

Microsoft's AI Strategy Deconstructed - From Energy to Tokens
"The Big Pause", AI Tokens Factory Economics Stack, OpenAI, Neocloud Renting, GitHub Copilot, MAI and Maia
Microsoft was at the top of AI in 2023 and 2024, but then a year ago they changed course drastically. They paused their datacenter construction significantly and slowed down their commitments to OpenAI. We called this out a year ago to datacenter model clients and later wrote a newsletter piece about it.

2025 was the story of OpenAI diversifying away from Microsoft, with Oracle, CoreWeave, Nscale, SB Energy, Amazon, and Google all signing large compute contracts with OpenAI directly.
This seems like a dire situation. Today we have a post dissecting Microsoft’s fumble as well as a public interview with Satya Nadella and our dear friend Dwarkesh Patel where we challenged him on their AI strategy and execution.
Now Microsoft’s investments in AI are back, and the AI giant has never had such high demand for Accelerated Computing. The Redmond titan has woken up to it going down the wrong path and has dramatically shifted course. With the newly announced OpenAI deal, Azure growth is set to Accelerate in the upcoming quarters as forecasted by our Tokenomics model.
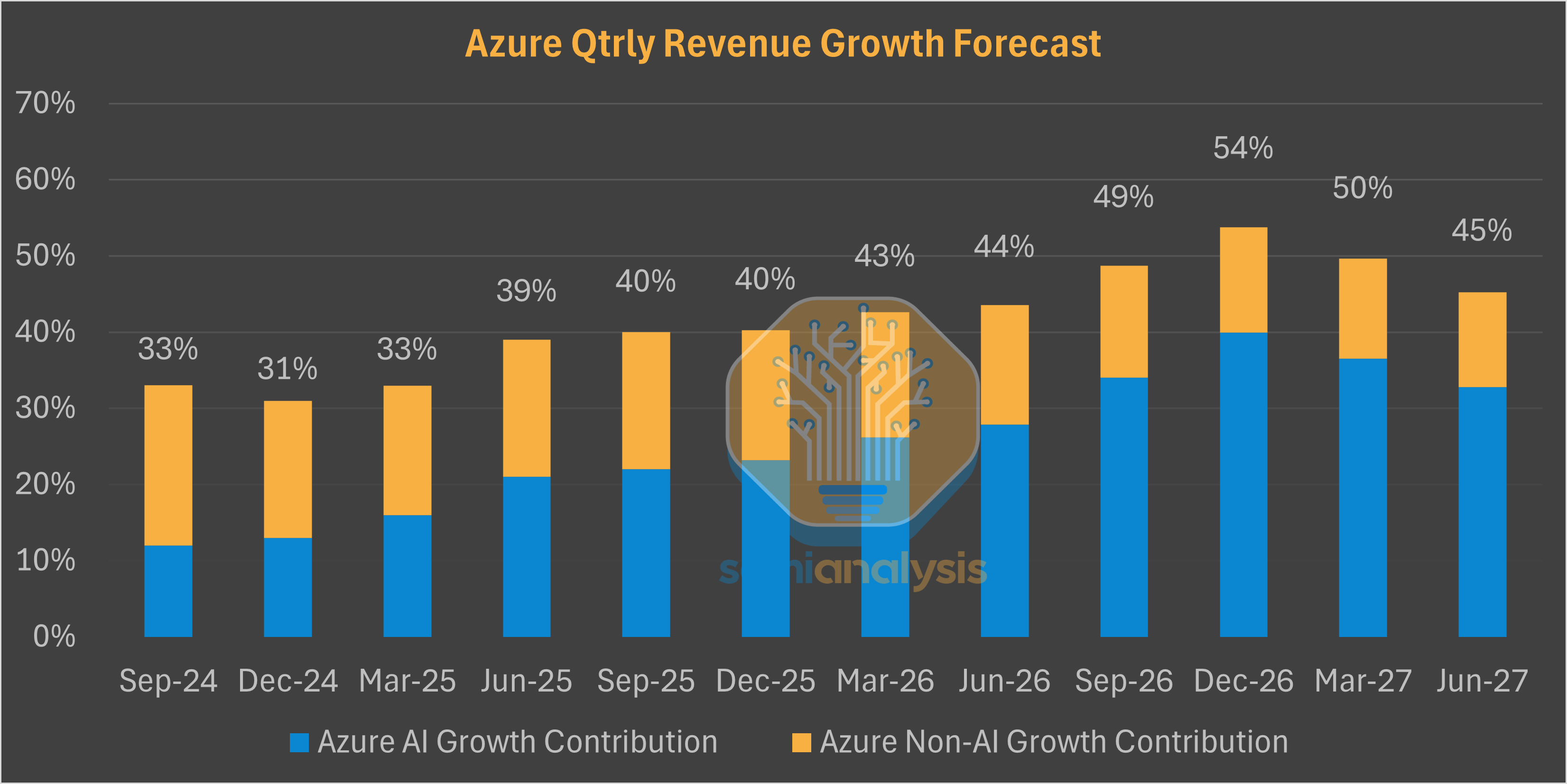
Microsoft plays in every single part of the AI Token Economic Stack, is witnessing accelerated growth, and we expect the trend to continue in coming quarters and years.
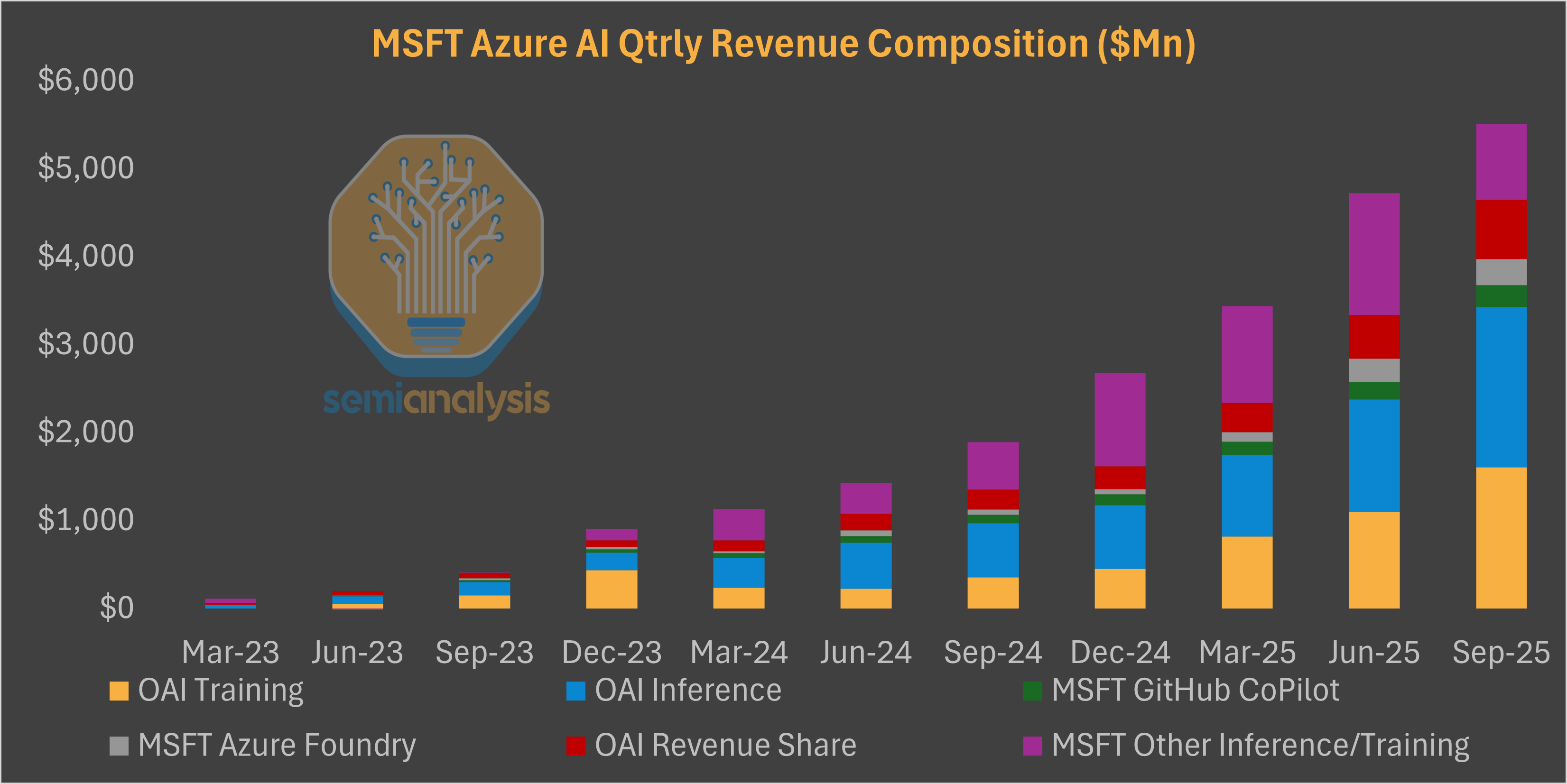
The firm is actively looking for near-term capacity and pulling the trigger on everything it can get its hands on. Self-build, leasing, Neocloud, middle-of-nowhere locations – everything is on the table to accelerate near-term capacity growth (exact numbers available to our Datacenter Model subscribers).
On the hardware side, Microsoft even has access to OpenAI’s Custom Chip IP, the most exciting custom chip ASICs currently in development. Given the trajectory of OpenAI’s ASIC developments look much better than that of Microsoft Maia, it may be that Microsoft ends up using the chip to serve OpenAI models. This dynamic mirros Microsoft’s situation with OpenAI models. While they have access to OpenAI models: they are still trying to train their own foundation model with Microsoft AI. We beleive they’re attempting to become a truly vertically integrated AI powerhouse, eliminating most of the 3rd party gross margin stack, and deliver more intelligence at lower cost than peers.

In this report, we will dive into all aspects of Microsoft’s AI business. We begin by reviewing the history of the OpenAI relationship, covering the historic surge in Microsoft’s datacenter investments in 2023-24, as well as the mooning scale of their OpenAI training clusters – from tens of MWs to Gigawatts. We then analyze the" “Big Pause” and spectacular return to the datacenter market. Much of this is motivated by a drastic simplification of the OpenAI ownership structure as well as Microsoft’s laser focus on serving the infrastructure needed for converting model capabilities into product use cases (and revenue) via stateless APIs.
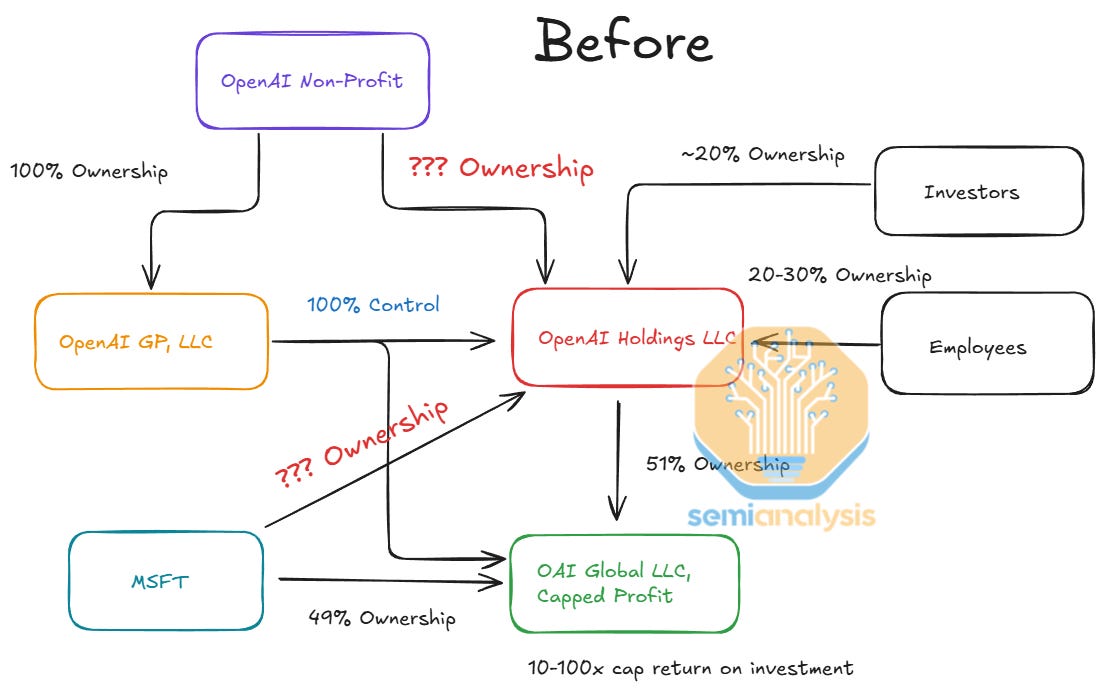
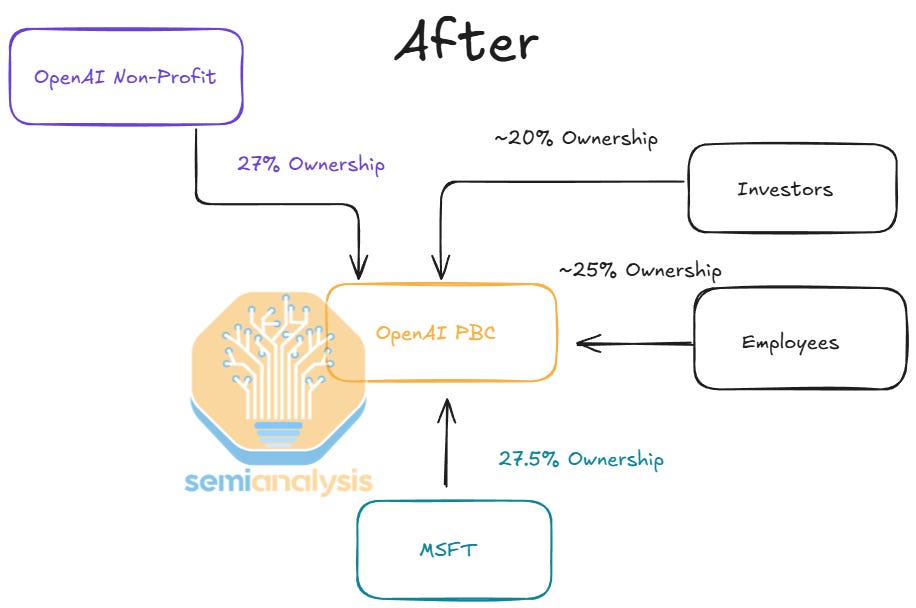
We then analyze every part of Microsoft’s positioning in the AI Tokens Economic Stack:
Applications
LLMs
PaaS
IaaS
Chips
System architecture
In each section, we’ll dive deep into Microsoft’s product portfolio, competitive positioning and outlook. It’s not all good news for Microsoft as the software behemoth faces a slew of new entrants and challengers to their dominant productivity suite and AI compute platform.
