

RL Environments and RL for Science: Data Foundries and Multi-Agent Architectures
Worker Automation, RL as a Service, Anthropic's next big bet, GDPval and Utility Evals, Computer Use Agents, LLMs in Biology, Mid-Training, Lab Procurement Patterns, Platform Politics and Access
We’re hiring for AI Analysts and Tokenomics Analyst roles. Apply here or reach out directly.
Last June, we argued that scaling RL is the critical path to unlocking further AI capabilities. As we will show, the past several months have affirmed our thesis: major capability gains are coming from ramping RL compute. Pre-training continues to see further optimizations, but the lab’s are laser focused on scaling compute for RL.

The best example of this is demonstrated by OpenAI. The company has used the same base model, GPT-4o, for all their recent flagship models: o1, o3, and GPT-5 series. Gains in the performance of OpenAI’s models for 18 months were being driven by post-training and scaling up RL compute alone. OpenAI has now fixed their pretraining problems, so with that vector of scaling unlocked, progress will be even more rapid.
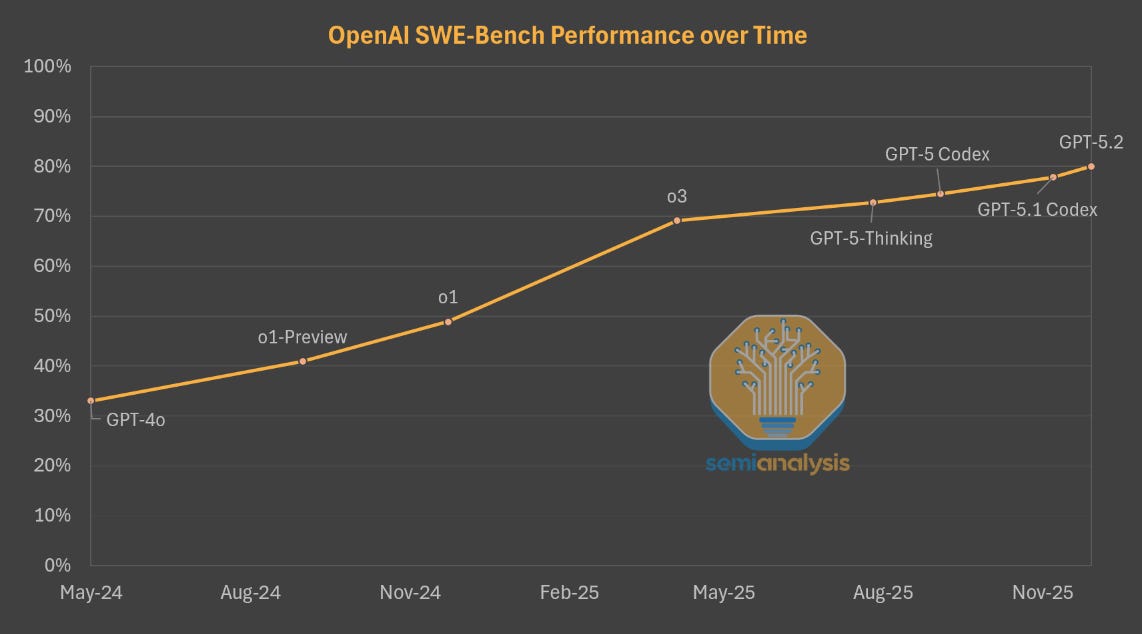
This is not to say that pre-training is dead: Anthropic, xAI, and especially Google all derived significant gains from scaling up pre-training. But OpenAI’s progress last year and ability to keep up using an older base model was existence proof of the efficacy of post-training.
Scaling up RL is difficult as it requires a steady stream of tasks the model needs to solve and learn from. Pre-training had the entire internet to train on, but equivalent corpus for RL is yet to be fully created. Most RL data and tasks must be constructed from scratch, which can be quite labor intensive.
Making the models “do the homework” started with math problems, which are easy to grade. Methods have since advanced, including branching out to newer domains like healthcare and financial modelling. To do this, models are placed in increasingly specialized “environments” that require the model to do these tasks.
Aggregating tasks and data can be done manually, or through the curation of high signal user data. The latter is what gives companies like Windsurf and Cursor the ability to post-train their own competitive models despite not having the resources of a lab.
These post-training efforts have improved model capability in domains like coding, but also model utility: models are more usable in everyday tools like Excel and PowerPoint.
To measure how much models are improving in utility and capability, OpenAI created an eval called GDPval. This eval covers 1000+ tasks across 44 occupations, picked from sectors that representing >5% of the economy. Many of these tasks are digital but require several hours to complete for a human. These tasks were created in conjunction with experts, averaging 14 years of experience.
Models are asked to solve these problems, given a prompt and a set of supporting documents. Tasks include filing a tax return for a fictitious human, creating slides as a client advisor for a resort, and creating commercials from a given set of stock footage. Grading occurs through experts picking between a model’s answer and a human expert’s answer. This win rate, if equal, would then mean that a model’s performance is then in parity with a human expert. The best current model, GPT-5.2, scores around 71%, meaning its work is tied to or preferred from human outputs 71% of the time.

While GDPval has some issues (e.g., skewed toward unusually specific digital work) it is the best example of how evaluations are shifting from measuring abstract intelligence to real world utility. This stands in contrast to most of the previous model evaluations, which focused on things like mathematical knowledge or PhD level scientific questions graded via multiple choice.
The underlying trend is models being able to operate autonomously for longer. With improved capabilities over shorter and longer horizons, AI companies think that models can help invent the next version of themselves. OpenAI, for their part, target having autonomous AI researchers by a March of 2028. Anthropic projects that in 2027, systems like Claude will be able to autonomously find breakthroughs that would otherwise take years to achieve.

But this journey will require significant amounts of data and task curation. Computer use environments for example require considerable amount of rote software engineering including replicating existing websites on the internet. This can be slow for the labs to do which is why much of it has been outsourced.
Outsourcing and The Ghost of Scale AI
Historically, Scale AI was one of the largest data contractors for the labs but now has been mostly absorbed by Meta. Scale saw considerable spending from across all labs, with revenues north of $1.4B in 2024.
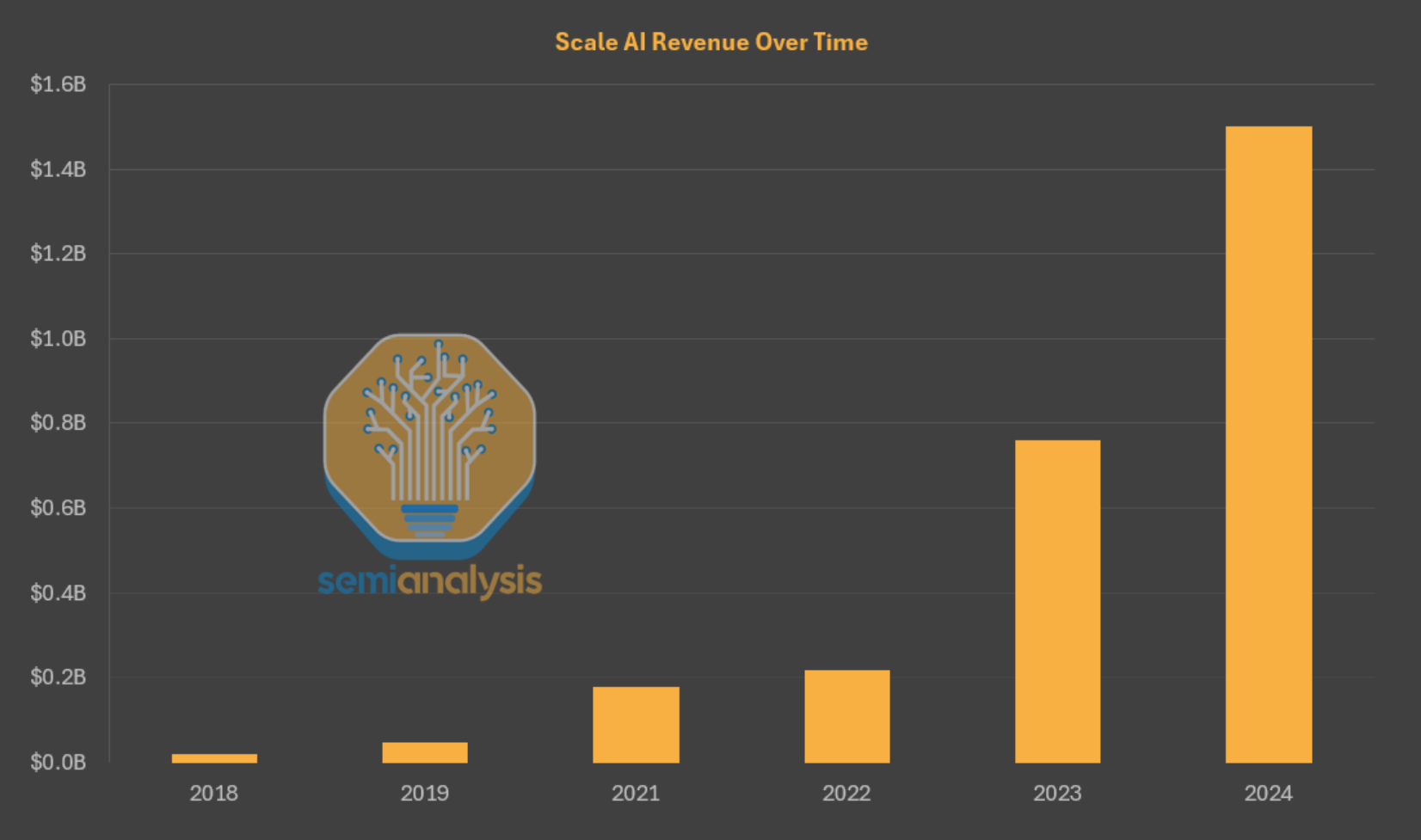
After the acquisition, though, multiple AI labs mostly stopped contracting Scale. This is to avoid Meta having access to the data they demand the most. Some from Scale’s team joined Meta’s Superintelligence group, mostly as leadership as well as part of the safety and evaluations teams. The organization now continues to produce evaluations and retains some data contracts, but is no longer servicing the labs to the extent it previously was.

