore. Bitdeer’s website claims that they have achieved SOC2 Type I and ISO/IEC 27001:2022 compliance. This should easily put them on our list. However, Bitdeer has an aggressive KYC process in place that prevented us from renting a GPU during the test period. As a result we can’t verify anything about their on-demand GPU cloud platform.
Interesting, Bitdeer offers different prices for bandwidth on a per-VM basis, ranging from 1Mb/s to 1024 Mb/s on a fixed or pay-per-use traffic basis. In heavy usage scenarios, this can double the cost of a 1x B200 VM on their platform from $4.69/hr to $8.27/hr.
Beyond hands on testing, Bitdeer has some big plans. Their site in Massillon, Ohio has recently undergone a third-party feasibility assessment regarding their suitability for Tier 3 HPC/AI datacenters, and reported “largely positive results (…) due to the availability of land, power, fiber and water resources”. We find it interesting to see nothing about the existing buildings in this report. It seems that Bitdeer, like other crypto miners, is planning to knock down existing buildings and use the powered land for a brand new AI cloud building, finally selling that as powered shell or colo with a 10-15% margin on their costs.

Runsun
Runsun is a provider based in Singapore with GPUs deployed in Japan and the US, and plans to expand to South Korea, Australia and Europe soon. Runsun claims over 10,000 GPUs deployed as a bare metal service. At this time we have been unable to access anything for testing, but look forward to testing Runsun’s cloud services in the future.
FPT CLOUD
A large regional provider in Southeast Asia with significant capacity in Vietnam and Japan and partnerships throughout the region. We were unable to gain access to a cluster in time for publishing this article, but expect to include them in ClusterMAX 2.1 soon. Stay tuned.
Backend
Backend is a Korean neocloud with many software offerings that seem to simplify onboarding to clusters. We appreciate the flexibility with backend apparently supporting customers running their software stack on-prem, in their cloud, or on developer workstations. At this point it seems that backend is missing a significant amount of compute capacity, and the public cloud service is still in beta requiring an invitation to test it out. We look forward to testing backend in the future.
Naver
Naver s effectively the “Google of South Korea”, thanks to their success in search, blogging, forums, e-commerce, payments and more. Naver has just recently gone public with their plans to launch a neocloud, thanks in no small part to Jensen’s trip to Seoul and meetings with HBM manufacturers SK Hynix and Samsung. The new cloud project will include a total of some 260,000 GPUs being deployed, with 60,000 going to Naver for the public cloud offering, while the other 200,000 are split between Samsung, SK, Hyundai and Naver’s internal workloads.
Notably, Naver already operates a cloud, has a large research organization putting out great work, and has the infrastructure in place to seed the Korean startup and academic ecosystem at large. We look forward to testing Naver’s GPU cloud offerings in the future.
Indosat
A major Indonesian telco that has a signed an MOU with NVIDIA to become Indonesia’s first certified NVIDIA cloud partner. The platform is not yet launched and is unavailable for testing.
SAKURA
A major Japanese sovereign AI cloud with significant MOUs with KDDI and HPE for a large Blackwell cluster. Their public, self-service AI cloud platform is not yet available for testing.
Yotta
Yotta’s Shakti Cloud (not to be confused with the datacenter industry conference “Yotta”, going by the same name) was the first mover in India’s sovereign AI push, and according to Jensen his “favourite cloud in Asia”. Yotta has announced over 16,000 H100 GPUs are deployed in Shakti, with Blackwell currently being deployed and more on the way. This maintains Yotta’s status with the most GPUs in India at 32,768 total by end of 2025.
We regret the difficulties experienced so far in testing Yotta’s cloud services and look forward to including them for testing in ClusterMAX 2.1 coming soon.
Neev Cloud
Neev Cloud is another Indian neocloud that unfortunately did not want us to test their offerings depite plans to deploy 40,000 GPUs by 2026 in their Indore location in Central India, backed by a $1.5B investment. An initial order in mid-2024 was placed for 8,000 GPUs from HPE, with planned expansion to Chennai, Mumbai, Hyderabad and Noida.
The website claims 1000 to 16000 GPUs connected with InfiniBand, with H200, B200 and B300 all available for “pre-reservation”. A prominent picture of the Neev Cloud CEO shaking hands with Modi on their front page leaves us to assume that Neev will be serving sovereign Indian customers primarily. However, it seems that kubernetes and slurm clusters are not available for testing. India is a large country with a vibrant tech ecosystem, but it is unclear how many neoclouds will make it going forward.
Evroc
Evroc is yet another European company that is building a neocloud with a focus on sustainability and sovereignty. Evroc is headquartered in Stockholm, with plans for datacenters in Arlandastad and Cannes, and partners in Paris, Stockholm and Frankfurt. The plans involve up to 10,000 GPUs GB300 NVL72. At this point we have not been able to test any of Evroc’s cloud services, but look forward to testing the “world’s cleanest cloud” in the future.
greenai.cloud
GreenAI cloud is another Swedish-based cloud provider focused on sustainability and sovereignty. GreenAI specifically claims “CO2-Negative Computing”, and focuses primarily on serving security conscious government agencies in defense, intelligence, health and science. Compliance with Schrems II is in place with a Level 4 secure facility. A100, H100, H200 and B200 GPUs are available, though no GB200 NVL72. Interestingly, a flash-in-the-pan partnership with Cerebras seems to have flamed out, with the greenai team emphasizing that they will never do business with the company again. We have not had the chance to test and of greenai’s cloud services but hope to have that chance in the future.
Disclaimer
The logos and associated trademarks are displayed herein solely for editorial and informational purposes, consistent with the principles of fair use under applicable law. No ownership, affiliation, sponsorship or endorsement by any of the associated Companies is expressed or implied herein. All rights, title and interest in and to the logos and associated trademarks remain the exclusive property of the Companies.
The content, methodology, and data presented in ClusterMAX™ are the intellectual property of SemiAnalysis. Any use of this work, in whole or in part, for the creation, structuring, issuance, or valuation of financial products, including but not limited to derivative instruments, investment funds, indices, exchange-traded products, or structured notes, requires prior written consent from the author.
Unauthorized use for commercial or financial purposes, including the creation of derivative or investment instruments based on these ratings, is strictly prohibited. Licensing inquiries and partnership proposals may be directed to clustermax@semianalysis.com