Microsoft & OpenAI in 2023-25: From All-In on AI to the Big “Pause”
2023-24: selfbuild, leasing, and building the world’s largest datacenters for OpenAI
ChatGPT’s release in November 2022 changed the world. Microsoft was the first hyperscaler to react to the “ChatGPT moment”, and they did it in a spectacular way. While Microsoft had invested $1B in OpenAI back in 2019, they 10x’d the investment in January 2023. Simultaneously, they engaged in the most aggressive datacenter buildout in history – primarily driven by its key AI partner.
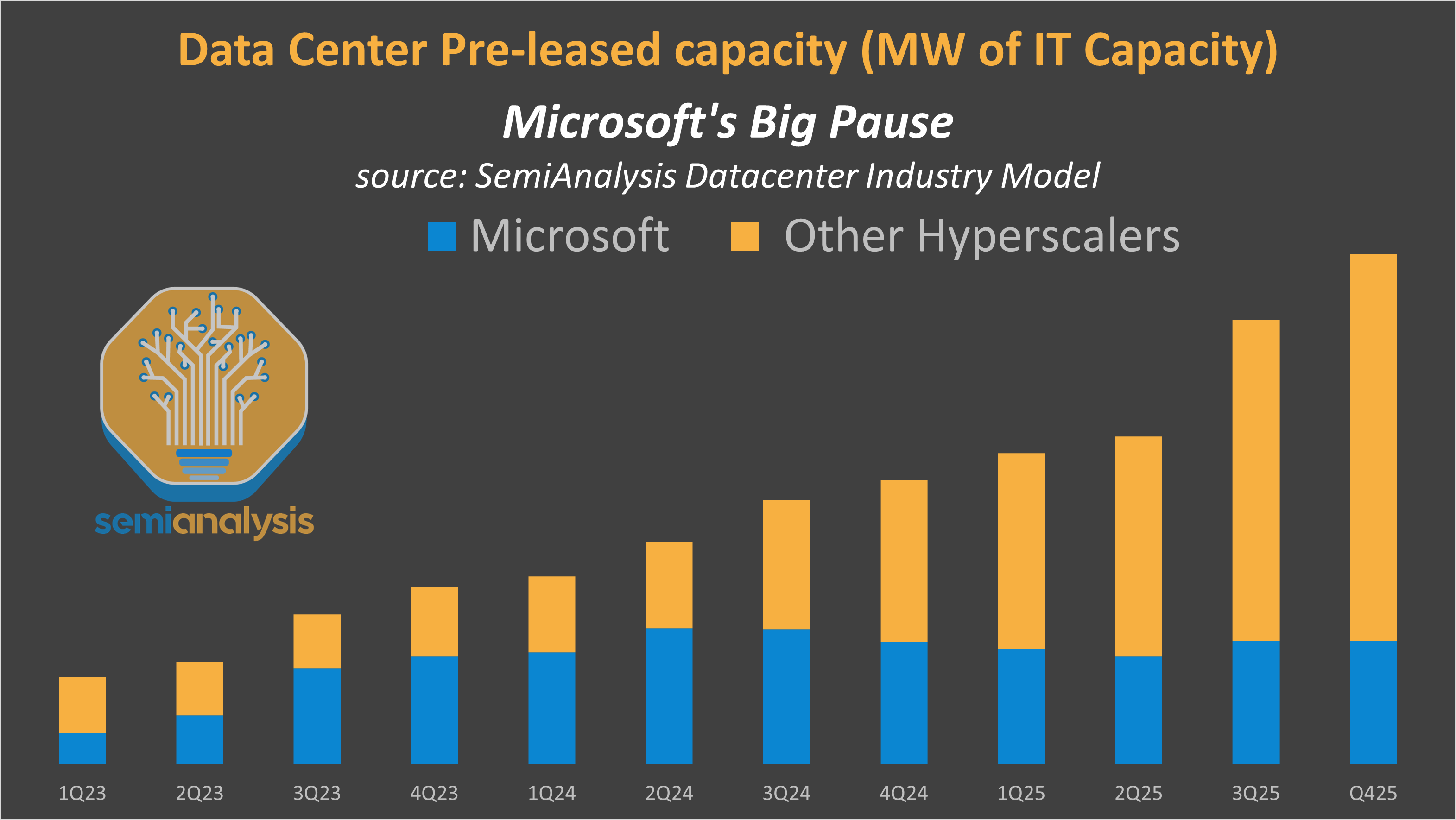
The chart below depicts datacenter pre-leasing activity, one of the best leading indicators on capacity growth and CapEx. Microsoft’s pre-leasing activity from Q1’23 to Q2’24 dwarfed that of the other hyperscalers combined. In Q3’23, Microsoft alone leased nearly as much as the whole North American market leasing in full year 2022.
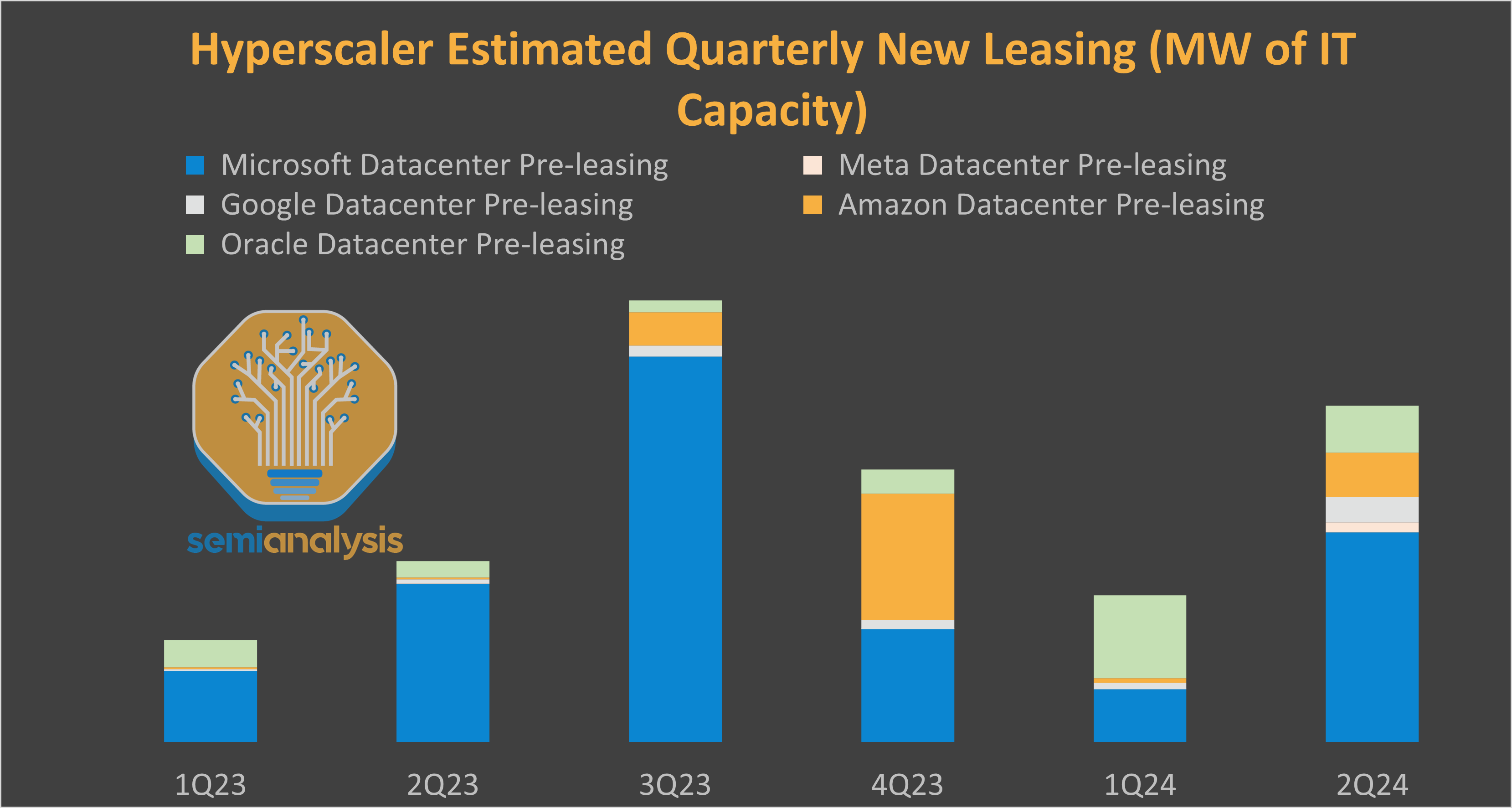
And datacenter leasing is only a portion of the picture. Our building-by-building Datacenter Industry Model highlights unprecedented growth in MWs of self-built capacity added over the course of 2024 and 2025. In addition, they also contracted billions of dollars from Coreweave and Oracle to get additional capacity.
Microsoft & OpenAI training clusters – from a fraction of a building to the world’s largest facility
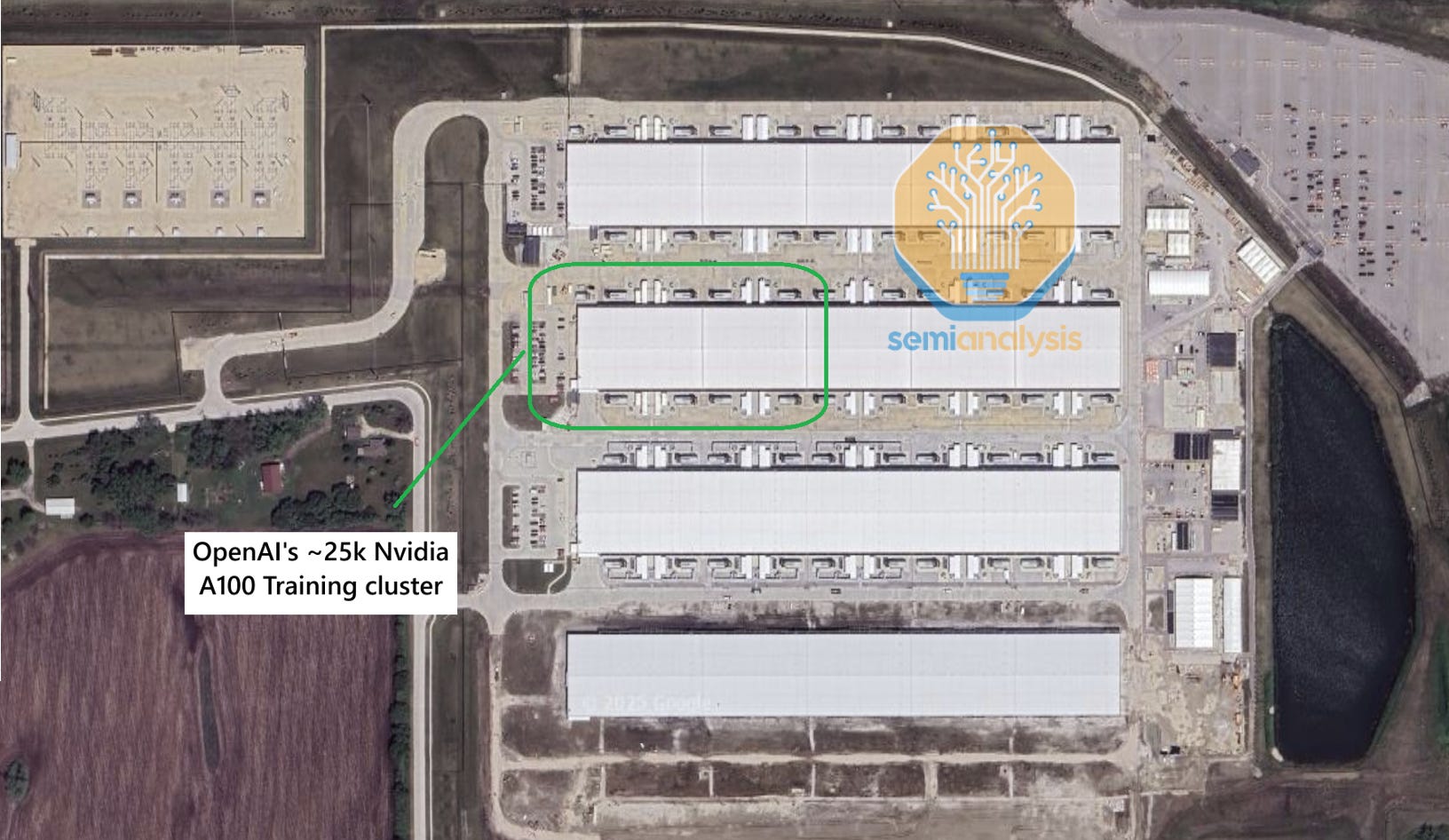
Perhaps the most iconic symbol of this buildout is the “Fairwater” program. In 2023-24, Microsoft planned and simultaneously constructed the two largest datacenters on Earth. Let’s briefly go back in time to get a sense of the scale of Microsoft’s 2023-24 buildouts. We show below their first major training cluster, in Iowa, where GPT 3.5 was trained. We believe it hosts ~25k A100 chips. While the campus shown below is fairly large, we believe OpenAI only uses two data halls of one Ballard building, i.e ~19MW.