While the tides were already shifting in the direction of other data providers like Surge, Scale left behind a large gap to fill. Who has stepped in to fill this gap?
During a Gold Rush, Sell Shovels. In an RL Scaling Boom…
During a Gold Rush, sell shovels. In an RL Scaling Boom, sell RL environments. More than 35 companies have popped up whose goal is to do exactly this across a variety of domains.
One set of companies focus on cloning websites. For example, environment companies hire overseas developers to replicate the UI of sites like DoorDash or Uber Eats and sell the mockups to labs. Labs then train agents to navigate the site so in production the agent can perform required functions reliably and consistently.
These “UI gyms” often cost about $20,000 per website, and OpenAI has purchased hundreds of sites for ChatGPT Agent training and development. These environments are a one time purchase and are reused for future models. Trajectories and logs from previous runs are preserved and fed back into various stages of training, like mid-training.
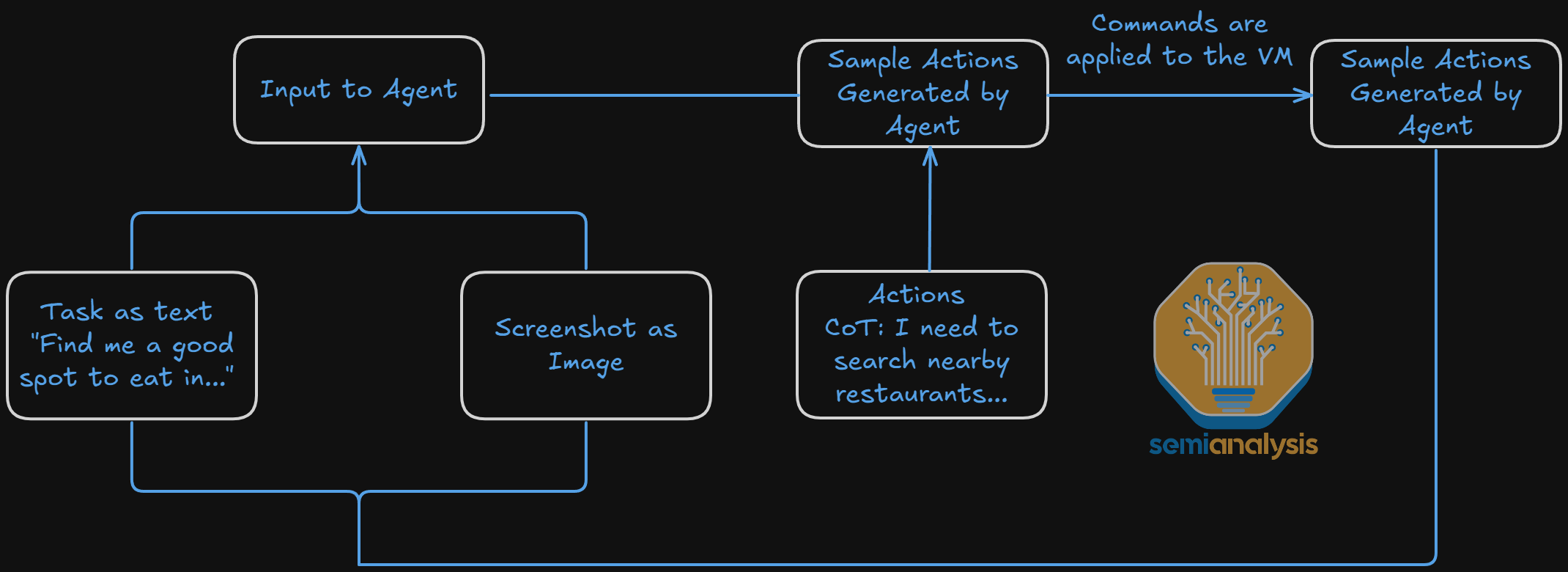
Other companies branched out into more sophisticated environments than just a website. Examples include Slack, Salesforce, AWS terminals, Microsoft OneDrive, Gmail, Discord, and Atlassian. The goal is for agents to autonomously operate in these software platforms, learning and better understanding how to navigate and operate within them.
These platforms, once built, can be combined to represent higher fidelity tasks and workloads. Putting together platforms like Slack, an API endpoint to a browser, and a coding editor can construct an increasingly realistic software task for the model. This enables interactions to be more multi-turn as opposed to a single shot, for example pinging the model halfway through its process via Slack to request a feature change.
Some of the companies building these sorts of environments, include Habitat, DeepTune, Fleet, Vmax, Turing, Mechanize, Preference Model, Bespoke Labs, Veris.ai and many others. Even within these companies there is significant diversity in quality or focus. Some companies focus on UI gyms, like Turing, while others like Mechanize focus on software engineering tasks. Almost all companies are seed stage companies with less than 20 employees, focused on 1 to 3 customers at most.
Most aforementioned companies close source their environments and serve them in exclusive contracts to the labs. Some, however, like Prime Intellect open source theirs and are fostering the Environments Hub, which aims to be a one stop shop for RL environments.
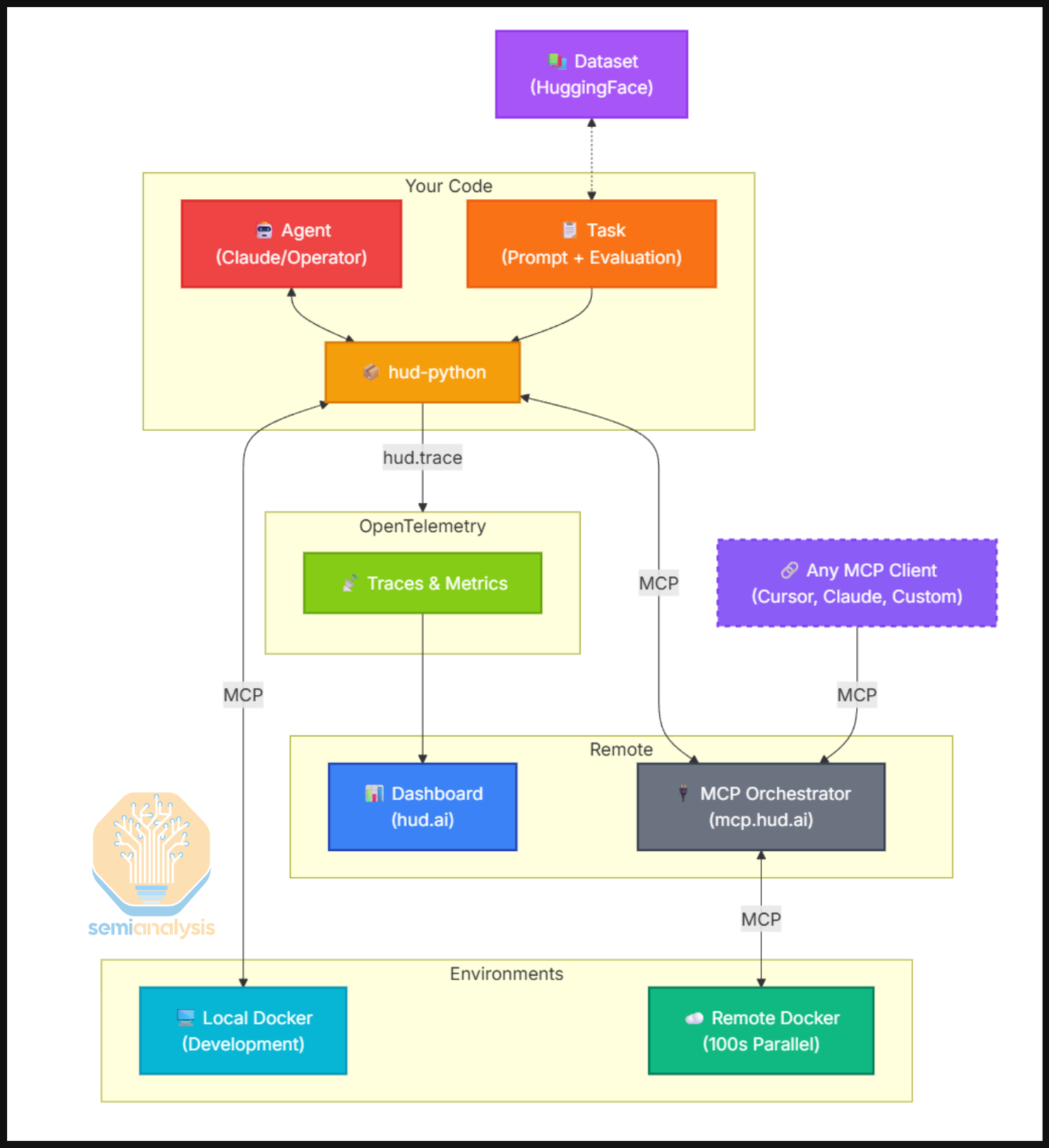
Others are building tooling for environments. HUD for example has tooling that allows for the wrapping any given software (e.g., a game, browser, google sheets) in a dockerized container, enabling its use as a scalable RL environment. Each container has two layers: the environment backend (the actual software being wrapped) and an MCP server that sits on top and exposes tool definitions the agent can call. When an agent issues a tool call like click(x,y) or type(text), the MCP server translates it into an action on the underlying software and returns the resulting observation. This is generally scaled into many parallel instances. Each task includes a prompt, setup conditions, and success criteria that return a reward signal. Every tool call and observation is captured via telemetry, which is useful for debugging but also collected and fed into training at later stages.
The highest in demand environments are coding environments. Understanding how these are built, structured, and assembled can provide a unique view into the infrastructure and engineering effort underpinning the progress we see today.
So You Want to Make a Coding Environment?
Demand for coding environments is so high that we believe defunct startups are getting acquired specifically for the value of another private GitHub repo to make environments out of. Understanding why these repos are so valuable requires understanding how coding environments are actually constructed. The process is more involved than it might seem.
SWE-rebench is a benchmark that aggregates thousands of Python tasks from GitHub and showcases how these environments are constructed. The process it employs is also automated, which is what we expect the labs to be doing.
The pipeline starts with downloading the GitHub Archive, containing 30k repos and 450k PRs with permissive licenses. This dataset is then filtered for several categories: PRs have to be resolved, merged to the main branch, have sufficient descriptions of the problem, impact more than one file, etc. PRs must introduce or modify test files as that is what is used for grading. For example, if a model’s patch causes previously failing tests to pass (without breaking others), the task is marked as solved.
To automate environment configuration, an LLM generates installation instructions for each task. The model reads relevant files in the repository (README, setup.py, requirements.txt, Docker files), then synthesizes a structured JSON “recipe” specifying the Python version, dependency installation commands, and test execution commands.
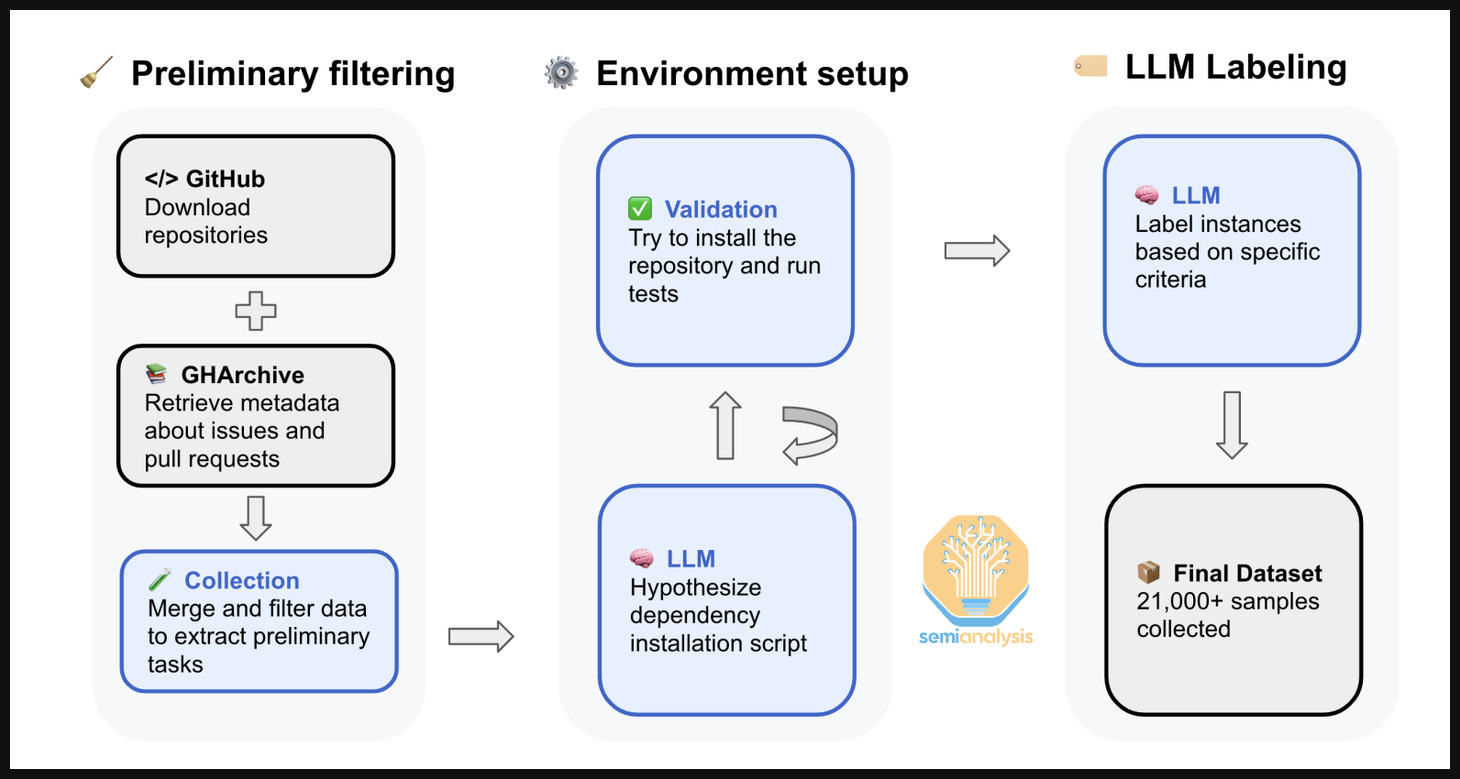
Each candidate task then undergoes execution-based verification. The environment is instantiated in a container, and tests from the PR’s test patch are executed. A task is considered valid only if at least one test fails before applying the solution patch, all initially failing tests pass after the patch is applied, and any tests that passed before continue to pass. After all the filtering, we end up with 21,336 tasks from the 450k we started.
But most PRs do not meet the strict criteria, which is why the yield is low. SWE-smith demonstrates this by having an LLM install repositories at their latest commit, then synthesizing bugs through four methods: prompting a model to introduce subtle errors into working functions, applying deterministic AST transformations like flipping if/else blocks or removing loops, using an LLM to semantically reverse real PRs against the current codebase, and combining validated single-function bugs into harder multi-file tasks. Every candidate is validated by checking if it breaks at least one existing test.
Importantly, these approaches aren't mutually exclusive. PR mining captures realistic bug patterns from actual development history and synthetic generation provides volume and coverage across the entire codebase. A lab with access to private repositories could run both pipelines against the same environments, first mining PRs then improving them with synthetic bugs. This combined approach is likely a strong approximation for how frontier labs are constructing RL environments for code.
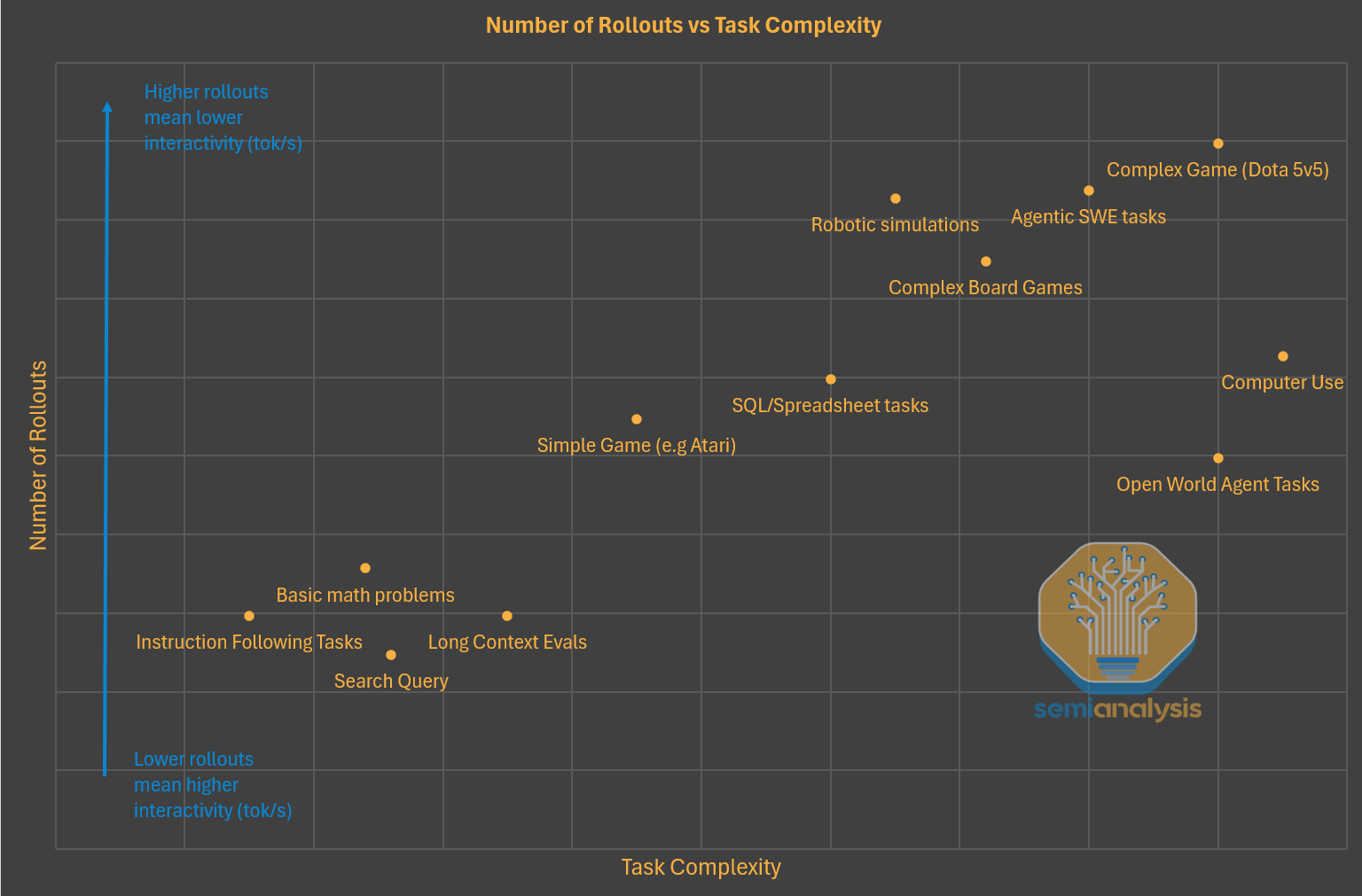
At scale, these pipelines produce tasks in the tens of thousands. DeepSeek ended up using 24,667 coding tasks extracted from GitHub for the training of V3.2. We know, from other labs like Kimi, that the infrastructure developed can support the instantiation of 10,000+ instances simultaneously. Generally speaking, the more difficult the task the more rollouts are needed during training. This is due to the problem being harder to solve, and the more rollouts, the more “shots on goal” the model has. However, this comes at the expense of each rollout being slower as throughput comes at the expense of speed.
Data Foundries and Expert Contractors
The reason environment tooling in general is useful is because environments are being created across many different domains: Chip design environments so models can aid in the design process, accounting ones for model to do taxes, and EHR software for medical use workflows are but few examples.
While software engineers construct the environment itself, often the workflows are created, described, and graded by domain specific contractors involved in the environment creation process. Finance professionals help define financial tasks, doctors for medicine, lawyers for law, etc.
Labs will go through human data contractor firms, who we will touch on shortly, who are looped in for their input on specific task creation. Contracts typically last at least a quarter and can be part time or full time. Contractors design tasks, write expected solutions, specify reward signals, and in some cases, grade model solutions. These reward signals can be in the form of rubrics, the writing of which can also involve contractors, or strict verifiers. These are the sort of experts that would be contracted to help build evals like GDPval.
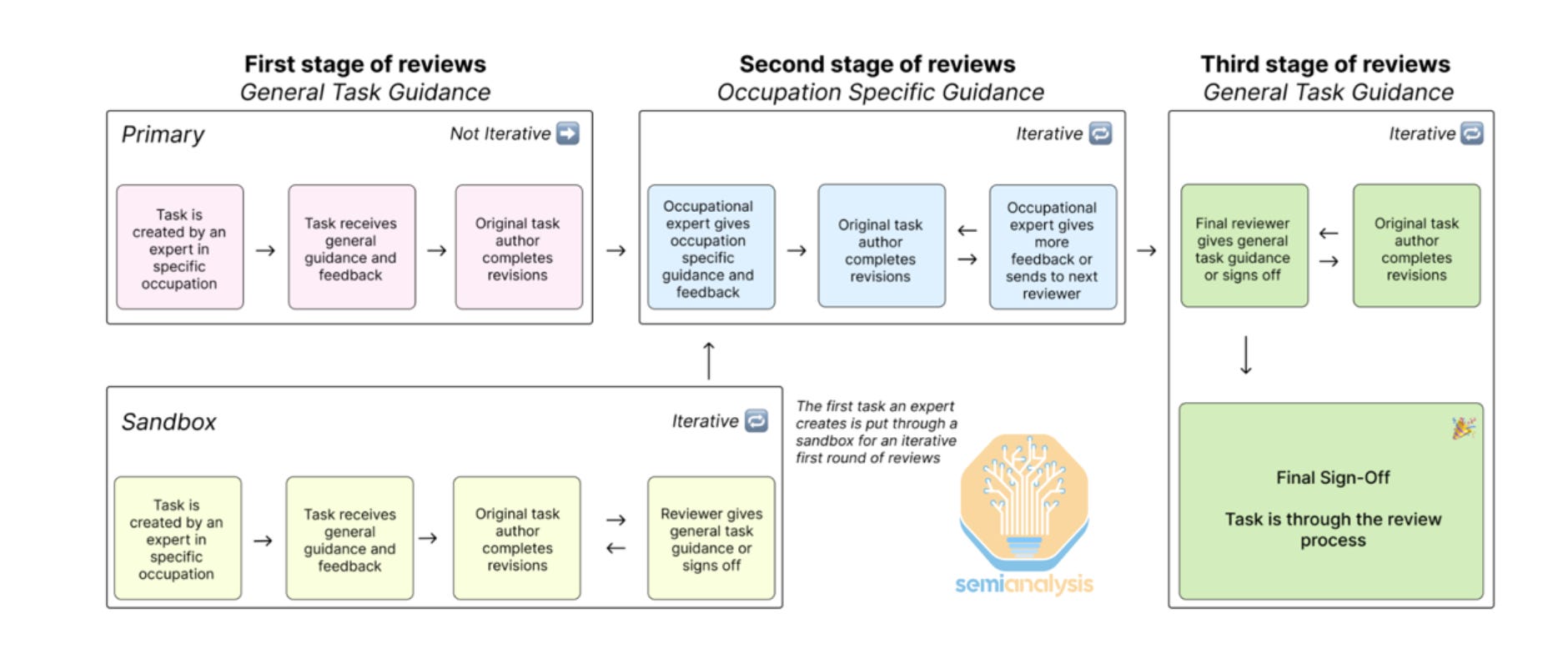
Firms like Mercor, Handshake, Surge, and Aboda.ai are used to hire these experts across many professional domains. Surge is the more established and larger player, with revenue we believe is closer to $1B ARR.
Most of these firms started out as AI interviewers or job matching companies, but ultimately found that being a connector between the labs and contractor experts is more valuable.
Coding is in the most amount of demand, but spending on non-professional domains like photography, music, and design has picked up. As mentioned, the labs want to not just increase the number of tasks they post-train over for a given domain, but also the breadth and variety.
Revenue for these providers is mostly concentrated around western labs like Anthropic, OpenAI, and Google. However, we think Surge is also active internationally, selling to Chinese labs like Moonshot and Z.ai. Indeed, we believe access to these RL environments played a huge part in increasing the capabilities for Kimi K2 Thinking and GLM-4.6. When companies advertise increased capabilities in PowerPoint deck or Excel sheet creation, that is directly downstream of additional RL training.
Chinese VC firms are actively trying to stand up Chinese data foundry competitors so they can fully serve the local ecosystem at cheaper prices than western ones. Most Chinese labs are still early to scaling RL: Qwen is currently spending around 5% of their pre-training compute on post-training. Successful homegrown data foundry business will drastically accelerate the transition, compute permitting, of course.