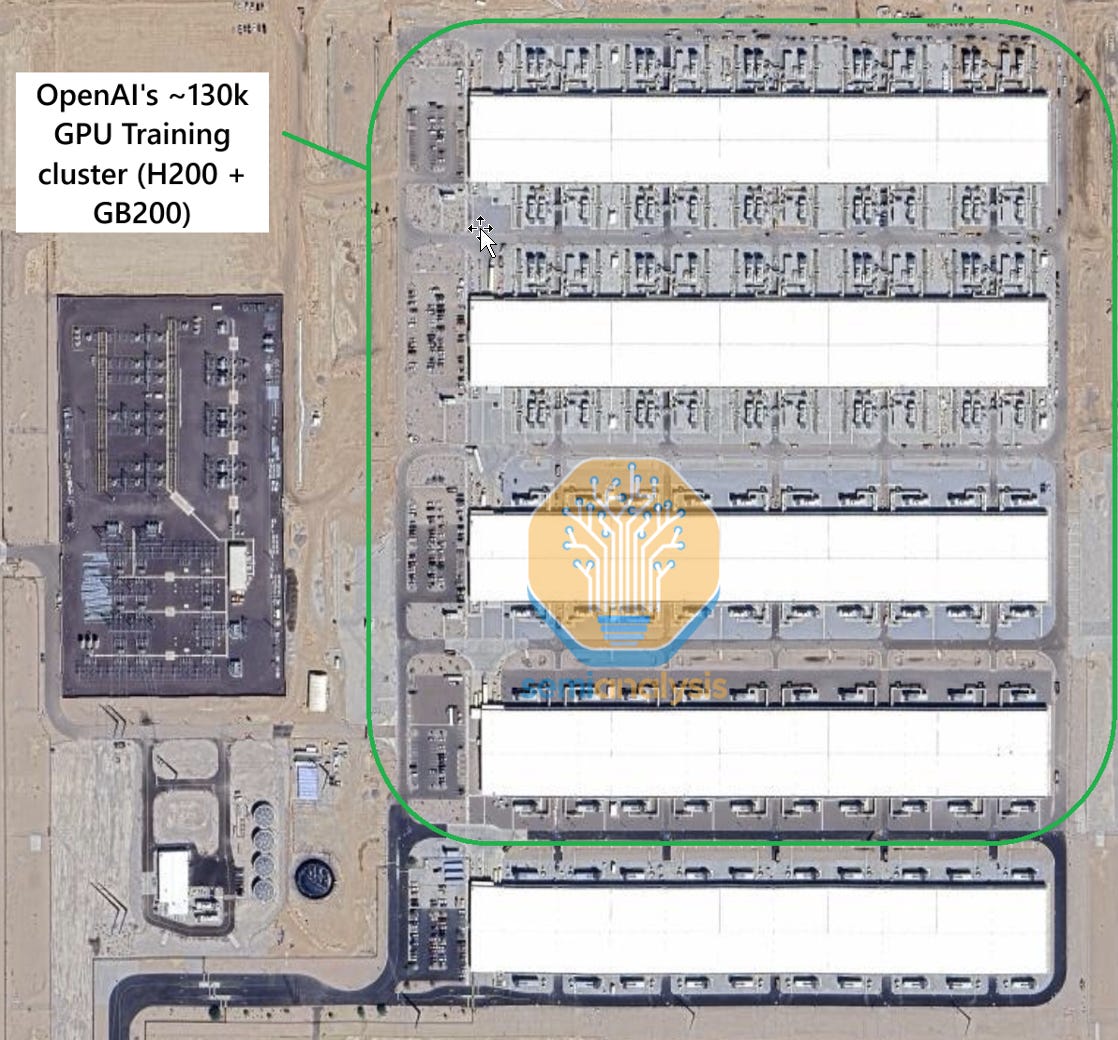
The second major cluster was built in Arizona. It scaled up over time, building by building, with the first H100 building completed in 2023, followed by H200s in 2024 in a separate facility, and two more datacenters hosting GB200 in 2025. In Total, we estimate ~130k GPUs across four buildings.
Microsoft’s next-generation clusters for OpenAI are called Fairwater and are significantly larger. Each “Fairwater” is comprised of two buildings – a standard CPU & storage facility of 48MW, and an ultra-dense GPU building. The latter, with two stories and a total ~800k sqft area, boasts ~300MW, i.e. the equivalent power consumption of >200k American households. That represents over 150k GB200 GPUs per building. We show below the Wisconsin facility – fully dedicated to OpenAI.

In Georgia, QTS built for Microsoft a “sister” facility, again for OpenAI. While the cooling system is different, the GPU building is also ~300MW. The picture below shows the scale of the facility – no other building in the world has as many air-cooled chillers for cooling purposes! The size of the onsite substation is also impressive.
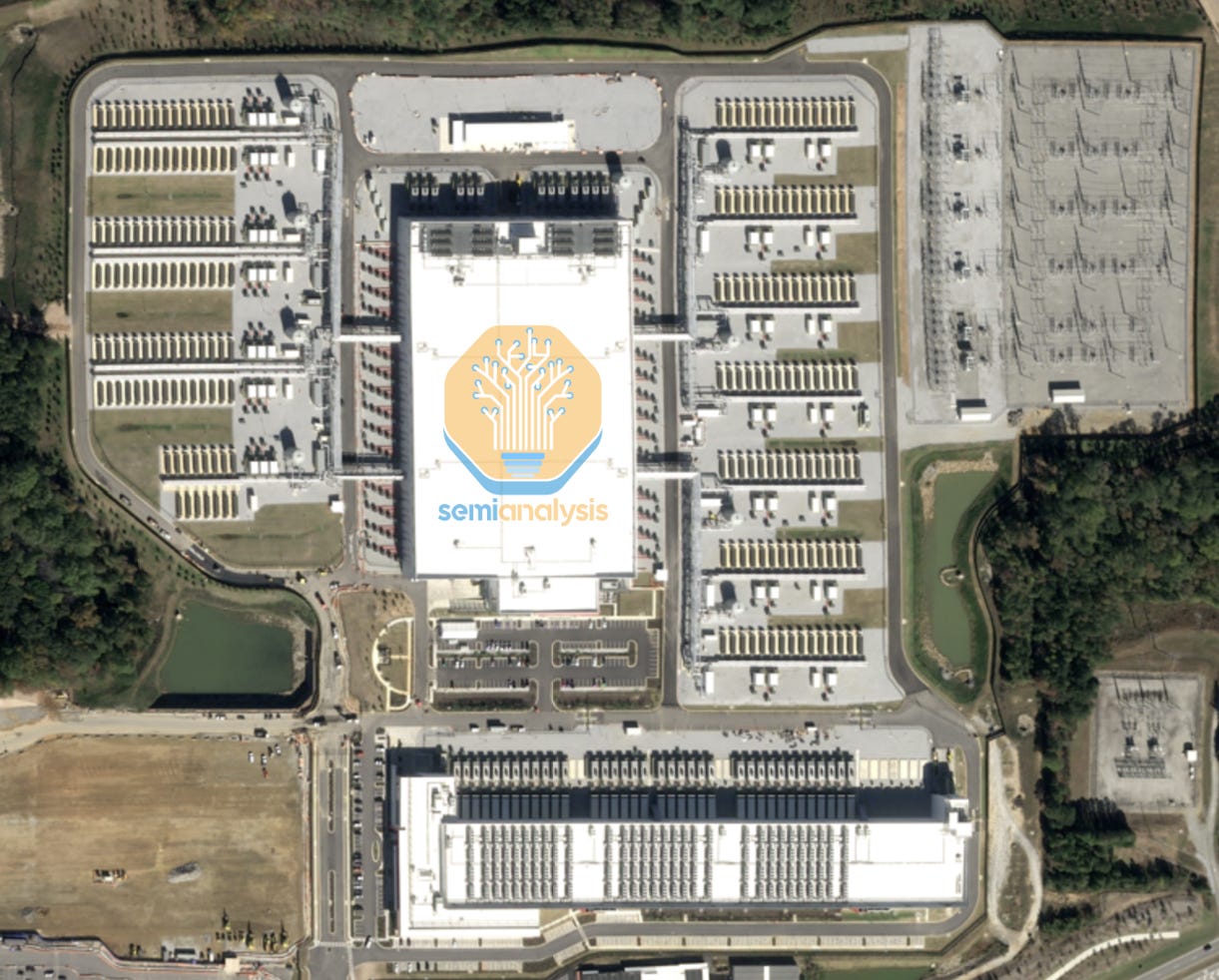
Not only are individual buildings the largest on Earth, they sit in even bigger campuses. In Atlanta, a second Fairwater is already well under construction.
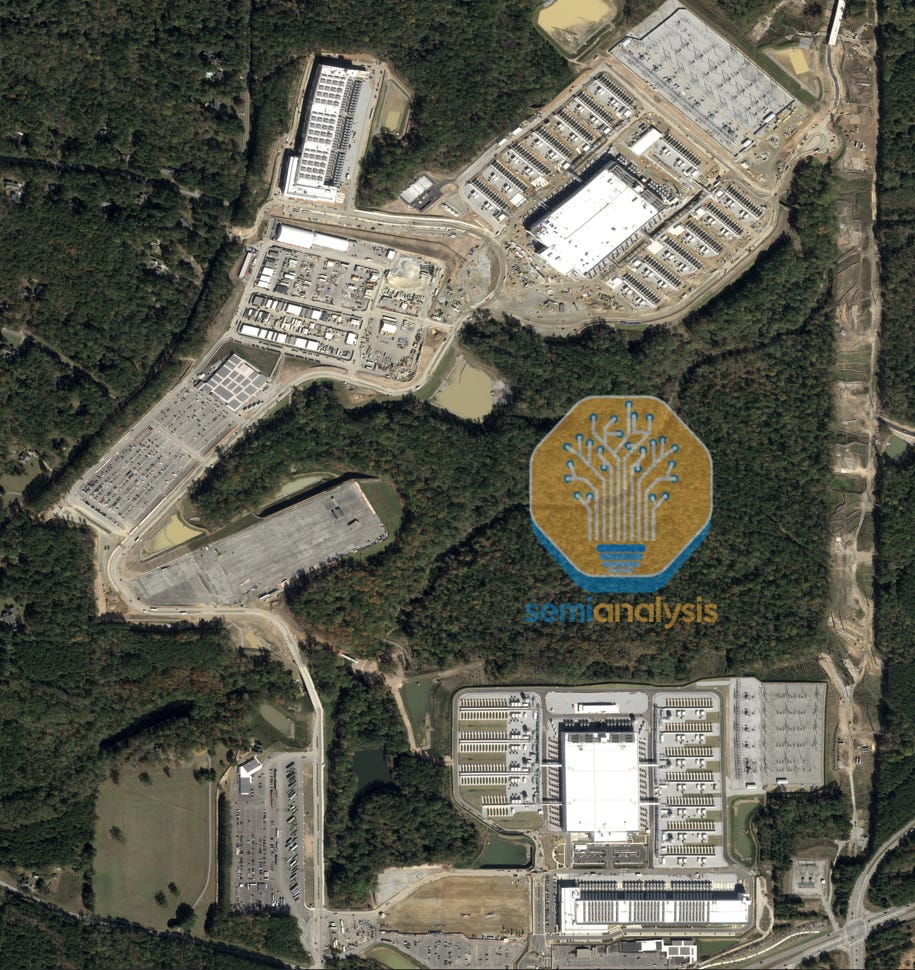
In Wisconsin, while a second Fairwater will imminently start construction, there’s more to the story as Microsoft is preparing for an even larger 3rd phase. We believe Microsoft designed two >600MW individual buildings, with each facility having 2x the amount of CPU/storage and diesel generators, relative to a standard ~300MW Fairwater. We show below the site plan associated with these 600MW buildings. These would be the largest individual datacenters in the world if they are built on time.
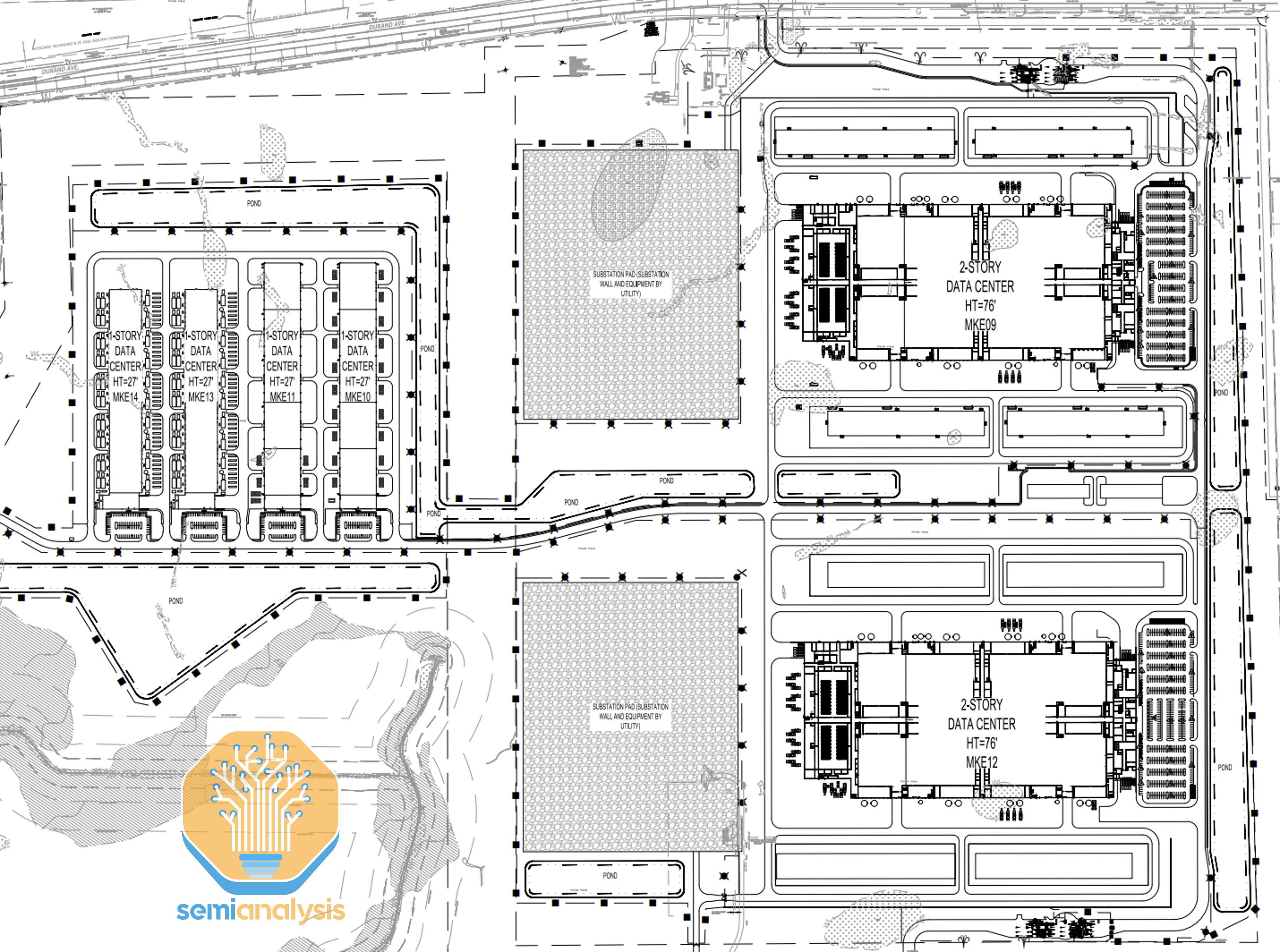
At full buildout, this will be one of the world’s largest campuses, with over 2GW of IT capacity.