In the case above, contractors provide full solutions with explanations. Contractors can also and grade model outputs with feedback on errors. This data can be sourced in any language and translated by another model if needed.
Firms like Mercor are also producers of a significant amount of grading rubrics, which can be used in a variety of different domains. Currently, most rubrics are written by humans, though there are some companies, like the LLM Data Company, trying to have models write grading rubrics. This can be done through, for example, connecting performant models to highly reliable MCPs to extract information to then be used in a structured rubric.

We think there is significant upside to this approach, though AI labs currently focus on consuming human generated data. In the long run, as models get better, reliability and quality will improve. As mentioned, all the labs are chasing AI-automated AI research.
Given the diversity of options, understanding data procurement decisions is critical to informing lab strategies. This paradigm is not like pre-training where everyone had access to the same data.
Buying patterns across labs
Anthropic
Anthropic has been an aggressive buyer in the RL environment market. Anthropic is often the first customer of dozens of new companies, providing them with exclusive contracts and in some cases tips on environment construction. We think they are working with more than a dozen RL environment companies as contractors. The company likely wants a broad ecosystem of vendors such that the product is commoditized, driving down costs on some types of environments.
A lively vendor ecosystem also attracts investors who can further subsidize costs. The tradeoff is overhead from managing many vendors at once, which is why we believe Anthropic is requiring vendors to adhere to specific sandbox frameworks in most domains and has built a vendor engagement platform.
While it is correct that the company is focused on code, we are now seeing them start to ramp up on other domains. Computer use, for example, has been high on the priority list for some time now. Other areas, like biology, are also ramping, as we will show later. Coding is still central to their efforts, but is not the only domain they are interested in.
OpenAI
We believe OpenAI buys from a smaller pool of vendors than Anthropic, though they outspend Anthropic and many other labs on net for data. To reduce reliance on third parties like Surge, Mercor, and Handshake, OpenAI is building an in-house human data team. xAI has taken a similar approach from the start, posting for AI tutors since the company launched and now ramping up that hiring.
They outspend the labs because they have many parallel areas they are trying to scale. ChatGPT Agent sees heavy use of UI Gyms. The model which won IMO Gold, a version of GPT-5.1 Codex Max, benefited from large amounts of math and code data. The consumer version sees a mix from all the programs in addition to targeted post-training around behaviour.

Data across programs is aggregated and spun back into mid-training, which we will explain later. This increases performance across the board.
The large volumes of data OpenAI procures has played a key part in their post-training efforts, which as mentioned, have driven the key capabilities forward in the last several generations. As their human data team scales, they will be able to skip paying the margins to many of the data vendors and aggregate more data volume for the same cost.
Google DeepMind
Google DeepMind’s procurement is rather decentralized. Environment procurement specifically has been driven by researchers from different teams and programs. Specific environments they have been interested in centralized around coding and computer use, particularly ML related environments and tasks.
Google spent a small amount of compute on post-training for Gemini 2.5 Pro, likely under 5% of pre-training compute at launch. While they have scaled it up for Gemini 3, we still think it is small relative to the other labs. Nevertheless, Google is uniquely positioned for this paradigm: they already own the underlying platforms (Sheets, Slides, Docs, Drive, Maps) and don’t need to build new ones. More importantly, their legions of PMs have deep visibility into how hundreds of millions of users actually interact with these products, providing a direct signal for what strong model performance should look like. It is then mostly a matter of time and politics until Google utilizes this user behavior to post-train Gemini on those applications. This is harder for Google than if it was just a technical barrier.
Google has also been on the defensive, decreasing rate limits for scraping of their products like Gmail. This makes it harder for other to scrape the app and use the data for replication efforts (e.g., a mockup app to train with).
In the long run, though, how useful should we expect these models to be? Is the path to AGI just environments stacked on top of each other?
LLM-based Automation is not a given
There has been much speculation around the automation of jobs, particularly white collar work, due to AI. An interesting datapoint against this hypothesis can be found in OpenAI’s GDPval paper. OpenAI’s found that human experts were faster and finished tasks for a smaller cost than they would otherwise. With rising capability, humans were augmented, not automated.
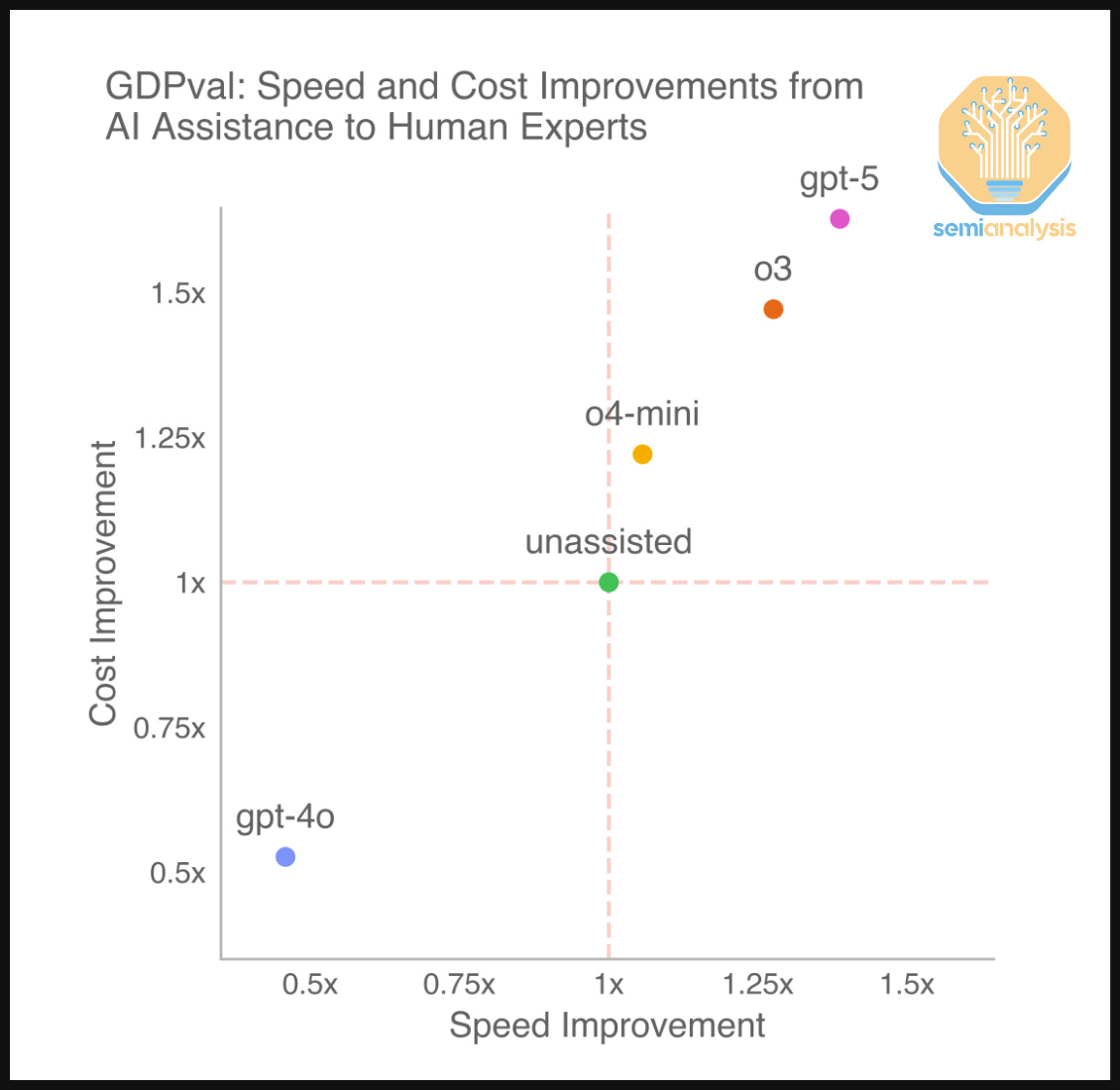
The near term may not bear automation of expert work, but rather task augmentation. This will likely be true for tasks like software engineering.
As another example, before the AI hype, many predicted that radiology will be automated. This was due to capability increases in vision models. This has not borne out to be true, despite continued improvements.
Radiology turned out to be more complicated than just scans.
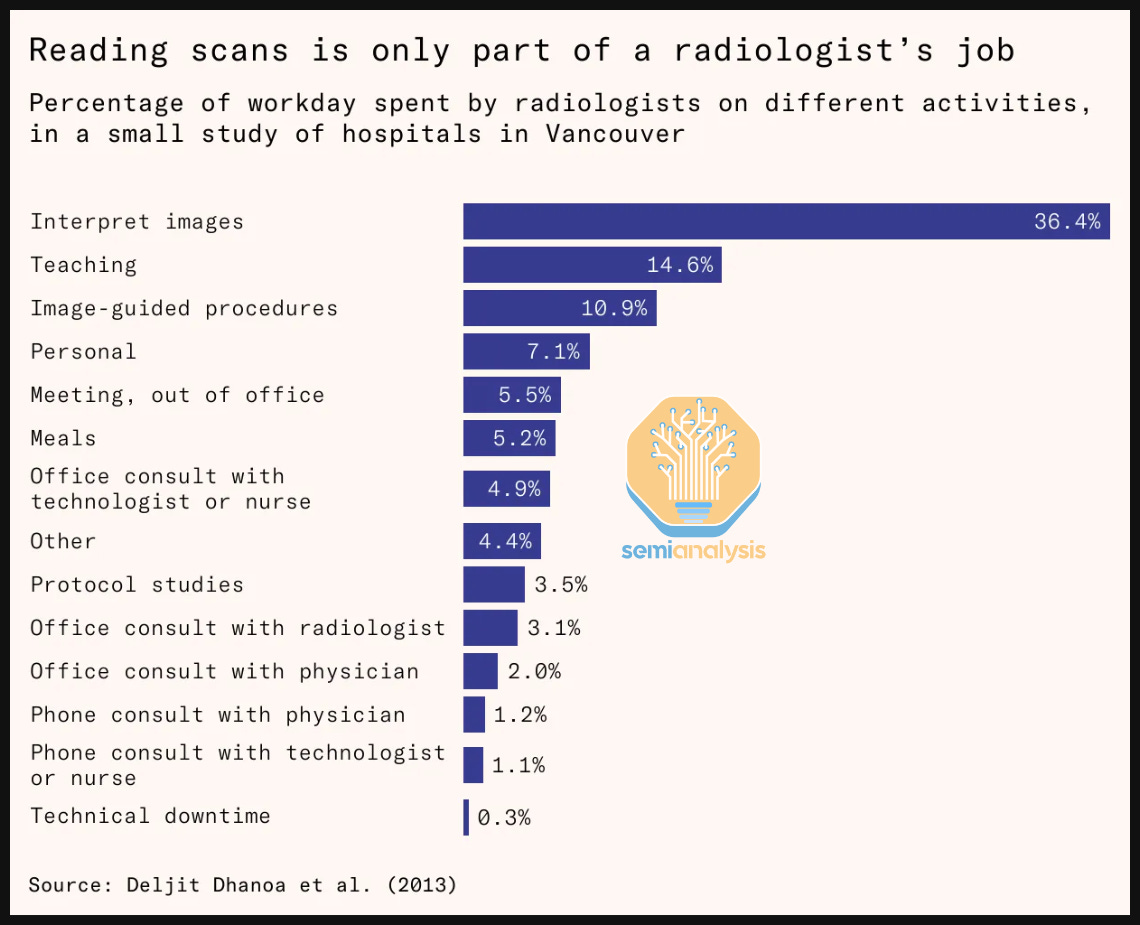
The idea that models will mostly augment workers may bear out for professional fields like consulting or software engineering. However, we think it is unlikely to be true for for shorter horizon, repetitive tasks, particularly call center jobs for example.
Regardless of capabilities, there are some barriers to adoption. This includes but is not limited to defensive posturing from web providers and companies. This is particularly true for agents.
Sorry, your agent is not allowed
Agents can also be blocked from major sites, with this dynamic playing out between ChatGPT Agent and Amazon.
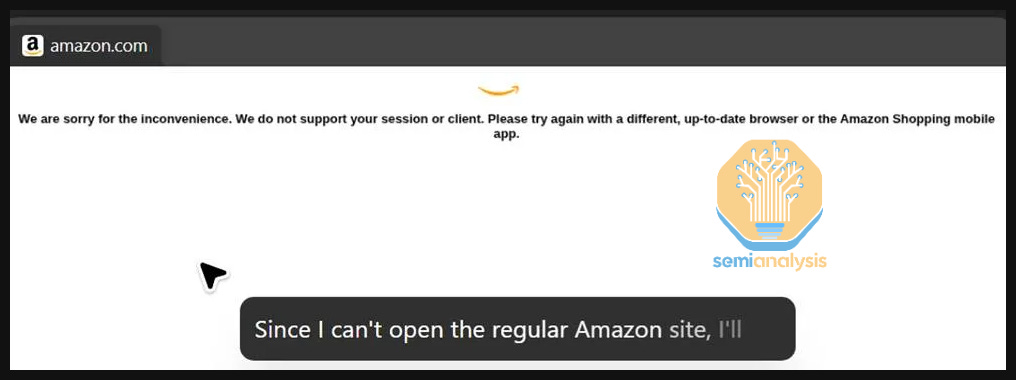
For Amazon, this move makes sense: agents shopping on the platform will allow users to sidestep any ads on the platform. Amazon could restrict the ecosystem to their own model, Nova and Rufus, or leverage access in negotiations.
The latter is exactly what is playing out. OpenAI is in talks with Amazon to get access to the shopping platform, though this may be contingent on details relating to the use of Amazon’s cloud and chips. We anticipate companies like Google, Meta, Microsoft, and X will all restrict access to their ecosystems to the greatest extent possible, though this may be limited by antitrust concerns.
Central to deals like the Amazon and OpenAI one is the monetization of free users. There is precedent to this: OpenAI announced “Instant Checkout,” integrated with Shopify and Etsy. We called this out as a potential path for agents in August.