Cherry on top of the cake, Microsoft planned all these major AI regions to be connected via an ultra-fast AI WAN, at over 300Tb/s with an ability to scale to above 10Pb/s. We called that out over a year ago in our piece “Multi-Datacenter Training: OpenAI’s Ambitious Plan To Beat Google’s Infrastructure”.

We show below a representation of the network design for a hypothetical 5GW distributed cluster. We will discuss all aspects of the Fairwater networking architecture later in the report, building on our AI Networking Model.
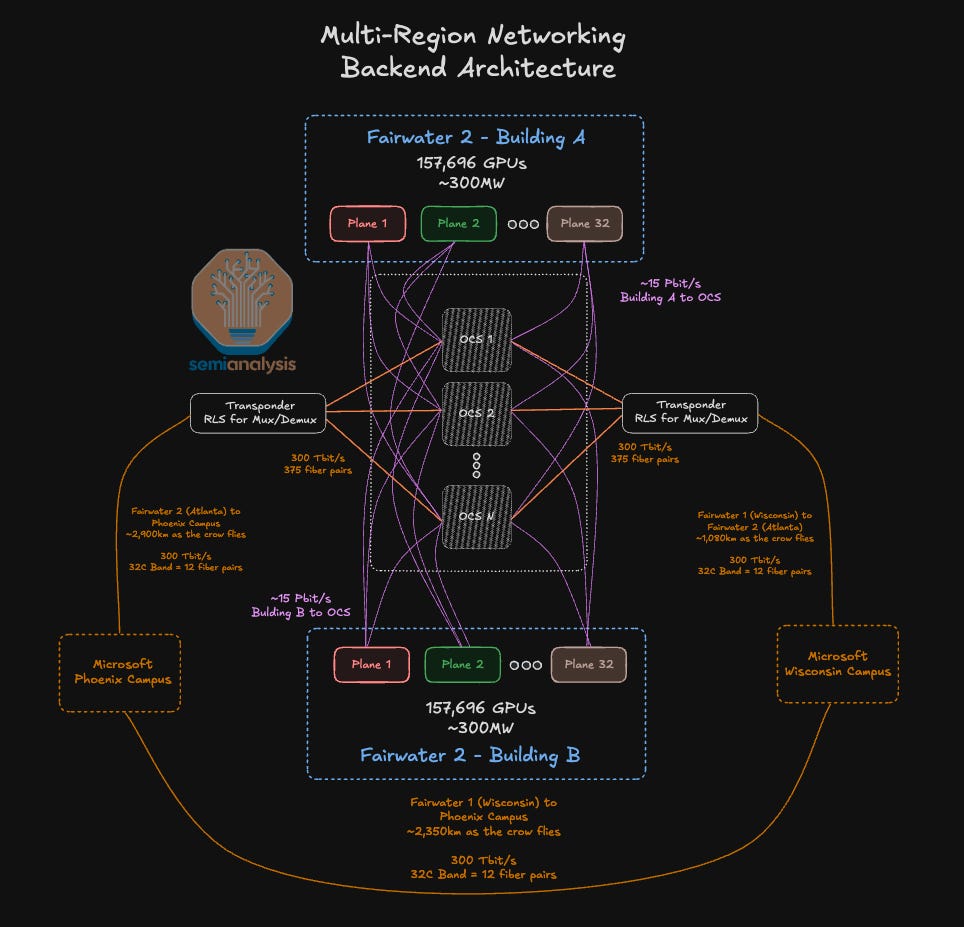
The Multi-Gigawatt “pause”
After firing on all cylinders, Microsoft suddenly decided to hit the brakes– in a spectacular fashion. Looking at total datacenter pre-leased balance, Microsoft alone was over 60% of leasing contracts at peak! But new leasing activity froze after Q2’24 (calendar) while other hyperscalers materially picked up. Microsoft is now below 25% of the total hyperscaler pre-leased capacity.
At that time, Microsoft also dropped out of multiple gigawatts of non-binding LOIs, in multiple locations such as:
Major US markets, such as Phoenix and Chicago.
Major European markets, including the UK and the Nordics, among others.
In the rest of the world, Microsoft’s pause impacted Australia, Japan, India, as well as LatAm.
These sites went to other major competitors such as Oracle, Meta, CoreWeave, Google, Amazon, etc. Microsoft forever ceded a large percentage of AI Infrastructure away due to tepidness and a lack of belief in AI.
In addition, Microsoft also materially slowed down its selfbuild program. We show some pictures below, listing ~950MW of “frozen” IT capacity. This doesn’t include multiple other datacenters in Virginia, Georgia, Arizona, as well as internationally.



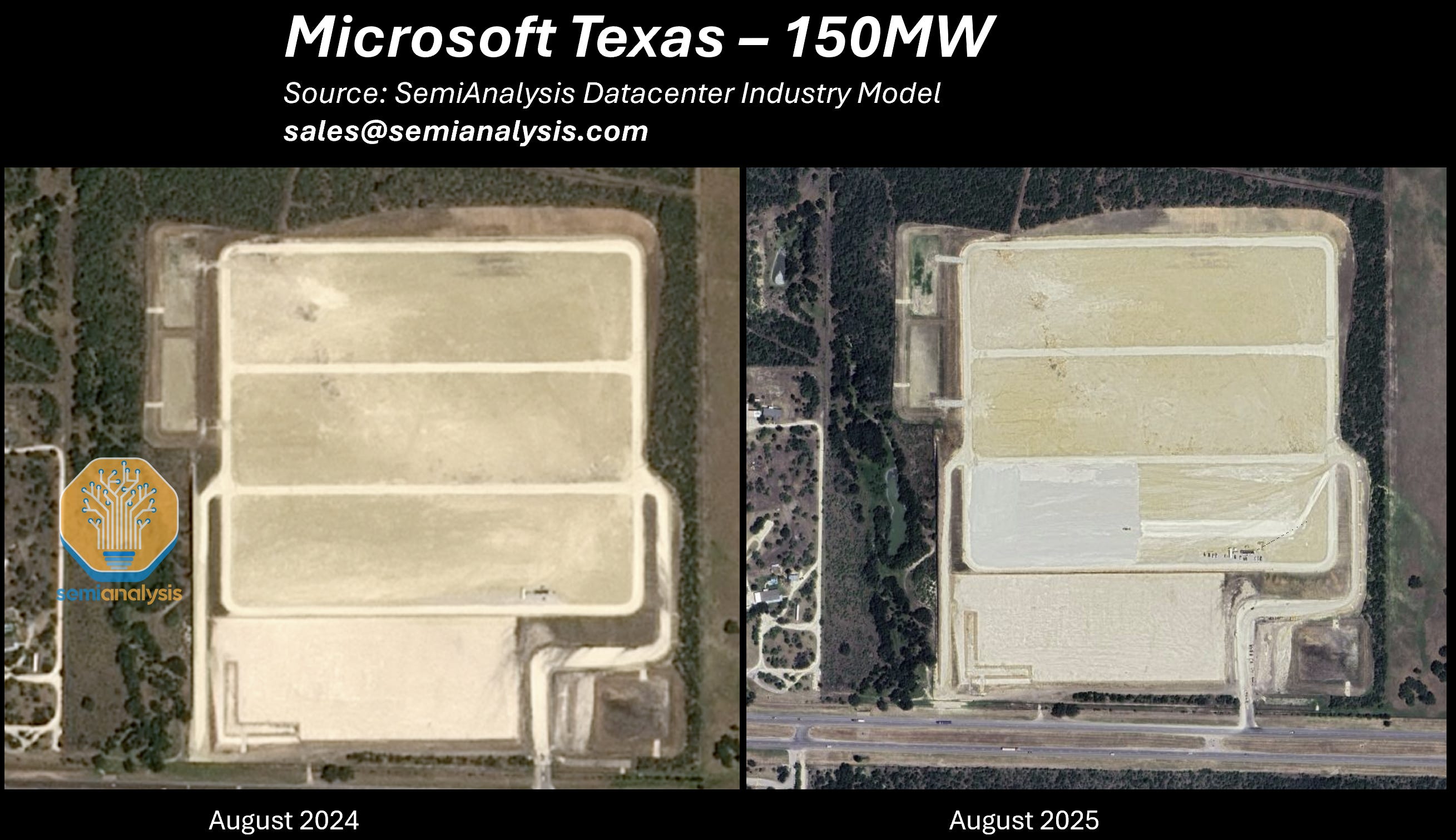
In the same time frame, major datacenters from other players went from ground broken to running workloads. In total Microsoft paused over 3.5GW of capacity that would have been built by 2028. The details are in the datacenter model.
Microsoft’s AI portfolio decomposed: IaaS, PaaS, Models, Applications
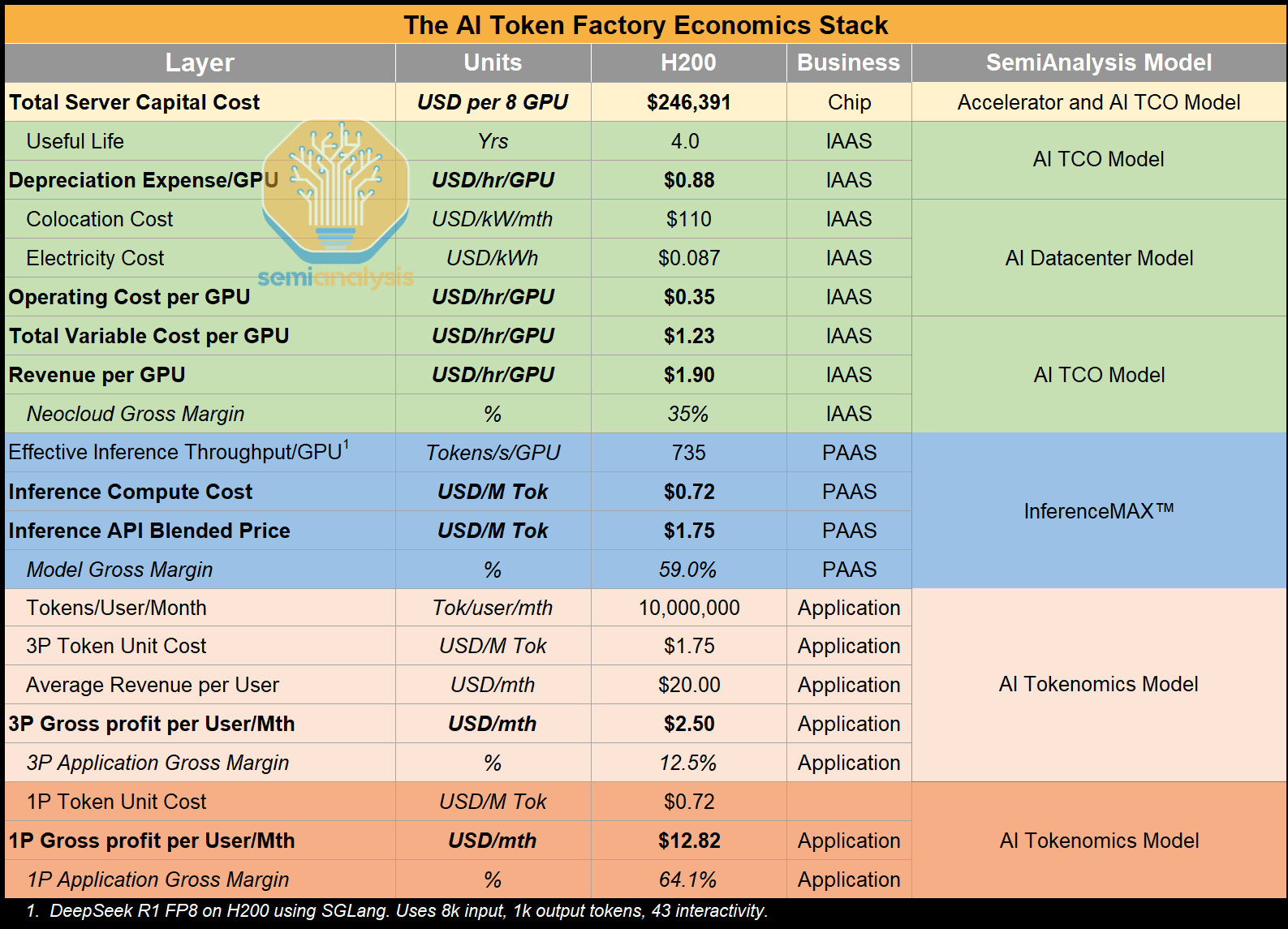
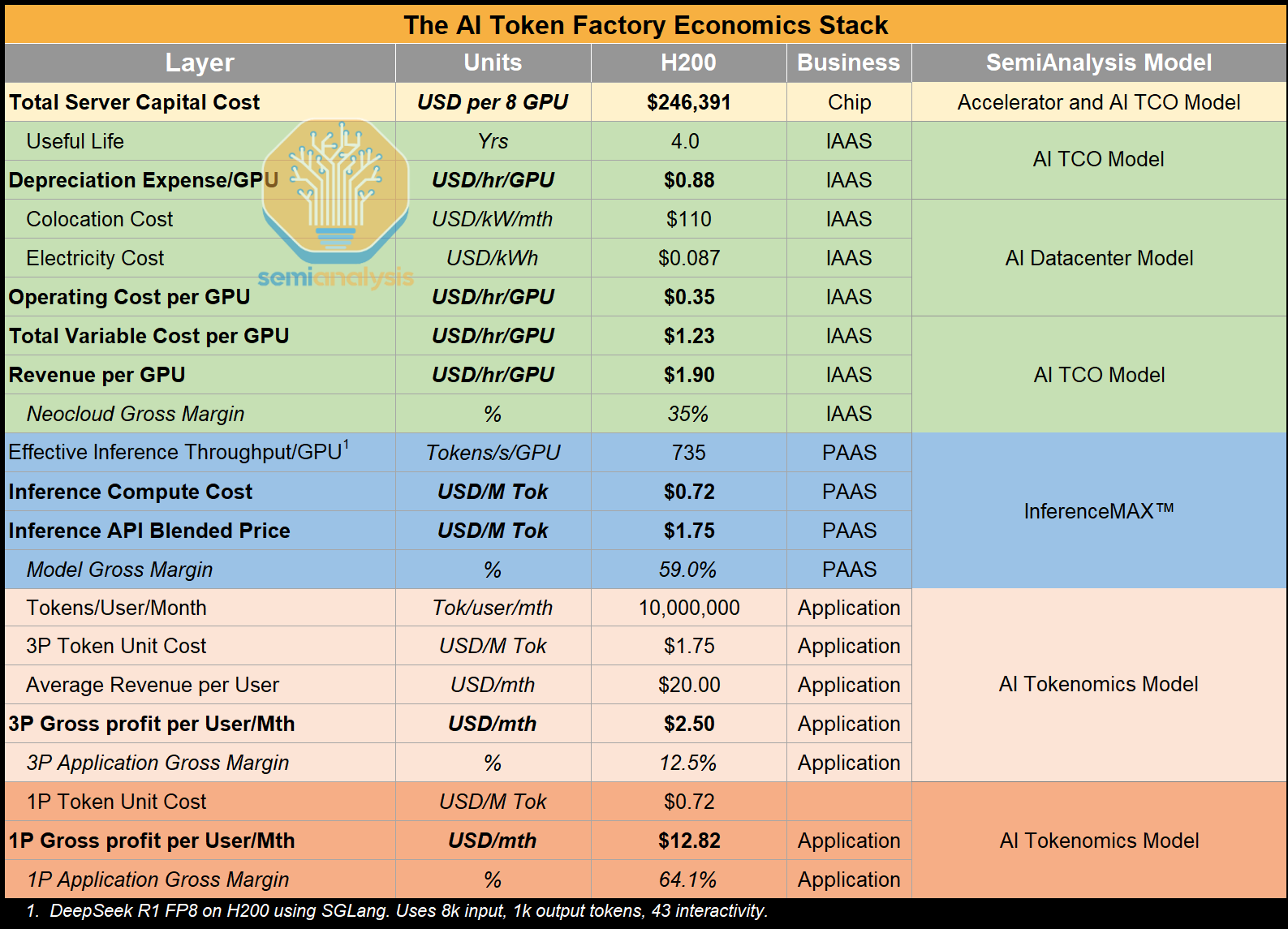
To understand the causes and consequences of the Big Pause, let’s dig into all parts of Microsoft’s AI portfolio. Our preferred framework to analyze the margins at different layers is our “AI Token Factory Economics Stack”:
From chip to tokens, a broad range of suppliers are exposed to the AI infrastructure buildout.