When it comes to enterprise, many are setting up their own agents. They often contract with other startups which conduct “RL as a service” for them, provided a specific task or workload.
RL as a service
RL is highly effective at teaching models to use tools. Through using open-source tooling, some startups now offer tailored RL services to large enterprises. The space is comprised of smaller YC startups like RunRL and Osmosis, but also ones started by experienced researchers like Applied Compute and Adaptive ML.
Often, Qwen models are used for this as they are easy to post-train and require little resources to run. Qwen has a variety of models, including small dense ones, which require less skill and set up.
After custom post-training, these models run on rented hardware. Currently, Baseten serves many these small, custom models. Typical targets include Salesforce and AWS Terminal and creating or closing Jira tickets. It is also possible to get models to be reliable at using MCPs, for example to extract data from SEC filings.
These RL as a service startup are joined by the labs, with OpenAI recently spinning up a “Reinforcement Fine Tuning” (RFT) service. OpenAI RFT’s goal is to let any customer with sufficient data RL an OpenAI model so it is tuned to the customer’s tasks and domains.
In practice, the service has fallen short. We believe it is unstable and too expensive for most customers. As such, we are seeing demand for these services mostly flow to young startups. These young, YC companies do not have strong margins. Indeed, they often lose money. However, they are able to serve users at 5x less compared to what it would cost on OpenAI’s platform, gaining market share.
In the longer term, this will change. OpenAI’s is targeting large enterprises who can spend millions, and in the aggregate, the labs will capture most of the revenue. For OpenAI, this will be done through the “Strategic Deployment” team, whose goal is to work directly with a customer to build custom models. OpenAI was early to bet on this service as an enterprise use case, and enterprise growth outpaced consumer in 2025 for the company.

Anthropic is also entering the game. We believe Anthropic has its own RFT-like service that is more stable and more sample-efficient than OpenAI’s. Anthropic might expose it through the API, but is also actively hiring “Forward Deployed Engineers,” as OpenAI does, presumably serving the same function as the strategic deployment team at OpenAI.
Anthropic is bringing on large volumes of Trainium, which is economically attractive for RL in part due to low $/HBM. HBM generally contributes a large part of the chip’s BOM, but Amazon sourced it directly, reducing costs. RL workloads are mostly inference, which is memory bound. This means having a low TCO chip like Trainium positions customers in a place to make strong margins off this service if they optimize the throughput a sufficient amount.

As noted, there is substantial upside in training custom models. One area in which we are particularly excited about is scientific discovery, within which custom models can make large amounts of progress.
RL as a service is also offered by a number of other companies such as ThinkingMachines Tinker as well as Applied Compute and Adaptive ML. All three have more success then OpenAI and Anthropic so far in this market.
RL for Science
LLMs unlock a new frontier where models can search, plan, and propose experiments. With the right tools, agents will also be able to execute them. RL enables the harnessing of the feedback from those experiments into information the model can use to improve, enabling a loop of self-improvement given the right conditions.
There are several companies leveraging this, and one such company is Periodic Labs. which aims to build an AI scientist trained through lab generated data.
The goal is to create a closed-loop RL system with rewards grounded in physical experiments. Models use tools, including other smaller specialised models, to test out hypotheses and validate ideas. Then, these ideas are tested out in increasingly high fidelity simulators, which later inform physical experiments.
This way, subagents handle what they are good at and general LLMs can be used for orchestrating. Orchestration may also extend to physical tools, like characterizing materials, for example.

This process of testing ideas through increasingly high-fidelity methods to derisk experiments before running them in a lab maps roughly onto a graduate student’s typical workflow.
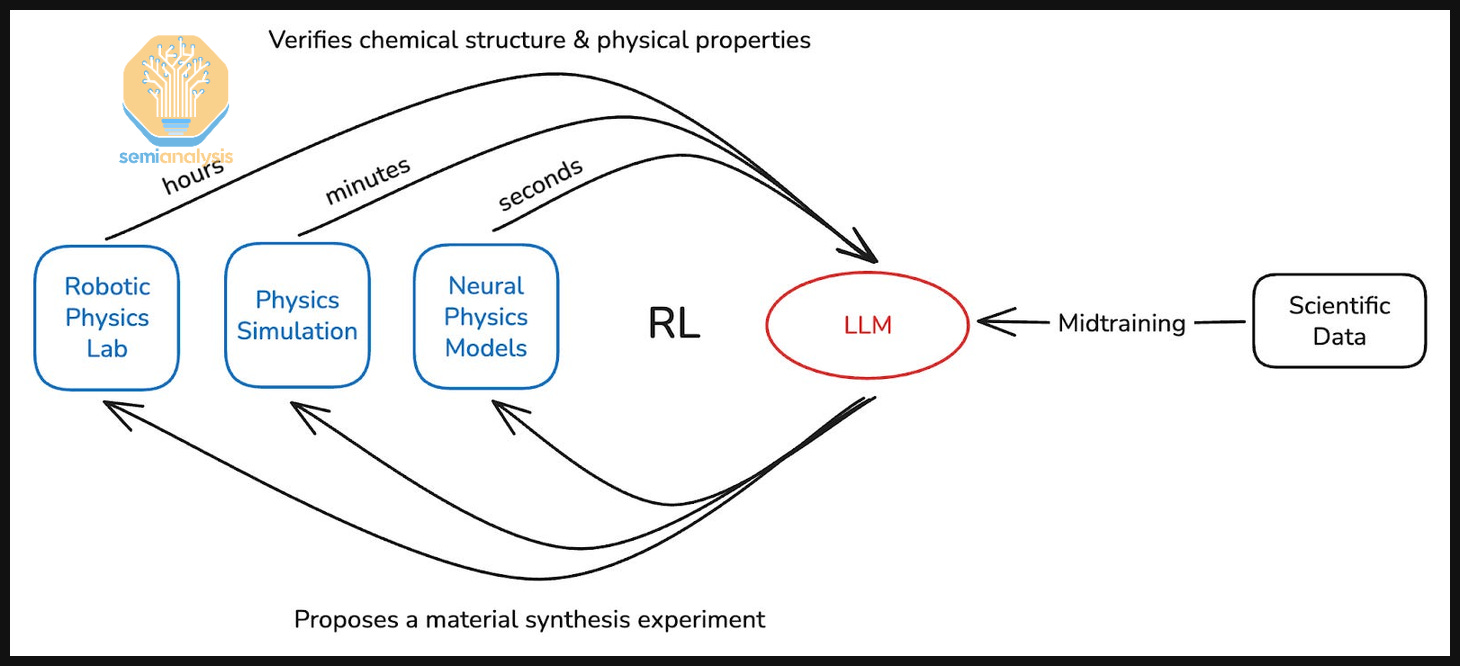
Open-source models can be used as a starting point and mid-training can be done to extend capabilities. Mid-training is continued pre-training (next token prediction), which can be used for extending a model’s cutoff date, improving domain knowledge on specific topics, and or priming them for high compute RL. For example, when OpenAI models see a refreshed cutoff date, it is due to continued mid-training on top of the model.
In highly specific scientific domains, mid-training will lead to higher quality models after post training. Meta, in their recent code specific model, found that the benefits of mid-training extended even after other stages (e.g., SFT) were applied. Meta used 1T tokens for mid-training for a recent model, but we expect OpenAI to be using somewhere between 5-10x more.
An example of data that it added into the mid-training stage is environment trajectories from previous runs. These are the collected rollouts that were generated when a previous version of the model was undergoing RL.