Currently, the single largest margin stack is, of course, at the chip level driven by Nvidia’s 75% GPM
There remain intense debates on the end-state margin profile of the following four layers:
Application layer (e.g. ChatGPT, Microsoft Copilot, Claude Code…)
Model layer (e.g. Claude 4.5 Sonnet, GPT5-Pro, DeepSeek R1,…)
IaaS layer (e.g. Coreweave renting a bare-metal GPU cluster to Meta, Oracle renting GPUs to OpenAI, Nebius renting SLURM and K8s in a multitenant cluster to startups…)
PaaS layer (e.g. AWS selling tokens to a Fortune 500 enterprise via Bedrock, Nebius selling a fraction of a GPU cluster to a startup with SLURM and K8s…)
At the current pricing today, we see leading model makers making 60%+ margins on their direct API business
Azure’s AI Bare Metal services – stepping away from $150B of OpenAI Gross Profit dollars, poor execution and ROIC concerns
Successful players in the business of building massive Bare Metal GPU/XPU clusters have mastered the art of constructing large-scale infrastructure. It is a mix of various ingredients such as speed of execution, understanding of the market and end-user requirements, site selection, and financing, among other things.
Our deep dive on Oracle called out their material strategic change to win over the market. Outside of tech giants, Coreweave is a case-study of a player with no initial scale, winning over the market by executing perfectly on the above criteria. Let’s now look at Microsoft’s execution.
Disappointing execution, loss of the Stargate contract
To gauge Microsoft’s bare metal efforts, it is useful to dig into the Fairwater projects. Early in 2024, rumors swirled around Microsoft’s $100 billion “Stargate” project for OpenAI. We believe they planned to host the cluster at the Wisconsin datacenter campus. As discussed earlier, the roadmap would’ve taken the site to over 2GW of capacity.
Of course, the first Stargate $100B contract ended up going to Oracle and Abilene, TX. Microsoft’s slow execution played a key role, in our view. Over two years after breaking ground, Phase 1 is still not operational. By contrast, Oracle broke ground on its Abilene, Texas datacenter in May 2024 and begun operations in September.

We also believe Microsoft poorly planned the 1.5GW expansion. Full capacity is slated for at least mid-2027 delivery from a power transmission standpoint, one year after Oracle’s Abilene cluster breaks the 1GW mark. Microsoft couldn’t keep up with OpenAI’s request to scale as fast as possible – demonstrating a misunderstanding of the market. The AI lab had no option but to look for other partners to serve its insatiable need for near-term compute.

Stepping away from $150B of OpenAI Gross Profits
As we know today, Oracle has become OpenAI’s main GPU partner. They’ve signed over $420B of contract value over the last twelve months, translating into ~$150B of gross profit dollars, detailed modeling is available in the AI TCO model for every Neocloud compute contract and their cost / margin breakdown.
Given typical 5-year duration, the $30B of annual gross profits would’ve increased Microsoft’s $194B of annual gross profits (FY25) by over 18%. To be fair, the loss of the OpenAI contract is not just about execution. It’s also, to some extent, a conscious decision. From Microsoft’s perspective, landing all OpenAI contracts would have deteriorated the quality of their Azure business, since:
OpenAI would’ve represented close to 50% of Azure’s revenue within a few years.
The margin and return on capital profile aren’t nearly as attractive as Azure’s historical Cloud profile.
Compared to Microsoft’s overall business, Oracle AI ROIC is indeed lower coming in at 20% vs overall 35-40% today for total MSFT. However, we see that Microsoft’s own AI ROIC is not much higher than ORCL’s once you strip out the revenue share from OpenAI which is set to end between 2030-2032.
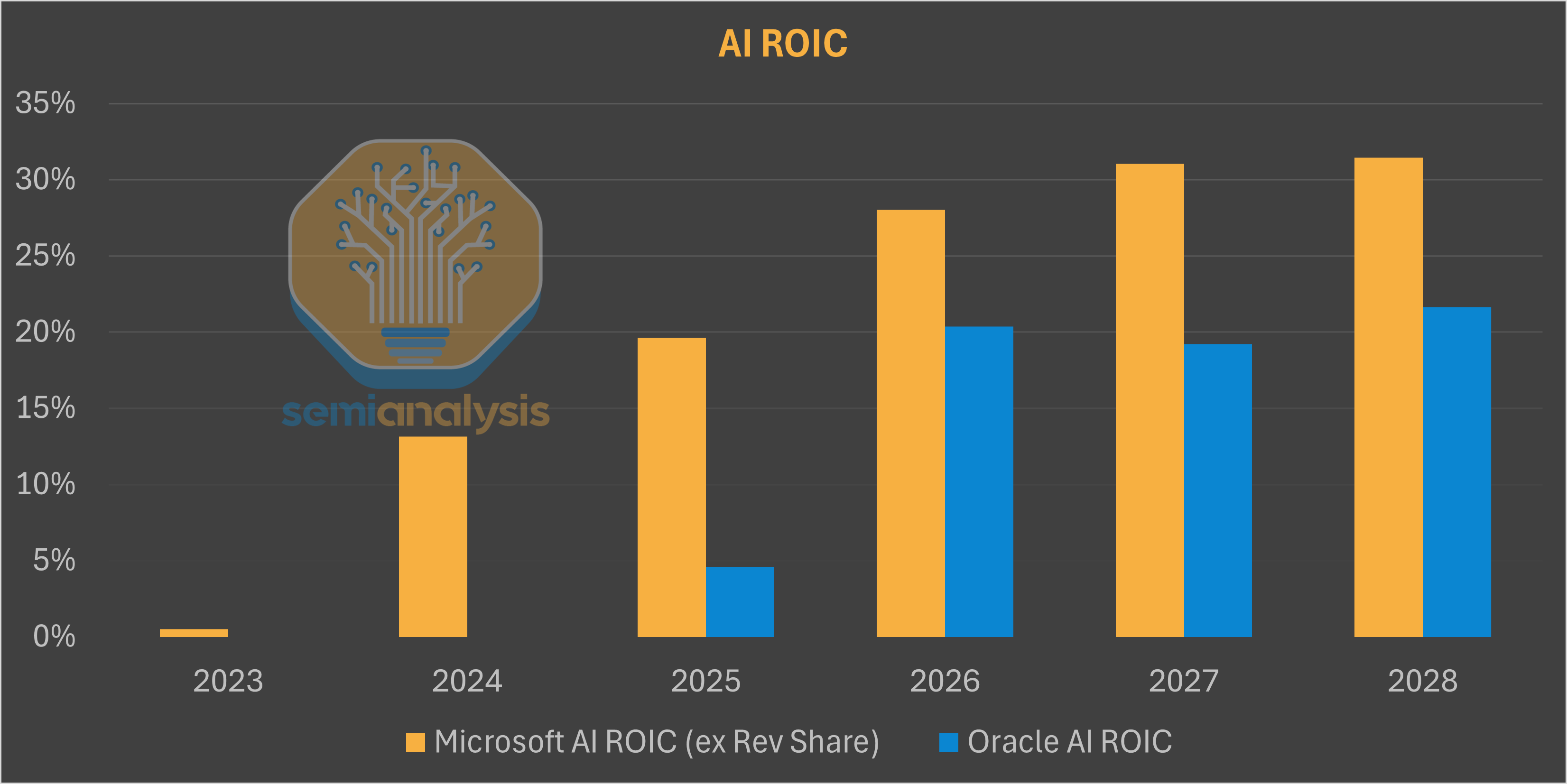
However, Microsoft seems to be forgetting their own recent history lesson as they moved from a very heavy bare metal workload AI revenue composition towards more API and token-factory business model, resulting in continuous gains in their ROIC profile. They potentially have just allowed a competitor to fund their own entry into the AI factory business!
For a comprehensive model of the economics of OpenAI, Oracle and Microsoft, refer to our industry-first Tokenomics Model. Built on top of our Datacenter and Accelerator tracking, Tokenomics tracks every single major compute contract and unpacks all relevant financial metrics: growth, profits, ROIC, funding, and much more.
Underestimating demand, RPO share loss, desperate need for Neocloud capacity
A key lesson from Microsoft’s Pause is how much they underestimated the scale of XPU Cloud demand coming from other players, such as Meta. We are currently witnessing the impact of their miscalculation. Other players have been booking materially more RPO than Microsoft.
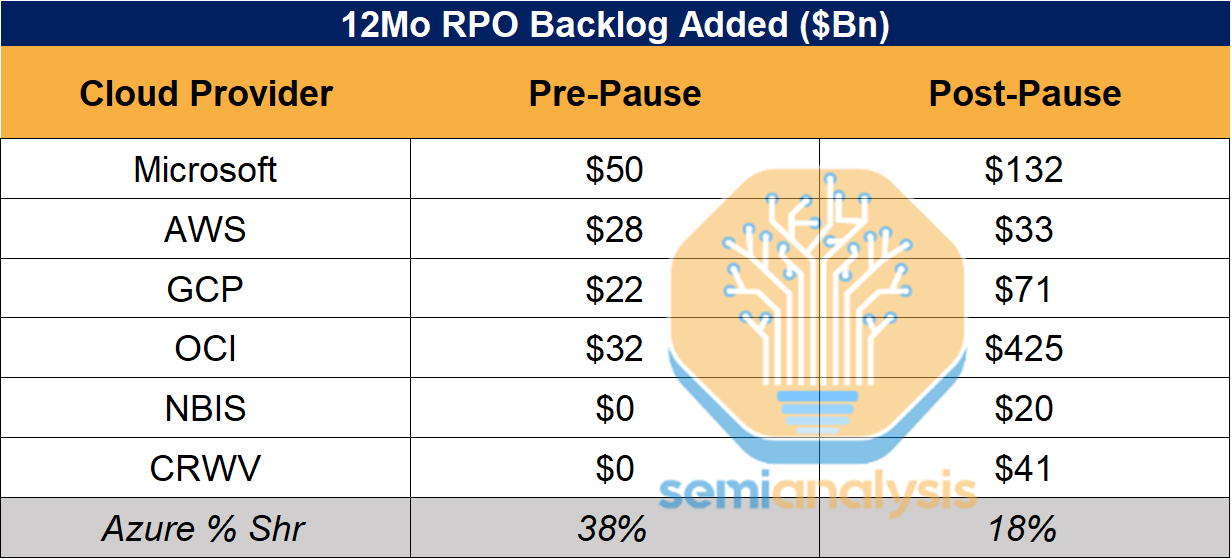
Microsoft is now firmly back to the market, but they’re running out of options to expand near-term capacity. They’re force to go with the worst option: renting GPUs from Neoclouds and reselling that to 3rd parties, either as bare metal or tokens through Foundry. We’ll discuss Foundry below. Of course, the business of renting bare metal to resell bare metal will yield a materially lower-than-usual margins for Azure.
Microsoft shunned away building their own DCs, only to pay margin to neoclouds when they realized they messed up.
PaaS layer – Not All GPUs Are Deployed Equally
Gold-rated cloud… at risk of downgrade
In ClusterMAX 1.0, released in March of this year, we discussed how Azure was leading the way on networking performance security, and availability of the latest GPUs, and had already captured the lions share of OpenAI’s compute buildout. This put them clearly in the Gold tier of our rankings, right behind CoreWeave and next to companies like Nebius, Oracle, and Crusoe. However, by the time ClusterMAX 2.0 rolled around in early November, it has become clear that the pace of development for new CycleCloud and AKS features targeting AI workloads has stagnated.
In our research talking to 140+ buyers of compute from scaled-up AI companies such as OpenAI, Meta, Snowflake and Cursor to startups like Periodic Labs, AdaptiveML, Jua, Nous Research, DatologyAI and Cartesia, it is clear that Azure is not a significant player for managed clusters or on-demand VMs. Azure’s GPU capacity for large scale clusters seems to go straight to OpenAI, with the leftovers being gobbled up by individual developers at legacy businesses in the Fortune 500. These companies that love working on internal RAG chatbots typically have enterprise agreements in place to purchase all their IaaS exclusively from Azure.

During our hands-on testing the reason why Azure is not selling managed slurm or kubernetes clusters for AI is clear: we found significant gaps in ease of use, monitoring, reliability and health checks on CycleCloud slurm clusters. The wholesale bare metal experience that Azure provides OpenAI when they are renting out entire data halls at a time is very different from what a provider like CoreWeave, Nebius, or Fluidstack gives to their end users.
The typical GPU compute buyer in the industry is still looking for H100, H200, B200, or B300 HGX servers on the scale of 64 to 8,000 GPUs. It is much less common for a buyer to look for GB200, GB300, or anything from AMD. However, Microsoft has invested enormous amounts of time and attention into AMD GPUs and GB200/GB300 NVL72 rack scale systems for their largest customers (aka OpenAI). You can measure this in terms of OPEX on engineers salaries or CAPEX on GPU purchases and new facilities.
An additional way to look at this is via the open source community. According to Hugging Face, the de facto place for any company to publish and download open source models, IPs associated with Microsoft represent 5x less daily model downloads when compared to Amazon, and 3x less when compared to Google.
Microsoft shoo’ed away the OpenAI business, but its not like they are capturing enterprises or long tail. They are significantly behind the other hyperscalers on this metric.
The result of all of this is clear: AI companies who are actively looking for capacity are looking elsewhere. This can range anywhere from a 1y 64-GPU contract valued around $1M all the way up to 3y 8000-GPU contracts valued at over $500M. We are seeing startups who bought 256 H100 in March look for 9,000 GB300 NVL72 in November. Right now, Azure is missing out on all of this upside.
To address this customer base, we believe that Azure must re-vamp its CycleCloud and AKS offering for AI, simplifying the current cluster deployment and monitoring experience. They need to build health checks, deploy them to clusters by default, and proactively recover from hardware failures. And they need to build the GTM and support organizations full of people to deliver these clusters to end users. We mentioned in ClusterMAX 2.0 that Azure is at risk of being demoted to Silver due to its poor user experience for startups from Series A to AI unicorns.

“Fungible fleet” and Sovereign AI – a bet on the direction of inference workloads
With that said, Azure clearly has a foundation built for success. They have 70 regions with over 400 datacenters globally. They run the biggest SaaS business ever seen, with experience selling to the largest organizations all over the world: from “Azure Government Secret” for US intelligence agencies to Windows PCs for consumers in China.
Key to Azure’s strategy is to bring AI closer to the enterprise customers, by having a broad geographical footprint. This is a directional bet on the future shape of AI workloads:
Today’s largest inference use-cases, namely ChatGPT and coding agents, are not latency-sensitive, will become increasingly less so as time horizons keep increasing. They also don’t interact with sensitive enterprise data, for the most part. As such, latency and data locality don’t matter much – the name of the game is ramping up capacity as fast as possible to sell more tokens to the world.
In the future, enterprise use-cases will likely be a large source of growth. They’ll have to comply with high security, data locality laws, and typical environments & constraints favored by large enterprises. They’ll also be co-processed with non-AI workloads, e.g. Cosmos DB storage in a specific Azure region. The drawback is that the datacenter site selection process is more complex, due to power constraints impacting most major metros in the world. They won’t be able to ramp as fast, relative to others building in “middle-of-nowhere” locations with excess power.
Constructing and leveraging a global footprint is key to Microsoft’s leitmotiv of building a “fungible” fleet. They’ve already seen some success. For example ByteDance Seed trains their video models in Arizona USA, not China or Malaysia. We believe ByteDance Seed rents from all major US hyperscalers on American soil. While this run was on a competitor, it shows some fungibility is not necessary.
That infrastructure strategy is quite different from that of leading AI labs like OpenAI. Given the most power-intensive workloads take several minutes to respond (e.g. Deep Research, reasoning models), adding a few milliseconds of networking latency is irrelevant to them.
As the time horizon of AI tasks extends, the locality to the user matters less and less.
The datacenters can be placed wherever possible and serve global traffic. This is further driven by the fact that post-training workloads are quickly increasing in compute, which are similarly latency insensitive and do not necessitate large amounts of centralized compute.
Depreciation Schedules and the Future of GPUs in Azure
If you are to crack open this fungible fleet, an important consideration is found. One that has received a lot of coverage lately. Namely: depreciation.
The infamous Michael Burry recently claimed that all hyperscalers (Meta, Google, Oracle, Microsoft, Amazon) are artificially boosting earnings by extending the useful life of their IT assets. This boost has moved the “useful life” from 3-5 years back in 2020, to 5-6 years in the present day.
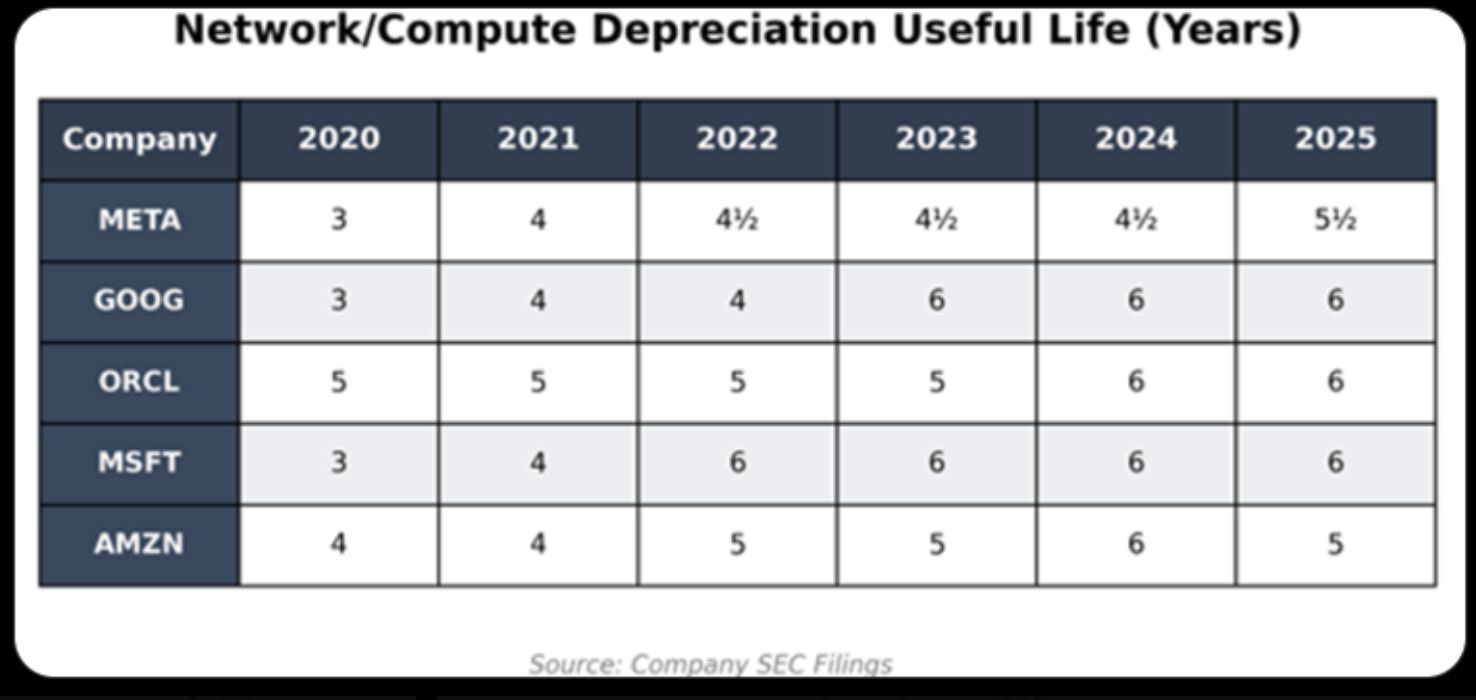
Dr. Burry’s claim is predicated on an assumption that the NVIDIA product cycle is now 2-3 years, which is far lower than the useful life of the assets. We believe this is a fatal flaw in the argument. The new accounting, while beneficial to the companies in the short-term, is also predicated on real operational experience in datacenters.
Back in 2020, when Microsoft, Meta, and Google increased the useful life from 3 to 4 years, we were still in the year 2 BC (Before ChatGPT). Now, in present-day 3 AD (After Da Launch of ChatGPT), the increases in useful life have proved beneficial to CAPEX-hungry hyperscalers. What began changing in IT equipment in 2020 that has continued through to 2025? The answer is reliability, and incentives.
Server OEMs such as Dell, SuperMicro, HPE, Lenovo, and Cisco have long sold servers with a standard warranty between 3 to 5 years in length. The 5 year warranty is more expensive, of course, but many extended warranty options exist for 6 and 7 years. The price goes up of course, but all it takes is the vendor stocking enough spare parts to make service calls on worn out nodes. Meanwhile, networking equipment vendors such as Cisco, Arista, Aruba and Juniper have experimented with lifetime warranty on their switches. Storage vendors have offered the same - just pay a yearly support contract and they’ll keep swapping worn out drives. Think of it like a car: the high end of the market might lease and upgrade their Benz every 2 years, while others drive their 20 year older beaters for the price of gas and insurance.
The point is proven when looking at the largest HPC clusters and Supercomputers in the world. These leading edge systems run the biggest, baddest, hottest (and sometimes most efficient) processors on the market. Supercomputing centers were the first to adopt liquid cooling, and have experience building a datacenter around the system, rather than fitting a system into a datacenter.
IBM Summit at Oak Ridge National Laboratory was for a long time the world’s fastest supercomputer on the Top500. It went into production in June 2018, and was decommissioned in November 2024 after 6.5 years of continuous operation. Summit used IBM Power9 processors that were launched in 2016, with the procurement being completed as far back as 2014.
Fugaku was installed at RIKEN in Japan in 2020 and is still running, sitting at #7 on the Top500. Sierra was installed at LLNL in 2018 and is still running, sitting at #20. Sunway TaihuLight was installed in 2016 in the National Supercomputing Center in Wuxi, China. It is still running and sits at #21. Exascale systems like El Capitan, Frontier, and Aurora (#1, #2, and #3 on the list respectively) went into service anywhere from 2021-2025, and are expected to run until 2027-2032.
Finally, Eagle - Microsoft NDv5 featuring 14,400 H100 was installed in 2023, and is sitting at #5. We expect this system is highly utilized and will be running for years to come.
Turning to current cloud providers, we can find p3.16xlarge for sale in AWS with 8x V100 GPUs. We can find similar instances available through marketplaces like Shadeform, Prime Intellect, and Runpod, from underlying providers such as DataCrunch, Paperspace, and Lambda Labs.
V100 was announced in May 2017, with volume shipments happening in the fall of 2017, and final product shipments from NVIDIA occurring in January 2022. In other words, NVIDIA shipped spare parts for over 5 years from the time they launched the new GPU. Hyperscalers and OEMs had plenty of time to stock their spares, and keep instances running through to the present day - a full 8 years after those V100 GPUs started shipping.
Of course, V100s today aren’t a great business on a pure revenue-per-MW basis. So much so that we are aware of hyperscalers ripping out V100, A100, and even older H100 GPUs from their older datacenters in order to make room for the latest and greatest. The point is not that they are doing this because the GPUs are wearing out and dying of old age. Rather, they are ripping out revenue-generating assets in favour of higher-revenue-generating-assets due to power and floorspace constraints.
Key to optmizing GPU Cloud economics is to maximize their economic life. Our AI Cloud TCO Model provides a useful framework. Analyzing the TCO of a H100 cluster, we see that after stripping capital costs, there remains operating costs of $0.30-0.40/GPU/hour. The question is whether, after 5 years, a GPU can still monetize above that rate.
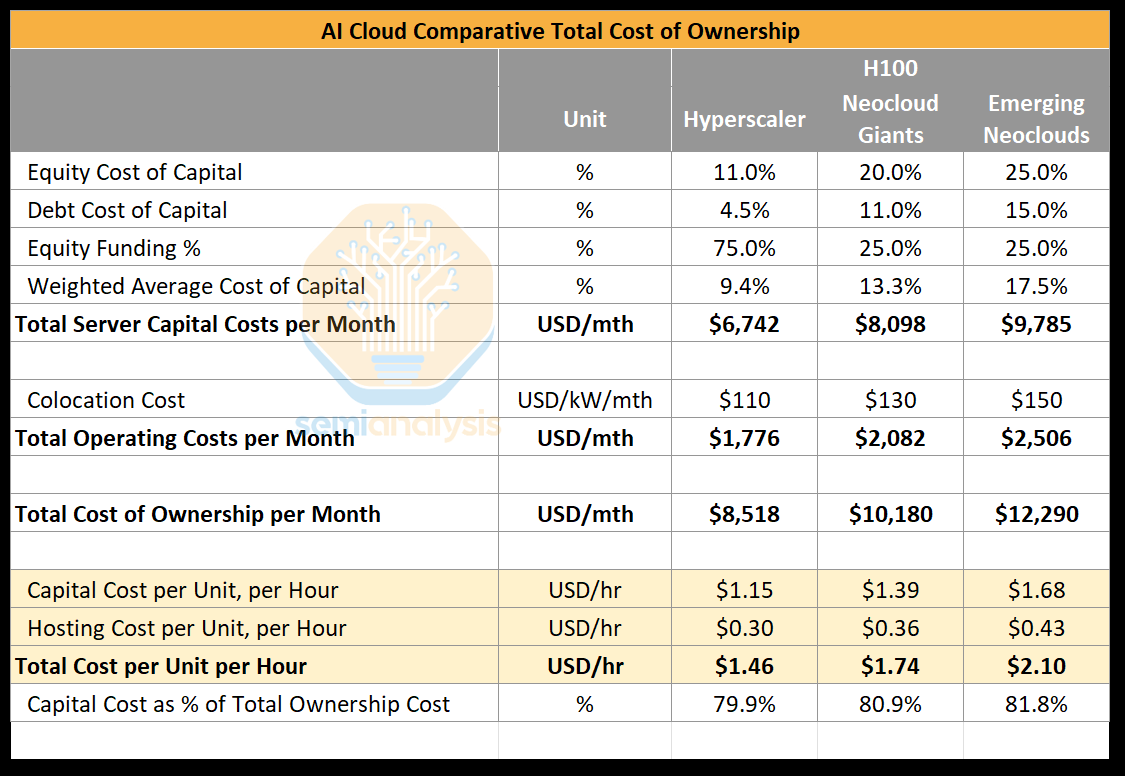
That operating cost has to be matched against the revenue extracted per GPU. Naturally, GPU pricing power fades rapidely, as Nvidia releases new chips that materially increase throughput per dollar and throughput per watt. Our AI Cloud TCO Model, trusted by most of the world’s largest buyers of GPUs as well as their financial sponsors, provides long-term rental pricing forecast for all Nvidia, AMD, TPUv7 & v8 and Trainium2 & 3 SKUs - in addition to detailed cluster bill-of-materials analysis.