To supply data for RL and mid-training, Periodic is building a large physical lab to run experiments and produce experimentally verified reward signals. This is in line with other efforts, as DeepMind is also starting an automated materials science research lab in 2026.
Running your own experiments yields complete knowledge of input variables and outcomes, something not guaranteed when training purely on published papers, which often disagree even with comparable metrics. Another domain which requires significant lab work is biology. It is also a domain in which the labs have had diverging approaches.
RL Meets the Wet Lab
There are two primary bottlenecks within biology: "how can promising drug candidates be identified faster" and "how can drug development be executed faster once candidates are found." OpenAI and Anthropic have both established pharma partnerships but are tackling different parts of this pipeline.
OpenAI is targeting early-stage discovery, building systems that conduct the research themselves. Recently, OpenAI showcased GPT-5 operating in a closed loop: proposing protocol modifications, receiving experimental results, and iterating autonomously with no human in the loop. As part of this effort, OpenAI also had to set up basic robotic systems to conduct the experiments. Fundamentally, this aims to increase the rate at which useful candidates are found.
Anthropic, on the other hand, is targeting the drug development and approval processes. Claude for Life Sciences is a platform with pre-built connectors linking directly to Benchling, 10x Genomics, PubMed, and other services scientists use. The goal is to be able to iterate faster on drug trials, for example. This is then neatly packaged in a solution ready to be shipped to enterprise companies, understandable essentially as a (functioning) Copilot for the Life Sciences. The core idea is to increase the speed at which documentation and approval happens.
We think there is a likelihood both companies converge into tackling both domains, but the current split is revealing: OpenAI is chasing moonshot AI projects, while Anthropic is continuing with its more boring but practical enterprise plugs-ins and solutions. Long term potential will be revealed through each company’s speed of iteration and ability to take on more and more tasks in the pipeline.
Implied within this is the need for large amounts of biological data to train models. While companies like Mercor will be happy to take money from the labs, those companies do not have the ML or physical infrastructure to supply large amounts of biological data. This is where we see a role for companies like Medra, who aims to supply large amounts of biological data to the labs.
Medra aims to set up a robotically automated scientific lab focused on biology. The company does not plan to build foundation models or design drugs. Instead, they aim to build the experimental infrastructure and generate the validated data that foundation model companies need to train on. Like periodic, Medra aims to build their own lab with hundreds of robots. We believe robotics will enable more consistent results and faster iteration, driven by the closed loop described above, but there will be a steep learning curve as set ups are optimised and systems made more robust. Lab automation is a decades old problem and improvement is likely downstream of restricting scope as opposed to sudden breakthroughs.
This further demonstrates how different post-training is to pre-training: if OpenAI choose a different set of experiments to optimise for versus Google DeepMind, then the resulting models and applications will be separate. The specialisation in these hyper specific domains cuts against the notion of model commodification and similarity.
RL environments are spilling into the physical world. These environments are no longer just a docker container that can be arbitrarily spun up in software land. It is an experiment that needs to be run by a human or a robot, with a real cost to materials, electricity, equipment, and lab space. There are interesting implications to this, including that the marginal amount of data per dollar spent is drastically lower than in software. A single biological experiment can cost hundreds to thousands of dollars and take hours to complete, compared to a coding task that can be attempted 64 times and graded for a trivial cost. This drives up the need for more efficient algorithms and specific architectural decisions to make physical RL tractable.
Why RL for Biology Can be Challenging
Scientific experiments can vary wildly in time required for completion. In biology, plenty of experiments take days to complete. These longer timelines require long rollouts, meaning rewards will be sparse. Sparse rewards provide less signal for the model to learn from.

One way around this would be to reward the model’s steps, not just its result. This rewards the model’s process and thinking, as opposed to just the final action. While it can be difficult to correctly identify what a “correct” step looks like, it can be approximated through the use of rubrics. In fact, this is exactly how OpenAI grades problems on open ended research tasks in a recent eval, Frontier Science, which measures a model’s ability to perform scientific research tasks. In practice during experiments, tasks can be split into individually rewarded ones that shrink down the grading time horizon.

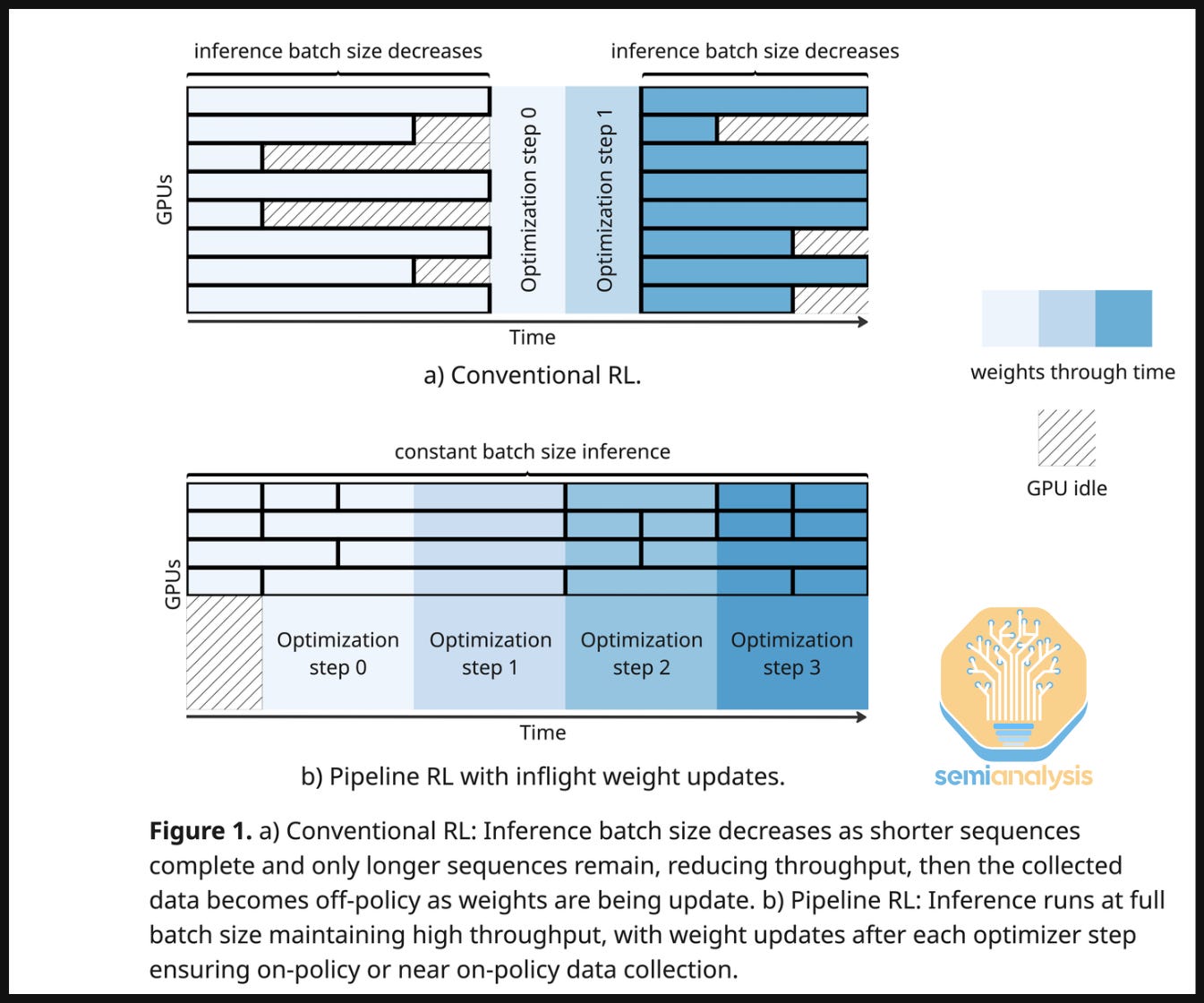
Long rollouts are also terrible for GPU utilization, which is why many of the labs have been utilizing methods like in-flight weight updates. Here, weights are exchanged and straggler rollouts continue with stale KV Caches. This allows for training to continue while straggler rollouts finish. The result can yield a 2x improvement on the amount of iterations for the same wall clock time.
Another bottleneck lies within the available data. Scientific literature often includes results that disagree with each other even on basic questions, making it difficult to construct reliable training sets. Biology is somewhat less challenging because existing open-source data is more common. AlphaFold was trained on data from the Protein Data Bank, which contained 170,000 samples. FutureHouse’s Ether0 used the Open Reaction Database. Additional efforts like EvE will continue to provide valuable platforms for model providers.
Though pharma also posses large swaths of closed source datasets. We expect to see more partnerships between frontier labs, which have the ML expertise pharma companies struggle to attract, and pharma companies, which have the biological data and clinical knowledge the labs lack.

While there are obstacles, including some outlined above, there is so much low hanging fruit to capture that we expect efforts focused on high compute RL for science to be extremely valuable rather quickly.
Many of the capabilities that have enabled the vast increase in progress have relied on scaling RL. While there is still plenty to go, there is one other dimension that is showing early promise. This can be done with current models, though at substantially higher costs. Below we dive into an additional frontier opening right in front of our eyes.