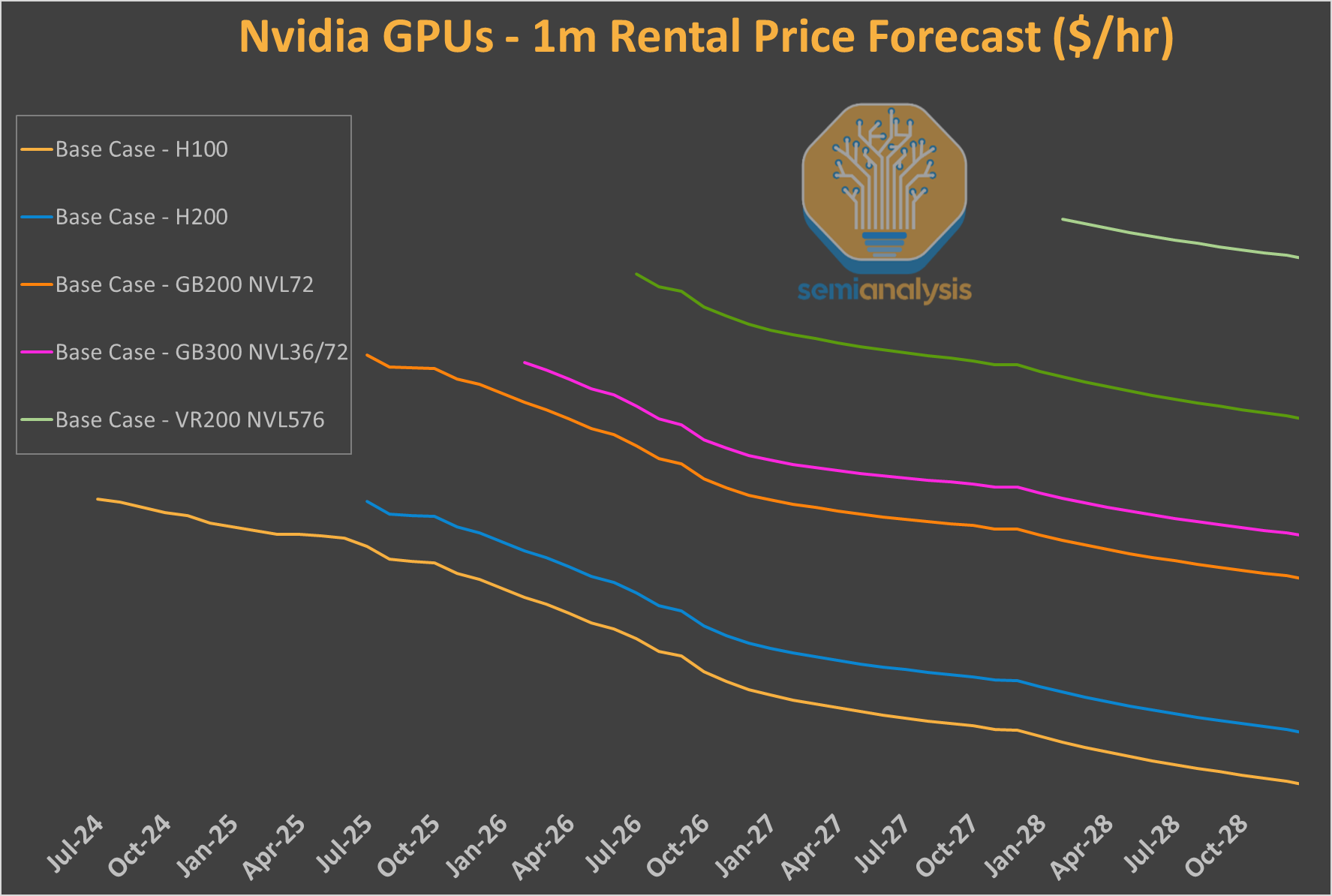
Our historical hit rate has proven remarkably accurate! But from the perspective of companies like Azure, the goal is to have a higher pricing power relative to the broad market. It remains uncertain, but could play out in multiple ways:
By leveraging their enterprise relationships, PaaS layers and vertical integration (apps, models, tokens, etc), Azure might be able to extract enough value out of 6-year old GPUs to avoid early decomissioning.
Another path, also related to the enterprise business, is to upsell higher-margin services (e.g. non-AI, such as database) alongside accelerated compute. Even if the 6-year-old GPUs aren’t generating profits on a standalone basis, if they happen to be the reason for an upsell of higher margin services, it might make sense to keep operating them.
In our view, this is why Azure’s “fungible fleet” strategy could make sense and enable a structurally higher ROIC than other players. The main uncertainty remains the scale of enterprise adoption, and whether Azure will be able to upsell higher value services.
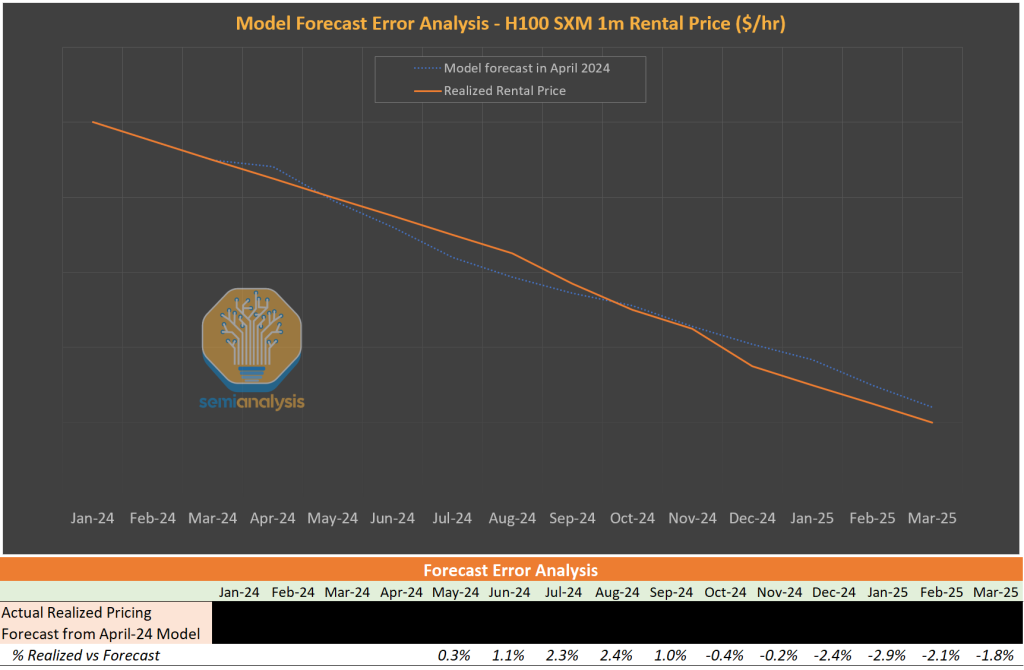
What will the future hold? Will Vera Rubin deliver on performance claims and motivate hyperscalers to rip out perfectly good, revenue generating GPUs after just 2-3 years in service as Dr. Burry claims? Or will we see the bottom of our H100 pricing data hold strong into the future? These questions remain to be answered, but our TCO Model provides our best estimate. Supported by our proprietary testing of GPU Clouds (ClusterMAX) and daily benchmarks via InferenceMAX, we aim to provide the best insights in the market. Our free & open-source InferenceMAX platform shows how system-level innovation, like Nvidia’s GB200 BVL72, can provide orders of magnitude of improvements versus more traditional HGX-based GPUs, for certain use-cases and configurations.
Azure Foundry: the Enterprise Token Factory
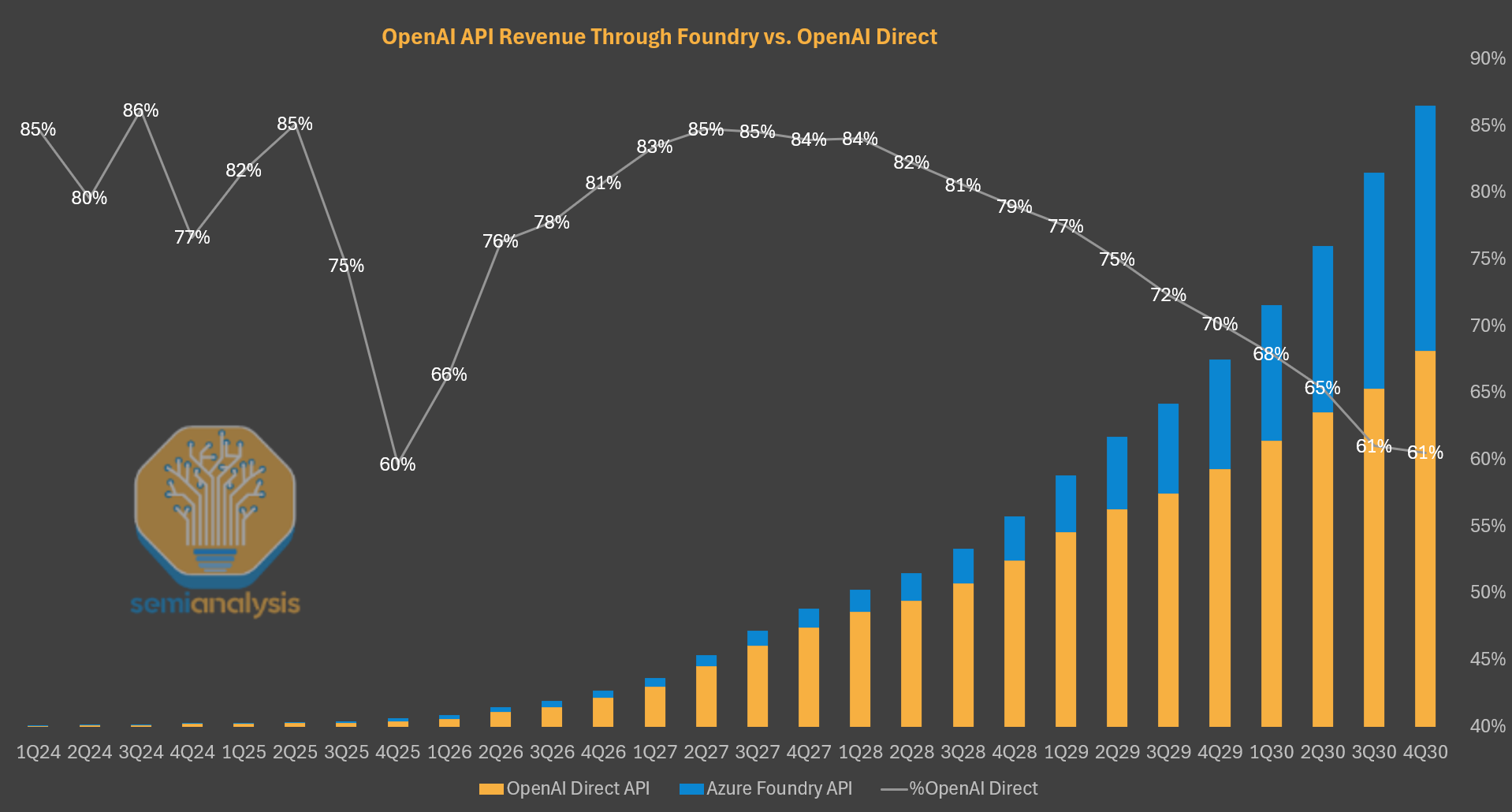
Azure Foundry is Microsoft’s “Token-as-a-Service” business offering a variety of models consumed both internally by services like M365 Copilot and Github Copilot (1P tokens) and externally by customers looking to use a model via an inference endpoint (3P tokens). Azure Foundry goes to market in a similar fashion to OpenAI API, competing for individual and enterprise use cases. Azure can also make independent pricing decisions because of their IP rights to OpenAI model weights.
Currently, the majority of GPT API tokens are processed directly via OpenAI, but we expect Foundry to be a major growth driver for Microsoft going forward and grabbing back some share. Importantly for Microsoft, Azure has 100% share of all API inference compute, regardless of it being served via OpenAI API or Azure Foundry, through 2032.
However, we believe that the business of selling tokens to enterprises remains nascent. Alphabet’s Sundar Pichai gave an interesting disclosure confirming our stance during the Q3’25 earnings call:
Over the past 12 months, nearly 150 Google Cloud customers each processed approximately 1 trillion tokens with our models for a wide range of applications.
This disclosure suggests that sales of Gemini tokens to these 150 enterprises is less than 0.5% of GCP’s business.
Converting tokens to revenue is much more complicated that it might seem. We often see analysts making huge mistakes in areas like input/output ratio, failing to account for cached tokens, or miscalculating pricing. Our Tokenomics Model provides a comprehensive understanding of the economics of generating tokens and translating tokens and watts into revenue, profits, and RPO.
Application layer: GitHub Copilot’s Moat Under Siege
In the application layer for code assistance, Microsoft enjoyed total dominance with GitHub Copilot. Microsoft had the first in-line code model, commonly referred to as “tab” models now, and were early integrating GPT-4 with Copilot given their exclusive IP access.
From afar, Microsoft’s fort seemed impenetrable. They owned VS Code and GitHub, the standard tools for industry, had exclusive access to OpenAI model IP for product development, and an enormous enterprise footprint to sell into.
However, they underestimated the rise of a series of startups forking VS Code to build tighter and improved integrations between models and the codebase which allowed these challengers to collectively scale beyond Copilot. A key enabling factor was the startups’ use Anthropic’s models.
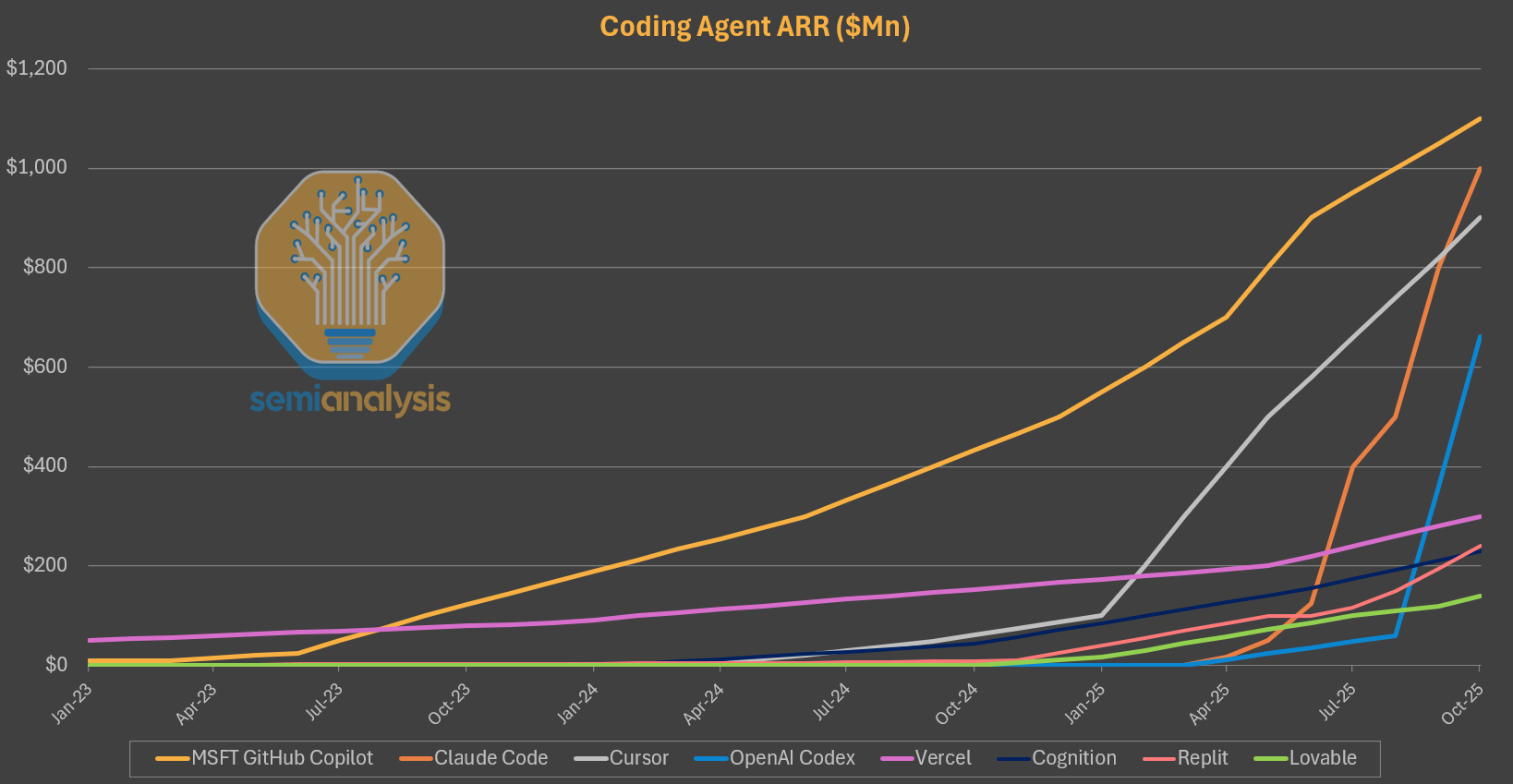
Microsoft reluctantly added Anthropic to the Github Copilot offering in early 2025 at great expense to its margins. Github Copilot went from serving nearly 100% 1P tokens to having to buy a large chunk of its tokens from Anthropic with the associated 50-60% gross margins.
The labs also developed products themselves. Users are bound to one set of models but these models were trained on the harness and environment used in production. This delivered an optimized experience that, as the revenue ramps of Codex and Claude Code show, is very popular.
Microsoft has since doubled down on their model supermarket ecosystem bet, recently launching Agent HQ which plugs into agents from a variety of labs including Google and xAI.

With the timeline on their access to OpenAI model weights extended only through 2032, the company will need a backup plan to their current highest margin OpenAI model offerings.
Microsoft’s homemade models: MAI
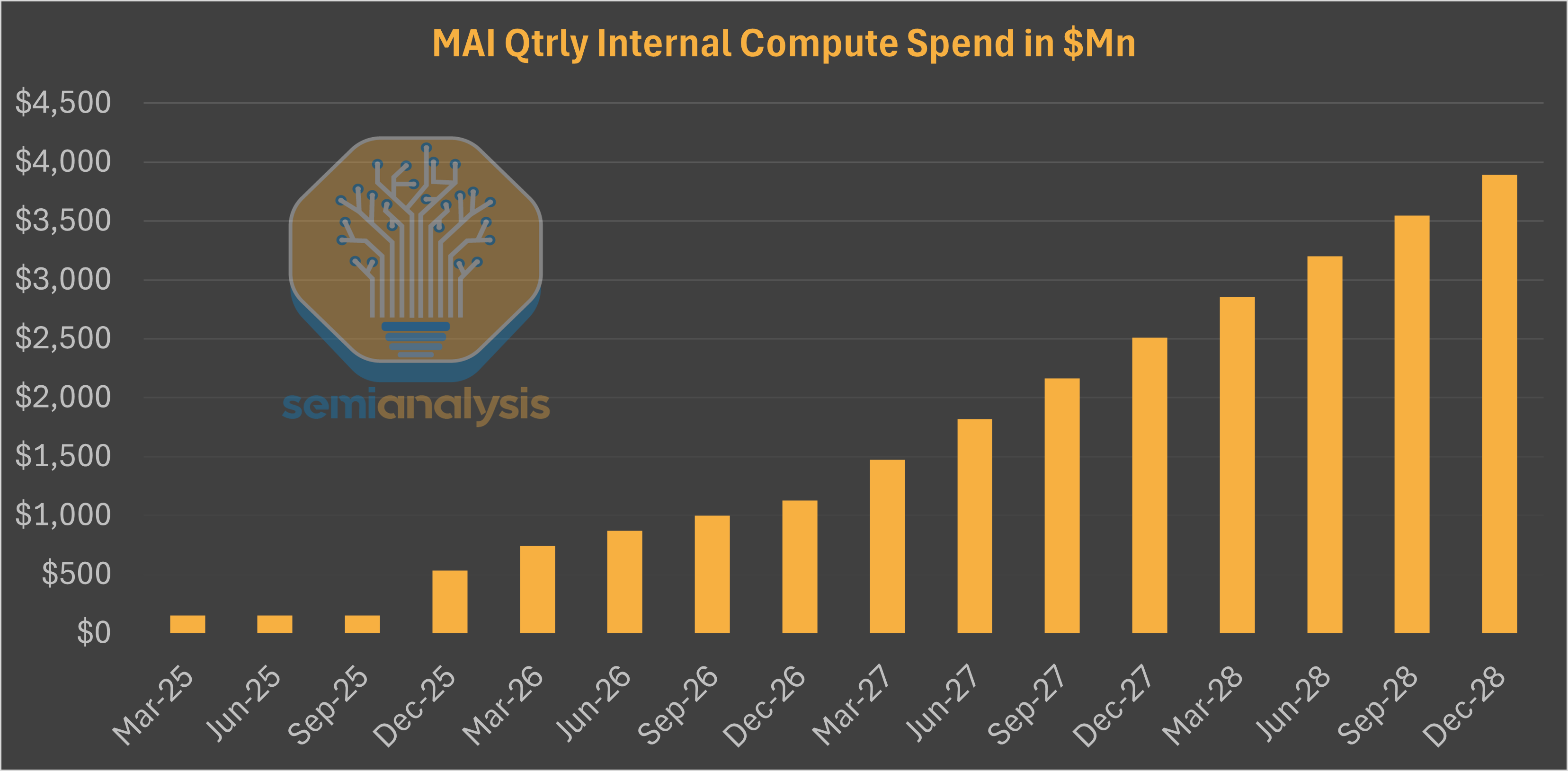
Microsoft has released 3 MAI models across text, images, and voice. The text model, MAI-1 is currently around 38 on LMArena but not yet publicly available either through chat or through API. The model is a large MoE trained on 15,000 H100s and the next model will be a much larger multi-modal LLM.
The other two are image and voice models respectively. The image model is still a top 10 model in LMArena, and both are available in Copilot.
To Microsoft, the latter two models represent a use case where models can be served cheaply and with decent quality. They are far from challenging the state-of-the-art models but we believe the company is quietly gearing up to invest in much larger internal training efforts, scaling to nearly $16Bn of annualized compute spend in the next few years.
Office 365 Copilot
Microsoft Copilot is an overarching umbrella comprising of more than just GitHub Copilot. There are Copilots for Sales, Finance, Service, Security, and others. This umbrella has itself surpassed 100M Monthly Active Users and will be a significant driver of overall AI adoption.
The latest effort to build the Office 365 Copilot is within the Office Agent, and we dive into the Excel one below. The overarching goal of these agents is to take actions across the Microsoft Ecosystem in way that is autonomous, functional, and useful for users.
Microsoft’s edge: OpenAI IP and Office user data
Access to OpenAI’s models, weights, and code base enables Microsoft to distill from the raw Chain of Thought of the OpenAI models. Distillation is more effective than post-training small models, meaning that Microsoft will be able to get significant capabilities without a meaningful compute cost.
Access to the OpenAI IP also enables Microsoft to finetune the OpenAI models with data Microsoft has access to that may be more granular or fundamental than what is externally available to companies building harnesses or environments on top of the Office Suite:
We are absolutely going to use the OpenAI models to the maximum across all of our products.
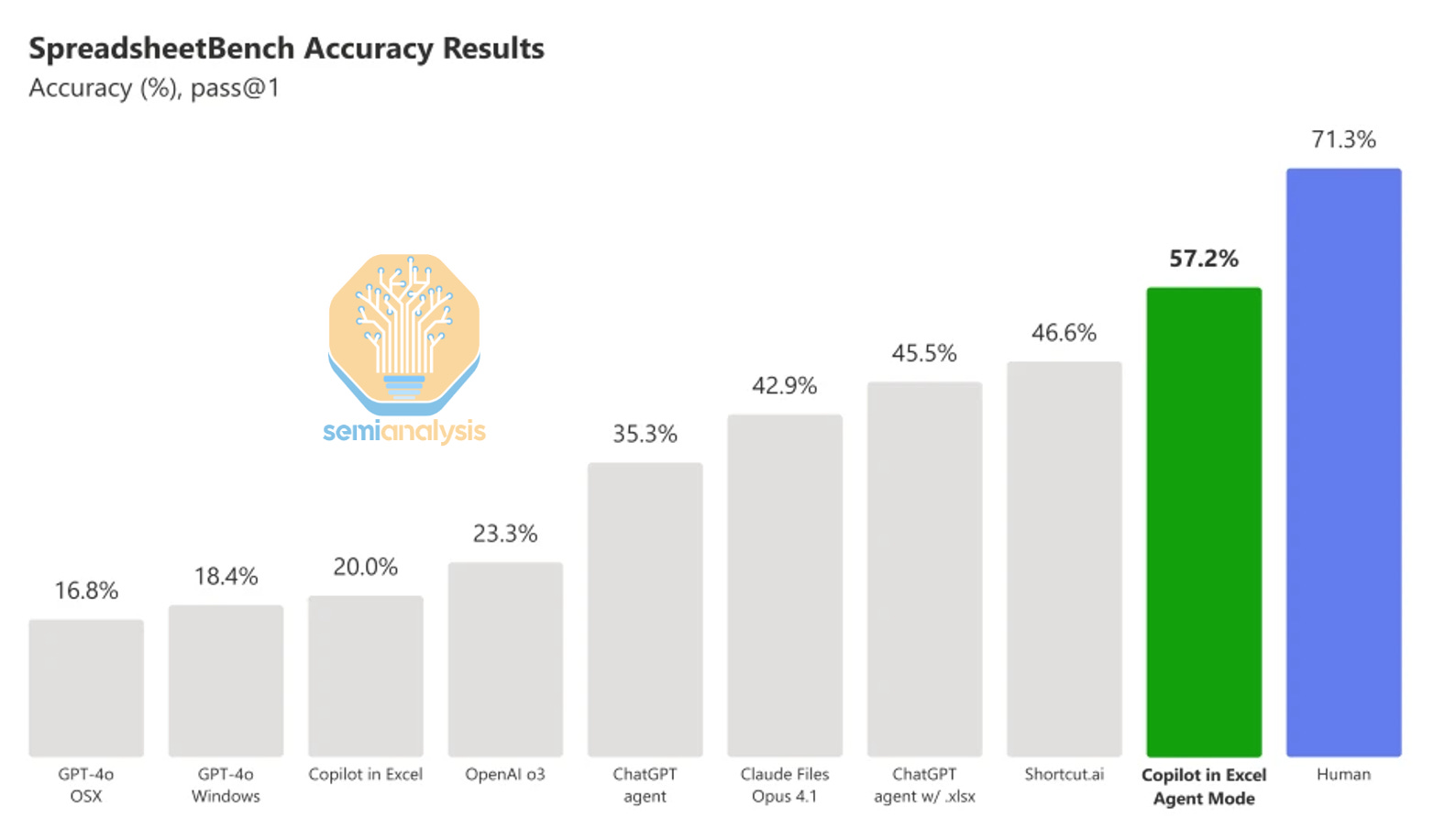
The Excel Agent is a post-trained version of one of OpenAI’s reasoning models. This led to results that Microsoft claims to be better than the frontier labs.
Having dug deep into Azure’s AI business, we now turn our attention to two key parts of Azure’s AI hardware stack:
Microsoft’s actual chip strategy: how they will balance NVIDIA, Maia, OpenAI, AMD and others
Azure’s networking architecture, and the impact on a broad range of suppliers
Mama Ma-ia!: Custom ASIC Struggles
In custom silicon development, Microsoft sits in dead last among the hyperscalers, and is not even trying to catch up.
Microsoft showcased their Maia 100 accelerator in late 2023, the latest of the big 4 hyperscalers to have an AI accelerator ASIC.

As expected of first generation silicon, Maia 100 was not manufactured in high volume or deployed for production workloads. The chip was architected before the Gen AI boom, leaving it short on memory bandwidth suitable for inference. ASIC programs take multiple generations to iterate until meaningful compute can be offloaded compute from merchant systems.
 | A guest post by
|